
ggplot2实现分半小提琴图绘制基因表达谱和免疫得分
最近看到很多人问下面这个图怎么绘制,看着确实不错。于是我查了一些资料,这个图叫split violin或者half violin,本质上是一种小提琴图。参考代码在https://gist.github.com/Karel-Kroeze/746685f5613e01ba820a31e57f87ec87
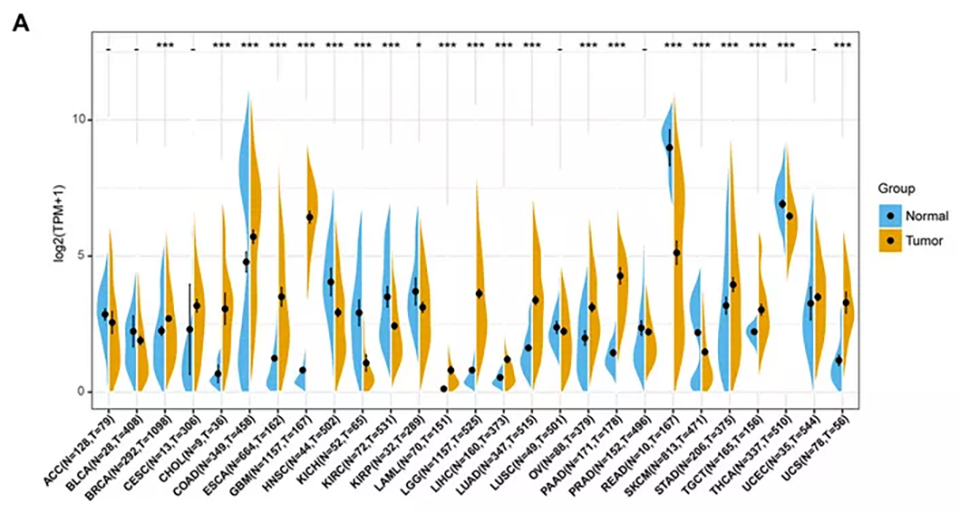
这里利用上期处理好的TCGA
HNSCC的配对数据进行练习,数据包含43个肿瘤样本和43个癌旁样本。
除了基因表达量绘制的结果展示,最后还附带一个ESTIMATE计算免疫评分的例子。此外,计算免疫浸润主流的方法还有Cibersort、ssGSEA等算法,在之后的推文里我会做一些教程介绍。
具体代码如下:
remove(list = ls()) #一键清空
#加载包
library(ggplot2)
library(reshape2)
library(plyr)
suppressMessages(library(ggpubr))
suppressMessages(library(dplyr))读入Deseq2标准化后的表达数据
# 1.1 表达数据
data <- read.csv("./Rawdata/TCGA_HNSCpaired_Norexpr_data_paired.csv",
header = T,row.names = 1, check.names=F)
data[1:3,1:4]
## TCGA.CV.6943.01 TCGA.CV.6959.01 TCGA.CV.7438.11 TCGA.CV.7242.11
## AAAS 10.795406 11.198490 10.864833 10.89324
## AACS 12.033001 11.427610 12.173660 11.37317
## AADAC 4.857712 4.740191 8.864625 11.14658保存为Tab键分割的格式,供estimate包使用。
# 安装ImageGP 包
# library(devtools)
# install_git("https://gitee.com/ct5869/ImageGP.git")
library(ImageGP)
sp_writeTable(data, file="./Rawdata/TCGA_HNSCpaired_Norexpr_data_paired.tsv")筛选要绘制的基因
selected_gene <- c("S100A9","MT-CO2","MT-CO3","MT-CO1","KRT16","S100A8","KRT14","MT-CYB")
data <- data[selected_gene,]读入分组数据
# 1.2 分组数据
phenotype <- read.csv("./Rawdata/TCGA_HNSCpaired.metadata.csv",header = T,row.names = 1,check.names=F, stringsAsFactors = T)
phenotype <- phenotype[,c("group","subject"),drop=F]
head(phenotype)
## group subject
## TCGA.CV.6943.01 Tumor TCGA.CV.6943
## TCGA.CV.6959.01 Tumor TCGA.CV.6959
## TCGA.CV.7438.11 Nontumor TCGA.CV.7438
## TCGA.CV.7242.11 Nontumor TCGA.CV.7242
## TCGA.CV.7432.01 Tumor TCGA.CV.7432
## TCGA.CV.6939.11 Nontumor TCGA.CV.6939绘图数据的格式准备
##
# 2.1 把分组信息加进去
data_new <- data.frame(t(data))
data_new$sample = row.names(data_new)
data_new <- merge(data_new, phenotype,by.x = "sample",by.y = 0)
# 2.2 融合数据
data_new = melt(data_new)
## Using sample, group, subject as id variables
colnames(data_new) = c("sample","group","subject", "gene","expression")
head(data_new)
## sample group subject gene expression
## 1 TCGA.CV.6933.01 Tumor TCGA.CV.6933 S100A9 17.30560
## 2 TCGA.CV.6933.11 Nontumor TCGA.CV.6933 S100A9 10.83050
## 3 TCGA.CV.6934.01 Tumor TCGA.CV.6934 S100A9 13.57274
## 4 TCGA.CV.6934.11 Nontumor TCGA.CV.6934 S100A9 16.36757
## 5 TCGA.CV.6935.01 Tumor TCGA.CV.6935 S100A9 12.29116
## 6 TCGA.CV.6935.11 Nontumor TCGA.CV.6935 S100A9 20.22816加载绘图函数
## 3. 这里加载包装好的2个函数,用于后面的统计和绘图
source("./assist/Function_for_violin_plot.R")计算均值和误差
