
Redis简明教程
本文公众号来源:柳树的絮叨叨
作者:SexyCode
Redis是啥?用Redis官方的话来说就是:
Redis is an open source (BSD licensed), in-memory data structure store, used as a database, cache and message broker.
Redis是一个开源的、基于内存的数据结构存储器,可以用作数据库、缓存和消息中间件。
What??? 这玩意把数据放在内存,还想当数据库使?为什么是“data structure store”,而不是“data store”?还能用作消息中间件??你这么牛,你咋不上天?
是的,Redis就是这么牛 ( ̄▽ ̄)~*
我们只需从Redis最常用的功能——缓存,开始了解,上面那些问题也就迎刃而解了。
1、你会怎样实现一个缓存?如果你是Redis新手,或者此前从未接触过Redis,那么这篇文章不仅能帮你快速了解Redis的实现原理,还能帮你了解一些架构设计的艺术;如果你是Redis老司机,那么,希望这篇文章能带给你一些新的东西。
假设让你设计一个缓存,你会怎么做?
相信大家都会想到用Map来实现,就像这样:
String value = map.get("someKey");
if(null == value) {
value = queryValueFromDB("someKey");
}
那用什么Map呢?HashMap、TreeMap这些都线程不安全,那就用HashTable或者ConcurrentHashMap好了。
不管你用什么样的Map,它的背后都是key-value的Hash表结构,目的就是为了实现O(1)复杂度的查找算法,Redis也是这样实现的,另一个常用的缓存框架Memcached也是。
Hash表的数据结构是怎样的呢?相信很多人都知道,这里简单画个图: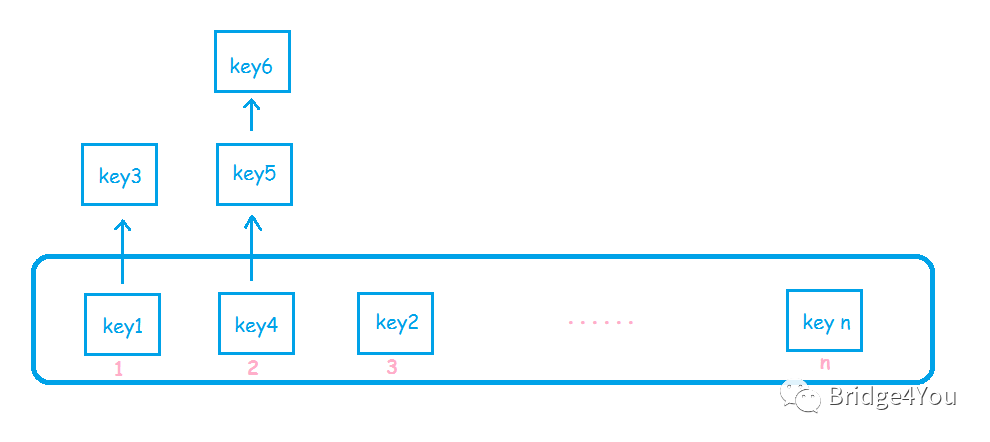
简单说,Hash表就是一个数组,而这个数组的元素,是一个链表。
为什么元素是链表?理论上,如果我们的数组可以做成无限大,那么每来一个key,我们都可以把它放到一个新的位置。但是这样很明显不可行,数组越大,占用的内存就越大。
所以我们需要限制数组的大小,假设是16,那么计算出key的hash值后,对16取模,得出一个0~15的数,然后放到数组对应的位置上去。
好,现在key1放到index为2的位置,突然又来了一个key9,刚好他也要放到index为2的位置,那咋办,总不能把人家key1给踢掉吧?所以key1的信息必须存储在一个链表结构里面,这样key9来了之后,只需要把key1所在的链表节点的next,指向key9的链表节点即可。
这样就没问题了吗?想象一下,如果链表越来越长,会有什么问题?
很明显,链表越长,Hash表的查询、插入、删除等操作的性能都会下降,极端情况下,如果全部元素都放到了一个链表里头,复杂度就会降为O(n),也就和顺序查找算法无异了。(正因如此,Java8里头的HashMap在元素增长到一定程度时会从链表转成一颗红黑树,来减缓查找性能的下降)
怎么解决?rehash。
关于rehash,这里就不细讲了,大家可以先了解一下Java HashMap的resize函数,然后再通过这篇文章:A little internal on redis key value storage implementation 去了解Redis的rehash算法,你会惊讶的发现Redis里头居然是两个HashTable。
好,上面带大家从一个及其微观的角度窥视了Redis,下面几个小节,再带大家用宏观的视角去观察Redis。
2、C/S架构作为Redis用户,我们要怎样把数据放到上面提到的Hash表里呢?
