
11种方法教你用Python高效下载资源!
在本教程中,你将学习如何使用不同的Python模块从web下载文件。此外,你将下载常规文件、web页面、Amazon S3和其他资源。
最后,你将学习如何克服可能遇到的各种挑战,例如下载重定向的文件、下载大型文件、完成一个多线程下载以及其他策略。
1
使用requests
你可以使用requests模块从一个URL下载文件。
考虑以下代码:

你只需使用requests模块的get方法获取URL,并将结果存储到一个名为“myfile”的变量中。然后,将这个变量的内容写入文件。
2
使用wget

你还可以使用Python的wget模块从一个URL下载文件。你可以使用pip按以下命令安装wget模块:
考虑以下代码,我们将使用它下载Python的logo图像。

在这段代码中,URL和路径(图像将存储在其中)被传递给wget模块的download方法。
3
下载重定向的文件
在本节中,你将学习如何使用requests从一个URL下载文件,该URL会被重定向到另一个带有一个.pdf文件的URL。该URL看起来如下:

要下载这个pdf文件,请使用以下代码:

在这段代码中,我们第一步指定的是URL。然后,我们使用request模块的get方法来获取该URL。在get方法中,我们将allow_redirects设置为True,这将允许URL中的重定向,并且重定向后的内容将被分配给变量myfile。
最后,我们打开一个文件来写入获取的内容。
4
分块下载大文件
考虑下面的代码:

首先,我们像以前一样使用requests模块的get方法,但是这一次,我们将把stream属性设置为True。
接着,我们在当前工作目录中创建一个名为PythonBook.pdf的文件,并打开它进行写入。
然后,我们指定每次要下载的块大小。我们已经将其设置为1024字节,接着遍历每个块,并在文件中写入这些块,直到块结束。
不漂亮吗?不要担心,稍后我们将显示一个下载过程的进度条。
5
下载多个文件(并行/批量下载)
要同时下载多个文件,请导入以下模块:

我们导入了os和time模块来检查下载文件需要多少时间。ThreadPool模块允许你使用池运行多个线程或进程。
让我们创建一个简单的函数,将响应分块发送到一个文件:
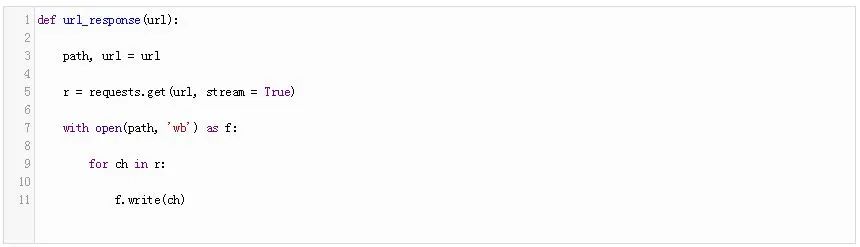
这个URL是一个二维数组,它指定了你要下载的页面的路径和URL。

就像在前一节中所做的那样,我们将这个URL传递给requests.get。最后,我们打开文件(URL中指定的路径)并写入页面内容。
现在,我们可以分别为每个URL调用这个函数,我们也可以同时为所有URL调用这个函数。让我们在for循环中分别为每个URL调用这个函数,注意计时器:

现在,使用以下代码行替换for循环:

运行该脚本。
6
使用进度条进行下载
进度条是clint模块的一个UI组件。输入以下命令来安装clint模块:

考虑以下代码:
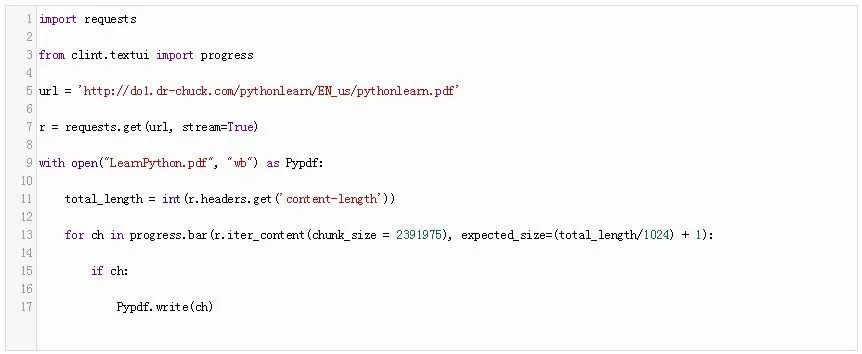
在这段代码中,我们首先导入了requests模块,然后,我们从clint.textui导入了进度组件。唯一的区别是在for循环中。在将内容写入文件时,我们使用了进度条模块的bar方法。
7
使用urllib下载网页
在本节中,我们将使用urllib下载一个网页。
urllib库是Python的标准库,因此你不需要安装它。
以下代码行可以轻松地下载一个网页:

在这里指定你想将文件保存为什么以及你想将它存储在哪里的URL。

在这段代码中,我们使用了urlretrieve方法并传递了文件的URL,以及保存文件的路径。文件扩展名将是.html。
8
通过代理下载
如果你需要使用代理下载你的文件,你可以使用urllib模块的ProxyHandler。请看以下代码:
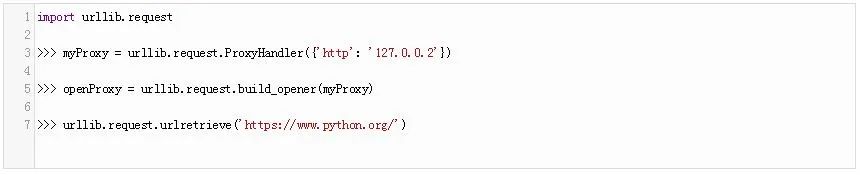
在这段代码中,我们创建了代理对象,并通过调用urllib的build_opener方法来打开该代理,并传入该代理对象。然后,我们创建请求来获取页面。
此外,你还可以按照官方文档的介绍来使用requests模块:

你只需要导入requests模块并创建你的代理对象。然后,你就可以获取文件了。
9
使用urllib3
urllib3是urllib模块的改进版本。你可以使用pip下载并安装它:

我们将通过使用urllib3来获取一个网页并将它存储在一个文本文件中。
导入以下模块:

在处理文件时,我们使用了shutil模块。
现在,我们像这样来初始化URL字符串变量:

然后,我们使用了urllib3的PoolManager ,它会跟踪必要的连接池。

创建一个文件:

最后,我们发送一个GET请求来获取该URL并打开一个文件,接着将响应写入该文件:

10
使用Boto3从S3下载文件
要从Amazon S3下载文件,你可以使用Python boto3模块。
在开始之前,你需要使用pip安装awscli模块:

对于AWS配置,请运行以下命令:

现在,按以下命令输入你的详细信息:

要从Amazon S3下载文件,你需要导入boto3和botocore。Boto3是一个Amazon SDK,它允许Python访问Amazon web服务(如S3)。Botocore提供了与Amazon web服务进行交互的命令行服务。
Botocore自带了awscli。要安装boto3,请运行以下命令:

现在,导入这两个模块:

在从Amazon下载文件时,我们需要三个参数:
Bucket名称
你需要下载的文件名称
文件下载之后的名称
初始化变量:

现在,我们初始化一个变量来使用会话的资源。为此,我们将调用boto3的resource()方法并传入服务,即s3:

最后,使用download_file方法下载文件并传入变量:

11
使用asyncio
asyncio模块主要用于处理系统事件。它围绕一个事件循环进行工作,该事件循环会等待事件发生,然后对该事件作出反应。这个反应可以是调用另一个函数。这个过程称为事件处理。asyncio模块使用协同程序进行事件处理。
要使用asyncio事件处理和协同功能,我们将导入asyncio模块:

现在,像这样定义asyncio协同方法:

关键字async表示这是一个原生asyncio协同程序。在协同程序的内部,我们有一个await关键字,它会返回一个特定的值。我们也可以使用return关键字。
现在,让我们使用协同创建一段代码来从网站下载一个文件:

在这段代码中,我们创建了一个异步协同函数,它会下载我们的文件并返回一条消息。
然后,我们使用另一个异步协同程序调用main_func,它会等待URL并将所有URL组成一个队列。asyncio的wait函数会等待协同程序完成。
现在,为了启动协同程序,我们必须使用asyncio的get_event_loop()方法将协同程序放入事件循环中,最后,我们使用asyncio的run_until_complete()方法执行该事件循环。
使用Python下载文件是很有趣的。希望本教程对你有用!
【提高】40多个项目实战,老手可以从真实场景中学习python;
【直播】不定期直播项目案例讲解,手把手教你如何分析项目;
【分享】优质python学习资料分享,让你在最短时间获得有价值的学习资源;圈友优质资料或学习分享,会不时给予赞赏支持,希望每个优质圈友既能赚回加入费用,也能快速成长,并享受分享与帮助他人的乐趣。
【人脉】收获一群志同道合的朋友,并且都是python从业者
【价格】本着布道思想,只需 69元 加入一个能保证学习效果的良心圈子。