
多应用项目开发架构和多进程间构建优化分析
(给前端大学加星标,提升前端技能.)
作者:Lucas HC
https://zhuanlan.zhihu.com/p/15941922
随着业务复杂度的上升,前端项目不管是从代码量上,还是从依赖关系上都会爆炸式增长。对于单页面应用或者多应用项目来说,各个应用之间的关系也会更加复杂,多个应用之间如何配合,如何维护相互关系?公共库版本如何管理?如何兼顾开发体验和上线构建效率?这些话题随着前端业务的发展,逐渐浮出水面。
这篇文章我就以一个成熟的大型项目为例,从其中一个优化点延伸,谈一谈前端现代化开发和架构设计方式的思考和经验。当然,每一种风格的项目组织方式都各有特点,如何在这些不同架构下,打造顺畅的开发构建流程,持续优化提效是一个非常值得深入的话题。
多项目应用开发架构设计
对于一个大型复杂的业务,如果我们将所有业务逻辑开发放在同一个 Git 仓库下,那么长久以往会导致项目臃肿不堪,难以维护。针对于此,历史上我们习惯将这个“超级 Git 仓库”,分散成多个小的 Git 仓库,一个项目拆分成多个应用。但是这样的做法并没有解决多个应用之间的耦合和公共逻辑的重复。甚至极端的场景下,如果应用之间具有强关联,这样的多仓库设计势必造成开发调试和上线的痛苦。
针对上述背景,目前更加现代化的前端管理风格和架构设计主要有两种(基于 Git submodule 能力的方案不再本文考虑范围之内):
基于 Webpack 多入口的项目拆分和多应用打包构建
基于 Monorepo 风格的项目设计
这两种解决方案都保留了这个唯一的“超级 Git 仓库”,但是它们的设计思想却有不同。我们可以简单理解为:
「基于 Webpack 多入口的项目拆分和多应用打包构建」更加适合于业务应用项目,在多项目内聚的前提下,保证了开发和调试的便利性,同时可以拆分构建和打包流程,显著提高效率
「基于 Monorepo 风格的项目组织」似乎更加适合库的编写,使用 Lerna 这种工具的 Monorepo 方案带有鲜明的发版能力和强烈的工程库风格。这种模式下,依然具有上述提到的开发和调试便利性,构建和打包的原子性,可谓「你喜欢的样子我都有」
这两种解决方案的原理和实现这里我不再赘述,感兴趣的读者可以订阅频道,后续我会详细解析,而本篇将会继续从另一种角度来持续深入。
Monorepo VS Multirepo
由于下文涉及到的场景采用了 Monorepo 风格的管理方式,且这是我个人非常推崇的方案,因此这里我稍微介绍一下相关概念。对于相关概念已经有过了解的读者,可以直接跳过这部分,进行下部分的阅读。
现代管理和组织代码的方式主要分为两种:
Multirepo
Monorepo
顾名思义,Multirepo 就是将应用按照模块分别管理在不同的仓库中;而 Monorepo 就是将应用中所有的模块全部一股脑放在同一个项目中,不再需要在单独发包、测试,且所有代码都在一个项目中管理,在开发阶段能够更早地复现 bugs,暴露问题,更方便进行调试。
这是项目代码在组织上的不同哲学:一种倡导分而治之,一种倡导集中管理。究竟是把鸡蛋放在同一个篮子里,还是倡导多元化,这就要根据团队的风格以及面临的实际场景进行选型。
我试图从 Multirepo 和 Monorepo 两种处理方式的各自弊端说起,希望给读者更多的参考和建议。
对于 Multirepo,存在以下问题:
开发调试以及版本更新效率低下
团队技术选型分散,有可能不同的库实现风格存在较大差异
Changelog 梳理困难,issue 管理混乱(对于开源库来说)
而 Monorepo 缺点也非常明显:
库体积超大,目录结构复杂度上升
需要使用维护 Monorepo 的工具,这就意味着学习成本
社区上的经典选型案例:
Babel 和 React 都是典型的 Monorepo
他们的 issue 和 pull request 都集中到唯一的项目中,changelog 可以简单地从一份 commit 列表梳理出来。我们参看 React 项目仓库,从其目录结构即可看出其强烈的 Monorepo 风格:
react-16.2.0/
packages/
react/
react-art/
react-.../
因此,react 和 react-dom 在 npm 上是两个不同的库,他们只不过在 react 项目中通过 Monorepo 的方式进行管理。
而著名的 rollup 目前是 Multirepo 组织。
对于 Monorepo 和 Multirepo,选择了 Monorepo 的 babel 贡献了文章:Why is Babel a Monorepo? 该文章思想,前文已经有所指出,这里不再展开。
Monorepo 风格在开发构建中的挑战
上述对于 Monorepo 的优缺点分析主要是针对于其管理风格本身来说的。作为工程师,我们还是要在实践中总结和发现问题,比如我还要补充 Monorepo 实际落地之后,会面临的两个挑战:
Monorepo 项目过大,导致每次上线构建流程过长,存在不必要的时间成本消耗
