
移动端超分的磁悬浮,推理仅需10ms!港理工&达摩院开源超轻量超分网络ECB

极市导读
香港理工和达摩院张磊团队提出了一种即插即用的重参数模块,并基于该模构建了用于端侧设备的超轻量超分网络ECBSR,该工作取得与其他SOTA方案相当的性能并已开源。>>加入极市CV技术交流群,走在计算机视觉的最前沿

原文链接:https://www4.comp.polyu.edu.hk/~cslzhang/paper/MM21_ECBSR.pdf
代码链接:https://github.com/xindongzhang/ECBSR
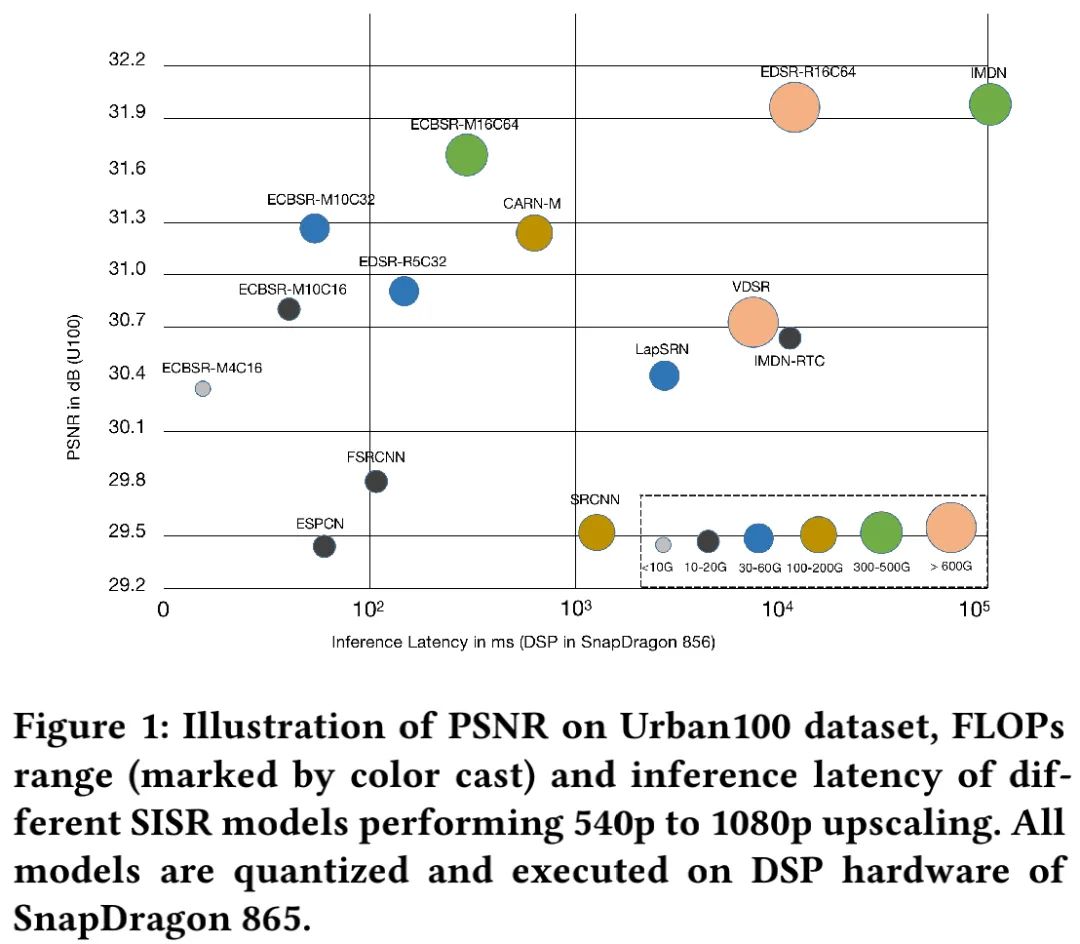
本文是香港理工&达摩院张磊团队(https://www4.comp.polyu.edu.hk/~cslzhang/)在移动端超分 方面的工作,已被ACM-MM2021接收。本文将low-level领域知识与重参数思想进行了巧妙结合,提出了一种新颖的模块:Edge-oriented Convolution Block(ECB) 。基于ECB构建了超轻量型且性能同样突出的ECBSR,在x4任务输出为1080p,硬件平台为骁龙865DSP上:
当性能媲美SRCNN/ESPCN时,ECBSR-M4C8在移动端推理仅需10ms ,而SRCNN与ESPCN分别需要1583ms、26ms;
当性能媲美LapSRN时,ECBSR-M10C32在移动端推理仅需17ms ,而LapSRN则需要5378ms;
当性能媲美IMDN、EDSR以及CARN时,ECBSR-M16C64在移动端的推理仅需71ms ,而IMDN、EDSR与CARN的推理则分别为2782ms、527ms、170ms。
Abstract
在实际应用场景中,高效轻量超分网络极具高需求。然而,现有研究大多聚焦于降低模型参数量与FLOPs,而这并不总是意味着更快的端侧推理速度。
本文提出了称之为ECB的重参数化模块用于高效超分网络设计。在训练阶段,ECB采用多分支方式提取特征:包含常规卷积、卷积、一阶与二阶梯度信息;在推理阶段,上述多个并行操作可以折叠为单个卷积。ECB可视作一种提升常规卷积性能的“即插即用 ”模块且不会引入额外的推理消耗。我们基于ECB提出了一种用于端侧设备的超轻量超分网络ECBSR。
所提ECBSR取得了与其他SOTA轻量超分方案相当的性能,同时可以在通用端侧设备(比如骁龙865SOC、天玑1000+SOC)上实时将270p/540p图像超分到1080p,可参考下图。
