
教你用 Python 实现 HashMap 数据结构

今天这篇文章给大家讲讲hashmap,这个号称是所有Java工程师都会的数据结构。为什么说是所有Java工程师都会呢,因为很简单,他们不会这个找不到工作。几乎所有面试都会问,基本上已经成了标配了。
在今天的这篇文章当中我们会揭开很多谜团。比如,为什么hashmap的get和put操作的复杂度是,甚至比红黑树还要快?hashmap和hash算法究竟是什么关系?hashmap有哪些参数,这些参数分别是做什么用的?hashmap是线程安全的吗?我们怎么来维护hashmap的平衡呢?
让我们带着疑问来看看hashmap的基本结构。
基本结构
hashmap这个数据结构其实并不难,它的结构非常非常清楚,我用一句话就可以说明,其实就是邻接表。虽然这两者的用途迥然不同,但是它们的结构是完全一样的。说白了就是一个定长的数组,这个数组的每一个元素都是一个链表的头结点。我们把这个结构画出来,大家一看就明白了。
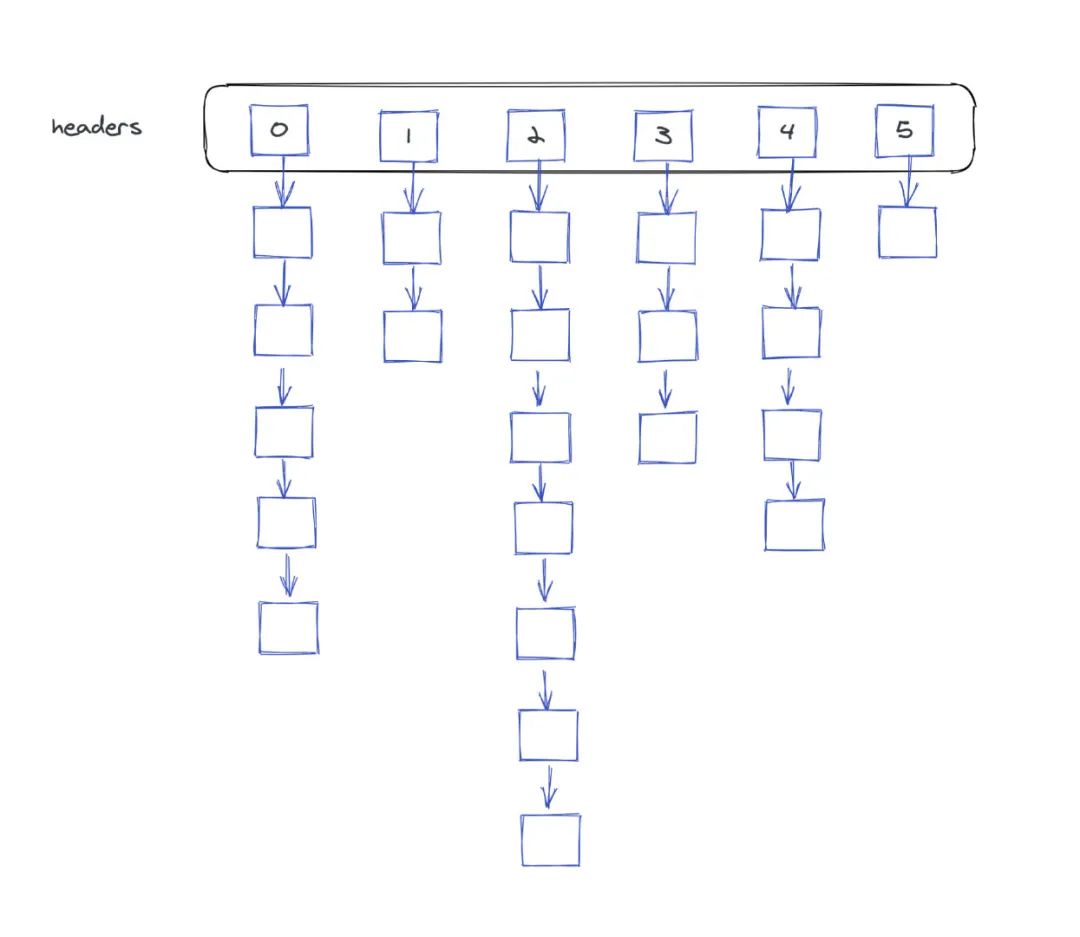
headers是一个定长的数组,数组当中的每一个元素都是一个链表的头结点。也就是说根据这个头结点,我们可以遍历这个链表。数组是定长的,但是链表是变长的,所以如果我们发生元素的增删改查,本质上都是通过链表来实现的。
这个就是hashmap的基本结构,如果在面试当中问到,你可以直接回答:它本质上就是一个元素是链表的数组。
hash的作用
现在我们搞明白了hashmap的基本结构,现在进入下一个问题,这么一个结构和hash之间有什么关系呢?