我们可以通过Redis的命令行,当然也可以通过各种语言的Redis API,在代码里面对Hash表进行操作,这些都是Redis客户端(Client),而Hash表所在的是Redis服务端(Server),也就是说Redis其实是一个C/S架构。
显然,Client和Server可以是在一台机器上的,也可以不在: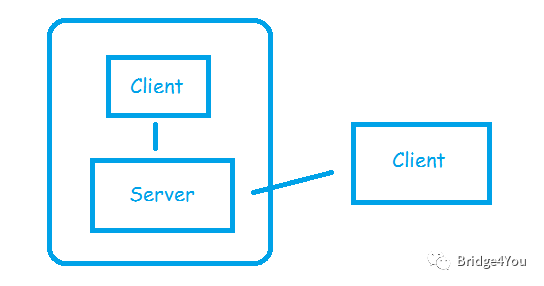
如果你想玩一下Redis,又不想自己搭建环境,可以试一下这一个非常好玩的网页:Try Redis,你可以按照上面的提示,熟悉Redis的基础命令,感受一下Redis的C/S模式。
值得一提的是,Redis的Server是单线程服务器,基于Event-Loop模式来处理Client的请求,这一点和NodeJS很相似。使用单线程的好处包括:
不必考虑线程安全问题。很多操作都不必加锁,既简化了开发,又提高了性能;
减少线程切换损耗的时间。线程一多,CPU在线程之间切来切去是非常耗时的,单线程服务器则没有了这个烦恼;
当然,单线程服务器最大的问题自然是无法充分利用多处理器,不过没关系,别忘了现在的机器很便宜。请继续往下看。
3、集群好,现在我们已经知道了Redis是一个C/S架构的框架,那就让我们开始用Redis来缓存信息,缓解数据库的压力吧!
我们搭起了这样一个框架,一台客户端,一台Redis缓存服务器: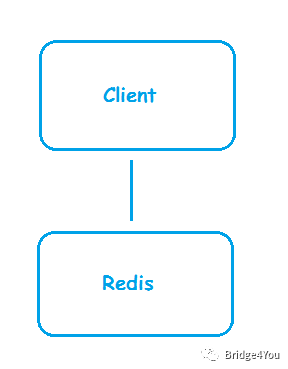
一开始风和日丽,系统运行良好。
后来,我们系统中使用Redis的客户端越来越多,变成了这样: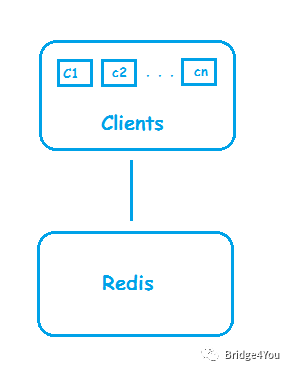
这带来了两个问题:
Redis内存不足:随着使用Redis的客户端越来越多,Redis上的缓存数据也越来越大,而一台机器的内存毕竟是有限的,放不了那么多数据;
Redis吞吐量低:客户端变多了,可Redis还是只有一台,而且我们已经知道,Redis是单线程的!这就好比我开了一家饭店,一开始每天只有100位客人,我雇一位服务员就可以,后来生意好了,每天有1000位客人,可我还是只雇一位服务员。一台机器的带宽和处理器都是有限的,Redis自然会忙不过来,吞吐量已经不足以支撑我们越来越庞大的系统。
分析完问题,解决思路也就再清晰不过了——集群。一台Redis不够,那就再加多几台!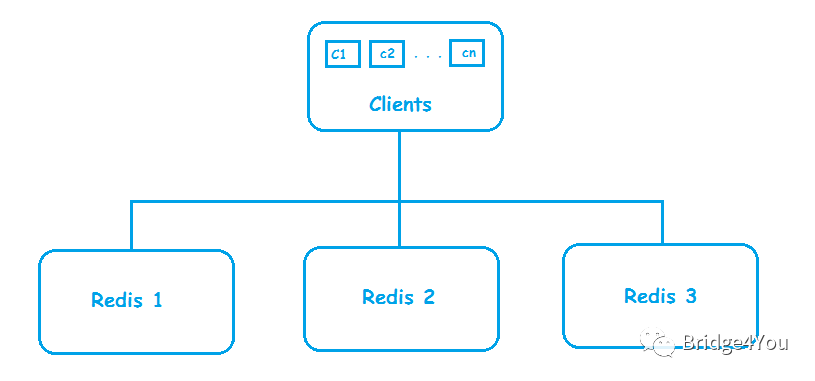
