
Python中使用正则表达式如何匹配出标点符号?
回复“资源”即可获赠Python学习资料
大家好,我是皮皮。
一、前言
前几天在Python最强王者交流群【Chloe】问了一道Pandas处理的问题,如下图所示。
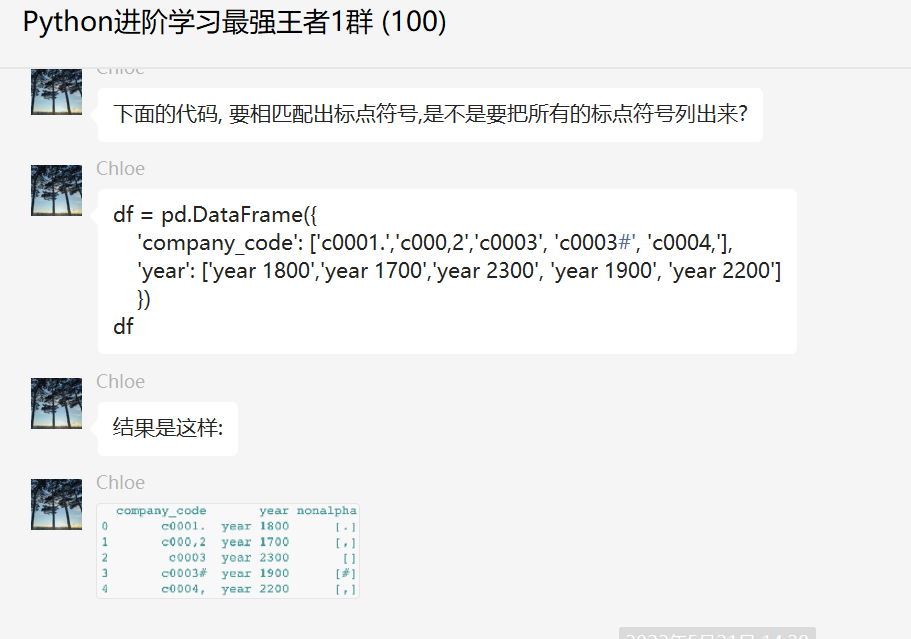
原始数据如下:
df = pd.DataFrame({
'company_code': ['c0001.','c000,2','c0003', 'c0003#', 'c0004,'],
'year': ['year 1800','year 1700','year 2300', 'year 1900', 'year 2200']
})
df
预期的结果如下图所示:

二、实现过程
这里【瑜亮老师】给出一个可行的代码,大家后面遇到了,可以对应的修改下,事半功倍,代码如下所示:
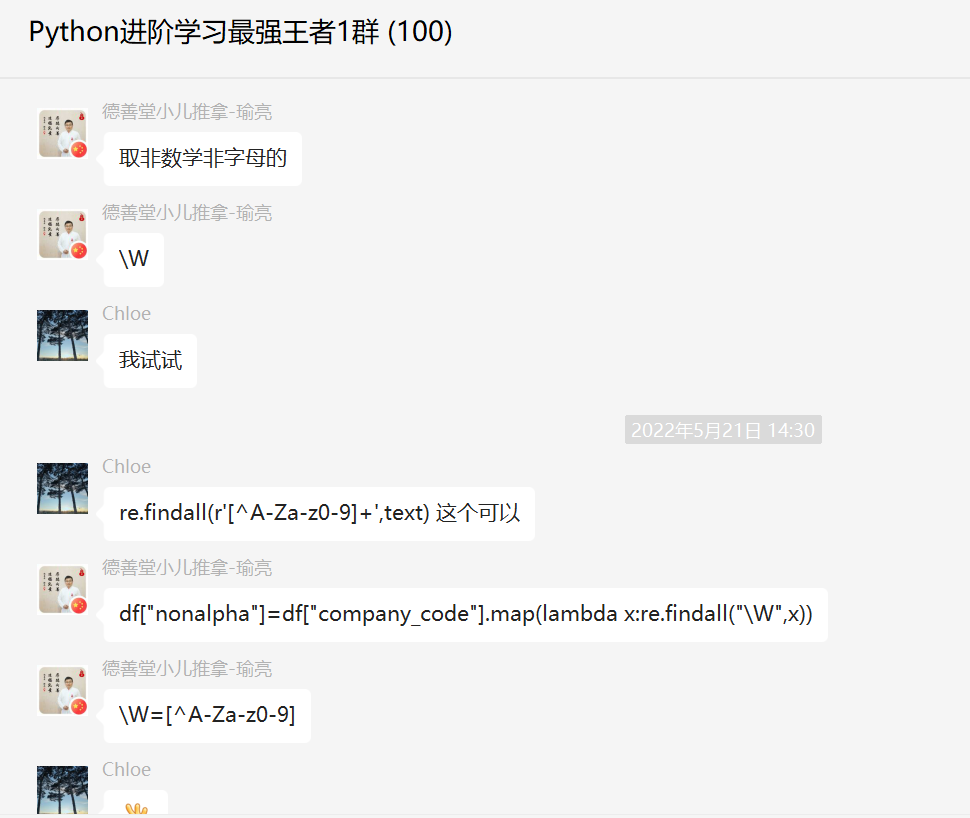
import pandas as pd
import re
df = pd.DataFrame({
'company_code': ['c0001.', 'c000,2', 'c0003', 'c0003#', 'c0004,'],