其实也不难猜,我们来思考一个场景。假设我们已经拥有了一个hashmap,现在新来了一份数据需要存储。上图当中数组的长度是6,也就是说有6个链表可供选择,那么我们应该把这个新来的元素放在哪个链表当中呢?
你可能会说当然是放在最短的那个,这样链表的长度才能平衡。这样的确不错,但是有一个问题,这样虽然存储方便了,但是读取的时候却有很大的问题。因为我们存储的时候知道是存在最短的链表里了,但是当我们读取的时候,我们是不知道当初哪个链表最短了,很有可能整个结构已经面目全非了。所以我们不能根据这种动态的量来决定节点的放置位置,必须要根据静态的量来决定。
这个静态的量就是hash值,我们都知道hash算法的本质上是进行一个映射运算,将一个任意结构的值映射到一个整数上。我们的理想情况是不同的值映射的结果不同,相同的值映射的结果相同。也就是说一个变量和一个整数是一一对应的。但是由于我们的整数数量是有限的,而变量的取值是无穷的,那么一定会有一些变量虽然它们并不相等但是它们映射之后的结果是一样的。这种情况叫做hash碰撞。
在hashmap当中我们并不需要理会hash碰撞,因为我们并不追求不同的key能够映射到不同的值。因为我们只是要用这个hash值来决定这个节点应该存放在哪一条链表当中。只要hash函数确定了,只要值不变,计算得到的hash值也不会变。所以我们查询的时候也可以遵循这个逻辑,找到key对应的hash值以及对应的链表。
在Python当中由于系统提供了hash函数,所以整个过程变得更加方便。我们只需要两行代码就可以找到key对应的链表。
hash_key = hash(key) % len(self.headers)
linked_list = self.headers[hash_key]
get、put实现
明白了hash函数的作用了之后,hashmap的问题就算是解决了大半。因为剩下的就是一个在链表当中增删改查的问题了,比如我们要通过key查找value的时候。当我们通过hash函数确定了是哪一个链表之后,剩下的就是遍历这个链表找到这个值。
这个函数我们可以实现在LinkedList这个类当中,非常简单,就是一个简单的遍历:
def get_by_key(self, key):
cur = self.head.succ
while cur != self.tail:
if cur.key == key:
return cur
cur = cur.succ
return None
链表的节点查询逻辑有了之后,hashmap的查询逻辑也就有了。因为本质上只做了两件事,一件事根据hash函数的值找到对应的链表,第二件事就是遍历这个链表,找到这个节点。
我们也很容易实现:
def get(self, key):
hash_key = self.get_hash_key(key)
linked_list = self.headers[hash_key]
node = linked_list.get_by_key(key)
return node
get方法实现了之后,写出put方法也一样水到渠成,因为put方法逻辑和get相反。我们把查找换成添加或者是修改即可:
def put(self, key, val):
node = self.get(key)
# 如果能找到,那么只需要更新即可
if node is not None:
node.val = val
else:
# 否则我们在链表当中添加一个节点
node = Node(key, val)
linked_list.append(node)
复杂度的保障
get和put都实现了,整个hashmap是不是就实现完了?很显然没有,因为还有一件很重要的事情我们没有做,就是保证hashmap的复杂度。
我们简单分析一下就会发现,这样实现的hashmap有一个重大的问题。就是由于hashmap一开始的链表的数组是定长的,不管这个数组多长,只要我们存储的元素足够多,那么每一个链表当中分配到的元素也就会非常多。我们都知道链表的遍历速度是,这样我们还怎么保证查询的速度是常数级呢?
除此之外还有另外一个问题,就是hash值倾斜的问题。比如明明我们的链表有100个,但是我们的数据刚好hash值大部分对100取模之后都是0。于是大量的数据就会被存储在0这个桶当中,导致其他桶没什么数据,就这一个桶爆满。对于这种情况我们又怎么避免呢?
