
Elasticsearch JVM 堆内存使用率飙升,怎么办?
1、引言
本系列文章介绍如何修复 Elasticsearch 集群的常见错误和问题。
这是系列文章的第四篇,主要探讨:Elasticsearch JVM 堆内存使用率飙升,怎么办?
第一篇:Elasticsearch 磁盘使用率超过警戒水位线,怎么办?
第二篇:Elasitcsearch CPU 使用率突然飙升,怎么办?
2、症状:高 JVM 内存使用率
高 JVM 内存使用率会降低集群性能并触发断路器错误(导致内存熔断)。

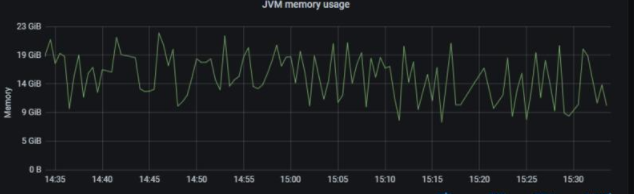
3、诊断 JVM 内存压力
3.1 检查 JVM 内存使用情况
借助:node stats API 进行排查。
GET _nodes/stats?filter_path=nodes.*.jvm.mem.pools.old
召回结果如下:
{
"nodes" : {
"J2-fr3wzSqqJk9cwoi2urw" : {
"jvm" : {
"mem" : {
"pools" : {
"old" : {
"used_in_bytes" : 179796016,
"max_in_bytes" : 1798569984,
"peak_used_in_bytes" : 179796016,
"peak_max_in_bytes" : 1798569984
}
}
}
}
}
}
}
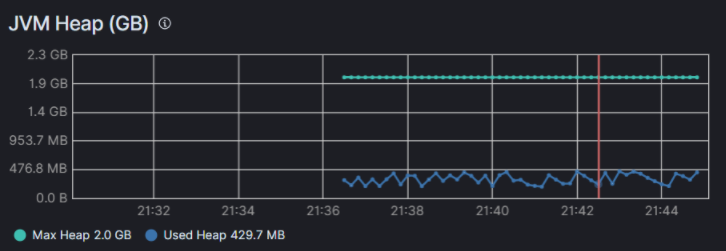
堆内存使用率为:used_in_bytes / max_in_bytes = 179796016/ 1798569984 = 9.99
6%,接近 10%。
能和 kibana 可视化监控结果保持一致:
3.2 垃圾回收日志检查
随着内存使用量的增加,垃圾收集变得更加频繁并且需要更长的时间。
你可以在 elasticsearch.log 中跟踪垃圾收集事件的频率和时长。
例如,以下事件表明 Elasticsearch 在过去 40 秒中花费了超过 50%(21 秒)执行垃圾收集。
[timestamp_short_interval_from_last][INFO ][o.e.m.j.JvmGcMonitorService] [node_id] [gc][number] overhead, spent [21s] collecting in the last [40s]
推荐阅读:你看懂 Elasticsearch Log 中的 GC 日志了吗?
https://elasticsearch.cn/article/812
4、降低JVM 堆内存使用率方案
4.1 减少分片数
关于分片的几点认知:
第一:搜索请求是以分片为单位发起的。
至少 7.16 版本之前是,如下图示更能说明问题。
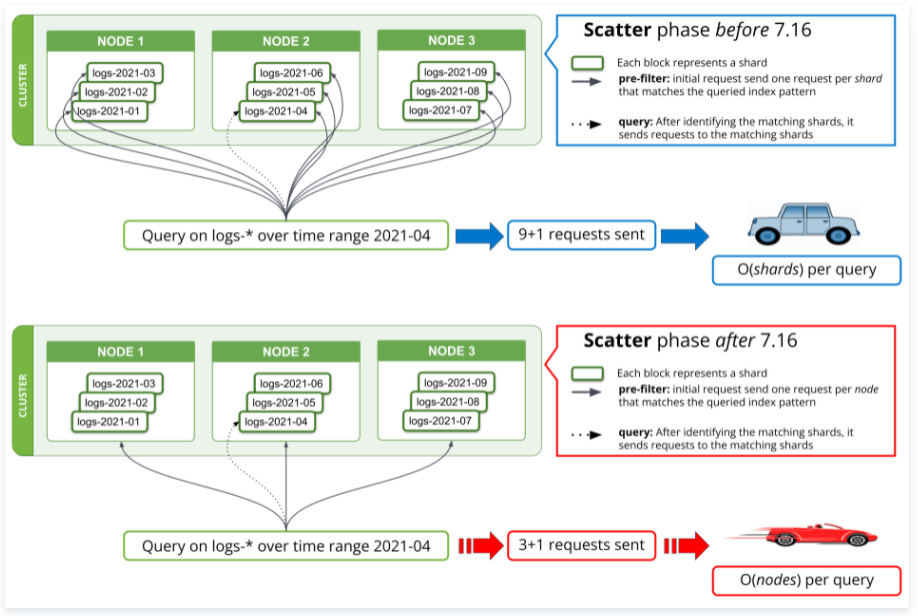
https://www.elastic.co/cn/blog/three-ways-improved-elasticsearch-scalability
这暗示了什么?