客户端的请求会通过负载均衡算法(通常是一致性Hash),分散到各个Redis服务器上。
通过集群,我们实现了两个特性:
扩大缓存容量;
提升吞吐量;
解决了上面提到的两个问题。
4、主从复制好,现在我们已经把Redis升级到了集群,真可谓效果杠杠的,可运行了一段时间后,运维又过来反馈了两个问题:
数据可用性差:如果其中一台Redis挂了,那么上面全部的缓存数据都会丢失,导致原来可以从缓存中获取的请求,都去访问数据库了,数据库压力陡增。
数据查询缓慢:监测发现,每天有一段时间,Redis 1的访问量非常高,而且大多数请求都是去查一个相同的缓存数据,导致Redis 1非常忙碌,吞吐量不足以支撑这个高的查询负载。
问题分析完,要想解决可用性问题,我们第一个想到的,就是数据库里头经常用到的Master-Slave模式,于是,我们给每一台Redis都加上了一台Slave: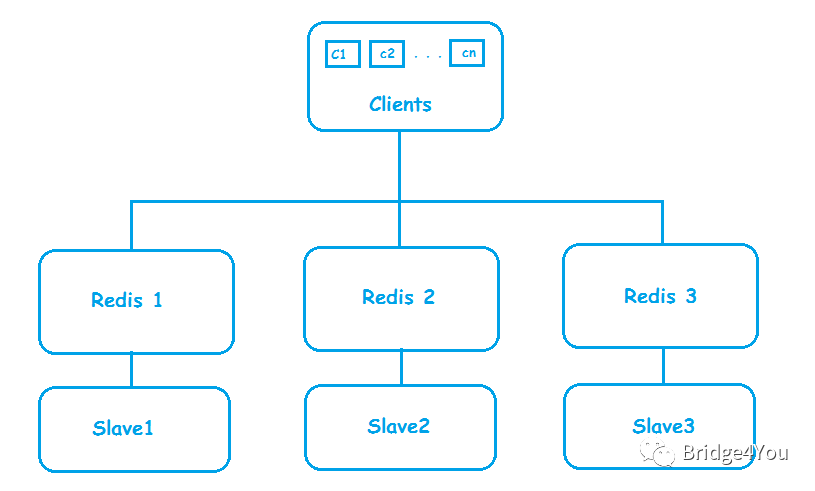
通过Master-Slave模式,我们又实现了两个特性:
数据高可用:Master负责接收客户端的写入请求,将数据写到Master后,同步给Slave,实现数据备份。一旦Master挂了,可以将Slave提拔为Master;
提高查询效率:一旦Master发现自己忙不过来了,可以把一些查询请求,转发给Slave去处理,也就是Master负责读写或者只负责写,Slave负责读;
为了让Master-Slave模式发挥更大的威力,我们当然可以放更多的Slave,就像这样: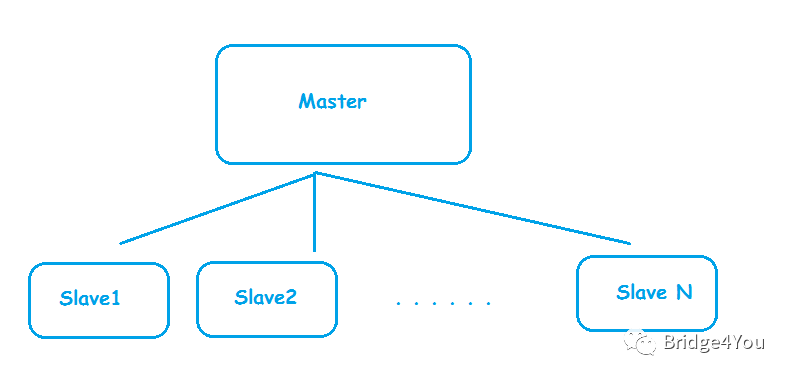
可这样又引发了另一个问题,那就是Master进行数据备份的工作量变大了,Slava每增加一个,Master就要多备份一次,于是又有了Master/slave chains的架构: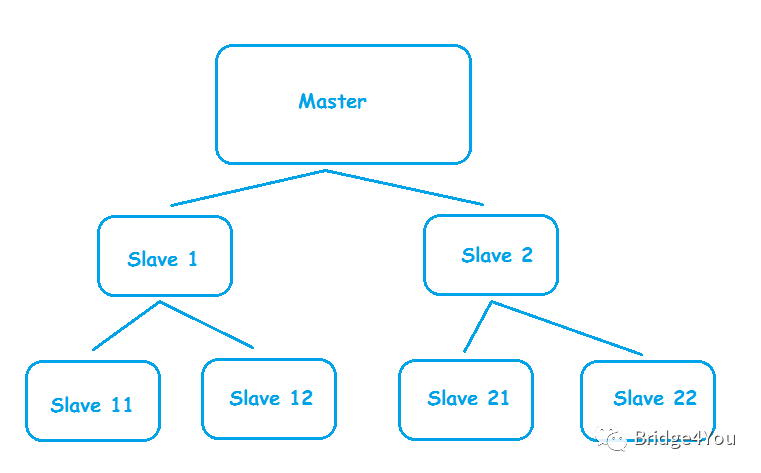
没错,我们让Slave也有自己的Slave,有点像古代的分封制。
这样最顶层的Master的备份压力就没那么大了,它只需要备份两次,然后让那它底下的那两台Slave再去和他们的Slave备份。
5、Redis没那么简单关于Master/slave chains,大家可以参考这篇文章 RedisLab Master/slave chains
这篇文章只是带大家逛一逛Redis的庄园,让大家从微观到宏观,对Redis有一个初步的了解。
