
【微软】AI-神经网络基本原理简明教程
点击下方卡片,关注“新机器视觉”公众号
视觉/图像重磅干货,第一时间送达
【导读】我们现在有了很多非常厉害的深度学习框架,比如Tensorflow,CNTK,PaddlePaddle,Caffe2等等。然而,这些为了解决实际的应用问题而生的,而不是用来学习“深度学习”知识和思想的。所以微软Xiaowuhu根据自己亲身经历的学习轨迹,归纳出了以下教程,可以帮助小白做到真正的从入门到精通。通过以下循序渐进地学习与动手实践,一方面可以帮助读者深刻理解“深度学习”的基础知识,更好地理解并使用现有框架,另一方面可以助力读者快速学习最新出现的各种神经网络的扩展或者变型,跟上快速发展的AI浪潮。
地址:
https://github.com/microsoft/ai-edu/tree/master/
写在前面,为什么要出这个系列的教程呢?
总的说来,我们现在有了很多非常厉害的深度学习框架,比如Tensorflow,CNTK,PaddlePaddle,Caffe2等等。然而,我们用这些框架在搭建我们自己的深度学习模型的时候,到底做了一些什么样的操作呢?我们试图去阅读框架的源码来理解框架到底帮助我们做了些什么,但是……很难!很难!很难!因为深度学习是需要加速啦,分布式计算啦,框架做了很多很多的优化,也让像我们这样的小白难以理解这些框架的源码。
这取决于你是想真正地掌握“深度学习”的思想,还是只想成为一个调参师?在我们看来,如TensorFlow,CNTK这些伟大的深度学习工具,是为了解决实际的应用问题而生的,而不是用来学习“深度学习”知识和思想的。所以我们根据自己亲身经历的学习轨迹,归纳出了以下教程,可以帮助小白做到真正的从入门到精通。
通过以下循序渐进地学习与动手实践,一方面可以帮助读者深刻理解“深度学习”的基础知识,更好地理解并使用现有框架,另一方面可以助力读者快速学习最新出现的各种神经网络的扩展或者变型,跟上快速发展的AI浪潮。
对于这份教程的内容,如果没有额外的说明,我们通常使用如下表格的命名约定:
| 符号 | 含义 |
|---|---|
| X | 输入样本 |
| Y | 输入样本的标签 |
| Z | 线性运算的结果 |
| A | 激活函数/结果 |
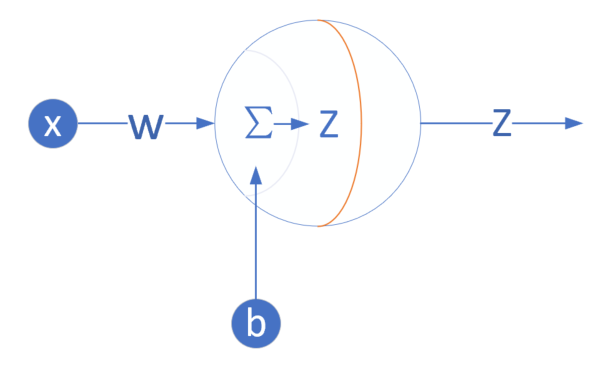
| W | 权重矩阵 |
| B | 偏移矩阵 |
| J | 损失函数 |
| 大写字母 | 矩阵或矢量,如A,W,B |
| 小写字母 | 变量,标量,如a,w,b |
| x1,2 | 第1个样本的第2个特征值 |
| wL2,3 | 第L层第2个神经元对第L-1层第3个神经元的权重值 |
| 矩阵的行 | 一批样本的某一个特征值的集合 |
| 矩阵的列 | 一批样本的某一个样本的所有特征值 |
适用范围
没有各种基础想学习却无从下手哀声叹气的玩家,请按时跟踪最新博客,推导数学公式,跑通代码,并及时提出问题,以求最高疗效;
深度学习小白,有直观的人工智能的认识,强烈的学习欲望和需求,请在博客的基础上配合代码食用,效果更佳;
调参师,训练过模型,调过参数,想了解框架内各层运算过程,给玄学的调参之路添加一点心理保障;
超级高手,提出您宝贵的意见,给广大初学者指出一条明路!
前期准备
环境:
Windows 10 version 1809
Visual Studio 2017 Community or above
Python 3.6.6
Jupyter Notebook (可选)
自己:
清醒的头脑(困了的同学请自觉泡茶),纸和笔(如果想跟着推公式的话),闹钟(防止久坐按时起来转转),厚厚的衣服(有暖气的同学请忽略)
网络结构概览
| 网络结构名称 | 网络结构图 | 应用领域 |
|---|---|---|
| 单入 单出 一层 |
| 一元线性回归 |
| 多入 单出 一层 |
| 多元线性回归 |
| 多入 单出 一层 |
| 线性二分类 |
| 多入 多出 一层 |
| 线性多分类 |
| 单入 单出 两层 |
| 一元非线性回归/拟合 可以拟合任意复杂函数 |
| 多入 单出 两层 |
| 非线性二分类 |
| 多入 多出 两层 |
| 非线性多分类 |
| 多入 多出 三层 |
| 非线性多分类 |
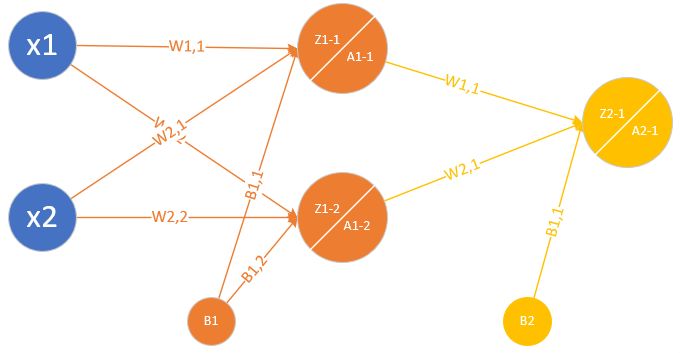
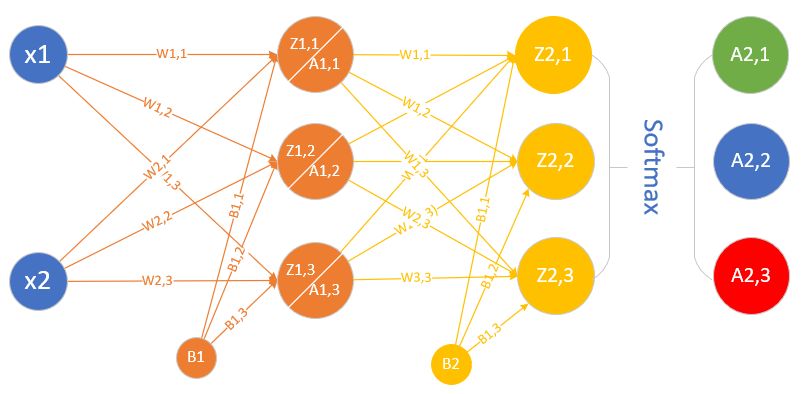
目录
1. 基本概念
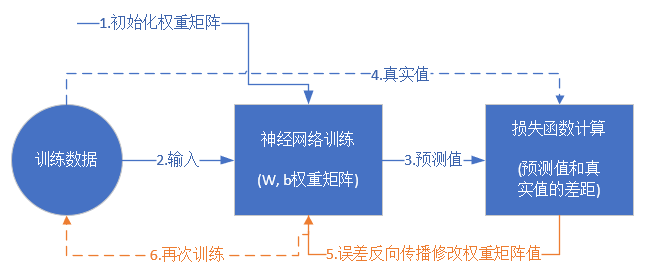
首先会讲解一下神经网络基本的训练和工作原理,因为基本上各种教程里都没有提到这一点,以至于笔者在刚开始学习神经网络时一头雾水,不得要领,不知从何处开始下手。
后面接的是导数公式和反向传播公式,包括矩阵求导,这一部分可以大概浏览一下,主要的目的是备查,在自己推导反向公式时可以参考。
然后是反向传播和梯度下降,我们先从简单的线性方式说起(只有加法和乘法),而且用代入数值的方式来消除对公式的恐惧心理。然后会说到分层的复杂(非线性)函数的反向传播,同样用数值代入方式手推反向过程。
梯度下降是神经网络的基本学习方法,我们会用单变量和双变量两种方式说明,配以可视化的图解。再多的变量就无法用可视化方式来解释了,所以我们力求用简单的方式理解复杂的事物。
本部分最后是损失函数的讲解,着重说明了神经网络中目前最常用的均方差损失函数(用于回归)和交叉熵损失函数(用于分类)。