Monorepo 项目子应用和依赖在开发阶段存在互相「干扰」的损耗
先说第一个挑战点,对于一个 Monorepo 项目来说,虽然可以在开发阶段单独构建打包,但是在整个项目上线时,却需要全量构建。举例来说,一个 Monorepo 项目包含应用:App1,App2,App3,Dependecies。当我们对 App1 进行改动时,因为所有应用都在同一个 Git 仓库中,导致上线时 App2 和 App3 仍然需要重新构建,这种构建显然是不必要的(App1,App2,App3 不同应用应该互相独立),这和 Multirepo 相比,这无疑增加了上线构建成本。这里需要注意的是:如果 Dependecies 改动,那么所有依赖 Dependecies 的项目比如 App1,App2,App3 的重新构建是必要且必须的。
这种“缺陷”我们往往使用「增量构建」的方案来优化。这个话题很有意思,比如涉及到「如何能找出每次提交的改动点所对应的原子构建任务」,我们这里暂不展开,依然回到本文的主题上。
再说第二个挑战点,「Monorepo 项目子应用和依赖在开发阶段存在互相干扰的损耗」并不好理解,但正是本篇文章一个非常核心的输出之一。接下来,我们通过下一部分,从一个案例来说起,帮助大家体会,并一起找到优化方案。
多进程间构建流程优化
前端构建流程的本质其实是一个个 NodeJS 任务,也因此是逃离不了进程或者线程的概念。Webpack,Babel,NPM Script 这些我们耳熟能详的工具和脚本都是一个独立或相互关联的进程任务。这里需要大家明白一个「不间断进程」概念,我使用 continuous processes 来表达。其实很简单,比如 @babel/cli 提供了 watch mode 选项:
npx babel script.js --watch --out-file script-compiled.js
这个 watch 选项可以监听文件(夹)的实时变动,并在有变动时重新对目标文件(夹)进行编译。因此这个编译进程是挂起的,持续的,更多内容可以看笔者之前的文章 从构建进程间缓存设计 谈 Webpack5 优化和工作原理 。类似的场景在 Webpack 当中也非常常见。
对于复杂的前端构建过程,当这些任务进程交织在一起,产生流水关系时,就会变非常有趣,请继续阅读。
一个多项目应用开发架构下的瑕疵
我们的中后台项目「Monstro」采用了经典的 Monorepo 结构,项目组织如下:
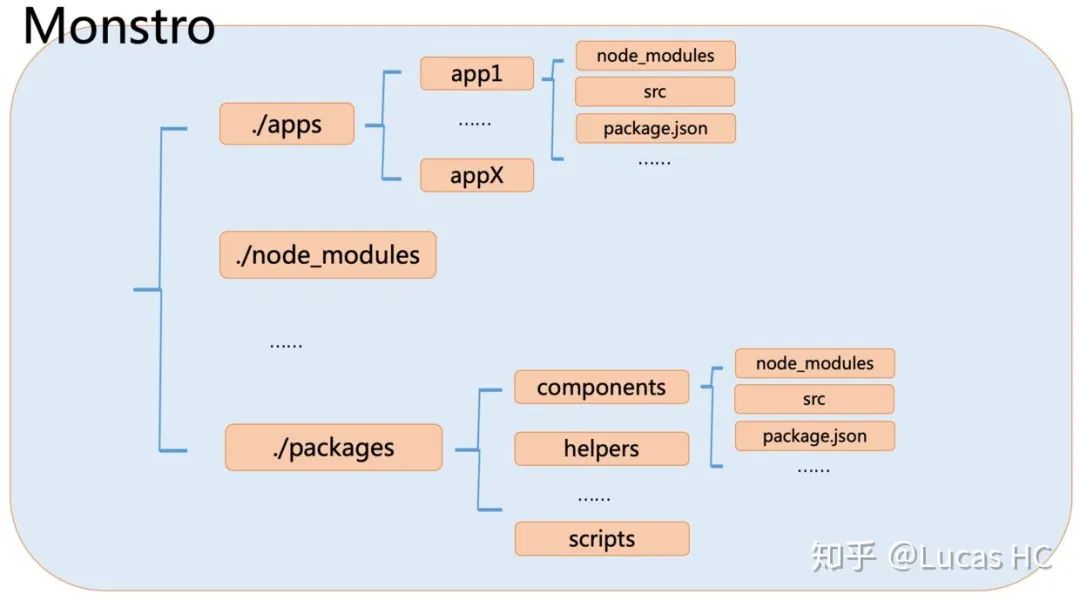
其中,package.json 中字段,
"workspaces": [
"packages/*",
"apps/*"
],
也暗示了项目中:apps 目录内是 Monorepo 下每一个单独的子应用,这些应用可以单独发版,单独构建,子应用之间相对独立;packages 目录内是公共依赖,被 apps 目录内所有子应用引用。
简要说明一下这种组织架构的优势:
不同子应用之间构建环节独立,每个子应用存在自己的 package.json 文件,可以在项目根目录下通过
NPMScript:yarn start ${appName}或yarn build ${appName}结合 --scope 选项,进行独立开发调试和构建不同子应用之间可以共同依赖 packages 内的公共依赖、公共组件、公共脚本
我们从开发流程来说起:当在根目录下进行 yarn start app1 时,会启动 appName 为 app1 的项目,浏览器代开 locahost:3000 端口进行开发调试。这一系列过程是如何串联起来的呢?yarn start app1 对应的脚本定义于 packages/script/* 目录当中,其内容简要为:
process.env.NODE_ENV = 'development'
const [app] = process.argv.slice(2)
const config = {
stdio: 'inherit',
env: {
...process.env
}
}
spawn.sync('monstro-scripts', ['clean'], config)
spawn('monstro-scripts', ['prebuild', '--watch'], config)
spawn(
'npx',
['lerna', 'exec', 'npm', 'run', 'start', '--scope', `@monstro/app-${app}`],
config
)
代码很好理解,其实在 start 脚本中我们做了三件事情:
串行执行 clean 脚本,进行一次新的构建前处理
clean 执行完后,并行执行 prebuild 脚本,对 pacakges 目录中各个依赖项进行 babel 编译,并传递 watch 参数
