
AI部署以及工业落地学习之路(文章较长,建议收藏)
点击下方卡片,关注“新机器视觉”公众号
重磅干货,第一时间送达
来源:计算机视觉研究院 作者:Edison_G
最近在复盘今年上半年做的一些事情,不管是训练模型、部署模型搭建服务,还是写一些组件代码,零零散散是有一些产出。
本文主要转自知乎《链接:https://zhuanlan.zhihu.com/p/386488468》

深感还有很多很多需要学习的地方。既然要学习,那么学习路线就显得比较重要了。
本文重点谈谈学习AI部署的一些基础和需要提升的地方。这也是老潘之前学习、或者未来需要学习的一些点,这里抛砖引玉下,也希望大家能够提出一点意见。
1
AI部署
AI部署这个词儿大家肯定不陌生,可能有些小伙伴还不是很清楚这个是干嘛的,但总归是耳熟能详了。





2
主题:聊聊AI部署


作为AI算法部署工程师,你要做的就是将训练好的模型部署到线上,根据任务需求,速度提升2-10倍不等,还需要保证模型的稳定性。
是不是很有挑战性?
3
需要什么技术?
需要一些算法知识以及扎实的工程能力。
老潘认为算法部署落地这个方向是比较踏实务实的方向,相比设计模型提出新算法,对于咱们这种并不天赋异禀来说,只要肯付出,收获是肯定有的(不像设计模型,那些巧妙的结果设计不出来就是设计不出来你气不气)。
其实算法部署也算是开发了,不仅需要和训练好的模型打交道,有时候也会干一些粗活累活(也就是dirty work),自己用C++、cuda写算子(预处理、op、后处理等等)去实现一些独特的算子。也需要经常调bug、联合编译、动态静态库混搭等等。
算法部署最常用的语言是啥,当然是C++了。如果想搞深度学习AI部署这块,C++是逃离不了的。

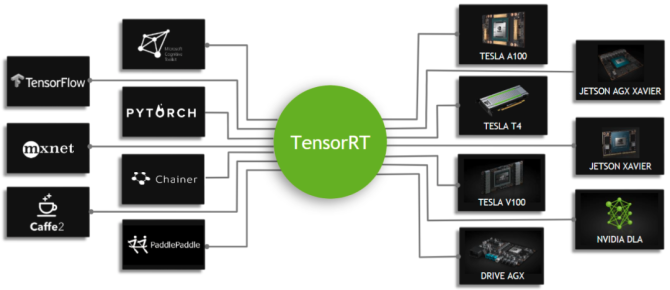
所以,学好C++很重要,起码能看懂各种关于部署精巧设计的框架(再列一遍:Caffe、libtorch、ncnn、mnn、tvm、OpenVino、TensorRT,不完全统计,我就列过我用过的)。当然并行计算编程语言也可以学一个,针对不同的平台而不同,可以先学学CUDA,资料更多一些,熟悉熟悉并行计算的原理,对以后学习其他并行语言都有帮助。
系统的知识嘛,还在整理,还是建议实际中用到啥再看啥,或者有项目在push你,这样学习的更快一些。
可以选择上手的项目:
好用的开源推理框架:Caffe、NCNN、MNN、TVM、OpenVino
好用的半开源推理框架:TensorRT
好用的开源服务器框架:triton-inference-server
基础知识:计算机原理、编译原理等
需要的深度学习基础知识
AI部署当然也需要深度学习的基础知识,也需要知道怎么训练模型,怎么优化模型,模型是怎么设计的等等。不然你怎会理解这个模型的具体op细节以及运行细节,有些模型结构比较复杂,也需要对原始模型进行debug。
常用的框架
这里介绍一些部署常用到的框架,毕竟对于某些任务来说,自己造轮子不如用别人造好的轮子。并且大部分大厂的轮子都有很多我们可以学习的地方,因为开源我们也可以和其他开发者一同讨论相关问题;同样,虽然开源,但用于生产环境也几乎没有问题,我们也可以根据自身需求进行魔改。
这里介绍一些值得学习的推理框架,不瞒你说,这些推理框架已经被很多公司使用于生成环境了。
Caffe
Libtorch (torchscript)
TensorRT
OpenVINO
NCNN/MNN/TNN/TVM
PaddlePaddle
海康开放平台

