
系统架构性能优化思路
互联网架构师后台回复 2T 有特别礼包
上一篇:朝阳群众盯上了望京A座?举报996造成交通严重堵塞。996将成历史?
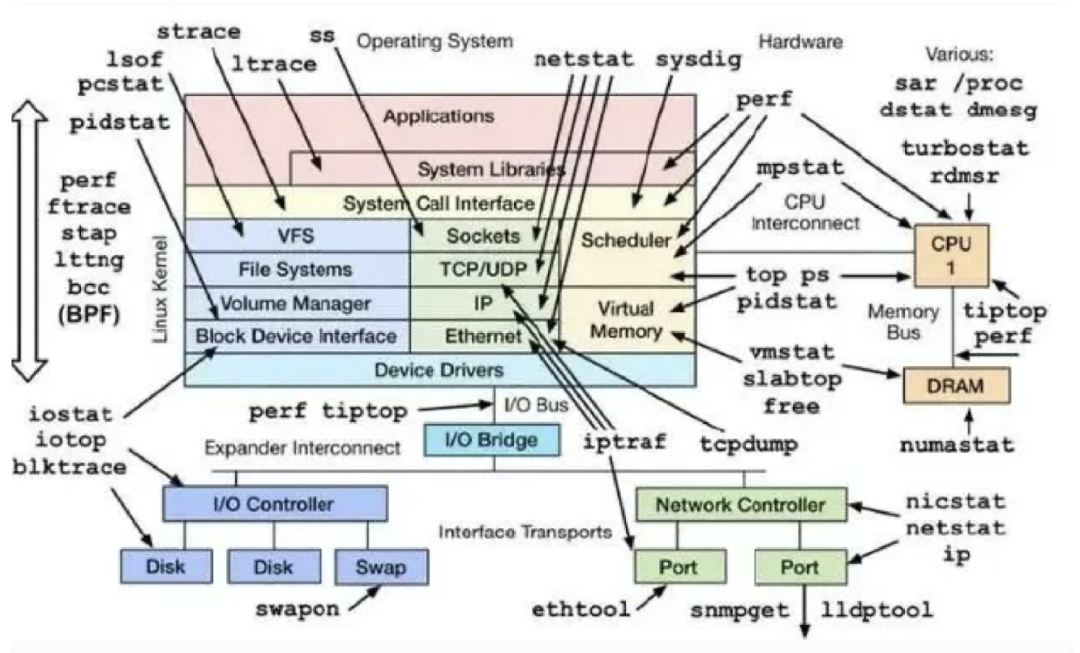
今天谈下业务系统性能问题分析诊断和性能优化方面的内容。这篇文章重点还是谈已经上线的业务系统后续出现性能问题后的问题诊断和优化重点。
系统性能问题分析流程
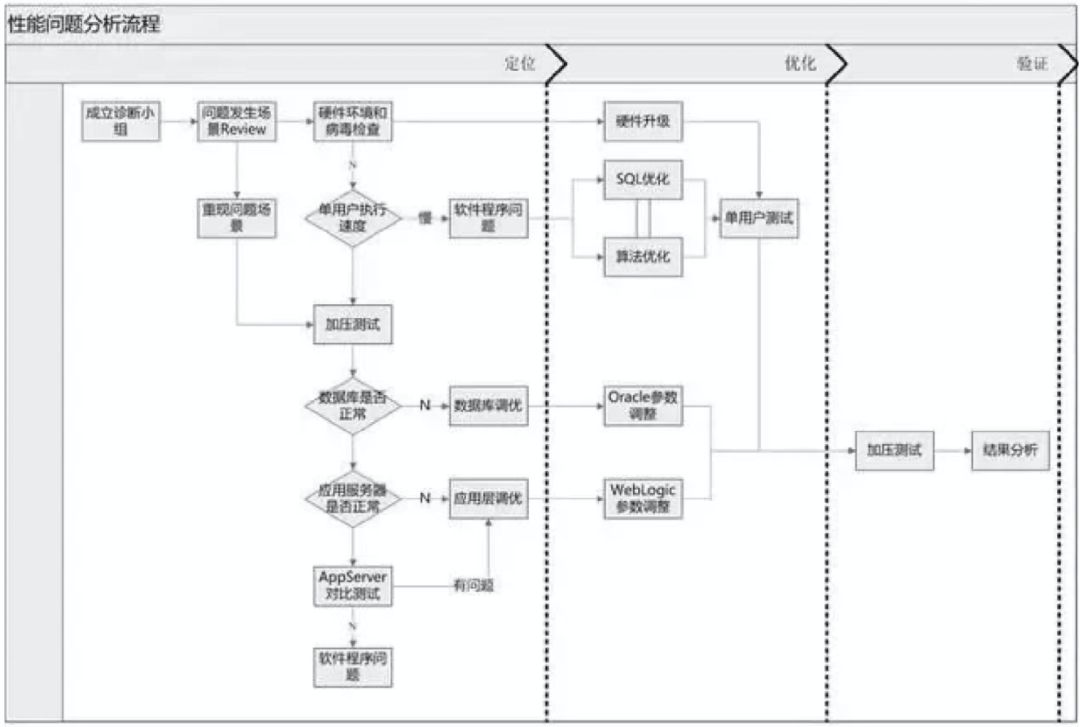
我们首先来分析下如果一个业务系统上线前没有性能问题,而在上线后出现了比较严重的性能问题,那么实际上潜在的场景主要来自于以下几个方面。
如果是单用户本身就存在性能问题,那么大部分问题都出在程序代码和SQL需要进一步优化上面。如果是并发性能问题,我们就需要进一步分析数据库和中间件本身的状态,看是否需要对中间件进行性能调优。
在加压测试过程中,我们还需要对CPU,内存和JVM进行监控,观察是否存在类似内存泄漏无法释放等情况,即并发下性能问题本身也可能是代码本身原因导致性能异常。