## 4. 绘图
# 4.1 这里注意到原图用的是误差线,这里用步骤三加载的函数,计算一下误差信息
Data_summary <- summarySE(data_new, measurevar="expression", groupvars=c("group","gene"))
head(Data_summary)
## group gene N expression sd se ci
## 1 Nontumor S100A9 43 18.02898 2.8049172 0.4277459 0.8632261
## 2 Nontumor MT.CO2 43 17.76159 0.8913531 0.1359301 0.2743180
## 3 Nontumor MT.CO3 43 18.18671 0.9300174 0.1418263 0.2862171
## 4 Nontumor MT.CO1 43 19.27698 1.0075457 0.1536493 0.3100768
## 5 Nontumor KRT16 43 15.84541 3.5569291 0.5424266 1.0946612
## 6 Nontumor S100A8 43 17.17403 3.4525920 0.5265153 1.0625510绘制分半小提琴图
# 4.2. 出图
# 这个是我自己写的一个ggplot2的主题,可以自定义修改其中的参数
if(T){
mytheme <- theme(plot.title = element_text(size = 12,color="black",hjust = 0.5),
axis.title = element_text(size = 12,color ="black"),
axis.text = element_text(size= 12,color = "black"),
panel.grid.minor.y = element_blank(),
panel.grid.minor.x = element_blank(),
axis.text.x = element_text(angle = 45, hjust = 1 ),
panel.grid=element_blank(),
legend.position = "top",
legend.text = element_text(size= 12),
legend.title= element_text(size= 12)
)
}
# 自行调整下面的参数
gene_split_violin <- ggplot(data_new,aes(x= gene,y= expression,fill= group))+
geom_split_violin(trim= F,color="white",scale = "area") + #绘制分半的小提琴图
geom_point(data = Data_summary,aes(x= gene, y= expression),pch=19,
position=position_dodge(0.5),size= 1)+ #绘制均值为点图
geom_errorbar(data = Data_summary,aes(ymin = expression-ci, ymax= expression+ci),
width= 0.05,
position= position_dodge(0.5),
color="black",
alpha = 0.8,
size= 0.5) +
scale_fill_manual(values = c("#56B4E9", "#E69F00"))+
labs(y=("Log2 expression"),x=NULL,title = "Split violin") +
theme_bw()+ mytheme +
stat_compare_means(aes(group = group),
label = "p.signif",
method = "anova",
label.y = max(data_new$expression),
hide.ns = T)
gene_split_violin;ggsave(gene_split_violin,
filename = "./Output/gene_split_violin.pdf",
height = 10,width = 16,units = "cm")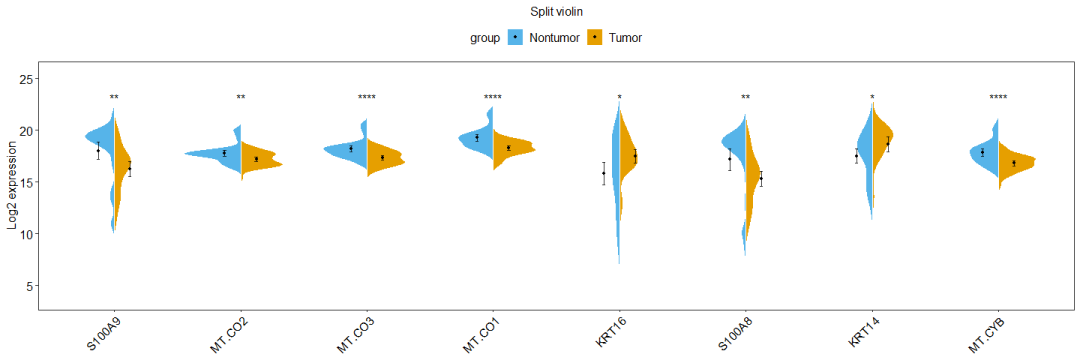
用ESTIMATE算法计算免疫得分
library(estimate)
# eestimate 包安装
# library(utils)
# rforge <- "http://r-forge.r-project.org"
# install.packages("estimate", repos=rforge, dependencies=TRUE)
# 5. ESTIMATE计算免疫得分
# 5.1 输入txt格式的表达矩阵,输出ESIMATE计算结果
filterCommonGenes(input.f= "./Rawdata/TCGA_HNSCpaired_Norexpr_data_paired.tsv",
output.f="./Output/TCGA_estimate.gct", id="GeneSymbol")
