
Node.js 多进程/线程 —— 日志系统架构优化实践
大厂技术 高级前端 Node进阶
点击上方 程序员成长指北,关注公众号
回复1,加入高级Node交流群
1. 背景
在日常的项目中,常常需要在用户侧记录一些关键的行为,以日志的形式存储在用户本地,对日志进行定期上报。这样能够在用户反馈问题时,准确及时的对问题进行定位。
为了保证日志信息传输的安全、缩小日志文件的体积,在实际的日志上传过程中会对日志进行加密和压缩,最后上传由若干个加密文件组成的一个压缩包。
为了更清晰的查看用户的日志信息。需要搭建一个用户日志管理系统,在管理系统中可以清晰的查看用户的日志信息。但是用户上传的都是经过加密和压缩过的文件,所以就需要在用户上传日志后,实时的对用户上传的日志进行解密和解压缩,还原出用户的关键操作。如下图所示,是一个用户基本的使用过程。

但是解密和解压缩都是十分耗时的操作,需要进行大量的计算,在众多用户庞大的日志量的情况下无法立即完成所有的解密操作,所以上传的日志拥有状态。(解密中、解密完成、解密失败等)
一个常见的日志系统架构如下:
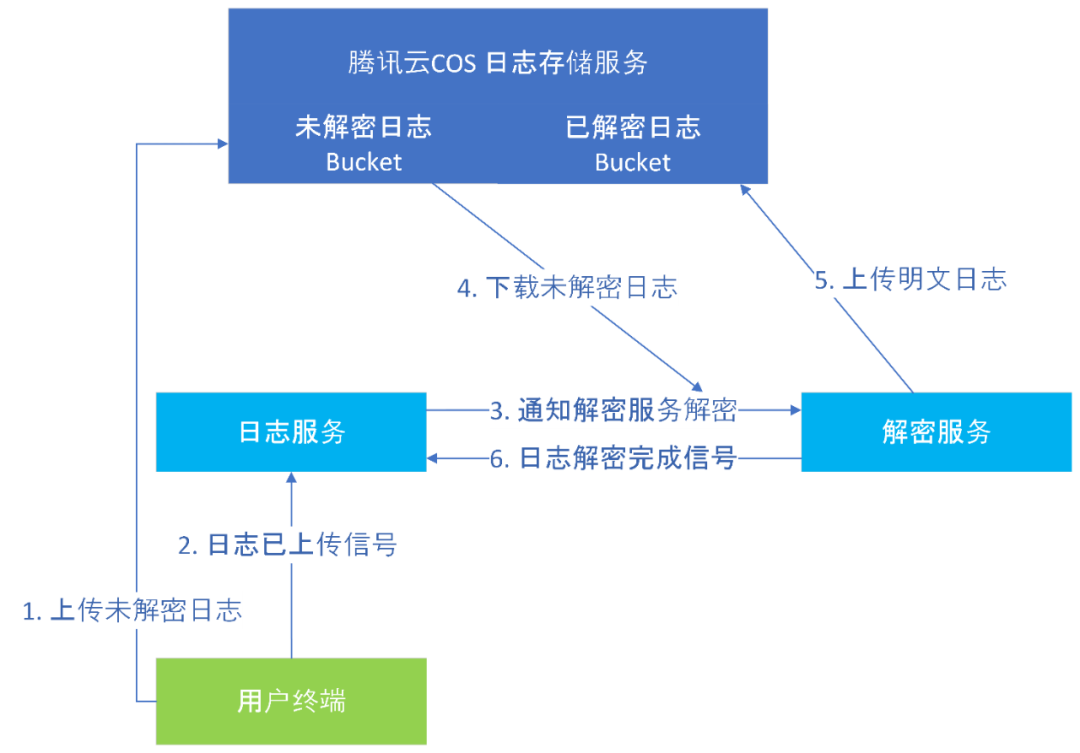
其中按照解密状态的变化,大体分为三个阶段:
用户终端上传日志到 cos 并通知后台日志服务已经上传了日志,后台日志服务记录这条日志,将其状态设置为未解密。
日志服务通知解密服务对刚上传的日志进行解密,收到响应后将日志的状态更改为解密中。
解密服务进行解密,完成后将明文日志上传并通知日志服务已完成解密,日志服务将解密状态更改为解密完成。如果过程中出现错误,则将日志解密状态更改为解密失败。
但是在实际的项目使用过程中,发现系统中有很多问题,具体表现如下:
有些日志在上传很久以后,状态仍然为解密中。
日志会大量解密失败。(只要有一个步骤出现错误,状态就会设置为解密失败)
接下来将以这些问题为线索,对其背后的技术实现进行深入探索。
2. 问题分析
第一个问题是有些日志上传很久之后,状态仍然为解密中。根据表现,可以初步确定问题出现在上述的阶段 3(日志状态已设置为解密中,但并未进行进一步的状态设置),因此,可以判断是解密服务内部出现异常。
解密服务使用 Node.js 实现,整体架构如下:

解密服务 Master 主进程负责进程调度与负载均衡,由它开启多个工作进程(Work Process)处理 cgi 请求,同时它也开启一个解密进程专用于解密操作。下面将着重介绍 Node.js 实现多进程和其通信的方法。
2.1 Node.js 实现多进程
2.1.1 使用多进程的好处
进程是资源分配的最小单位,不同进程之间是隔离开来,内存不共享的,使用多进程将相对复杂且独立的内容分隔开来,能降低代码的复杂度,每个进程只需要关注其具体工作内容即可,降低了程序之间的耦合。并且子进程崩溃不影响主进程的稳定性,能够增加系统的鲁棒性。 进程作为线程的容器,使用多进程也充分享受多线程所带来的好处。在下文会有多线程的详细介绍。
2.1.2 使用多进程的劣势
进程作为资源分配的最小单位,启动一个进程必须分配给它独立的内存地址空间,需要建立众多的数据表来维护它的代码段、堆栈段和数据段,在进程切换时开销很大,速度较为缓慢。除此之外,进程之间的数据不共享,进程之间的数据传输会造成一定的消耗。
因此,在使用多进程时应充分考虑程序的可靠性、运行效率等,创建适量的进程。
2.1.2 Node.js 提供的实现多进程的模块
Node.js 内部通过两个库创建子进程:child_process 和 cluster,下文先介绍 child_process 模块。
child_process 模块提供了四个创建子进程的函数,分别为:spawn、execFile、exec、fork,可以根据实际的需求选用适当的方法,各个函数的区别如下:
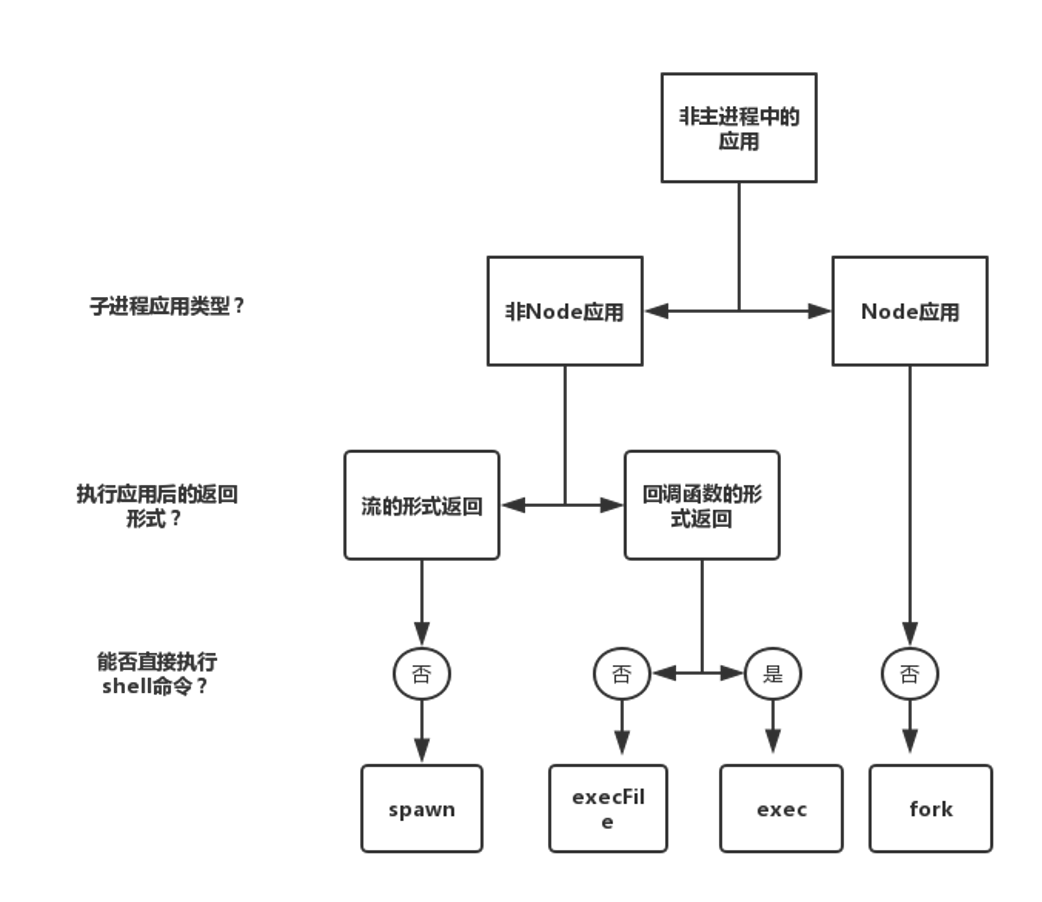
其中 fork 用于开启 Node.js 应用,在 Node.js 中较为常用,其用法如下:

一个简单的 demo 如下:
// demo/parent.js
const ChildProcess = require('child_process');
console.log(`parent pid: ${process.pid}`)
const childProcess = ChildProcess.fork('./child.js');
childProcess.on('message', (msg) => {
console.log("parent received:", msg);
})
// demo/child.js
console.log(`child pid: ${process.pid}`)
setInterval(() => {
process.send(newDate());
}, 2000)