4
AI部署中提速的方法
上到模型层面,下到底层硬件层面,其实能做的有很多。如果我们将各种方法都用一遍(大力出奇迹),最终模型提升10倍多真的不是梦!
有哪些能做的呢?
模型结构
剪枝
蒸馏
稀疏化训练
量化训练
算子融合、计算图优化、底层优化
主要说说最后两个模块。
量化训练
这里指的量化训练是在INT8精度的基础上对模型进行量化。简称QAT(Quantization Aware Training)。
量化后的模型在特定CPU或者GPU上相比FP32、FP16有更高的速度和吞吐,也是部署提速方法之一。
PS:FP16量化一般都是直接转换模型权重从FP32->FP16,不需要校准或者finetune。
量化训练是在模型训练中量化的,与PTQ(训练后量化)不同,这种量化方式对模型的精度影响不大,量化后的模型速度基本与量化前的相同(另一种量化方式PTQ,TensorRT或者NCNN中使用交叉熵进行校准量化的方式,在一些结构中会对模型的精度造成比较大的影响)。
举个例子,我个人CenterNet训练的一个网络,使用ResNet-34作为backbone,利用TensorRT进行转换后,使用1024x1024作为测试图像大小的指标:
| 精度/指标 | FP32 | INT8(PTQ) | INT8(QAT) |
|---|
精度不降反升(可以由于之前FP32的模型训练不够彻底,finetune后精度又提了一些),还是值得一试的。
目前我们常用的Pytorch当然也是支持QAT量化的。
不过Pytorch量化训练出来的模型,官方目前只支持CPU。即X86和Arm,具有INT8指令集的CPU可以使用:
x86 CPUs with AVX2 support or higher (without AVX2 some operations have inefficient implementations)
ARM CPUs (typically found in mobile/embedded devices)
已有很多例子。
那么GPU支持吗?
Pytorch官方不支持,但是NVIDIA支持。
NVIDIA官方提供了Pytorch的量化训练框架包,目前虽然不是很完善,但是已经可以正常使用:
NVIDIA官方提供的pytorch-quantization-toolkit
利用这个量化训练后的模型可以导出为ONNX(需要设置opset为13),导出的ONNX会有QuantizeLinear和DequantizeLinear两个算子:
带有QuantizeLinear和DequantizeLinear算子的ONNX可以通过TensorRT8加载,然后就可以进行量化推理:
Added two new layers to the API: IQuantizeLayer and IDequantizeLayer which can be used to explicitly specify the precision of operations and data buffers. ONNX’s QuantizeLinear and DequantizeLinear operators are mapped to these new layers which enables the support for networks trained using Quantization-Aware Training (QAT) methodology. For more information, refer to the Explicit-Quantization, IQuantizeLayer, and IDequantizeLayer sections in the TensorRT Developer Guide and Q/DQ Fusion in the Best Practices For TensorRT Performance guide.
而TensorRT8版本以下的不支持直接载入,需要手动去赋值MAX阈值。
5
AI部署流程
假设我们的模型是使用Pytorch训练的,部署的平台是英伟达的GPU服务器。
训练好的模型通过以下几种方式转换:
Pytorch->ONNX->trt onnx2trt
Pytorch->trt torch2trt
Pytorch->torchscipt->trt trtorch
其中onnx2trt最成熟,torch2trt比较灵活,而trtorch不是很好用。三种转化方式各有利弊,基本可以覆盖90%常见的主流模型。
遇到不支持的操作,首先考虑是否可以通过其他pytorch算子代替。如果不行,可以考虑TensorRT插件、或者模型拆分为TensorRT+libtorch的结构互相弥补。trtorch最新的commit支持了部分op运行在TensorRT部分op运行在libtorch,但还不是很完善,感兴趣的小伙伴可以关注一下。
常见的服务部署搭配:
triton server + TensorRT/libtorch
flask + Pytorch
Tensorflow Server
本文仅做学术分享,如有侵权,请联系删文。