clean 执行完后,并行执行 app1 scope 内的 npm run start,注意这个 npm run start 对应的 NPM Script 定义在 apps/app1/packages.json 中
其中代码中 monstro-scripts 命令行预先定义在 packages/scripts 的 package.json 文件中:
"bin": {
"monstro-scripts": "bin/monstro-scripts.js"
},
保证形如 spawn.sync('monstro-scripts', ['命令名称'], 参数) 的脚本能够正常执行。
让我们来逐一分析:
开发者敲入 yarn start app1 后,先执行 clean 脚本,clean 脚本执行构建结果清理工作:
import rimraf from 'rimraf'
rimraf.sync('node_modules/.cache')
rimraf.sync('packages/*/lib')
rimraf.sync('apps/*/build')
rimraf.sync('apps/*/node_modules/.cache')
同时执行 spawn('monstro-scripts', ['prebuild', '--watch'], config) 脚本,prebuild 过程实际上是使用 @babel/cli 对依赖目录 packages 内 src 目录内容进行编译,原地输出到 lib 目录中:
const args = process.argv.slice(2)
const packages = glob
.sync(path.resolve(process.cwd(), 'packages/*'))
.filter(name => readdirSync(name).includes('src'))
for (const pkg of packages) {
spawn(
'npx',
[
'babel',
path.resolve(`${pkg}`, 'src'),
'--out-dir',
path.resolve(`${pkg}`, 'lib'),
'--copy-files',
'--config-file',
path.resolve(__dirname, '../configs/babel.config.js'),
'-x',
['.es6', '.js', '.es', '.jsx', '.mjs', '.ts', '.tsx'].join(','),
...args
],
{
stderr: 'inherit',
env: {
...process.env,
NODE_ENV: process.env.NODE_ENV || 'production'
}
}
)
}
其中关于 Babel 的配置我们采用了 react-app 这个预设:
presets: [['react-app', { flow: false, typescript: true }]]
依然是同时执行:
spawn(
'npx',
['lerna', 'exec', 'npm', 'run', 'start', '--scope', `@monstro/app-${app}`],
config
)
这一步使用了 lerna exec 命令,该命令可以在每个包目录下(apps/*)执行任意命令,我们到 apps/app1(@monstro/app-${app}) 下执行了 npm run start,对应 app1 的 start 脚本定义在 apps/app1/packages.json 中:
"scripts": {
"build": "react-scripts build",
"start": "react-scripts start"
},
由此可知,我们最终是使用了 create-react-app 提供的 react-scripts 脚本完成了项目的开发构建,create-react-app 提供的 react-scripts 最终会打开浏览器,呈现应用内容,启动持续化进程,监听应用依赖树上的任何变动,随时进行重新构建。
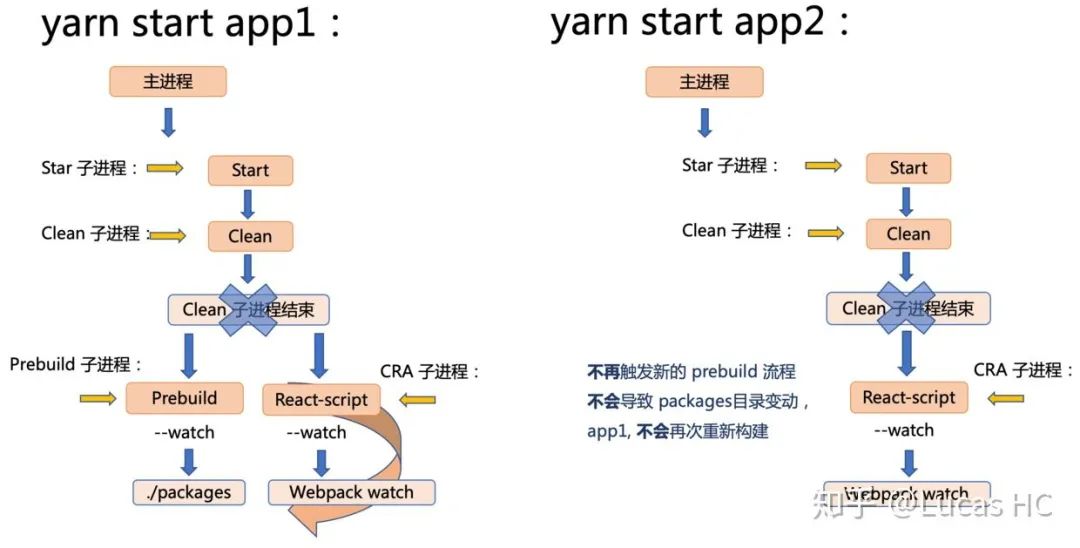
总结一下,一个 start 脚本构建流程如图:
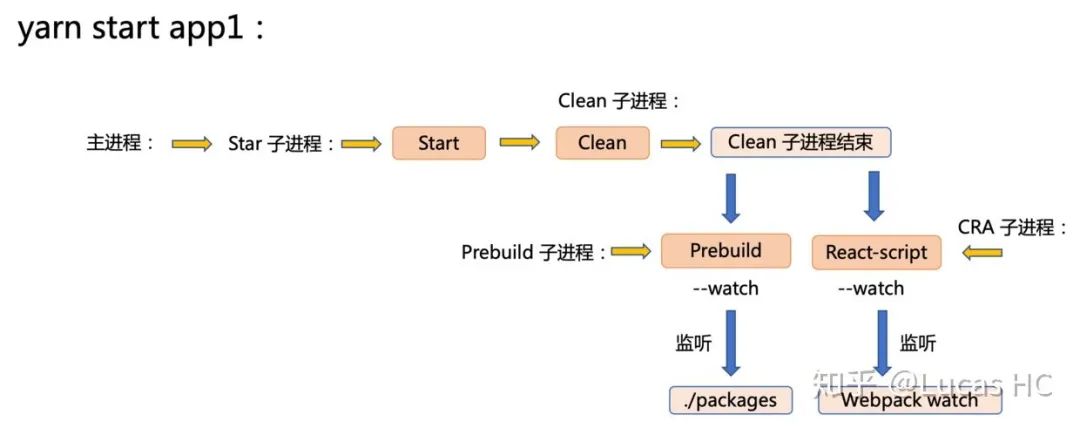
整体来看,这套流程架构兼顾了各子应用的独立性,也充分尊重了子应用之间和依赖的关联性,从而达到了较高的开发调试效率。在较长一段时间内,稳定为中后台系统赋能,支持一体化的开发、编译、上线流程。
直到有一天收到开发者 A 同学的反馈:有时候短时间内连续开启多个应用,会造成较高的内存占用,电脑持续发热并伴随有较大风扇噪音。
这虽然是偶发的状况,但是仍然得到了我们的重视。还原场景如:我先开发第一个应用 app1:yarn start app1,接着开发第二个应用:yarn start app2,再开发第二个应用:yarn start app3...