'year': ['year 1800', 'year 1700', 'year 2300', 'year 1900', 'year 2200']
})
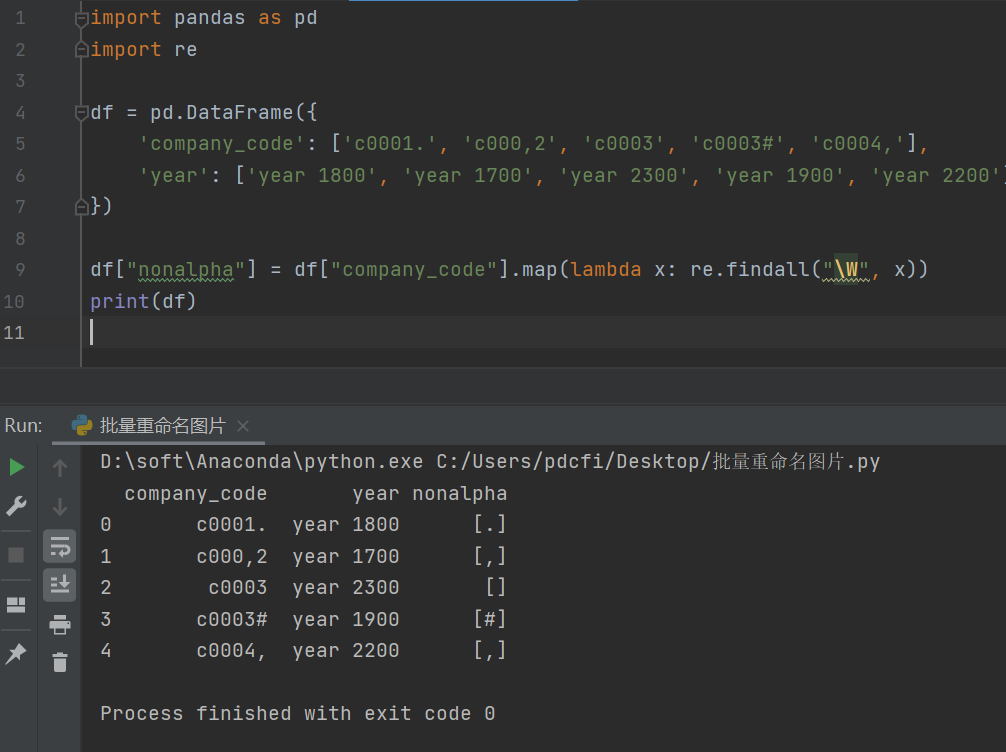
df["nonalpha"] = df["company_code"].map(lambda x: re.findall("\W", x))
print(df)
运行之后,结果就是想要的了。
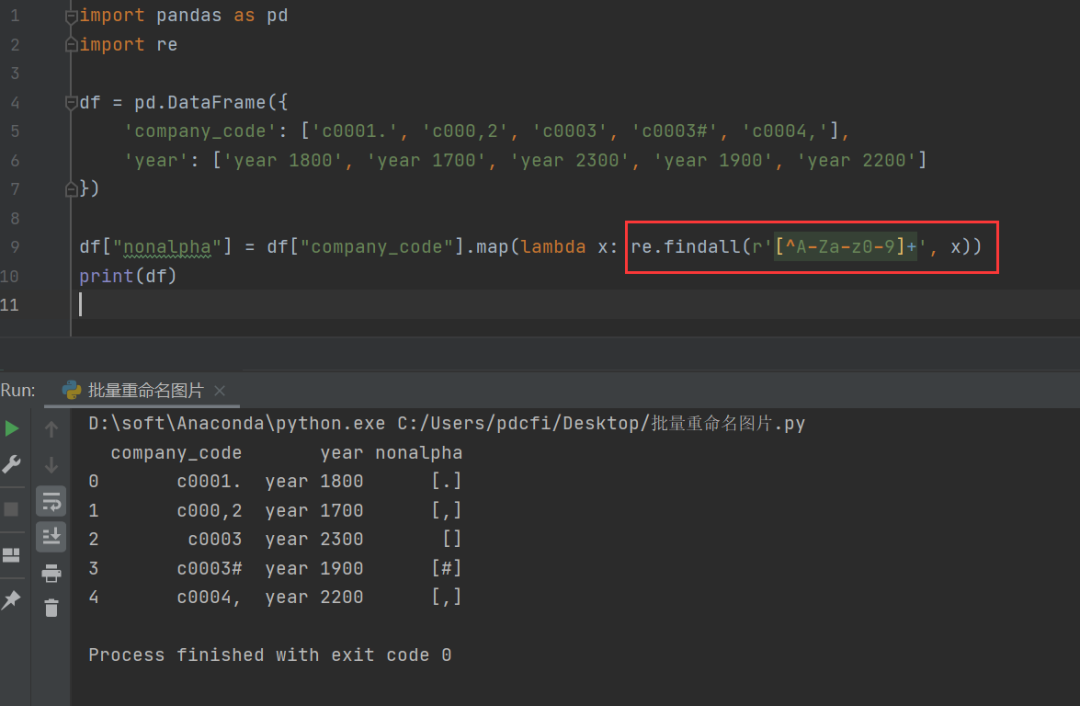
后来她自己也给了一个方法,也是可以的。
df["nonalpha"] = df["company_code"].map(lambda x: re.findall(r'[^A-Za-z0-9]+', x))
正则表达式,yyds!
三、总结
大家好,我是皮皮。这篇文章主要盘点了一道使用Pandas处理数据的问题,文中针对该问题给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝【Chloe】提问,感谢【瑜亮老师】给出的思路和代码解析,感谢【月神】、【dcpeng】等人参与学习交流。
小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
评论