深度课堂:全角度解读神经网络编译器


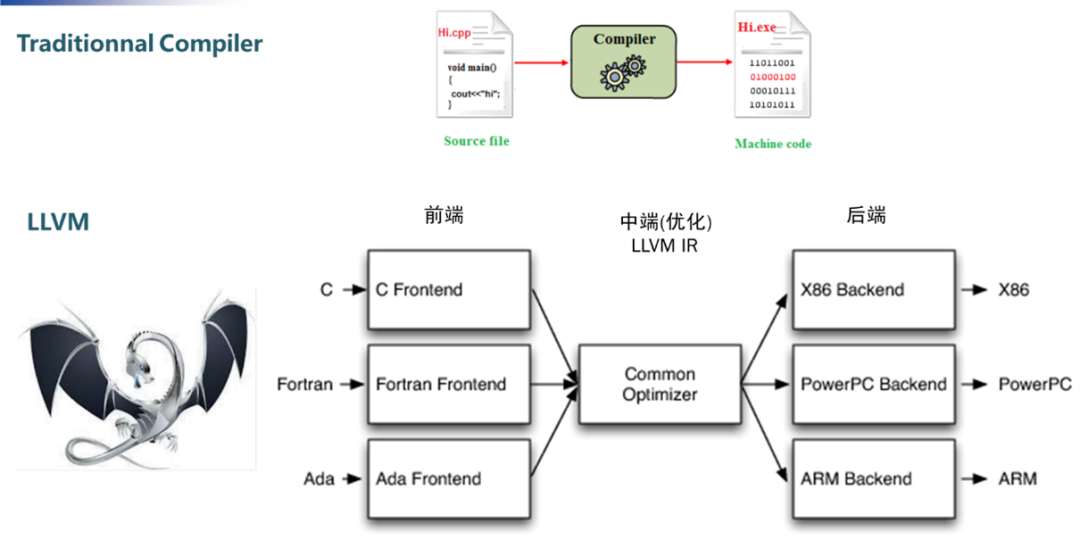
编译器的输入/输出:
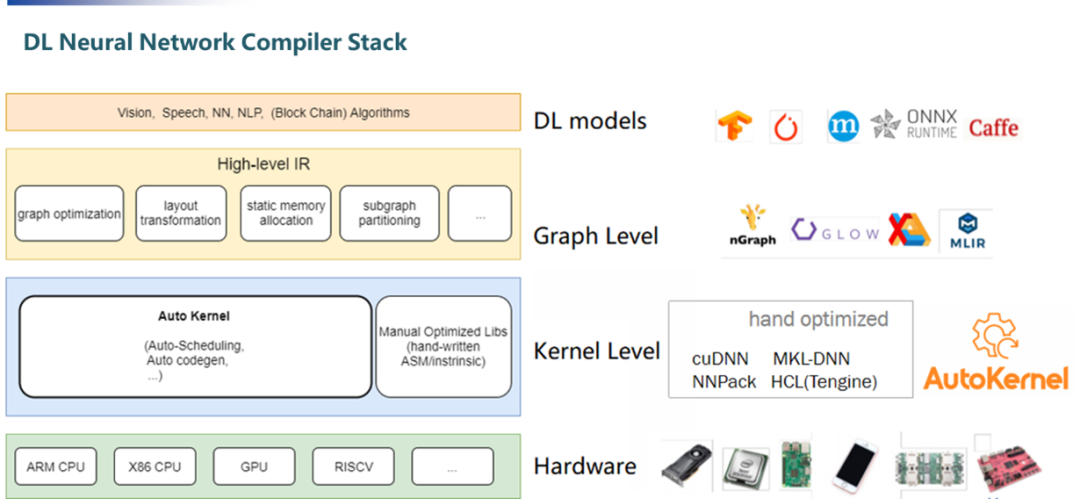
编译器的IR:


扫码添加OPEN AI LAB小助手
咨询产品/技术问题&加入技术交流群
TengineGitHub开源链接
https://github.com/OAID/Tengine
欢迎大家Star、Watch、Fork三部曲
往期· 看点


评论
 下载APP
下载APP编译器的输入/输出:
编译器的IR:
扫码添加OPEN AI LAB小助手
咨询产品/技术问题&加入技术交流群
TengineGitHub开源链接
https://github.com/OAID/Tengine
欢迎大家Star、Watch、Fork三部曲
往期· 看点