必然是:分片越多,检索越慢。
因为:跨大量分片的搜索可能会耗尽节点的搜索线程池,这可能导致吞吐量低和搜索速度慢。
第二:每个索引和分片都有内存和 CPU 开销。
每个索引和每个分片都需要一些内存和 CPU 资源。
在大多数情况下,一小组大分片比许多小分片使用更少的资源。
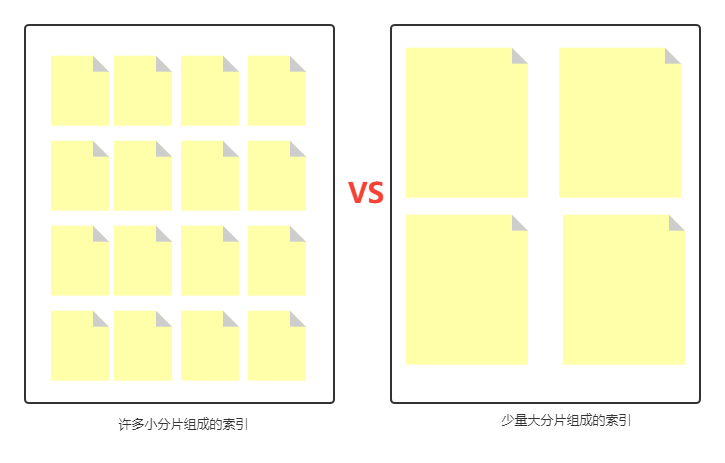
为什么呢?解释一下:
分片的底层是 Lucene 分段。 段的元数据会保留在 JVM 堆内存中,以便快速检索。 分片越多,意味着分段会越多,进而分段元数据会越多,JVM 堆内存使用率会越高。反之,则相反。
第三:Elasticsearch 会在相同角色的节点间平衡分片。
节点角色划分是 7.x 高版本新的节点定义方式,其目的是:节点用途更明确。
当添加新节点或某节点出故障时,Elasticsearch 会自动在相同角色层的剩余节点之间重新平衡索引的分片。
关于减少分片数,更确切的是如何合理规划分片,官方建议如下:
第一:尽量避免 delete_by_query 删除文档,更好的方案是直接删除索引。
Elasticsearch 中为什么会有大量文档插入后变成 deleted?
第二:使用 datastrem 和 ILM 索引生命周期管理管理时序数据。
Elasticsearch 7.X data stream 深入详解
干货 | Elasticsearch 索引生命周期管理 ILM 实战指南
第三:分片大小控制在 10GB-50GB。
另有 30GB-50GB一说,下文有过讨论:
第四:控制在每 GB 堆内存 20 个分片以内。
也就是说:具有 30GB 堆内存的节点最多应该有 600 个分片。
第五:避免单个节点分片过多、负载过重。
如果单个节点包含太多分片,且索引量很大,则该节点可能会出现问题。
可以使用如下命令行加以控制:
PUT my_index_001/_settings
{
"index": {
"routing.allocation.total_shards_per_node": 5
}
}
更多实践推荐阅读:
https://www.elastic.co/guide/en/elasticsearch/reference/current/size-your-shards.html
4.2 避免复杂检索
复杂搜索会占用大量的内存空间。建议启用:慢日志进行排查。
导致内存使用率飙升的复杂查询,通常具备如下的特点:
size 召回值设置的巨大; 包含分桶值很大的聚合操作或者聚合嵌套很深; 包含极其耗费资源的查询,举例:script 查询、fuzzy 查询、regexp 查询、prefix 查询、wildcard 查询、text 或 keyword 上的 range 查询。
为避免复杂查询,常规措施如下:
限制:index.max_result_window 的大小。
PUT _settings
{
"index.max_result_window": 5000
}
设置 search.max_buckets cluster 以限制分桶值大小。
PUT _cluster/settings
{
"persistent": {
"search.max_buckets": 20000,
}
}
设置 search.allow_expensive_queries 直接禁用耗费资源的查询。
PUT _cluster/settings
{
"persistent": {
"search.allow_expensive_queries": false
}
}
4.3 避免 Mapping “爆炸”
定义过多的字段或嵌套过深的字段会导致使用大量内存,出现“Mapping 爆炸" 现象。
为防止“Mapping 爆炸“,使用映射限制设置来限制字段映射的数量。
PUT my_index_001/_settings
{
"index.mapping.total_fields.limit": 100
}
更多类似参数,推荐阅读:
https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-settings-limit.html
4.4 分散批量请求
批量请求虽然比单个请求更有效,但大批量写入(以 bulk 操作为代表)或多搜索请求(以 _msearch 为代表)仍然会产生较高的 JVM 内存压力。
如果可能,提交较小(小是个相对值,需要根据集群性能测算出适合自己集群的经验值)的请求并在它们之间留出更多时间时隔。
4.5 升级节点内存
繁重的写入操作和搜索负载过重均会导致高 JVM 内存压力。
为了更好地处理繁重的工作负载,在其他方法都不灵的情况下,可以考虑通过为节点内存扩容以达到升级节点目的。
这是无法之法,这是万能之法。
5、小结
多了解导致 JVM 飙升的操作,业务开发方面及早避免和规避相关操作,做好前置规划和布局很关键。
做好监控和核心指标的预警工作,“防患于未然”。
你的实际业务场景有没有遇到类似问题,你是怎么解决和避免的?欢迎留言讨论。
参考
1. https://www.elastic.co/guide/en/elasticsearch/reference/current/fix-common-cluster-issues.html
2. https://www.elastic.co/guide/en/elasticsearch/reference/current/size-your-shards.html
推荐
更短时间更快习得更多干货!
和全球近 1600+ Elastic 爱好者一起精进!