$ cd demo && node parent.js // 在demo目录下执行parent.js文件结果:

在任务管理器(活动监视器)中看到,确实创建了对应 pid 的 Node.js 进程:

2.2 Node.js 实现多进程通信
2.2.1 常见的进程通信方式
试想有以下两个独立的进程,它们通过执行两个 js 文件创建,那么如何在它们之间传递信息呢?
// Process 1
console.log("PID 1:", process.pid);
setInterval(() => { // 保持进程不退出
console.log("PROCESS 1 is alive");
}, 5000)
// Process 2
console.log("PID 2:", process.pid);
setInterval(() => { // 保持进程不退出
console.log("PROCESS 2 is alive");
}, 5000)
接下来介绍几种通信方式:
1. 信号
信号是一种通信机制,程序运行时会接受并处理一系列信号,并且可以发送信号。
1.1 发送信号
可以通过 kill 指令向指定进程发送信号,如下例子表示向 pid 为 3000 的进程发送 USR2 信号(用户自定义信号)
// shell指令,可以直接在命令行中输入
$ kill -USR2 30001.2 接收信号
定义 process 在指定信号事件时,执行处理函数即可接收并处理信号。在收到未定义处理函数的信号时进程会直接退出
// javascript
process.on('SIGUSR2', () => {
console.log("接收到了信号USR2");
}
1.3 示例
// Receiver
console.log("PID", process.pid);
setInterval(() => {
console.log("PROCESS 1 is alive");
}, 5000)
process.on('SIGUSR2', () => {
console.log("收到了USR2信号");
})
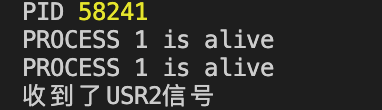
假设 Receiver 执行之后的 pid 为 58241,则:
// Sender
const ChildProcess = require('child_process');
console.log("PID", process.pid);
setInterval(() => {
console.log("PROCESS 2 is alive");
}, 5000)
const result = ChildProcess.execSync('kill -USR2 58241');
在运行 Sender 后,Receiver 成功收到信号,实现了进程间的通信。同样的方式,Receiver 也可以向 Sender 发送信号。
2. 套接字通信
通过在接受方和发送方之间建立 socket 连接实现全双工通信,例如在两者间建立 TCP 连接:
// Server
const net = require('net');
let server = net.createServer((client) => {
client.on('data', (msg) => {
console.log("ONCE", String(msg));
client.write('server send message');
})
})
server.listen(8087);
// Client
const net = require('net');
const client = new net.Socket();
client.connect('8087', '127.0.0.1');
client.on('data', data =>console.log(String(data)));
client.write('client send message');
创建 server 和 client 进程后成功发送并接收消息,分别输出以下内容:
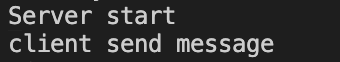
3. 共享内存
在两个进程之间共享部分内存段,两个进程都可以访问,可用于进程之间的通信。Node.js 中暂无原生的共享内存方式,可通过使用 cpp 扩展模块实现,实现较为复杂,在此不再举例。
4. 命名管道
命名管道可以在不相关的进程之间和不同的计算机之间使用,建立命名管道时给他指定一个名字,任何进程都可以使用名字将其打开,根据给定权限进行通信。
例如我们创建一个命名管道,通过它在 server 和 client 之间传输信息,例如 server 向 client 发送消息:
// shell
$ mkfifo /tmp/nfifo
// Server
const fs = require('fs');