性能问题影响因素分析
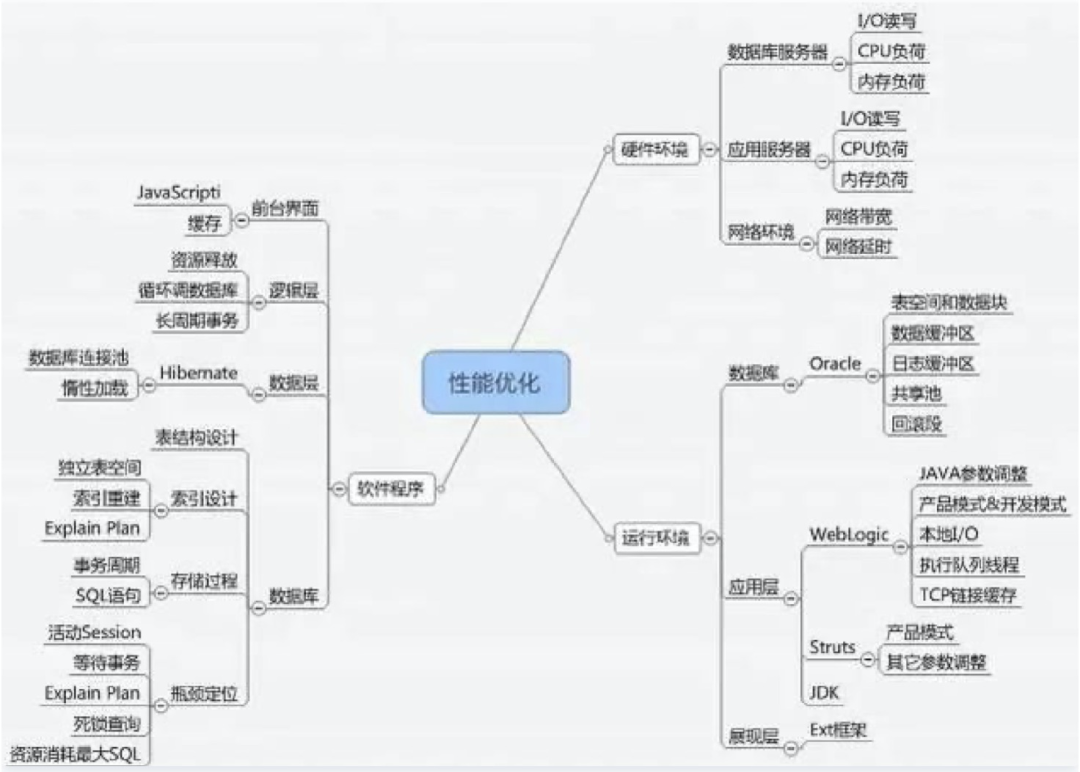
对于性能问题影响因素,简单来说包括了硬件环境,软件运行环境和软件程序三个方面的主要内容。下面分别再展开说明下。
硬件环境
对于服务器的计算能力,一般来说厂家都会提供TPMC参数作为一个参考数据,但是我们实际看到相同TPMC能力下的X86服务器能力仍然低于小型机的能力。
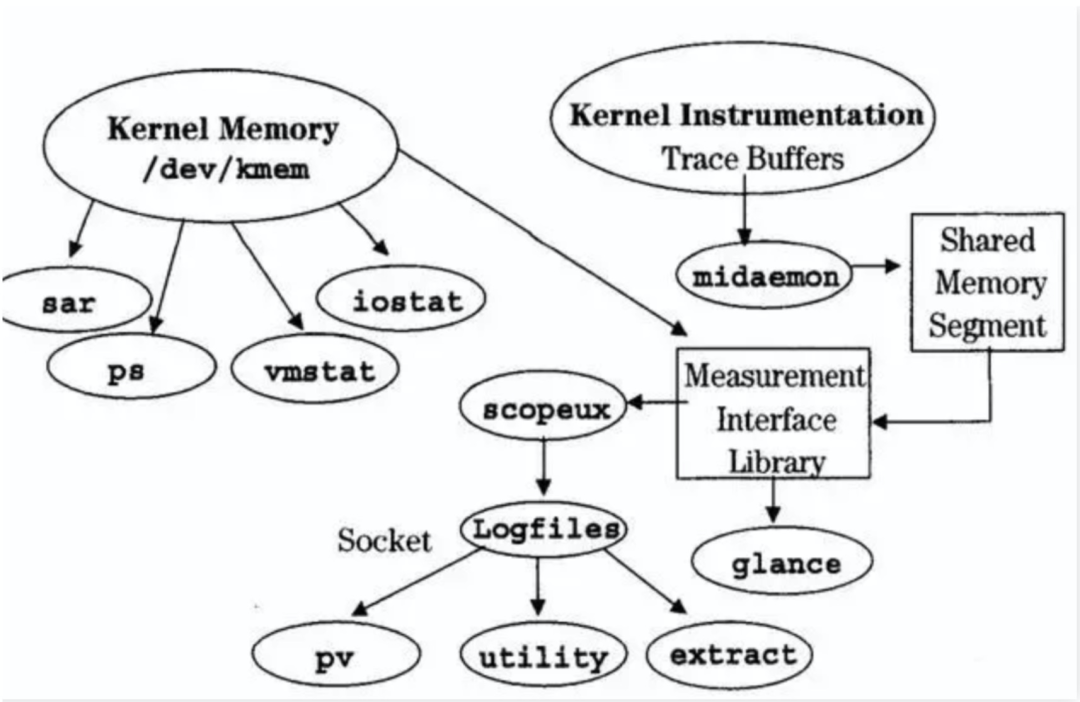
比如我们常说的内存使用率持续告警,你就必须发现是高并发调用导致,还是JVM内存泄漏导致,还是本身由于磁盘IO瓶颈导致。
对于CPU,内存,磁盘IO性能监控和分析的一个思路可以参考:
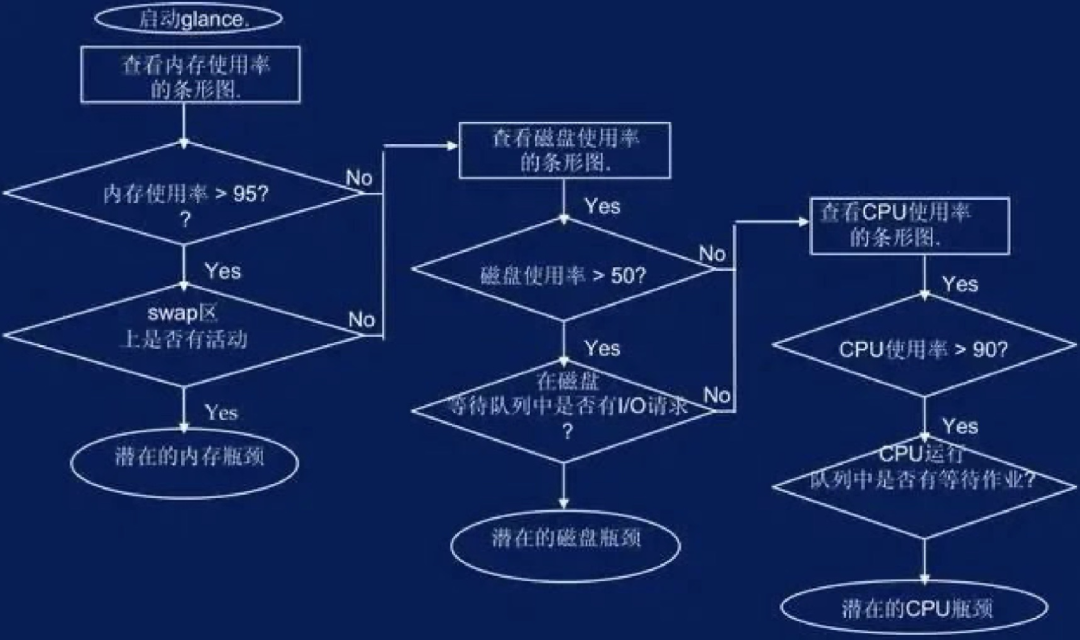
运行环境-数据库和应用中间件
数据库和应用中间件性能调优是另外一个经常出现性能问题的地方。
数据库性能调优