分析问题本质 找到优化方案
多应用同时开发时的内存成本持续上升的原因是什么呢?
我们将上述过程通过两个应用的启动来进行演示:
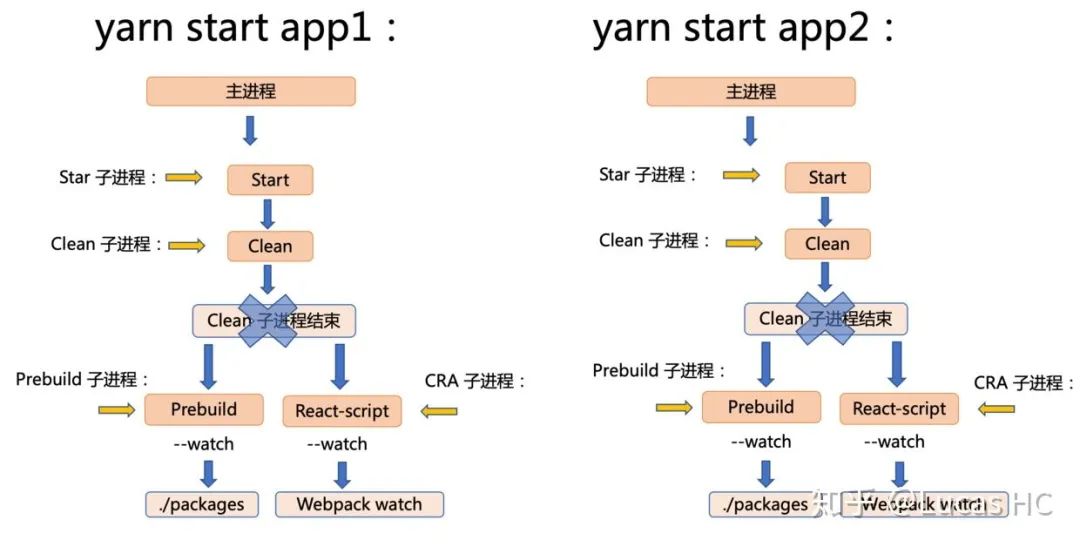
关键点在于 prebuild 这一步。回顾一下 start 脚本中对于 prebuild 任务的启动:
spawn('monstro-scripts', ['prebuild', '--watch'], config)
这里使用 Babel 编译 packages 下内容时,我们使用了 @babel/cli 的 --watch 这一参数。用前文说法, watch 模式的开启将会创建一个可持续进程,监听 packages 下文件内容的变动,并即时将编译结果输出到原地 lib 目录中。
我们知道,对于每一个应用,我们使用了 react-script 构建开发应用,create-react-app 中 react-script 会内置 Webpack 配置,参看其源码,可以找到内置 Webpack 配置的部分内容,配置有 webpack-dev-server 来帮助开发者启动本地服务用于开发:
watchOptions: {
ignored: ignoredFiles(paths.appSrc),
},
源码:webpackDevServer.config.js
简要对源码进行说明:ignoredFiles(paths.appSrc) 是一个匹配项目 nodemodules 的正则表达式,意味着 create-react-app 在持续性进程重新构建中会显式地忽略 nodemodules 目录的变动。
module.exports = function ignoredFiles(appSrc) {
return new RegExp(
`^(?!${escape(
path.normalize(appSrc + '/').replace(/[\\]+/g, '/')
)}).+/node_modules/`,
'g'
);
};
这么做的原因主要是考虑到监听 nodemodules 全量内容时的性能损耗的性价比。毕竟在 create-react-app 早期在全量监听 nodemodules 时,某些系统(OS X)上会偶现 CPU 使用率过高的问题。具体 issues:
High CPU usage while running on OS X
Document src/node_modules as official solution for absolute imports
目前 create-react-app 对于监听 nodemodules 这件事情所采用的策略非常聪(鸡)明(贼):如果 nodemodules 加入一个新的依赖包,仍然会被监听到,从而触发 create-react-app 重新构建,这个是依赖 WatchMissingNodeModulesPlugin 插件实现的,在 create-react-app 源码文件 webpack.config.js 中:
isEnvDevelopment &&
new WatchMissingNodeModulesPlugin(paths.appNodeModules),
总之,create-react-app 中 react-script 脚本使用了 webpack-dev-server,这样也同样开启了一个可持续进程,监听当前应用上依赖树关系的任何变动,以便随时重新进行构建。