fs.writeFile('/tmp/tmpipe', 'info to send', (data, err) =>console.log(data, err));
// Client
const fs = require('fs');
fs.readFile('/tmp/tmpipe', (err, data) => {
console.log(err, String(data));
})
先创建命名管道 /tmp/nfifo 后运行 client,与读取一般的文件不同,读取一般的文件会直接返回结果,而读取 fifo 则会等待,在 fifo 有数据写入时返回结果,然后开启 server,server 向 fifo 中写入信息,client 将收到信息,并打印结果,如下所示:


5. 匿名管道
匿名管道与命名管道类似,但是它是在调用 pipe 函数生成匿名管道后返回一个读端和一个写端,而不具备名字,没有具名管道灵活,在此不做过多介绍。
2.2.2 Node.js 原生的通信方式
原生的 Node.js 在 windows 中使用命名管道实现,在 * nix 系统采用 unix domain socket(套接字)实现,它们都可以实现全双工通信,Node.js 对这些底层实现进行了封装,表现在应用层上的进程间通信,只有简单的 message 事件和 send () 方法,例如父子进程发送消息:
// 主进程 process.js
const fork = require('child_process').fork;
const worker = fork('./child_process.js');
worker.send('start');
worker.on('message', (msg) => {
console.log(`SERVER RECEIVED: ${msg}`)
})
// 子进程 child_process.js
process.on('message', (msg) => {
console.log("CLIENT RECEIVED", msg)
process.send('done');
});
2.2.3 兄弟进程之间通信的实现
Node.js 创建进程时便实现了其进程间通信,但这种方式只能够用于父子进程之间的通信,而不能在兄弟进程之间通信,若要利用原生的方式实现兄弟进程之间的通信,则需要借助它们公共的父进程,发送消息的子进程将消息发送给父进程,然后父进程收到消息时将消息转发给接收消息的进程。但是使用这种方式进行进程间的通信经过父进程的转发效率低下,所以我们可以根据 Node.js 原生的进程间通信方式实现兄弟进程的通信:在 windows 上使用命名管道,在 * nix 上使用 unix 域套接字,该方法与上文套接字通信类似,只是这里不是监听一个端口,而是使用一个文件。
// Server
const net = require('net');
let server = net.createServer(() => {
console.log("Server start");
})
server.on('connection', (client) => {
client.on('data', (msg) => {
console.log(String(msg));
client.write('server send message');
})
})
server.listen('/tmp/unix.sock');
// Client
const net = require('net');
const client = new net.Socket();
client.connect('/tmp/unix.sock');
client.on('data', data =>console.log(String(data)));
client.write('client send message');
启动 server 后会在指定路径创建文件,用于 ipc 通信。
2.2.4 本案例中的问题分析
本项目中通过一个 requestManager 实现兄弟进程之间的通信,set 方法用于设定当指定序列号收到消息时执行的回调函数。
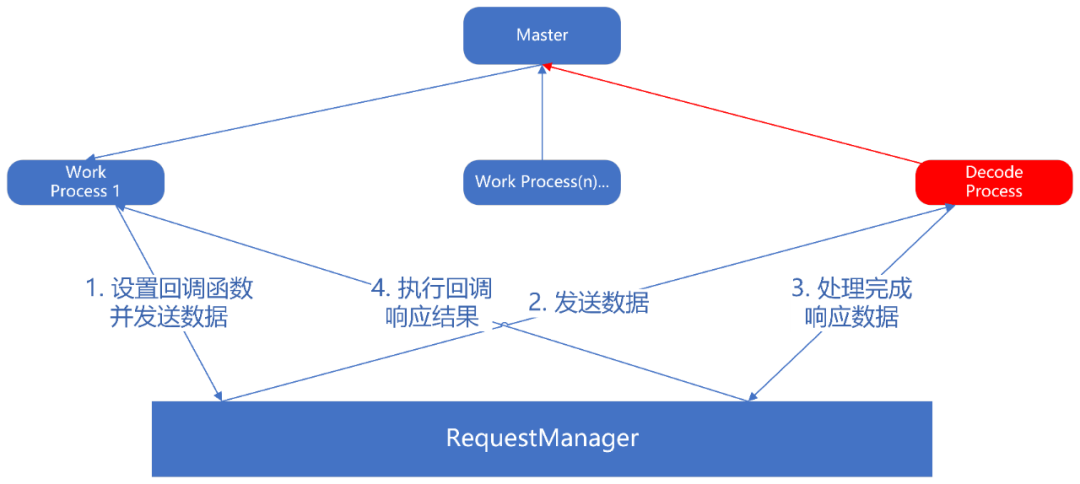
在本项目中过程如下:
1 和 2 流程:

3 流程:
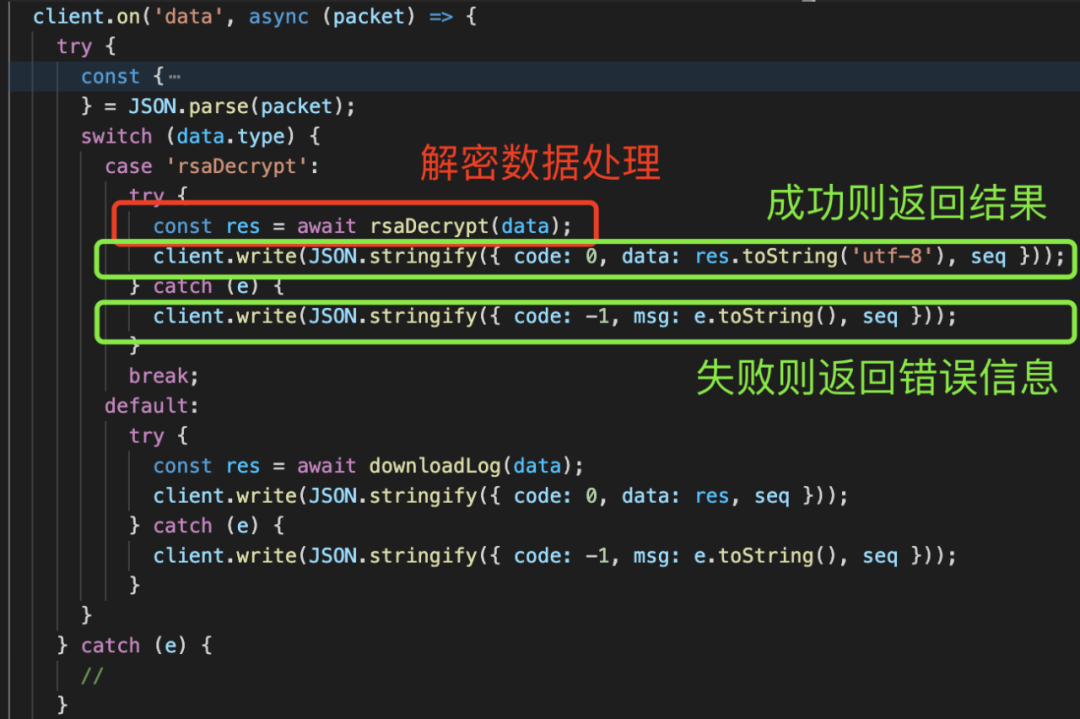
解密数据处理片段:
而本项目的第一个问题,就出现在这里:程序在返回结果时,调用了 res.toString 方法,在出现异常时调用 e.toString 方法获取异常字符串,而实际中项目抛出的异常可能为空异常 null,null 不具有 toString 方法,所以向客户端写入数据失败,导致了解密状态的更新没有触发。