Method
我们首先基于端侧友好算子设计了一种基础模型,然后提出了一种重参数化的面向边缘的卷积模块提升超分性能。
Base Model
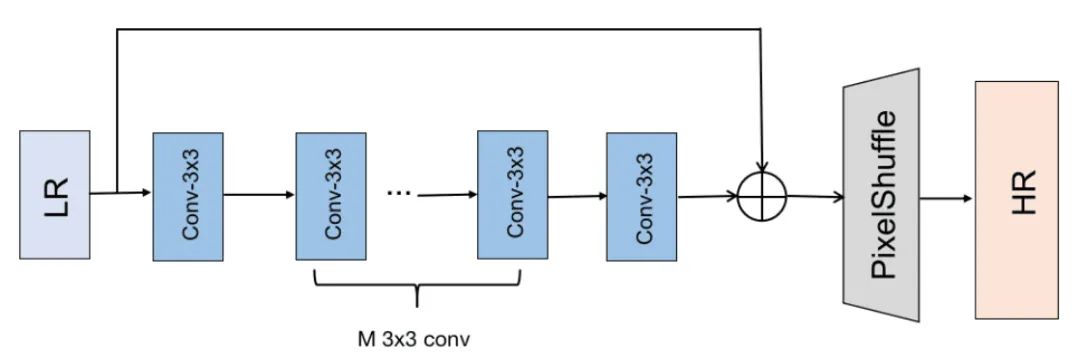
为确保高推理速度与跨设备部署(常见移动设备),我们在仔细考虑移动端设备有限计算资源与内存资源后,设计了一种仅由基础模块构成的基础模型,见上图(注:这里的图示应该是有问题的,起码是与论文开源的code不对应;code中对应的是类EDSR架构 )。
Neat Topology 尽管复杂的结果(比如多分支、稠密连接)可以在不引入过多FLOPs的前提下带来丰富的特征表达,但是这类结构会导致过高的MAC(Memory Access Cost, MAC)、牺牲并行度,进而降低推理速度。由于DDR的低带宽问题,这种现象在移动端尤为严重。比如,FSRCNN采用了简单的结构,FLOPs比IMDN-RTC稍高,但在骁龙865平台上FSRCNN的推理速度要快的多(大概快2个数量级 ,可参见前面的Figure1图示部分)。因此,我们将带宽限制问题纳入考虑后,设计了上述非常简单的结果以尽可能降低模型的MAC。
Basic Operations 不同于GPU端侧,移动端DSP/GPU/NPU上优化的算子非常有限且不同设备之前的优化程度也不一样,不支持的算子需要在CPU上进行处理,不仅会降低推理速度而且会引入额外的MAC。因此,我们仅仅采用了卷积(针对移动端DSP/GPU/NPU均进行了高度优化)提取特征,在上采样部分我们采用PixelShuffle。
上述所提基础模块非常适用于移动端场景,同时具有高效率与灵活性。在移动端,上述结果具有超快推理速度、更低MAC;此外,简单的基础操作使其非常适合跨设备部署。通过控制卷积数量与通道数,我们可以控制模型的复杂度以获取不同设备上更好的性能-速度均衡。
Edge-oriented Convolution Block
尽管上述结果非常高效,但其性能要弱于复杂的模型。因此,我们采用重参数技术(比如ACNet、DBB以及RepVGG)提升模型的表达能力。然而,在超分任务上直接采用技术带来的性能提升非常有限。针对超分任务,我们设计了一种更合适的重参数模块ECB(见下图),它可以更有效的提取边缘与纹理信息。从图示可以看到:ECB包含四种类型的算子。(注:下面的图示应该也是有问题的,第四个分支应该是 卷积,起码code中不是 )
