
微服务的熔断原理与实现
在微服务中服务间依赖非常常见,比如评论服务依赖审核服务而审核服务又依赖反垃圾服务,当评论服务调用审核服务时,审核服务又调用反垃圾服务,而这时反垃圾服务超时了,由于审核服务依赖反垃圾服务,反垃圾服务超时导致审核服务逻辑一直等待,而这个时候评论服务又在一直调用审核服务,审核服务就有可能因为堆积了大量请求而导致服务宕机
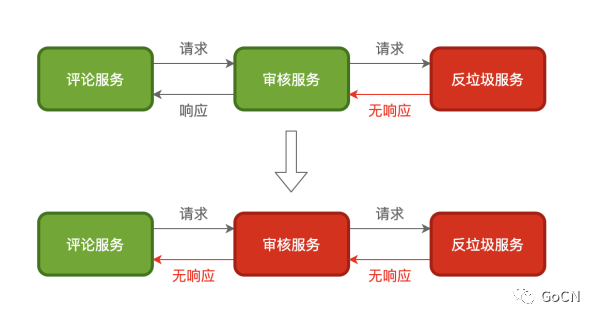
由此可见,在整个调用链中,中间的某一个环节出现异常就会引起上游调用服务出现一些列的问题,甚至导致整个调用链的服务都宕机,这是非常可怕的。因此一个服务作为调用方调用另一个服务时,为了防止被调用服务出现问题进而导致调用服务出现问题,所以调用服务需要进行自我保护,而保护的常用手段就是熔断
熔断器原理
熔断机制其实是参考了我们日常生活中的保险丝的保护机制,当电路超负荷运行时,保险丝会自动的断开,从而保证电路中的电器不受损害。而服务治理中的熔断机制,指的是在发起服务调用的时候,如果被调用方返回的错误率超过一定的阈值,那么后续的请求将不会真正发起请求,而是在调用方直接返回错误
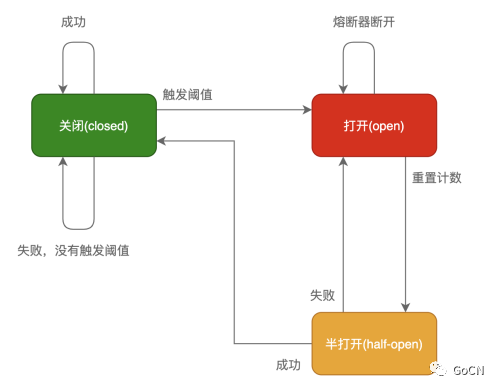
在这种模式下,服务调用方为每一个调用服务 (调用路径) 维护一个状态机,在这个状态机中有三个状态:
关闭 (Closed):在这种状态下,我们需要一个计数器来记录调用失败的次数和总的请求次数,如果在某个时间窗口内,失败的失败率达到预设的阈值,则切换到断开状态,此时开启一个超时时间,当到达该时间则切换到半关闭状态,该超时时间是给了系统一次机会来修正导致调用失败的错误,以回到正常的工作状态。在关闭状态下,调用错误是基于时间的,在特定的时间间隔内会重置,这能够防止偶然错误导致熔断器进去断开状态
打开 (Open):在该状态下,发起请求时会立即返回错误,一般会启动一个超时计时器,当计时器超时后,状态切换到半打开状态,也可以设置一个定时器,定期的探测服务是否恢复
半打开 (Half-Open):在该状态下,允许应用程序一定数量的请求发往被调用服务,如果这些调用正常,那么可以认为被调用服务已经恢复正常,此时熔断器切换到关闭状态,同时需要重置计数。如果这部分仍有调用失败的情况,则认为被调用方仍然没有恢复,熔断器会切换到关闭状态,然后重置计数器,半打开状态能够有效防止正在恢复中的服务被突然大量请求再次打垮
服务治理中引入熔断机制,使得系统更加稳定和有弹性,在系统从错误中恢复的时候提供稳定性,并且减少了错误对系统性能的影响,可以快速拒绝可能导致错误的服务调用,而不需要等待真正的错误返回
熔断器引入
上面介绍了熔断器的原理,在了解完原理后,你是否有思考我们如何引入熔断器呢?一种方案是在业务逻辑中可以加入熔断器,但显然是不够优雅也不够通用的,因此我们需要把熔断器集成在框架内,在zRPC框架内就内置了熔断器
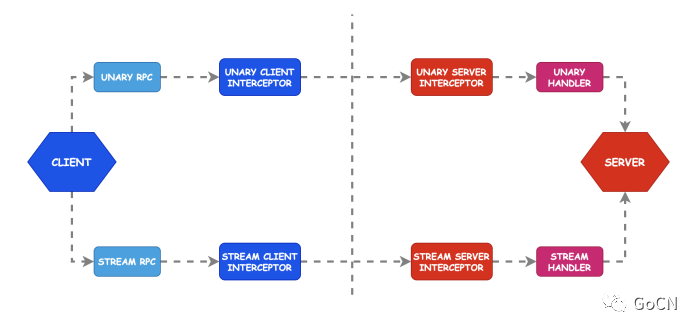
我们知道,熔断器主要是用来保护调用端,调用端在发起请求的时候需要先经过熔断器,而客户端拦截器正好兼具了这个这个功能,所以在 zRPC 框架内熔断器是实现在客户端拦截器内,拦截器的原理如下图:
对应的代码为:
func BreakerInterceptor(ctx context.Context, method string, req, reply interface{},
cc *grpc.ClientConn, invoker grpc.UnaryInvoker, opts ...grpc.CallOption) error {
// 基于请求方法进行熔断
breakerName := path.Join(cc.Target(), method)
return breaker.DoWithAcceptable(breakerName, func() error {
// 真正发起调用
return invoker(ctx, method, req, reply, cc, opts...)