提示:在处理异常时,返回的异常信息一般情况下应该能描述具体的异常,而不应该返回空值;其次,可以使用 String (e) 代替 e.toString (),并且不应该在捕获到异常时静默处理。
2.3 “粘包” 问题的解决
在解决完上述的问题后,发现 bug 并没有完全解决,于是发现了另一个问题:接收端每次接受的数据并不一定是发送的单条数据,而可能是多条数据的合体。当发送端只发送单条 JSON 数据时,服务端 JSON.parse 单条数据顺利处理消息;然而,当接收端同时接受多条消息时,便会出现错误,最终造成进程间通信超时:
Uncaught SyntaxError: Unexpected token { inJSON2.3.1 “粘包” 问题的出现原因
由于 TCP 协议是面向字节流的,为了减少网络中报文的数量,默认采取 Nagle 算法进行优化,当向缓冲区写入数据后不会立即将缓冲区的数据发送出去,而可能在写入多条数据后将数据一同发送出去,所以接收端收到的消息可能是多条数据的组合体。除此之外,也有可能是发送端一次发送一条数据,但是接收端没有及时读取,导致后续一次读取多条消息。
2.3.1 “粘包” 问题的解决办法
“粘包” 问题的根本原因就在于传输的数据边界不明确,因此确定数据边界即可。
可以通过在发送的消息前指定消息的长度大小,服务端读取指定长度大小的数据。
除此之外,还能够制定消息的起始和结束符号,起始符和结束符中间的内容即为一条消息。
2.4 异常的处理
在本项目中,解密会大量失败,而大量失败的原因是进程间通信失败,查看具体原因后发现是解密进程已经退出,导致大量的失败。接下来将探讨 Node.js 进程退出的原因和其解决办法。
2.4.1 Node.js 进程退出的原因
在实际 Node.js 进程使用中,如果异常处理不当,会造成进程的退出,使服务不可用。Node.js 退出的原因有以下几种:
Node.js 事件循环不再需要执行任何额外的工作,这是一种最常见的进程退出原因,当运行一个 js 文件时,发现文件执行完成之后,进程会自动退出,其原因就是因为事件循环不需要执行额外的工作。阻止此类进程退出可以不断在事件循环中添加事件,如使用 setInterval 方法定时添加任务。
显式调用
process.exit()方法,该方法可接受一个参数,表示返回代码,代码为 0 表示正常退出,否则为异常。未捕获的异常, 未捕获的异常会导致进程退出并打印错误信息。使用
process.setUncaughtExceptionCaptureCallback(fn)可以在有未捕获异常时调用 fn,防止进程的退出。未兑现的承诺,未捕获的
Promise.reject在高版本的 Node.js(v15 以后)会导致进程的退出,而在低版本不会。未监听的错误事件,
new EventEmitter().emit('error')若没有监听 error 事件则会导致进程退出,处理方法同未捕获的异常未处理的信号,在向进程发送信号时,若没有设置监听函数,则进程会退出。
$ kill -USR2 <程序中输出的pid>
2.4.2 处理异常的方式
对于上述造成 Node.js 退出的原因,都有其解决办法。
Node.js 事件循环不再需要执行任何额外的工作,可以在事件循环中定时添加任务,例如
setInterval会定时添加任务,阻止进程退出。显示调用
process.exit()方法,在程序中非必要情况下,不要调用 exit 方法。未捕获的异常,使用
try { ... } catch (e) { }对异常进行捕获,并且可以设置process.setUncaughtExceptionCaptureCallback(fn)可以在有未捕获异常时调用 fn,防止进程的退出,作为兜底策略。未兑现的承诺,在 promise 后调用
.catch方法或者设置process.on('unhandledRejection', fn),防止进程退出,作为兜底策略。未监听的错误事件,在触发 'error' 事件前,可以通过
EventEmitter.listenerCount方法查看其监听器的个数,如果没有监听器,则使用其它策略提示错误。未处理的信号,对于信号量,设置监听函数
process.on('信号量', fn)监听其信号量的接受,防止进程退出。
2.4.3 异常对于 Promise 状态的影响
process.on('uncaughtException', err =>console.log(err));
let pro = newPromise((resolve, reject) => {
thrownewError('error');
});
setInterval(() =>console.log(pro), 1000);
这种情况这个 promise 的状态如何呢?在 promise 内部既没有调用 resolve 方法,也没有调用 reject 方法。那么 promise 的状态为 pending 吗?