## [1] "Merged dataset includes 9219 genes (1193 mismatched)."
estimateScore(input.ds = "./Output/TCGA_estimate.gct",
output.ds = "./Output/TCGA_estimate_score.gct",
platform="illumina")
## [1] "1 gene set: StromalSignature overlap= 135"
## [1] "2 gene set: ImmuneSignature overlap= 139"
ESTI_score <- read.table("./Output/TCGA_estimate_score.gct",skip = 2,header = T,row.names = 1)
ESTI_score <- as.data.frame(t(ESTI_score[2:ncol(ESTI_score)]))
head(ESTI_score)
## StromalScore ImmuneScore ESTIMATEScore
## TCGA.CV.6943.01 906.2923 1649.01369 2555.30599
## TCGA.CV.6959.01 -352.6656 318.22117 -34.44448
## TCGA.CV.7438.11 -1183.4705 276.89782 -906.57268
## TCGA.CV.7242.11 -1067.1461 -47.83809 -1114.98415
## TCGA.CV.7432.01 -1234.5253 -449.47317 -1683.99846
## TCGA.CV.6939.11 424.8381 -674.84391 -250.00579
# 5.2 融合数据
table(row.names(ESTI_score) == rownames(phenotype))
##
## TRUE
## 86
ESTI_score$group <- phenotype$group
ESTI_score$sample <- rownames(ESTI_score)
ESTI_score_New = melt(ESTI_score)
## Using group, sample as id variables
colnames(ESTI_score_New)=c("group","sample","status","score") #设置行名
head(ESTI_score_New)
## group sample status score
## 1 Tumor TCGA.CV.6943.01 StromalScore 906.2923
## 2 Tumor TCGA.CV.6959.01 StromalScore -352.6656
## 3 Nontumor TCGA.CV.7438.11 StromalScore -1183.4705
## 4 Nontumor TCGA.CV.7242.11 StromalScore -1067.1461
## 5 Tumor TCGA.CV.7432.01 StromalScore -1234.5253
## 6 Nontumor TCGA.CV.6939.11 StromalScore 424.8381
# 5.3 计算误差线
ESTI_Data_summary <- summarySE(ESTI_score_New, measurevar="score", groupvars=c("group","status"))
head(ESTI_Data_summary)
## group status N score sd se ci
## 1 Nontumor StromalScore 43 -918.91119 837.0492 127.64881 257.6057
## 2 Nontumor ImmuneScore 43 -210.02121 504.0363 76.86481 155.1195
## 3 Nontumor ESTIMATEScore 43 -1128.93240 1138.1268 173.56271 350.2637
## 4 Tumor StromalScore 43 -517.35577 659.5859 100.58590 202.9906
## 5 Tumor ImmuneScore 43 -67.37634 638.1790 97.32139 196.4025
## 6 Tumor ESTIMATEScore 43 -584.73211 1138.8398 173.67145 350.4832
ESTI_split_violin <- ggplot(ESTI_score_New,aes(x= status,y= score,fill= group))+
geom_split_violin(trim= F,color="white",scale = "area") + #绘制分半的小提琴图
geom_point(data = ESTI_Data_summary,aes(x= status, y= score),pch=19,
position=position_dodge(0.4),size= 1)+ #绘制均值为点图
geom_errorbar(data = ESTI_Data_summary,aes(ymin = score-ci, ymax= score+ci),
width= 0.05,
position= position_dodge(0.4),
color="black",
alpha = 0.8,
size= 0.5) +
scale_fill_manual(values = c("#56B4E9", "#E69F00"))+
labs(y=("ESTIMATE score"),x=NULL,title = "Split violin") +
theme_bw()+ mytheme +