2. 线性回归
用线性回归作为学习神经网络的起点,是一个非常好的选择,因为线性回归问题本身比较容易理解,在它的基础上,逐步的增加一些新的知识点,会形成一条比较平缓的学习曲线,或者说是迈向神经网络的第一个小台阶。
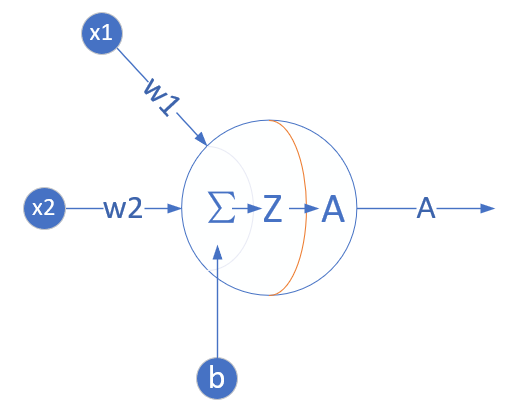
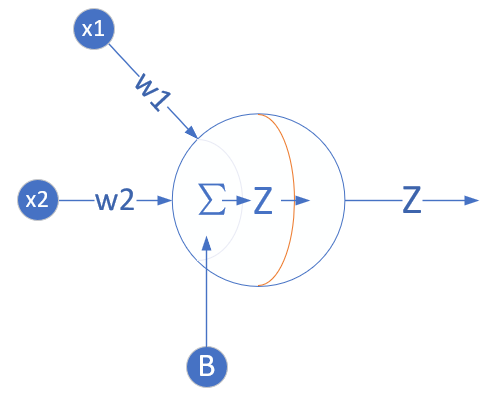
单层的神经网络,其实就是一个神经元,可以完成一些线性的工作,比如拟合一条直线,这用一个神经元就可以实现。当这个神经元只接收一个输入时,就是单变量线性回归,可以在二维平面上用可视化方法理解。当接收多个变量输入时,叫做多变量线性回归,此时可视化方法理解就比较困难了,通常我们会用变量两两组对的方式来表现。
当变量多于一个时,两个变量的量纲和数值有可能差别很大,这种情况下,我们通常需要对样本特征数据做归一化,然后把数据喂给神经网络进行训练,否则会出现“消化不良”的情况。
3. 线性分类
分类问题在很多资料中都称之为逻辑回归,Logistic Regression,其原因是使用了线性回归中的线性模型,加上一个Logistic二分类函数,共同构造了一个分类器。我们在本书中统称之为分类。
神经网络的一个重要功能就是分类,现实世界中的分类任务复杂多样,但万变不离其宗,我们都可以用同一种模式的神经网络来处理。
本部分中,我们从最简单的线性二分类开始学习,包括其原理,实现,训练过程,推理过程等等,并且以可视化的方式来帮助大家更好地理解这些过程。
在第二步中,我们学习了实现逻辑非门,在本部分中,我们将利用学到的二分类知识,实现逻辑与门、与非门,或门,或非门。
做二分类时,我们一般用Sigmoid函数做分类函数,那么和Sigmoid函数长得特别像的双曲正切函数能不能做分类函数呢?我们将会探索这件事情,从而对分类函数、损失函数、样本标签有更深的理解。
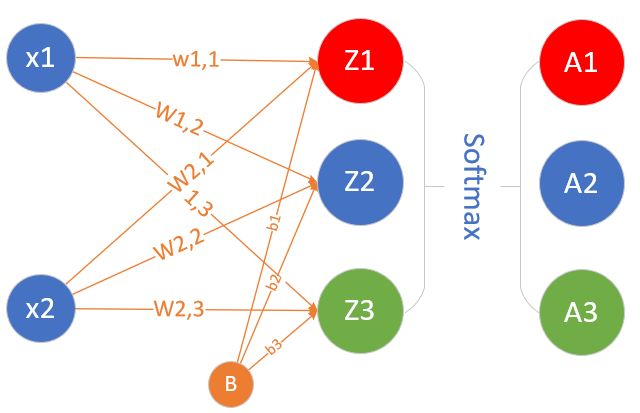
然后我们将进入线性多分类的学习。多分类时,可以一对一、一对多、多对多,那么神经网络使用的是哪种方式呢?