距离“破案”越来越近了。我们想,当我们在已经启动 app1 并触发 webpack-dev-server watch 监听后,再次启动 app2,app2 的 start 流程不可避免地进行 prebuild 脚本,使得 packages 目录下产生了变动,这个变动反过来会影响 app1,被 app1 所对应的 webpack-dev-server 进程捕获到变动,进而重新构建 app1(我们这里默认所有的业务项目都依赖了 packages 目录内容,实际上这也是 99% 的场景)。这样循环下去,如果我们同时开启 K 个应用,当再次开启 K + 1 个应用时(yarn start ${appK+1}),因为不可避免地触发了 packages 目录变动,前面 K 个应用都将会同时重新构建。这就意味着更大的内存消耗。
如下图,我们以开启第四个应用项目为例:
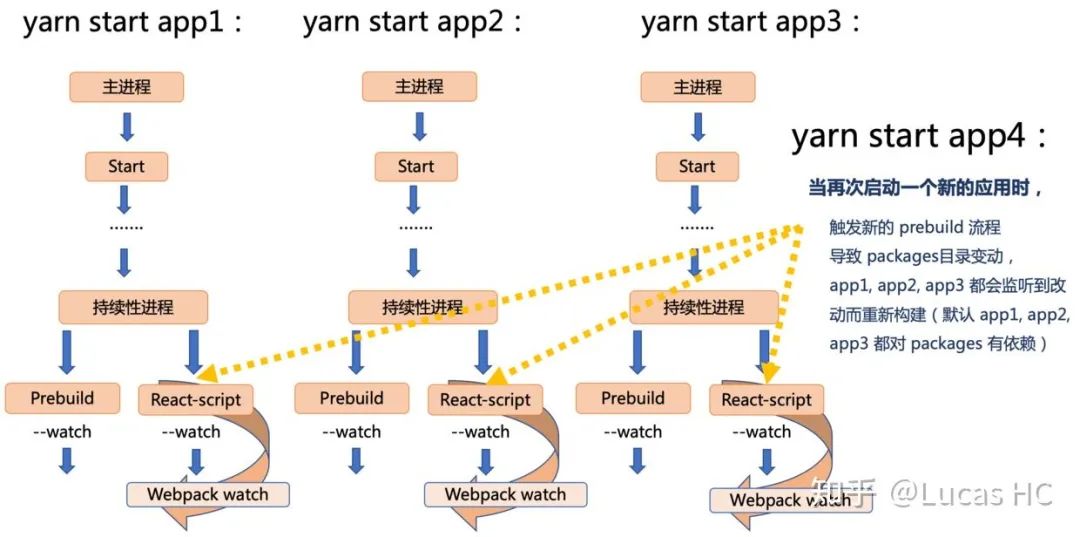
我把这个问题称之为——「多应用多持续性进程间的构建消耗」问题。
互斥锁和锁竞争的解决之道
如何解决这个「多应用多持续性进程间的构建消耗」问题呢?首先,create-react-app 中 react-script 脚本的 webpack-dev-server 的 watch 配置一定是我们预期当中的:因为我们希望在应用项目中,有相关文件改动,即重新构建。其次 react-script 脚本由 create-react-app 封装,且不暴露配置 webpack-dev-server 的能力,同时 eject create-react-app 是我们永远不想做的, 因此改动 react-script 脚本的思路不可行。
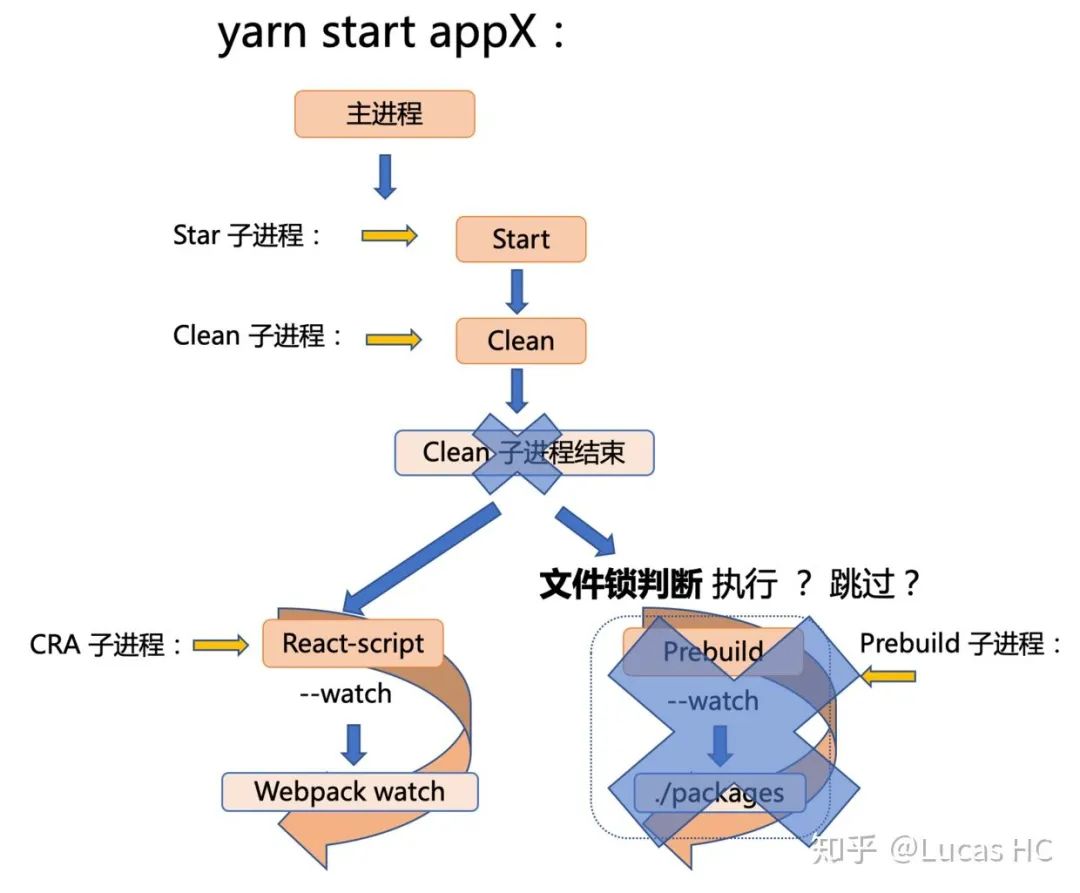
关键当然是在 prebuild 流程,我们再次提及问题核心是:第一次启动 app1 之后,经过 prebuild,我们已经产出了编译后的 packages/*/lib目录,因此后续启动的所有应用都不需要再次触发 prebuild。思路如此,对应图示为:
但是 start 脚本是统一的,我们该如何改造呢?伪代码如下:
process.env.NODE_ENV = 'development'
const [app] = process.argv.slice(2)
const config = {
stdio: 'inherit',
env: {
...process.env
}
}
spawn.sync('monstro-scripts', ['clean'], config)
if (prebuild 过程已经成功执行 !== true) {
spawn('monstro-scripts', ['prebuild', '--watch'], config)
}
spawn(
'npx',
['lerna', 'exec', 'npm', 'run', 'start', '--scope', `@monstro/app-${app}`],
config
)
我们给 spawn('monstro-scripts', ['prebuild', '--watch'], config) 加上了一个判断条件,在已经成功 prebuild 后,跳过后续所有 prebuild 流程。但是 prebuild 过程已经成功执行 这个变量应该如何设计呢?