// codes.Acceptable判断哪种错误需要加入熔断错误计数
}, codes.Acceptable)
}
熔断器实现
zRPC 中熔断器的实现参考了Google Sre 过载保护算法,该算法的原理如下:
请求数量 (requests):调用方发起请求的数量总和
请求接受数量 (accepts):被调用方正常处理的请求数量
在正常情况下,这两个值是相等的,随着被调用方服务出现异常开始拒绝请求,请求接受数量 (accepts) 的值开始逐渐小于请求数量 (requests),这个时候调用方可以继续发送请求,直到 requests = K * accepts,一旦超过这个限制,熔断器就回打开,新的请求会在本地以一定的概率被抛弃直接返回错误,概率的计算公式如下:
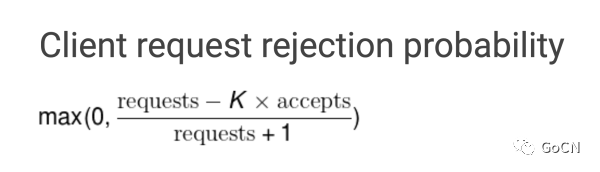
通过修改算法中的 K(倍值),可以调节熔断器的敏感度,当降低该倍值会使自适应熔断算法更敏感,当增加该倍值会使得自适应熔断算法降低敏感度,举例来说,假设将调用方的请求上限从 requests = 2 * acceptst 调整为 requests = 1.1 * accepts 那么就意味着调用方每十个请求之中就有一个请求会触发熔断
代码路径为 go-zero/core/breaker
type googleBreaker struct {
k float64 // 倍值 默认1.5
stat *collection.RollingWindow // 滑动时间窗口,用来对请求失败和成功计数
proba *mathx.Proba // 动态概率
}
自适应熔断算法实现
func (b *googleBreaker) accept() error {
accepts, total := b.history() // 请求接受数量和请求总量
weightedAccepts := b.k * float64(accepts)
// 计算丢弃请求概率
dropRatio := math.Max(0, (float64(total-protection)-weightedAccepts)/float64(total+1))
if dropRatio <= 0 {
return nil
}
// 动态判断是否触发熔断
if b.proba.TrueOnProba(dropRatio) {
return ErrServiceUnavailable
}
return nil
}
每次发起请求会调用 doReq 方法,在这个方法中首先通过 accept 效验是否触发熔断,acceptable 用来判断哪些 error 会计入失败计数,定义如下:
func Acceptable(err error) bool {
switch status.Code(err) {
case codes.DeadlineExceeded, codes.Internal, codes.Unavailable, codes.DataLoss: // 异常请求错误
return false
default:
return true
}
}
如果请求正常则通过 markSuccess 把请求数量和请求接受数量都加一,如果请求不正常则只有请求数量会加一
func (b *googleBreaker) doReq(req func() error, fallback func(err error) error, acceptable Acceptable) error {
// 判断是否触发熔断
if err := b.accept(); err != nil {
if fallback != nil {
return fallback(err)
} else {
return err
}
}
defer func() {
if e := recover(); e != nil {
b.markFailure()
panic(e)
}
}()
// 执行真正的调用
err := req()
// 正常请求计数
if acceptable(err) {
b.markSuccess()
} else {
// 异常请求计数
b.markFailure()
}
return err
}
总结
调用端可以通过熔断机制进行自我保护,防止调用下游服务出现异常,或者耗时过长影响调用端的业务逻辑,很多功能完整的微服务框架都会内置熔断器。其实,不仅微服务调用之间需要熔断器,在调用依赖资源的时候,比如 mysql、redis 等也可以引入熔断器的机制。
项目地址
https://github.com/tal-tech/go-zero
熔断器实现
https://github.com/tal-tech/go-zero/tree/master/core/breaker