事实上,Redis内部要处理的问题还有很多:
数据结构。文章一开头提到了,Redis不仅仅是数据存储器,而是数据结构存储器。那是因为Redis支持客户端直接往里面塞各种类型的数据结构,比如String、List、Set、SortedSet、Map等等。你或许会问,这很了不起吗?我自己在Java里写一个HashTable不也可以放各种数据结构?呵呵,要知道你的HashTable只能放Java对象,人家那可是支持多语言的,不管你的客户端是Java还是Python还是别的,都可以往Redis塞数据结构。这一点也是Redis和Memcached相比,非常不同的一点。当然Redis要支持数据结构存储,是以牺牲更多内存为代价的,正所谓有利必有弊。关于Redis里头的数据结构,大家可以参考:Redis Data Types
剔除策略。缓存数据总不能无限增长吧,总得剔除掉一些数据,好让新的缓存数据放进来吧?这就需要LRU算法了,大家可以参考:Redis Lru Cache
负载均衡。用到了集群,就免不了需要用到负载均衡,用什么负载均衡算法?在哪里使用负载均衡?这点大家可以参考:Redis Partitioning
Presharding。如果一开始只有三台Redis服务器,后来发现需要加多一台才能满足业务需要,要怎么办?Redis提供了一种策略,叫:Presharding
数据持久化。如果我的机器突然全部断电了,我的缓存数据还能恢复吗?Redis说,相信我,可以的,不然我怎么用作数据库?去看看这个:Redis Persistence
数据同步。这篇文章里提到了主从复制,那么Redis是怎么进行主从复制的呢?根据CAP理论,既然我们已经选择了集群,也就是P,分区容忍性,那么剩下那两个,Consistency和Availability只能选择一个了,那么Redis到底是支持最终一致性还是强一致性呢?可以参考:Redis Replication
……
官网:
Redis官网(之所以建议看官网,是因为这是一手的学习资料,其他资料都最多只能算二手,一手资料意味着最权威,准确性最高)
Try Redis(如果你懒得装环境,这或许是一个不错的选择… )
书籍(可以参考):
Redis实战
Redis设计与实现
Redis开发与运维
公众号文章导航:两年呕心沥血的文章!(包含原创Redis文章)
长按扫码可关注获取
在看和分享对我非常重要!