每一个 start 脚本对应一个不同且独立的持续性进程任务,因此 prebuild 过程已经成功执行 这个变量应该能够被不同进程都访问到,这是一个典型的多进程间通信问题。历数 IPC 的几种方式,其实都并不完全适合我们的场景。其实针对我们的问题,似乎用一个文件锁更好。以开源库 jsonfile 为例,我们把 prebuild 结果标记在一个 json 文件中,似乎是一个合适的选择。伪代码:
const jsonfile = require('jsonfile')
process.env.NODE_ENV = 'development'
const [app] = process.argv.slice(2)
const config = {
stdio: 'inherit',
env: {
...process.env
}
}
spawn.sync('monstro-scripts', ['clean'], config)
if (jsonfile.readFileSync(file).status !== 'success') {
spawn('monstro-scripts', ['prebuild', '--watch'], config)
jsonfile.writeFileSync(file, {status: 'success'})
}
spawn(
'npx',
['lerna', 'exec', 'npm', 'run', 'start', '--scope', `@monstro/app-${app}`],
config
)
此时 start 脚本流程如图:
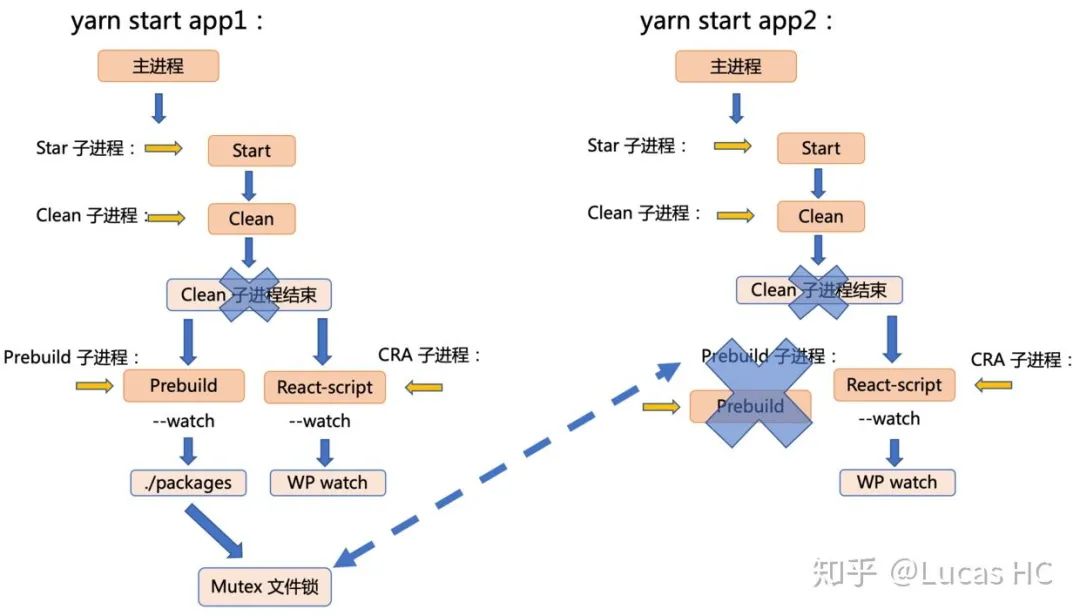
这里插一个细节,初期设计我们认为文件锁状态应该有 3 种:
{
status: 'success'/'running'/'fail'
}
如果 prebuild 流程正在构建或构建失败,仍然要继续执行 spawn('monstro-scripts', ['prebuild', '--watch'], config)。事实上,这是完全没有必要的,因为 Babel 的编译是一个持续性进程,开启 watch 选项,这样开发者可以始终在编译进行中和编译失败中得到信息,进行修复。文件锁内容完全可以乐观更新,而后续乐观可行性保障由开发者负责。
但却还有另外一个重要问题需要考虑:在初期架构设计中,每个应用的启动,都使用了 Babel 持续性编译进程,进行 watch 监听,这样当开发者手动杀死(Ctrl + C)一个终端进程后:比如不再需要 app1 的开发,杀死 app1 后,就没有任何应用能够监听 packages 的变化了。理想状态下,我们需要启动另外一个应用进程,去监听着 packages 文件夹的变动,进而触发 packages 的持续编译。