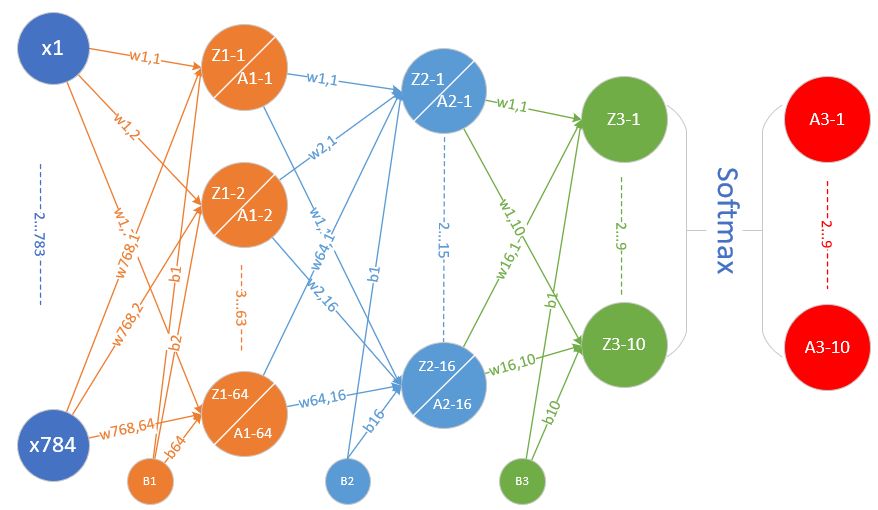
Softmax函数是多分类问题的分类函数,通过对它的分析,我们学习多分类的原理、实现、以及可视化结果,从而理解神经网络的工作方式。
4. 非线性回归
从这一步开始,我们进入了两层神经网络的学习,从而解决非线性问题。
在两层神经网络之间,必须有激活函数连接,从而加入非线性因素,提高神经网络的能力。所以,我们先从激活函数学起,一类是挤压型的激活函数,常用于简单网络的学习;另一类是半线性的激活函数,常用于深度网络的学习。
接下来我们将验证著名的万能近似定理,建立一个双层的神经网络,来拟合一个比较复杂的函数。
在上面的双层神经网络中,已经出现了很多的超参,都会影响到神经网络的训练结果。所以在完成了基本的拟合任务之后,我们将会尝试着调试这些参数,得到更好的训练效果(又快又好),从而得到超参调试的第一手经验。
。

5. 非线性分类
我们在第三步中学习了线性分类,在本部分中,我们将学习更复杂的分类问题,比如,在很多年前,两位著名的学者证明了感知机无法解决逻辑中的异或问题,从而使感知机这个研究领域陷入了长期的停滞。我们将会在使用双层网络解决异或问题。
异或问题是个简单的二分类问题,因为毕竟只有4个样本数据,我们会用更复杂的数据样本来学习非线性多分类问题,并理解其工作原理。
然后我们将会用一个稍微复杂些的二分类例子,来说明在二维平面上,神经网络是通过怎样的神奇的线性变换加激活函数预算,把线性不可分的问题转化为线性可分问题的。
解决完二分类问题,我们将学习如何解决更复杂的三分类问题,由于样本的复杂性,必须在隐层使用多个神经元才能完成分类任务。
最后我们将搭建一个三层神经网络,来解决MNIST手写数字识别问题,并学习使用梯度检查来帮助我们测试反向传播代码的正确性。
数据集的使用,是深度学习的一个基本技能,开发集、验证集、测试集,合理地使用才能得到理想的泛化能力强的模型。
6. 模型推理与部署
我们已经用神经网络训练出来了一套权重矩阵,但是这个模型如何使用呢?我们总不能在实际生产环境中使用python代码来做推理吧?更何况在手机中也是不能运行Python代码的。
这就引出了模型的概念。一个模型会记录神经网络的计算图,并加载权重矩阵,而这些模型会用C++等代码来实现,以保证部署的便利。
我们将会学习到在Windows上使用ONNX模型的方法,然后是在Android上的模型部署方法。而在iOS设备上的模型,与Android的原理相同,有需要的话可以自己找资料学习。我们也许会考虑以后增加这部分内容。
7. 深度神经网络
在前面的几步中,我们用简单的案例,逐步学习了众多的知识,使得我们可以更轻松地接触深度学习。
从这一部分开始,探讨深度学习的一些细节,如权重矩阵初始化、梯度下降优化算法、批量归一化等高级知识。
由于深度网络的学习能力强的特点,会造成网络对样本数据过分拟合,从而造成泛化能力不足,因为我们需要一些手段来改善网络的泛化能力。
8. 卷积神经网络
卷积神经网络是深度学习中的一个里程碑式的技术,有了这个技术,才会让计算机有能力理解图片和视频信息,才会有计算机视觉的众多应用。
在本部分的学习中,我们将会逐步介绍卷积的前向计算、卷积的反向传播、池化的前向计算与反向传播,然后用代码实现一个卷积网络并训练一些实际数据。
在后面我们还会介绍一些经典的卷积模型,向大师们学习一些解决问题的方法论问题。
声明:部分内容来源于网络,仅供读者学习、交流之目的。文章版权归原作者所有。如有不妥,请联系删除。
—THE END—