scale_x_discrete(labels=c("Stromal","Immune","ESTIMATE")) +
stat_compare_means(aes(group = group),
label = "p.signif",
method = "wilcox",
label.y = max(ESTI_score_New$score),
hide.ns = T)
ESTI_split_violin; ggsave(ESTI_split_violin,filename = "./Output/ESTIMATE_plot.pdf", height = 10,width = 10,units = "cm")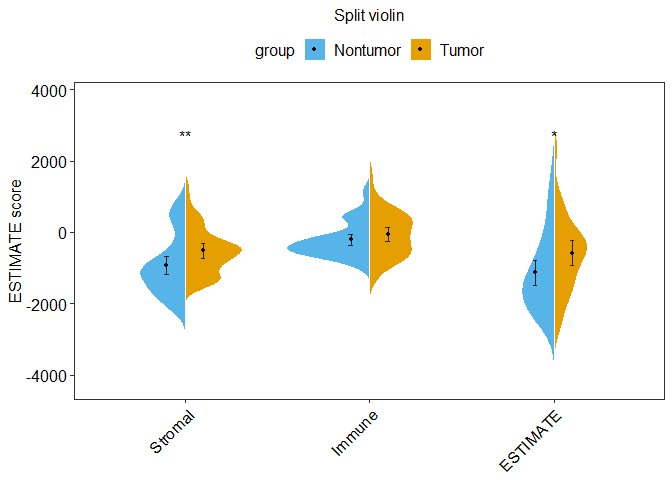
sessionInfo()
## R version 4.0.2 (2020-06-22)
## Platform: x86_64-w64-mingw32/x64 (64-bit)
## Running under: Windows 10 x64 (build 14393)
##
## Matrix products: default
##
## locale:
## [1] LC_COLLATE=Chinese (Simplified)_China.936 LC_CTYPE=Chinese (Simplified)_China.936
## [3] LC_MONETARY=Chinese (Simplified)_China.936 LC_NUMERIC=C
## [5] LC_TIME=Chinese (Simplified)_China.936
##
## attached base packages:
## [1] stats graphics grDevices utils datasets methods base
##
## other attached packages:
## [1] ImageGP_0.1.0 devtools_2.3.0 usethis_1.6.1 dplyr_1.0.0 ggpubr_0.4.0
## [6] estimate_1.0.13 plyr_1.8.6 reshape2_1.4.4 ggplot2_3.3.2
##
## loaded via a namespace (and not attached):
## [1] matrixStats_0.56.0 fs_1.4.2 RColorBrewer_1.1-2 rprojroot_1.3-2
## [5] rstan_2.21.1 tools_4.0.2 backports_1.1.7 R6_2.4.1
## [9] colorspace_1.4-1 withr_2.2.0 tidyselect_1.1.0 gridExtra_2.3
## [13] prettyunits_1.1.1 processx_3.4.3 curl_4.3 compiler_4.0.2
## [17] git2r_0.27.1 cli_2.0.2 desc_1.2.0 labeling_0.3
## [21] scales_1.1.1 callr_3.4.3 stringr_1.4.0 digest_0.6.25
## [25] StanHeaders_2.21.0-5 foreign_0.8-80 rmarkdown_2.3 rio_0.5.16
## [29] htmltools_0.5.1.1 pkgconfig_2.0.3 sessioninfo_1.1.1 rlang_0.4.6
## [33] readxl_1.3.1 rstudioapi_0.11 farver_2.0.3 generics_0.1.0
## [37] jsonlite_1.7.0 zip_2.1.1 car_3.0-8 inline_0.3.15
## [41] magrittr_1.5 loo_2.3.1 Rcpp_1.0.5 munsell_0.5.0
## [45] fansi_0.4.1 abind_1.4-5 lifecycle_0.2.0 stringi_1.4.6
## [49] yaml_2.2.1 carData_3.0-4 pkgbuild_1.1.0 grid_4.0.2
## [53] parallel_4.0.2 forcats_0.5.0 crayon_1.3.4 haven_2.3.1
## [57] hms_0.5.3 knitr_1.29 ps_1.3.3 pillar_1.4.6
## [61] ggsignif_0.6.0 codetools_0.2-16 stats4_4.0.2 pkgload_1.1.0
## [65] glue_1.4.1 evaluate_0.14 V8_3.2.0 data.table_1.14.0
## [69] remotes_2.1.1 BiocManager_1.30.10 RcppParallel_5.0.2 vctrs_0.3.1
## [73] testthat_2.3.2 cellranger_1.1.0 gtable_0.3.0 purrr_0.3.4
## [77] tidyr_1.1.0 assertthat_0.2.1 xfun_0.15 openxlsx_4.1.5
## [81] broom_0.7.0 rstatix_0.6.0 tibble_3.0.2 pheatmap_1.0.12
## [85] memoise_1.1.0 ellipsis_0.3.1参考资料:
《数据可视化——R语言ggplot2包绘制精美的小提琴图》
数据和代码下载:
https://gitee.com/ct5869/shengxin-baodian/tree/master/TCGA
作者:赵法明
编辑:生信宝典
往期精品(点击图片直达文字对应教程)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|



























后台回复“生信宝典福利第一波”或点击阅读原文获取教程合集
评论