-- 答案是否定的,在 promise 内部抛出异常,会立即将 promise 的状态更改为 reject,而不会使 promise 的状态始终为 pending。
那么又有另外一个问题,如果当前不捕获异常的情况下,这里使用那个事件捕获异常呢?
unhandledRejection?uncaughtException?
答案是都可以,这个异常会先由 unhandledRejection 的 handler 处理,如果该事件未定义则由 uncaughtException 的 handler 处理,如果两个事件都未定义则会提示错误并终止进程,具体原因在此处不作过多讨论。
2.5 Node.js 多线程
由于需要进行大量的解密和解压缩操作,在本项目中的解密进程中,创建了多个线程,接下来将对 Node.js 多线程做详细的介绍。
2.5.1 使用多线程的好处
前文已经提到过,进程是资源分配的最小单位,使用多进程能够将关联很小的部分隔离开来,使其各自关注自己的职责。
而线程则是 CPU 调度的最小单位,使用多线程能够充分利用 CPU 的多核特性,在每一个核心中执行一个线程,多线程并发执行,提高 CPU 的利用率,适合用于计算密集型任务。
2.5.2 Node.js 提供的实现多线程的模块
在 Node.js 中,内置了用于实现多线程的模块 worker_threads ,该模块提供了如下方法 / 变量:
isMainThread:当线程不运行在 Worker 线程中时,为 true。Worker类:代表独立的 javascript 执行线程:
parentPort:用于父子线程之间的信息传输:// 子线程 -> 父线程
// 子线程中
const { parentPort } = require('worker_threads');
parentPort.postMessage(`msg`);
// 父线程中
const { Worker } = require('worker_threads');
const worker = new Worker('filepath');
worker.on('message', (msg) => { console.log(msg) });// 父线程 -> 子线程
// 父线程中
const { Worker } = require('worker_threads');
const worker = new Worker('filepath');
worker.postMessage(`msg`);
// 子线程中
const { parentPort } = require('worker_threads');
parentPort.on('message', (msg) =>console.log(msg));
2.5.3 单线程、多线程、多进程的比较
接下来,将使用单线程、多线程、多进程完成相同的操作。
// 单线程
console.time('timer');
let j;
for(let i = 0;i<6e9;i++) {
Math.random();
}
console.timeEnd('timer');
// 多线程
// 主线程 thread.js
console.time('timer');
const { Worker, isMainThread } = require('worker_threads')
let cnt = 15;
for(let i = 0;i<15;i++) {
const worker = new Worker('./worker.js');
worker.postMessage('start');
worker.on('message', () => {
if(--cnt === 0) {
console.timeEnd('timer');
