
为什么随机 IP、随机 UA 也逃不掉被反爬虫的命运
有些同学在写爬虫的时候,觉得只要自己每次请求都使用不同的代理 IP,每次请求的 Headers 都写得跟浏览器的一模一样,就不会被网站发现。
但实际上,还有一个东西,叫做浏览器指纹,它是不会随着你更换 IP 或者 User-Agent 而改变的。
而且即使你不使用模拟浏览器,你直接使用 Golang、使用 Python,它们也有自己各自的指纹,并且他们的指纹每次请求也是固定的。
只要网站发现某个拥有特定指纹的客户端持续高频率请求网站,它就可以把你封掉。
你似乎不相信?那我证明给你看。
现在,我准备一个隧道代理,如下图所示:
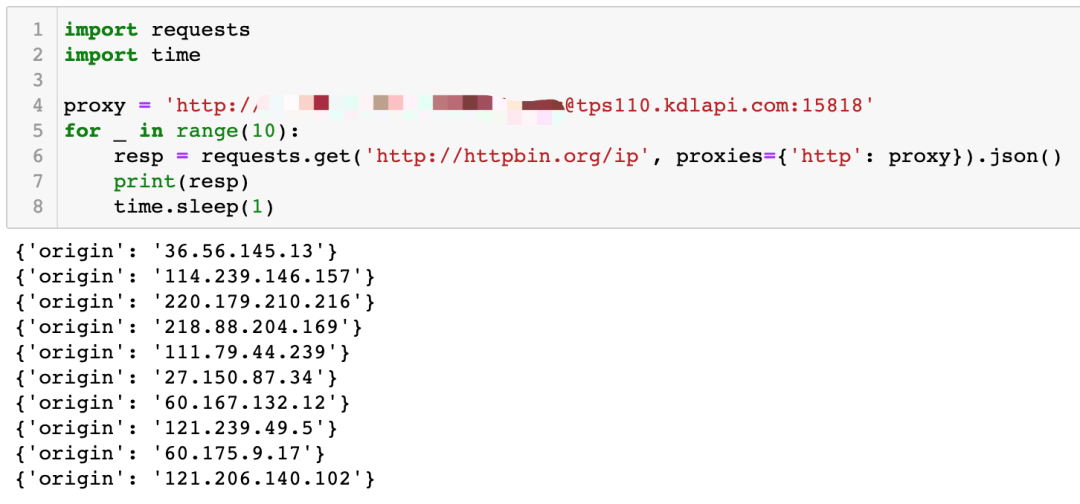
然后,我们打开一个网站:https://ja3er.com/json . 当你用电脑浏览器打开它的时候,它是这样的:
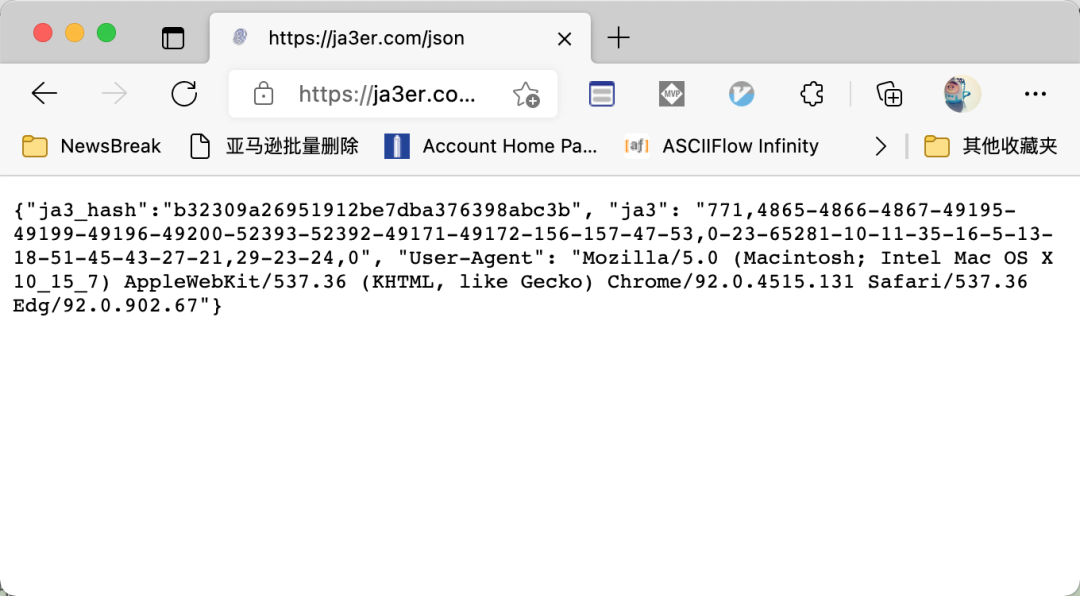
不论你怎么刷新网页,这上面的字符串都是不会变的。
现在,我使用 Python 去请求这个页面,看到的内容如下图所示:
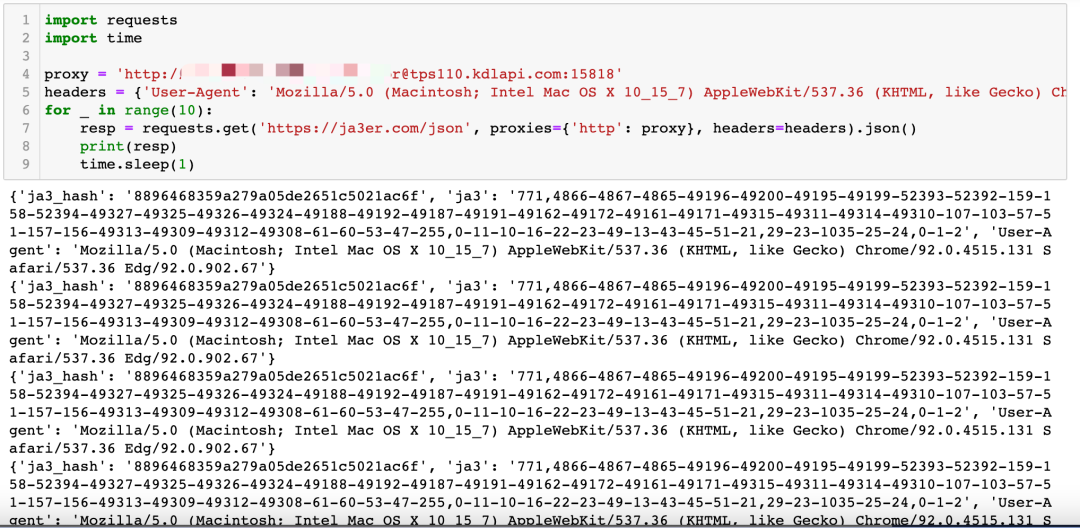
可以看到,虽然我使用了隧道代理,每次请求的 IP 都是不一样的,但是这个网站返回的内容始终是一样的。
所以如果这不是一个测试网站,而是一个加了这个检测机制的网站,那么它轻松就能把我给屏蔽了。
这个检测算法,叫做JA3算法。这个算法在官网上面的介绍信息如下:
The JA3 algorithm takes a collection of settings from the SSL “Client Hello” such as SSL/TLS version, accepted cipher suites, list of extensions, accepted elliptic curves, and elliptic curve formats.
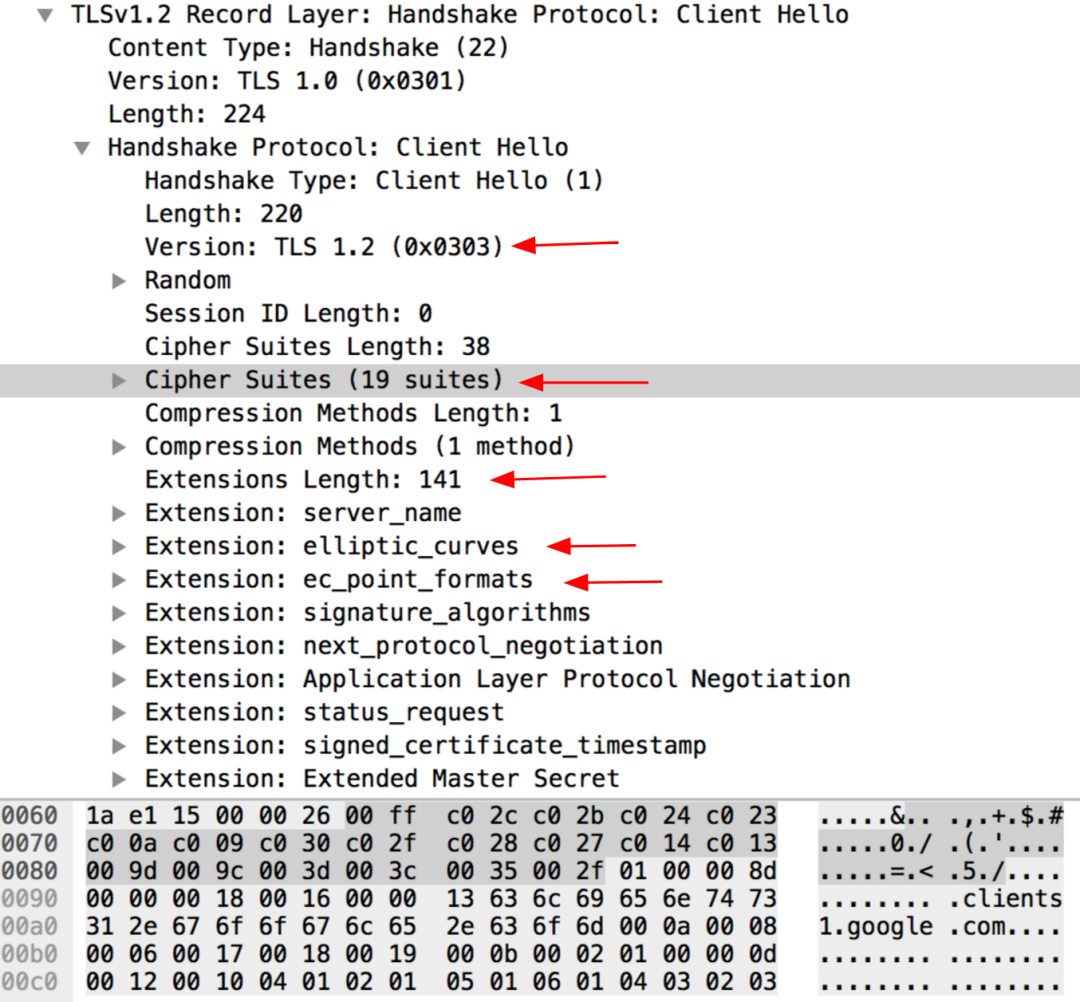
JA3算法收集了 SSL 请求里面的信息,包括但不限于 SSL/TLS 版本,Cipher Suites数量,浏览器扩展列表,elliptic curves等等。
通过这一系列参数综合起来生成一个指纹字符串。也许这些参数里面,你跟一些人的 Cipher Suites 数量相同,你跟另外一些人的浏览器扩展数相同,你又跟另外一些人的 TLS版本号相同……但是所有这些参数全部相同的人,就非常少了。
而在这非常少的人里面,这些人还同时访问同一个网站的可能性就更小了。所以,网站用 JA3算法,可以近似认为,在一段时间内,指纹字符串相同的连续请求,有极大概率是来自同一个人。
JA3算法的三个作者之一John Althouse写了一篇文章来介绍浏览器指纹和 JA3算法:TLS Fingerprinting with JA3 and JA3S | by John Althouse | Salesforce Engineering[1] 。有兴趣的同学可以看一看。
但我们说,魔高一尺,道高一丈。JA3算法是不是真的无懈可击呢?其实也不是,仍然有办法绕过去的。请大家期待我后面的文章。
P.S.: 给大家科普一个小知识,日常生活中,我们常常听一些人说,道高一尺,魔高一丈,又听另一些人说,魔高一尺,道高一丈。那么这两句到底哪一句是对的,什么情况下应该用哪一句呢?
其实,以道高一尺,魔高一丈为例,它的意思是,道非常厉害,道往上涨一尺所产生的力量,魔需要往上涨一丈才能抵消。通俗的讲,就是巨人走一步,普通人要走十步才能追的上。
同理,魔高一尺,道高一丈的意思是魔非常厉害,魔往上涨一尺所产生的力量,道需要往上涨一丈才能抵消。
但我们日常生活中,很多人以为,魔高一尺,道高一丈的意思是说,魔长高一尺的时间,道已经长高了一丈,所以魔永远追不上道。这种理解是错误的,这些人刚好把意思搞反。
参考资料
TLS Fingerprinting with JA3 and JA3S | by John Althouse | Salesforce Engineering: https://engineering.salesforce.com/tls-fingerprinting-with-ja3-and-ja3s-247362855967



秀啊!用Python斗地主,欢乐豆蹭蹭涨!

10 分钟 纯 Python 搭建全文搜索引擎