如何理解呢?请参考上图,在我们新改进的流程中:app1 的启动中执行了 spawn('monstro-scripts', ['prebuild', '--watch'], config),后续的 appN 不再有 prebuild 过程,也就不在监听 packages 文件夹的变动,此时,如果开发者手动杀死(Ctrl + C)第一个应用(即 app1),那么开发者再对 packages 内代码进行改动,就不会触发 Babel 编译,任何应用都不在有相应,此时状态如下:
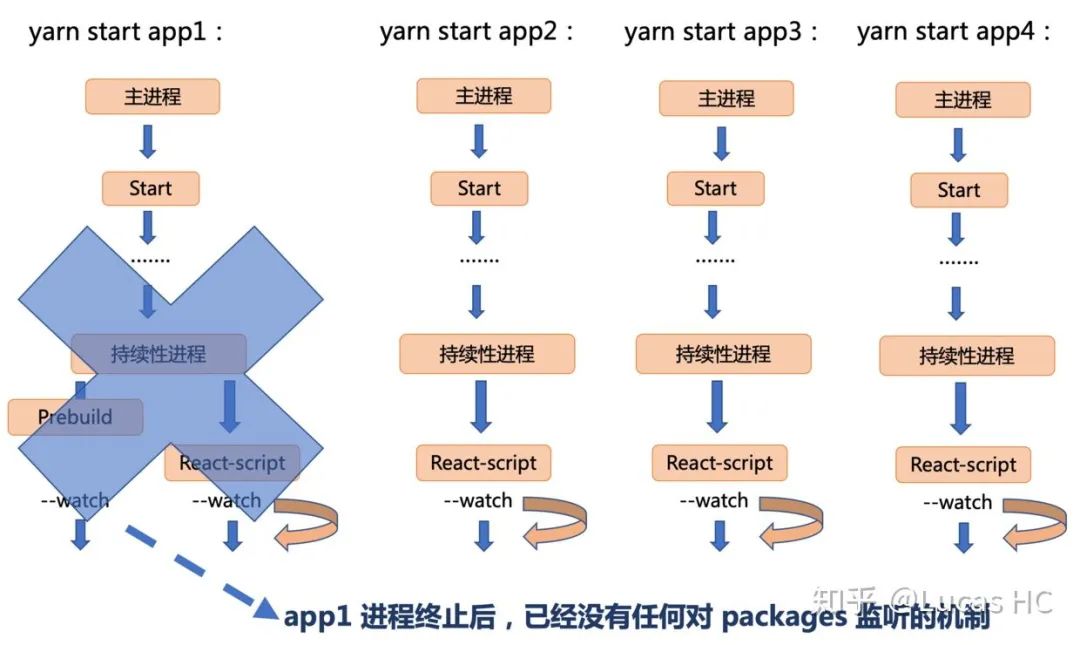
如何解决这个问题?这就涉及到了 竞争锁的概念。
锁竞争常出现在多线程编程中,熟悉 Java 并发机制的读者可能对这个概念并不陌生。简单来说,同一个进程里线程是数共享的,当各个线程访问数据资源时会出现竞争状态,即数据几乎同步会被多个线程占用,造成数据混论,即所谓的线程不安全。那怎么解决多线程问题,就是锁了。切换到另一种语言,Python 提供的对线程控制的对象,其中包括有互斥锁、可重入锁、死锁等。互斥锁概念,是用来保证共享数据操作的完整性。这个标记用来保证在任一时刻,只能有一个线程访问该对象。
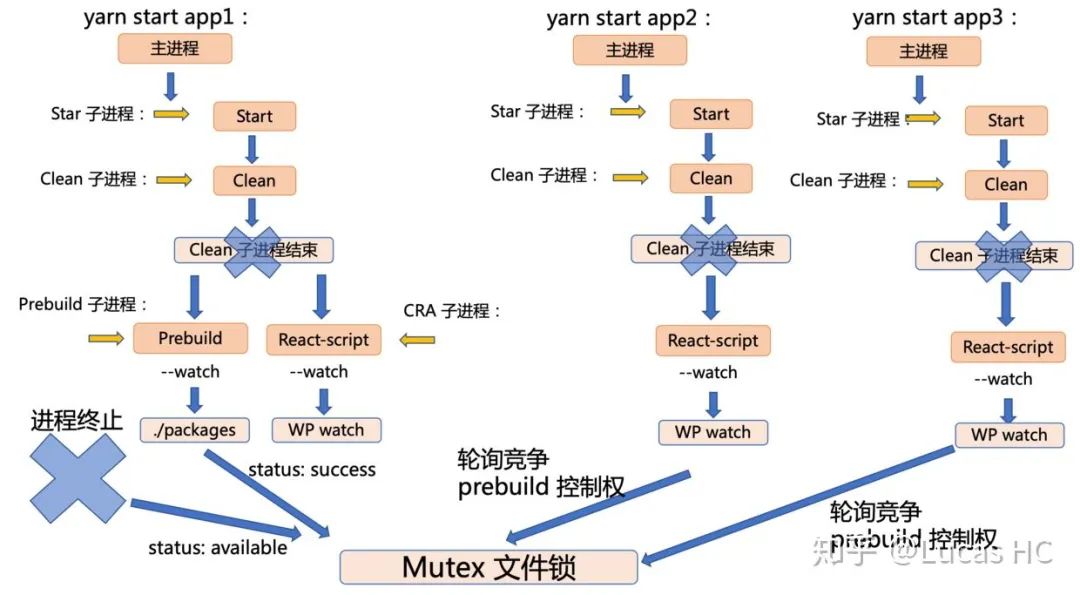
按照这个思路,我们进行扩展,通过互斥锁和锁竞争,实现这样的机制:第一个应用启动时,在 prebuild 阶段对该进程的终止进行监听,在监听到 Babel 持续性进程终止时,改写文件锁内容 status 为 available;同时之后的每一个应用启动时,都加入轮询脚本,轮询内容即为对文件锁 status 值的查询,一旦查询到 status === 'available',说明相关监听 Babel 编译的进程结束,需要“我”来接管。具体操作是:将 status 值置为 'success',同时开启 prebuild 流程(spawn('monstro-scripts', ['prebuild', '--watch'], config))。整个过程概括为:
第一个应用负责 prebuild,负责 Babel 持续性进程来监听 packages 目录的改动。同时监听该进行的终止事件
第一个应用一旦监听到进程终止,则改写文件锁 status 状态为 available,释放 prebuild 流程控制权
其他应用通过启动时的轮询机制,竞争被释放的 prebuild 流程控制权
其他应用谁先竞争到 prebuild 流程控制权,就通过改写文件锁 status 状态为 success,进行锁定