process.exit(0);
}
})
}
// 工作线程 worker.js
const { parentPort, isMainThread } = require('worker_threads');
parentPort.on('message', () => {
for(let i = 0;i<1e9;i++) {
Math.random();
}
parentPort.postMessage('done');
})
// 多进程
// 主进程 process.js
console.time('timer');
const fork = require('child_process').fork;
let cnt = 15;
for(let i = 0;i<15;i++) {
const worker = fork('./child_process.js');
worker.send('start');
worker.on('message', () => {
if(--cnt === 0) {
console.timeEnd('timer');
process.exit(0);
}
})
}
// 子进程 child_process.js
process.on('message', () => {
for(let i = 0;i<1e9;i++) {
Math.random();
}
process.send('done');
});
实际运行结果如下(测试机为 8 核 CPU):
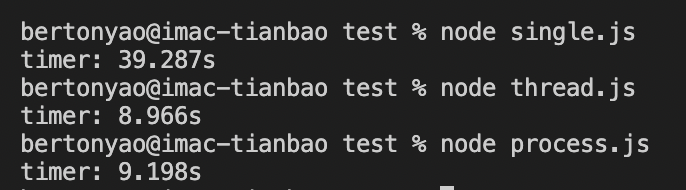
分别为单个线程、6 个线程、6 个进程的运行结果,(在多次实验后)结果有以下规律:
多线程 <多进程 < 单线程 < (多线程 / 多进程) * 6
其原因如下:
多线程:由于充分利用 CPU,所以执行的最快。
多进程:由于每个进程中都有一个线程,同样能充分利用 CPU,但是进程创建的开销要比线程大,所以执行的略慢于多线程。
单线程:由于 CPU 利用不充分所以慢于多线程和多进程,但是由于多线程 / 多进程的创建需要一定的开销,所以快于单个线程执行时间 * 线程个数。
结果与预期一致。
2.5.2 本案例中线程池的问题
在本系统中,实现了一个线程池,它能够在线程持续空闲的时候将线程退出,它会在线程创建时监听它的退出事件。
worker.on('exit', () => {
// 找到该线程对应的数据结构,然后删除该线程的数据结构
const position = this.workerQueue.findIndex(({worker}) => {
return worker.threadId === threadId;
});
const exitedThread = this.workerQueue.splice(position, 1);
// 退出时状态是BUSY说明还在处理任务(非正常退出)
this.totalWork -= exitedThread.state === THREAD_STATE.BUSY ? 1 : 0;
});
当线程一段时间内都是空闲时,调用线程的 terminate 方法,将其退出。然而,这段代码中的问题是,线程在调用 terminate 函数退出后,其 threadId 自动重置为 - 1,所以这段代码并不会在线程池中将其移除,而由于 splice (-1, 1) 会将线程池中的最后一个线程移出。这样,当线程池分配任务时,会分配给已经退出的线程,而已经退出的线程不具备处理任务的能力,因此造成进程间通信超时。
2.6 内存泄漏问题的处理