拿Oracle数据库来说,影响数据库性能的因素包括:系统、数据库、网络。数据库的优化包括:优化数据库磁盘I/O、优化回滚段、优化Rrdo日志、优化系统全局区、优化数据库对象。
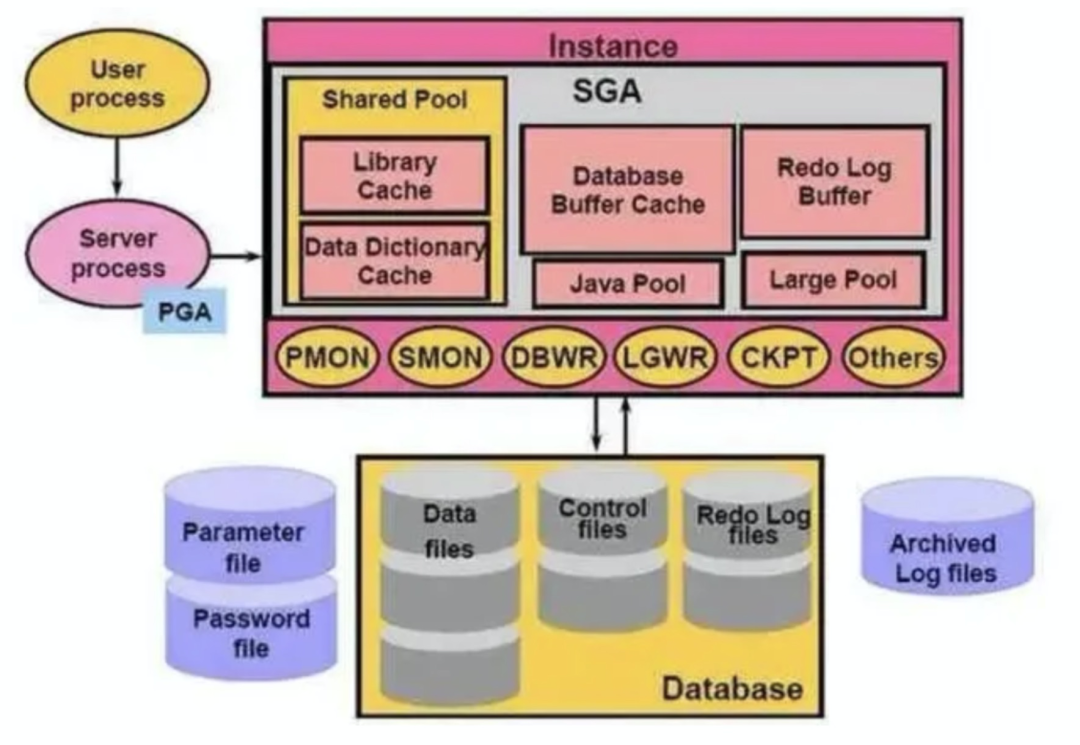
要调整首先就需要对数据库性能进行监控
比如我们可能会发现Oracle数据库出现内存使用率高的告警,而通过检查会发现是产生了大量的Redo日志导致,那么我们就需要从程序上进一步分析为何会产生如此多的回滚。
应用中间件性能分析和调优
应用中间件容器即我们常说的Weblogic, Tomcat等应用中间件容器或Web容器。应用中间件调优一个方面是本身的配置参数优化设置,一个方面就是JVM内存启动参数调优。
对于应用中间件本身的参数设置,主要包括了JVM启动参数设置,线程池设置,连接数的最小最大值设置等。如果是集群环境,还涉及到集群相关的配置调优。
对于JVM启动参数调优,往往也是应用中间件调优的一个关键点,但是一般JVM参数调优会结合应用程序一起进行分析。
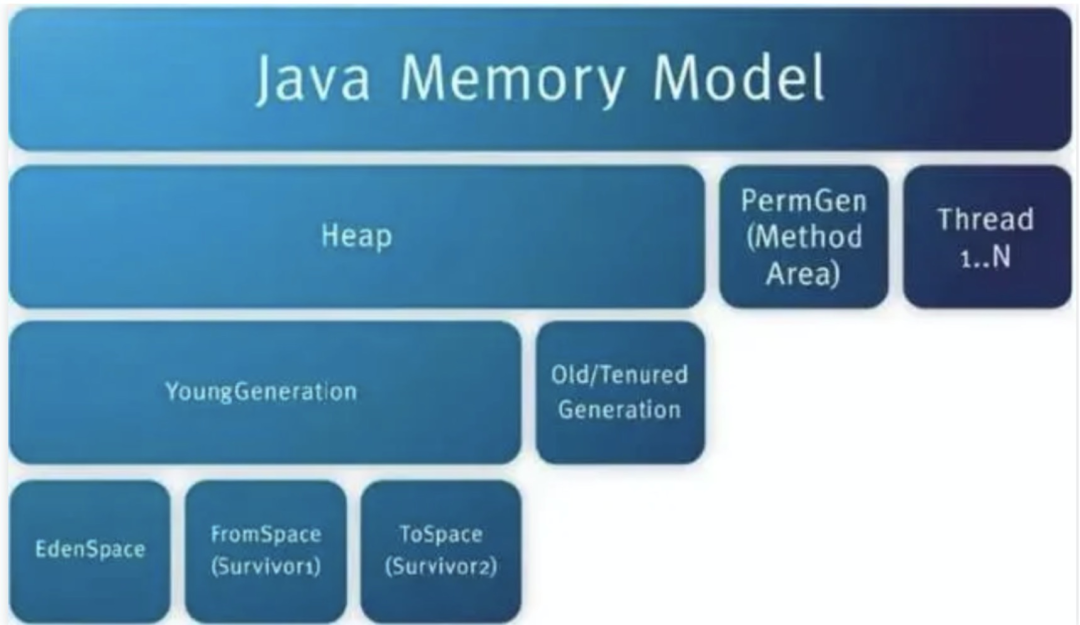
其中JVM启动的主要控制参数说明如下:
-Xmx #设置最大堆空间
-Xms #设置最小堆空间
-XX:MaxNewSize #设置最大新生代空间
-XX:NewSize #设置最小新生代空间
-XX:MaxPermSize #设置最大永久代空间(注:新内存模型已经替换为Metaspace)
-XX:PermSize #设置最小永久代空间(注:新内存模型已经替换为Metaspace)
-Xss #设置每个线程的堆栈大小
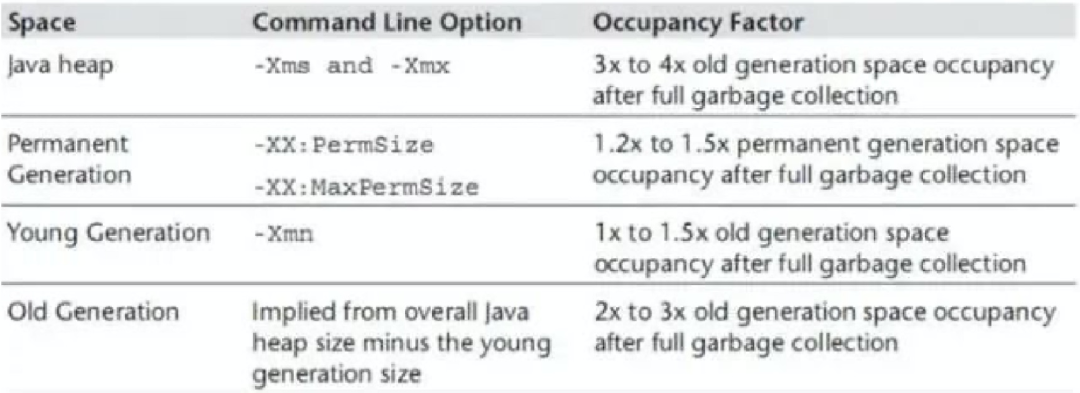
注意在新的JVM内存模型下已经没有PermSize而是变化为Metaspace,因此需要考虑Heap内存和Metaspace大小的配比,同时还需要考虑相关的垃圾回收机制是采用哪种类型等。
对于JVM内存溢出问题,我前面写过一篇专门的分析文章可以参考。
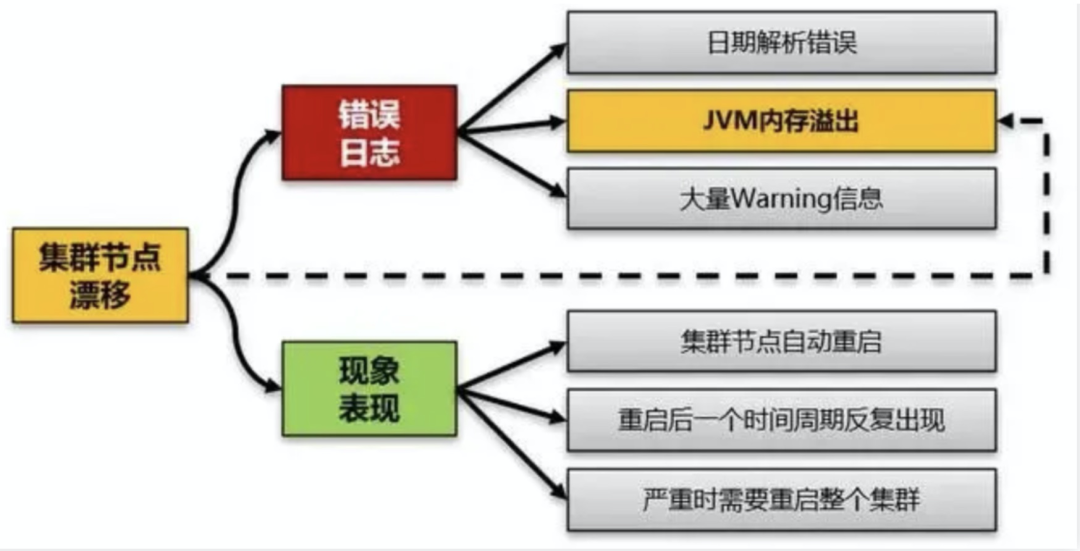
软件程序性能问题分析
在这里首先要强调的一点就是,当我们发现性能问题后首先想到的就是扩展资源,但是大部分的性能问题本身并不是资源能力不够导致,而是我们程序实现上出现明显缺陷。
比如我们经常看到的大量循环创建连接,资源使用了不释放,SQL语句低效执行等。
为了解决这些性能问题,最好的方法仍然是在事前控制。其中包括了事前的代码静态检查工具的使用,也包括了开发团队对代码进行的Code Review来发现性能问题。
所有已知的问题都必须形成开发团队的开发规范要求,避免重复再犯。
业务系统性能问题扩展思考
对于业务系统的性能优化,除了上面谈到的标准分析流程和分析要素外,再谈下其它一些性能问题引发的关键思考。
上线前的性能测试是否有用?
有时候大家可能觉得奇怪,为何我们系统上线前都做了性能测试,为何上线后还是会出现系统性能问题。那么我们可以考虑下实际上我们上线前性能测试可能存在的一些无法真实模拟生产环境的地方,具体为:
而实际上我们在做性能测试的时候以上几个点都很难真正做到,因此要想完全模拟出生产真实环境是相当困难的,这也导致了很多性能问题是在真正上线后才发现。
系统本身水平弹性扩展是否完全解决性能问题?
实际上我们看到对于数据库往往很难真正做到无限的弹性水平扩展,即使对于Oracle RAC集群往往也是最多扩展到单点的2到3倍性能。对于应用集群往往可以做到弹性水平扩展,当前技术也比较成熟。
业务系统性能诊断的分类
对于业务系统性能诊断,如果从静态角度我们可以考虑从以下三个方面进行分类
那么一个业务系统应用功能出现问题了,我们当然也可以从动态层面来看实际一个应用请求从调用开始究竟经过了哪些代码和硬件基础设施,通过分段方法来定位和查询问题。
比如我们常见的就是一个查询功能如果出现问题了,首先就是找到这个查询功能对应的SQL语句在后台查询是否很慢,如果这个SQL本身就慢,那么就要优化优化SQL语句。如果SQL本身快但是查询慢,那就要看下是否是前端性能问题或者集群问题等。
软件代码的问题往往是最不能忽视的一个性能问题点
对于业务系统性能问题,我们经常想到的就是要扩展数据库的硬件性能,比如扩展CPU和内存,扩展集群,但是实际上可以看到很多应用的性能问题并不是硬件性能导致的,而是由于软件代码性能引起的。对于软件代码常见的性能问题我在以往的博客文章里面也谈过到,比较典型的包括了。