流程如下图:
工程从来不只是个技术问题
上述使用「锁」的方案虽然稍显复杂,但似乎能够从技术上给出较彻底完备的解法了。可是在项目工程上,这真是我想要的么?让我们回到问题的最初始:「start 这个脚本开启两个子进程,其中对 packages 目录进行 watch 并增量编译的脚本会影响并触发 create-react-app 进程的重新构建。在多应用同时开发的情况下,这种影响是指数叠加的,从而导致了内存的重复消耗」。这是项目已用的设计,我不禁要想,「将 start 脚本中的 create-react-app 进程和 babel 增量编译进程解耦,似乎是很自然而然的做法」。如下图:
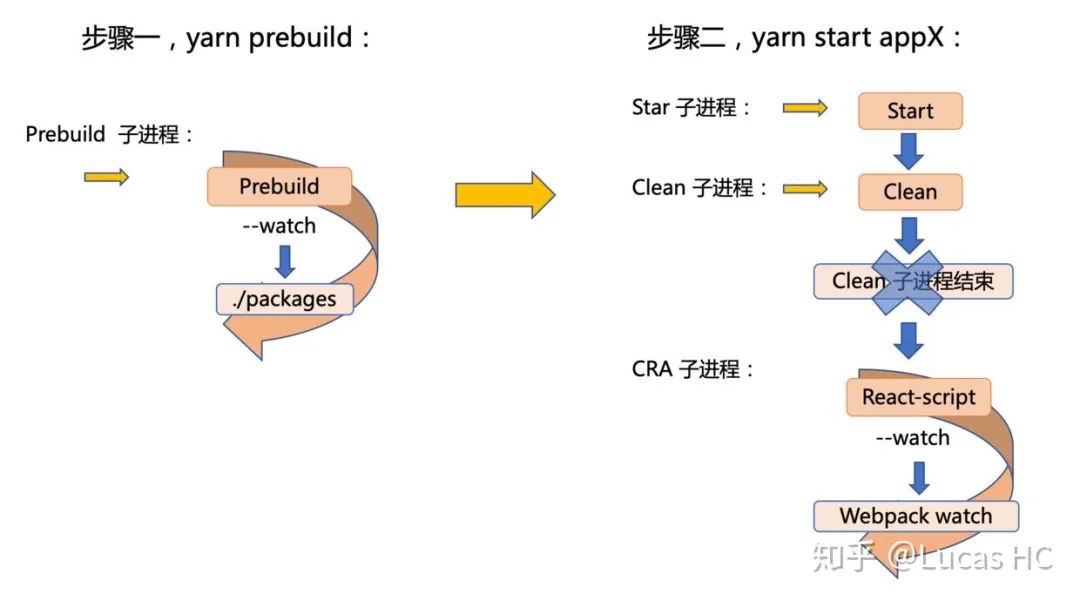
这样的启动流程排除了 babel 进程和 create-react-app 进程之间的相互干扰,从根源上解决了问题。但是它的「副作用」是:需要开发者在启动应用时,先执行 yarn prebuild 的 script,再执行 yarn start appX。相比于之前的「一键无脑启动」,多了一个终端 tab 和脚本执行过程,且要求开发者知晓这么做的目的以及意义:当修改 packages 目录下内容,并由于各种原因中断 prebuild babel 进程后,开发者要知道需要重启 yarn prebuild 进程。这些「信息量」我们可以通过 README 来进行说明和指导,并在丧失 prebuild 进程持续执行时,进行中断友好提示。相比上述纯技术向的「锁」方案,这样的设计更「取巧」。我认为,工程从来不只是个技术问题,不钻牛角尖,多角度思考,往往有「四两拨千斤」的效用。
实际上,当初将 prebuild babel watch 进程作为 start 进程的子进程设计也是有一定道理的,这里不再展开(这是一个设计取舍问题)。
总结
这篇文章讨论了两个核心问题:
多项目应用开发架构设计
多进程多应用间构建流程优化设计
对于大型复杂应用的开发和构建设计——这一话题,我们结合实际生产中的项目,分析并给出了一个较为“完美”的方案。在这个方案的基础上,论证并解决了 Monorepo 化的项目在遇见多进程复杂构建流程时的一个“小尴尬”。整个过程中,为了发现问题,解决问题,我们深入剖析了 create-react-app 和 Webpack 的源码及设计,同时讨论了持续化进程,最终通过互斥锁和锁竞争找到了灵感,实现了迭代和优化。最后我们从流程解耦的角度,也给出了另外一种优化方案。
当然,这其中也涉及到很多其他有趣的问题,大型复杂应用的开发和构建关联到基建的方方面面,为此我们会持续输出这方面的技术经验和心得,请大家订阅内容。
分享前端好文,点亮 在看