在实际的应用中一个服务端项目往往都会持续运行很长时间,Node.js 会自动对没有引用的变量所占用的内存进行回收,但是还有很多内存泄漏的问题,系统并不能够自动对其进行处理,例如使用对象作为缓存,在对象上不断添加数据,而不对无用的缓存做清除,则会导致这个对象占用的内存越来越大,直到达到内存分配的最大限度后进程自动退出。下文将介绍如何分析内存泄漏问题。
2.6.1 内存快照分析
分析内存泄漏问题最基本的方式是通过内存快照,在 Node.js 中可以通过 heapdump 库获取内存快照,内存快照可以用于查看内存的具体占用情况。
const heapdump = require('heapdump');
const A = { // 4587
b: { // 4585
c: { // 4583
d: newArray(1e7),
}
}
}
heapdump.writeSnapshot();
例如在 Chrome 调试工具中查看内存快照:
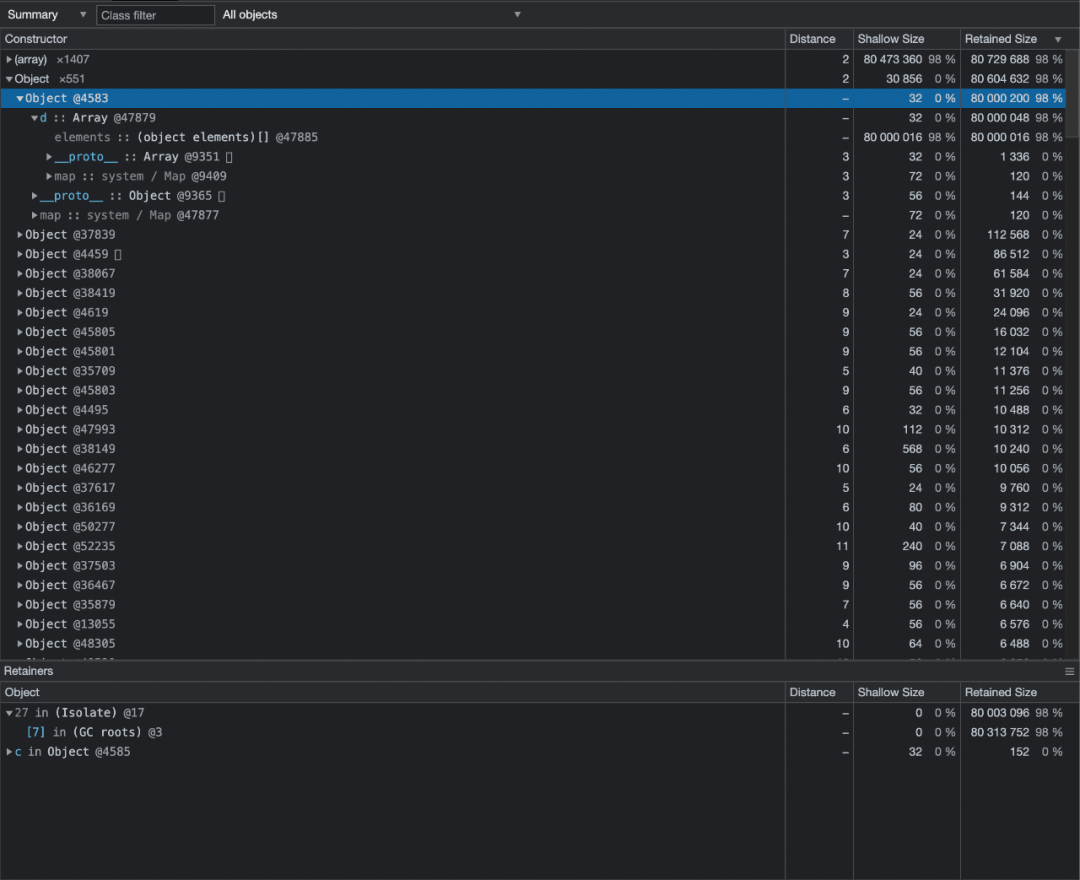
在 Summary 快照总览中可以看到内存分配的详细信息。
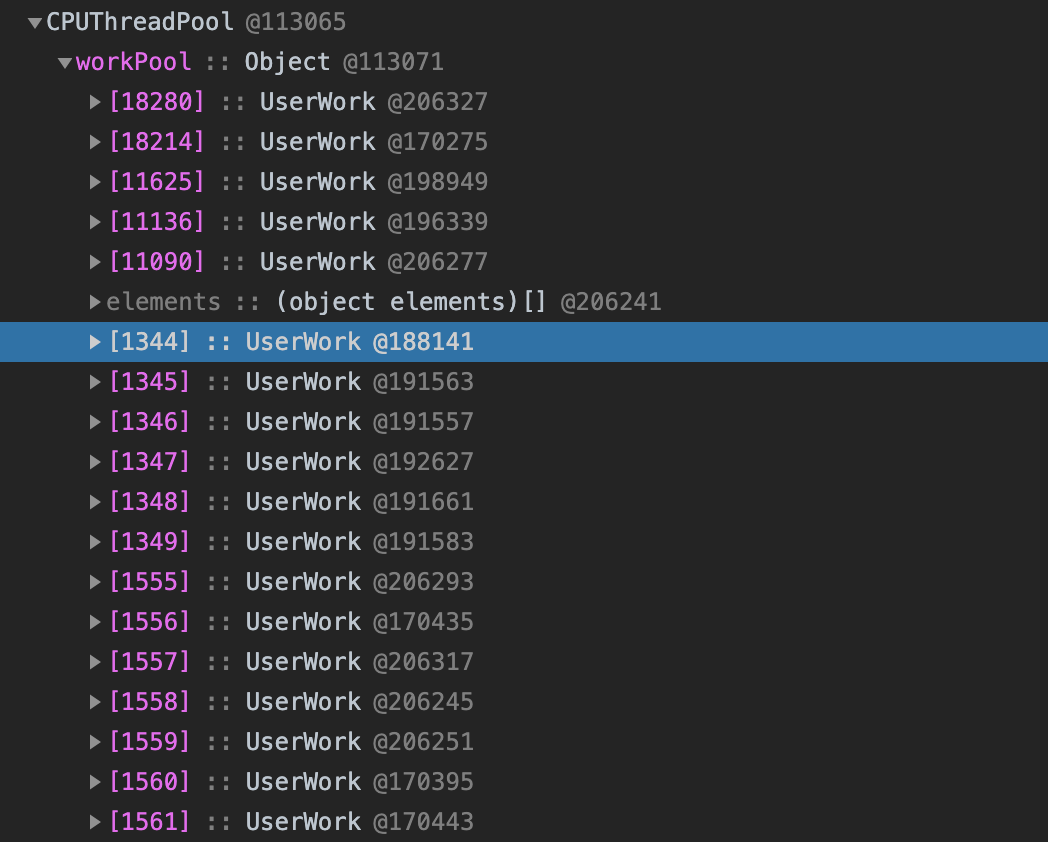
第一列是 Constructor 构造函数,表示该内存的对象由该构造函数创建,()包裹的部分为内置的底层构造函数,后方的 x1407 表示有 1407 个实例通过该构造函数创建,下方 Object @4583 表示该 Object 实例的唯一内存标识为 4583,下方 d::Array 表示其内部的键为 d 的值为一个 Array 类型的数据;
第二列为 Distance,距离顶层 GCroot 的距离,例如直接在全局作用域中的变量。
第三列为 Shallow Size,表示其自身真实占用的内存大小。
第四列为 Retained Size,表示与其关联的内存大小,此处和此处可释放的子节点占用的内存总和。
从上图可以看出,标记为 4583 的对象,它的键为 d 的数组下真实分配了 80 000 016 字节大小的数据,占总堆分配的数据的 98%,点击它查看详情,可以看到它以 c 这个键存在于标记为 4585 对象下,查看 4585 对象可以看到,它以 b 这个键存在于标记为 4587 的对象下:
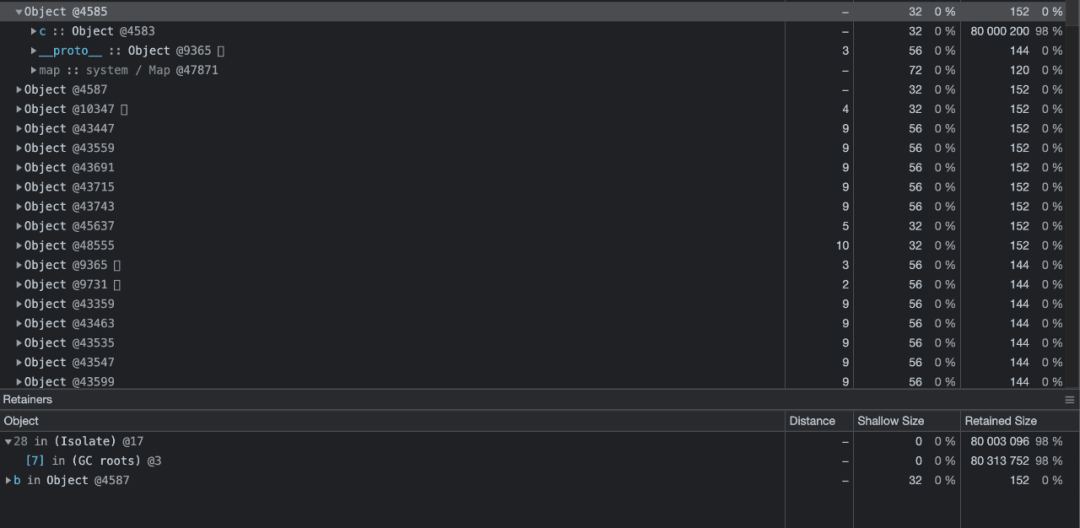
查看标记为 4587 的对象可以看到,它直接存在于垃圾回收根节点上 GCRoot,与代码完全对应,相关对应关系如下:
const A = { // 4587
b: { // 4585
c: { // 4583
d: e,
}
}
}
2.6.2 本案例中的内存泄漏问题
在本案例中,也发现其一些任务始终存在于内存中,下图为时间间隔为一天后内存的占用量,可以看出内存占用量提升的非常快,
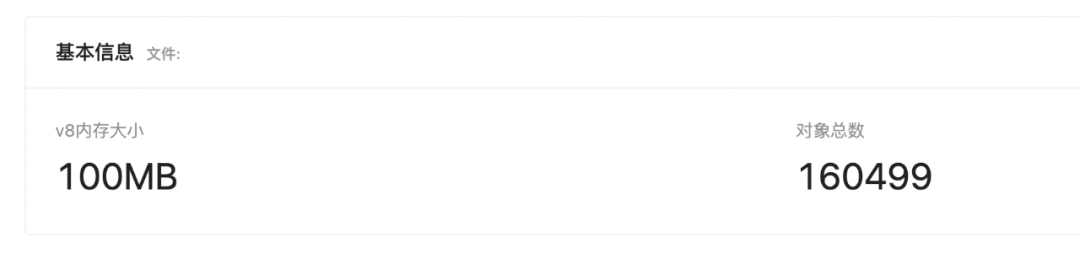
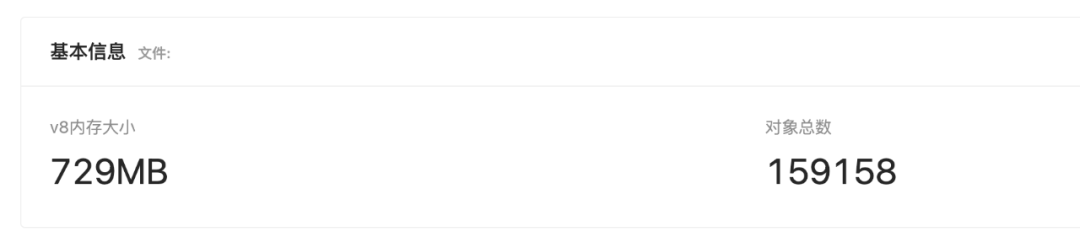
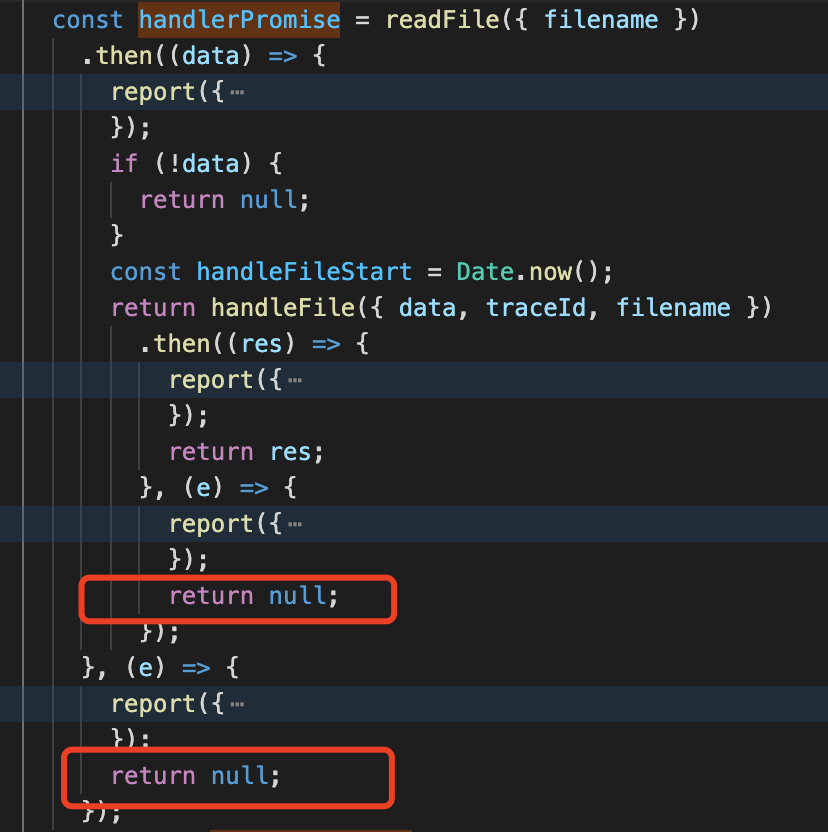
查看其内存占用后发现是线程池中部分任务,由于进程间通信超时,始终没有得到释放,解决进程间通信超时问题,并且设置一个 timeout 超时释放即可。
2.7 npm 包发布流程
在一个大型项目中,往往需要用到多方面的技术,如果各方面内容的实现都放在一起,会比较杂乱,耦合度高,难以阅读和维护。因此,需要对程序的模块进行划分,对每一个模块进行良好的设计,让每一个模块都各司其职,最后组成整个程序。
在本项目中的 nodejs-i-p-c 进程间通信库,nodejs-threadpool 线程池均以包的形式发布到了 npm 上。接下来将介绍基本的 npm 包发布流程。
注册 npm 账号(https://www.npmjs.com/) 在 npm 官网使用邮箱注册账号,需要注意的是 npm 官网登录只能使用用户名 + 密码登录,而不能使用邮箱 + 密码登录!
初始化本地 npm 包。在一个本地的空文件夹中运行
npm init指令,创建一个 npm 仓库,仓库的名称即为将要发布的包的名称。(package.json 文件中的 name 字段)登录 npm 账号 在本地命令行中运行
npm login指令即可进行登录操作,在输入用户名、密码、邮箱后即可完成,登录成功则会提示Logged in asnpm whoami 指令可以查看当前登录的账户。on https://registry.npmjs.org/. 在(2)中初始化的仓库中运行
npm publish即可快速发布当前包 如果发布失败,可能是因为包名重复,提示没有权限发布该包,需要更改包名重新发布。使用
npm view验证包发布,如果出现该包的详细信息则说明包发布成功了!
在包发布成功之后其他人都能够访问到该包,通过 npm i 即可安装您发布的包使用啦。
3. 成果展示
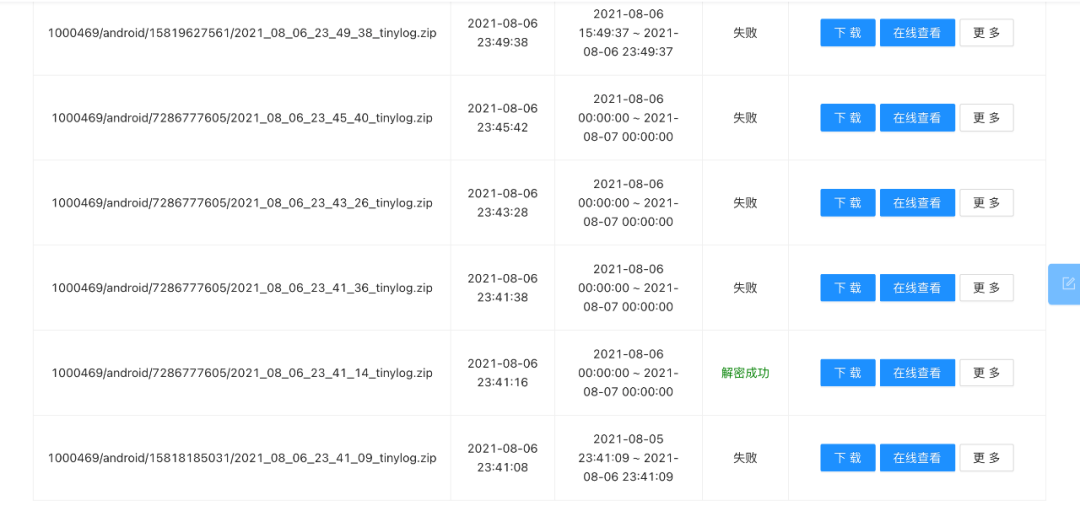
处理前:日志解密大量失败,一些日志持续停留在解密中状态

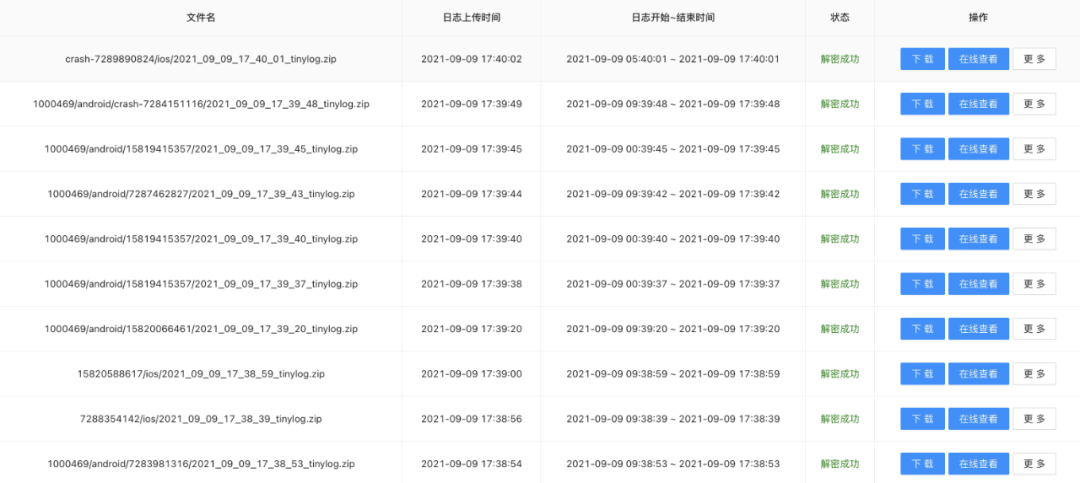
处理后:解密全部成功,无其它异常。
我组建了一个氛围特别好的 Node.js 社群,里面有很多 Node.js小伙伴,如果你对Node.js学习感兴趣的话(后续有计划也可以),我们可以一起进行Node.js相关的交流、学习、共建。下方加 考拉 好友回复「Node」即可。
“分享、点赞、在看” 支持一波👍