其实不论是数据过多也好,还是分布不均匀也罢,其实说的都是同一种情况。就是至少一个桶当中存储的数据过多,导致效率降低。针对这种情况,hashmap当中设计了一种检查机制,一旦某一个桶当中的元素超过某个阈值,那么就会触发reset。也就是把hashmap当中的链表数量增加一倍,并且把数据全部打乱重建。这个阈值是通过一个叫做load_factor的参数设置的,当某一个桶当中的元素大于load_factor * capacity的时候,就会触发reset机制。
我们把reset的逻辑加进去,那么put函数就变成了这样:
def put(self, key, val):
hash_key = self.get_hash_key(key)
linked_list = self.headers[hash_key]
# 如果超过阈值
if linked_list.size >= self.load_factor * self.capacity:
# 进行所有数据reset
self.reset()
# 对当前要加入的元素重新hash分桶
hash_key = self.get_hash_key(key)
linked_list = self.headers[hash_key]
node = linked_list.get_by_key(key)
if node is not None:
node.val = val
else:
node = Node(key, val)
linked_list.append(node)
reset的逻辑也很简单,我们把数组的长度扩大一倍,然后把原本的数据一一读取出来,重新hash分配到新的桶当中即可。
def reset(self):
# 数组扩大一倍
headers = [LinkedList() for _ in range(self.capacity * 2)]
cap = self.capacity
# capacity也扩大一倍
self.capacity = self.capacity * 2
for i in range(cap):
linked_list = self.headers[i]
nodes = linked_list.get_list()
# 将原本的node一个一个填入新的链表当中
for u in nodes:
hash_key = self.get_hash_key(u.key)
head = headers[hash_key]
head.append(u)
self.headers = headers
其实这里的阈值就是我们的最大查询时间,我们可以把它近似看成是一个比较大的常量,那么put和get的效率就有保障了。因为插入了大量数据或者是刚好遇到了hash不平均的情况我们就算是都解决了。
细节和升华
如果你读过JDK当中hashmap的源码,你会发现hashmap的capacity也就是链表的数量是2的幂。这是为什么呢?
其实也很简单,因为按照我们刚才的逻辑,当我们通过hash函数计算出了hash值之后,还需要将这个值对capacity进行取模。也就是hash(key) % capacity,这一点在刚才的代码当中也有体现。
这里有一个小问题就是取模运算非常非常慢,在系统层面级比加减乘慢了数十倍。为了优化和提升这个部分的性能,所以我们使用2的幂,这样我们就可以用hash(key) & (capacity - 1)来代替hash(key) % capacity,因为当capacity是2的幂时,这两者计算是等价的。我们都知道位运算的计算速度是计算机当中所有运算最快的,这样我们可以提升不少的计算效率。
最后聊一聊线程安全,hashmap是线程安全的吗?答案很简单,当然不是。因为里面没有任何加锁或者是互斥的限制,A线程在修改一个节点,B线程也可以同时在读取同样的节点。那么很容易出现问题,尤其是还有reset这种时间比较长的操作。如果刚好在reset期间来了其他的查询,那么结果一定是查询不到,但很有可能这个数据是存在的。所以hashmap不是线程安全的,不可以在并发场景当中使用。
最后,我们附上hashmap完整的实现代码:
import random
class Node:
def __init__(self, key, val, prev=None, succ=None):
self.key = key
self.val = val
# 前驱
self.prev = prev
# 后继
self.succ = succ
def __repr__(self):
return str(self.val)
class LinkedList:
def __init__(self):
self.head = Node(None, 'header')
self.tail = Node(None, 'tail')
self.head.succ = self.tail
self.tail.prev = self.head
self.size = 0
def append(self, node):
# 将node节点添加在链表尾部
prev = self.tail.prev
node.prev = prev
node.succ = prev.succ
prev.succ = node
node.succ.prev = node
self.size += 1
def delete(self, node):
# 删除节点
prev = node.prev
succ = node.succ
succ.prev, prev.succ = prev, succ
self.size -= 1
def get_list(self):
# 返回一个包含所有节点的list,方便上游遍历
ret = []
cur = self.head.succ
while cur != self.tail:
ret.append(cur)
cur = cur.succ
return ret
def get_by_key(self, key):
cur = self.head.succ
while cur != self.tail:
if cur.key == key:
return cur
cur = cur.succ
return None
class HashMap:
def __init__(self, capacity=16, load_factor=5):
self.capacity = capacity
self.load_factor = load_factor
self.headers = [LinkedList() for _ in range(capacity)]
def get_hash_key(self, key):
return hash(key) & (self.capacity - 1)
def put(self, key, val):
hash_key = self.get_hash_key(key)
linked_list = self.headers[hash_key]
if linked_list.size >= self.load_factor * self.capacity:
self.reset()
hash_key = self.get_hash_key(key)
linked_list = self.headers[hash_key]
node = linked_list.get_by_key(key)
if node is not None:
node.val = val
else:
node = Node(key, val)
linked_list.append(node)
def get(self, key):
hash_key = self.get_hash_key(key)
linked_list = self.headers[hash_key]
node = linked_list.get_by_key(key)
return node.val if node is not None else None
def delete(self, key):
node = self.get(key)
if node is None:
return False
hash_key = self.get_hash_key(key)
linked_list = self.headers[hash_key]
linked_list.delete(node)
return True
def reset(self):
headers = [LinkedList() for _ in range(self.capacity * 2)]
cap = self.capacity
self.capacity = self.capacity * 2
for i in range(cap):
linked_list = self.headers[i]
nodes = linked_list.get_list()
for u in nodes:
hash_key = self.get_hash_key(u.key)
head = headers[hash_key]
head.append(u)
self.headers = headers
今天的文章就到这里,衷心祝愿大家每天都有所收获。如果还喜欢今天的内容的话,请来一个三连支持吧~(点赞、在看、转发)

优质文章,推荐阅读:
