
每日一道 LeetCode (4):罗马数字转整数

题目:罗马数字转整数
题目来源:https://leetcode-cn.com/problems/roman-to-integer/
罗马数字包含以下七种字符: I, V, X, L,C,D 和 M。
字符 数值
I 1
V 5
X 10
L 50
C 100
D 500
M 1000
例如, 罗马数字 2 写做 II ,即为两个并列的 1。12 写做 XII ,即为 X + II 。27 写做 XXVII, 即为 XX + V + II 。
通常情况下,罗马数字中小的数字在大的数字的右边。但也存在特例,例如 4 不写做 IIII,而是 IV。数字 1 在数字 5 的左边,所表示的数等于大数 5 减小数 1 得到的数值 4 。同样地,数字 9 表示为 IX。这个特殊的规则只适用于以下六种情况:
I 可以放在 V (5) 和 X (10) 的左边,来表示 4 和 9。 X 可以放在 L (50) 和 C (100) 的左边,来表示 40 和 90。 C 可以放在 D (500) 和 M (1000) 的左边,来表示 400 和 900。
给定一个罗马数字,将其转换成整数。输入确保在 1 到 3999 的范围内。
示例 1:
输入: "III"
输出: 3
示例 2:
输入: "IV"
输出: 4
示例 3:
输入: "IX"
输出: 9
示例 4:
输入: "LVIII"
输出: 58
解释: L = 50, V= 5, III = 3.
示例 5:
输入: "MCMXCIV"
输出: 1994
解释: M = 1000, CM = 900, XC = 90, IV = 4.
解法
说实话,这道题我看到的时候,读了四五遍,愣是一点想法都没,只感觉要循环去解(这不是废话)。
思考了 5 分钟,愣是没想通,这时我深深的意识到自己并不是天才,这个词与我无关,还是乖乖去看答案吧。
果然,看了答案,立马就明白套路了。
我相信,我说了算法以后,哪怕一个刚接触编程的同学都能尝试着将这个算法写出来。
所以说,读懂题太特么重要了。
主要还是罗马数字我们平时接触的少,缺乏这方面的概念,至少我从小到大也就只在钟表表盘上见过罗马数字。

简单总结一下:
罗马数字由 I,V,X,L,C,D,M构成的。当小值在大值的左边,则减小值,如 IV=5-1=4。当小值在大值的右边,则加小值,如 VI=5+1=6。
最关键的一点,计算的时候从左往右算,右边的小,就把右边的数字加起来,右边的大,就把右边的数字减一下,最后一位加起来,结束。
我相信,如果把题目换成上面这句话,99% 的人都写的出来,下面开始放代码。
代码实现
public int romanToInt(String s) {
// 定义返回结果
int sum = 0;
int preNum = getValue(s.charAt(0));
for (int i = 1; i < s.length(); i++) {
int num = getValue(s.charAt(i));
if (preNum < num) {
sum -= preNum;
} else {
sum += preNum;
}
preNum = num;
}
sum += preNum;
return sum;
}
private int getValue(char ch) {
switch(ch) {
case 'I': return 1;
case 'V': return 5;
case 'X': return 10;
case 'L': return 50;
case 'C': return 100;
case 'D': return 500;
case 'M': return 1000;
default: return 0;
}
}
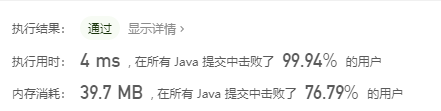
这个方法获取字母对应的数字是采用了遍历的方式,那么这里是不是可以优化一下,如果把这个对应关系放到 hash 表中,寻找的速度会不会更快?马上我又写了第二段代码做尝试。
public int romanToInt_1(String s) {
Map map = new HashMap<>();
map.put('I', 1);
map.put('V', 5);
map.put('X', 10);
map.put('L', 50);
map.put('C', 100);
map.put('D', 500);
map.put('M', 1000);
// 定义返回结果
int sum = 0;
int preNum = map.get(s.charAt(0));
for (int i = 1; i < s.length(); i++) {
int num = map.get(s.charAt(i));
if (preNum < num) {
sum -= preNum;
} else {
sum += preNum;
}
preNum = num;
}
sum += preNum;
return sum;
}

最终的结果有点失望,构建 hash 表占用了更多的内存,结果执行时间还比前面遍历的方式慢了 50% 。
这里我猜测是因为数据量小的原因,我们总共只往 hash 表中放了 7 个值,如果是放 700 个或者 7000 个值,hash 表的平均寻找速度肯定要比遍历来的快。