以上都是常见的一些软件代码性能问题点,而这些往往需要通过我们进行Code Review或代码评审的方式才能够发现出来。因此如果要做全面的性能优化,对于软件代码的性能问题排查是必须的。
通过IT资源监控或APM应用工具来发现性能问题
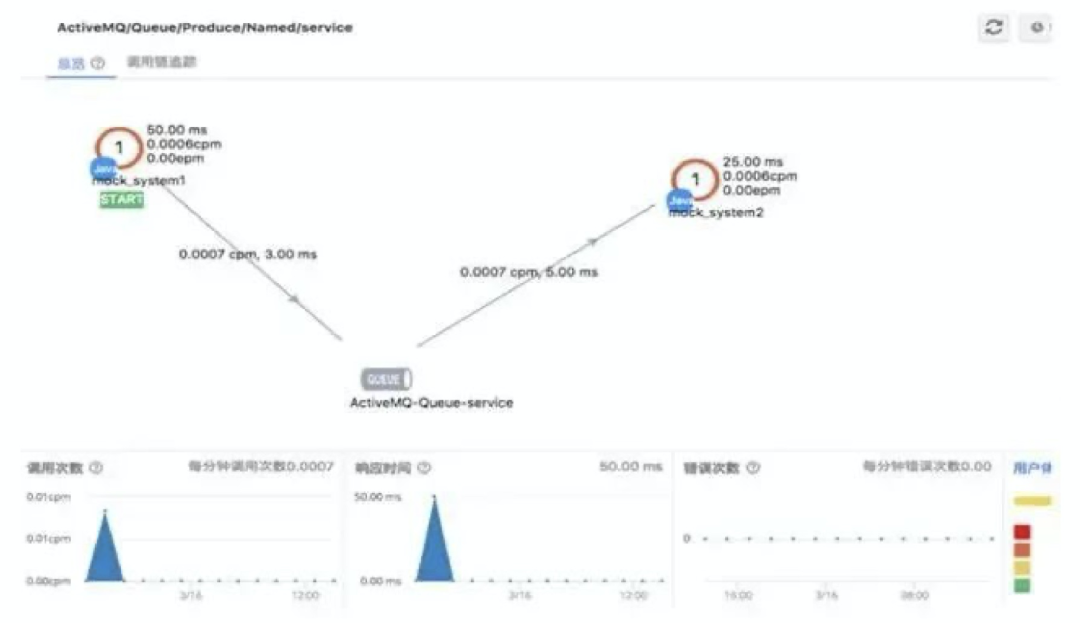
对于性能问题的发现一般有两条路径,一个就是通过我们IT资源的监控,APM的性能监控和预警来提前发现性能问题,一个是通过业务用户在使用过程中的反馈来发现性能问题。
APM应用性能管理主要指对企业的关键业务应用进行监测、优化,提高企业应用的可靠性和质量,保证用户得到良好的服务,降低IT总拥有成本(TCO)。
资源池-》应用层-》业务层
这个可以理解为APM的一个关键点,原有的网管类监控软件更多的是资源和操作系统层面,包括计算和存储资源的使用和利用率情况,网络本身的性能情况等。但是当要分析所有的资源层问题如何对应到具体的应用,对应到具体的业务功能的时候很难。
比如在我们最近的项目实施中,结合APM和服务链监控,我们可以快速的发现究竟是哪个服务调用出现了性能问题,或者快速的定位出哪个SQL语句有验证的性能问题。这个都可以帮助我们快速的进行性能问题分析和诊断。
资源上承载的是应用,应用本身又包括了数据库和应用中间件容器,同时也包括了前端;在应用之上则是对应到具体的业务功能。因此APM一个核心就是要将资源-》应用-》功能之间进行整合分析和衔接。
而随着DevOps和自动化运维的思路推进,我们更加希望是通过APM等工具主动监控来发现性能问题,对于APM工具最大的好处就是可以进行服务全链路的性能分析,方便我们发现性能问题究竟发生在哪里。比如我们提交一个表单很慢,通过APM分析我们很容易发现究竟是调用哪个业务服务慢,或者是处理哪个SQL语句慢。这样可以极大的提升我们性能问题分析诊断的效率。
感谢您的阅读,也欢迎您发表关于这篇文章的任何建议,关注我,技术不迷茫!小编到你上高速。
正文结束
1.不认命,从10年流水线工人,到谷歌上班的程序媛,一位湖南妹子的励志故事