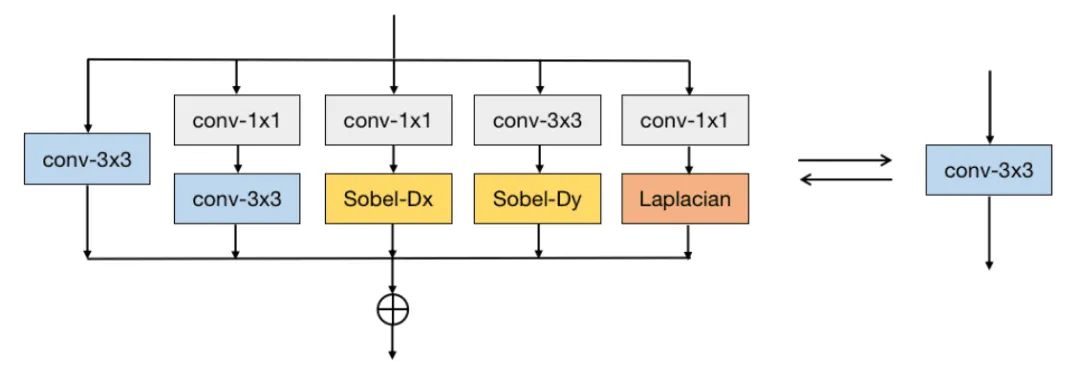
Component I: Normal 卷积 我们首先采用常规卷积以确保基线性能,类似于已有超分模型,我们同样并未采用BN操作。该分支的操作可以如下:
Component II: Expanding-and-Squeezing Convolution WDSR(https://bmvc2019.org/wp-content/uploads/papers/0288-paper.pdf)中实验表明:更宽的特征可以显著提升表达能力、提升超分性能 。因此,我们采用卷积进行通道升维。具体来说,我们通过卷积将输入通道从C提升到D,然后再通过卷积将通道从D降低到C,确保不同分支的输出通道相同。该分支的操作定义如下(注:我们设置):
Component III: Sequential Convolution with Scaled Sobel Filters SPSR(https://arxiv.org/abs/2003.13081)研究表明:边缘信息对于超分任务非常有用 。不同于SPSR的显式利用梯度信息,我们采用隐式方式将Sobel梯度集成到ECB模块的第三与第四分支。这两个分支操作定义如下(注:分表水平与垂直Sobel滤波器):
Component IV: Sequential Convolution with Scaled Laplacian Filters 除了一阶梯度外,我们还采用Laplacian滤波器提取二阶梯度(更稳定,对噪声更鲁棒)。该分支操作定义如下:
ECB模块的输出则是上述五个成分的组合,组合后特征将送入到非线性激活层。在实验中,我们采用了PReLU。
Re-parameterization for Efficient Inference
接下来,我们将介绍如何将ECB折叠为单个卷积以便于高效推理。如DBB所说,卷积与卷积可以合并为单个常规卷积:
Component III与Component IV采用串行卷积与DWConv,而DWConv可以视作常规卷积的一种特例,DWConv可以通过补零扩展为常规卷积。扩展方式描述如下:
最终折叠后的参数定义如下:
因此,我们可以在推理阶段采用单个常规卷积替换上述ECB模块:
Experiments
Main Results
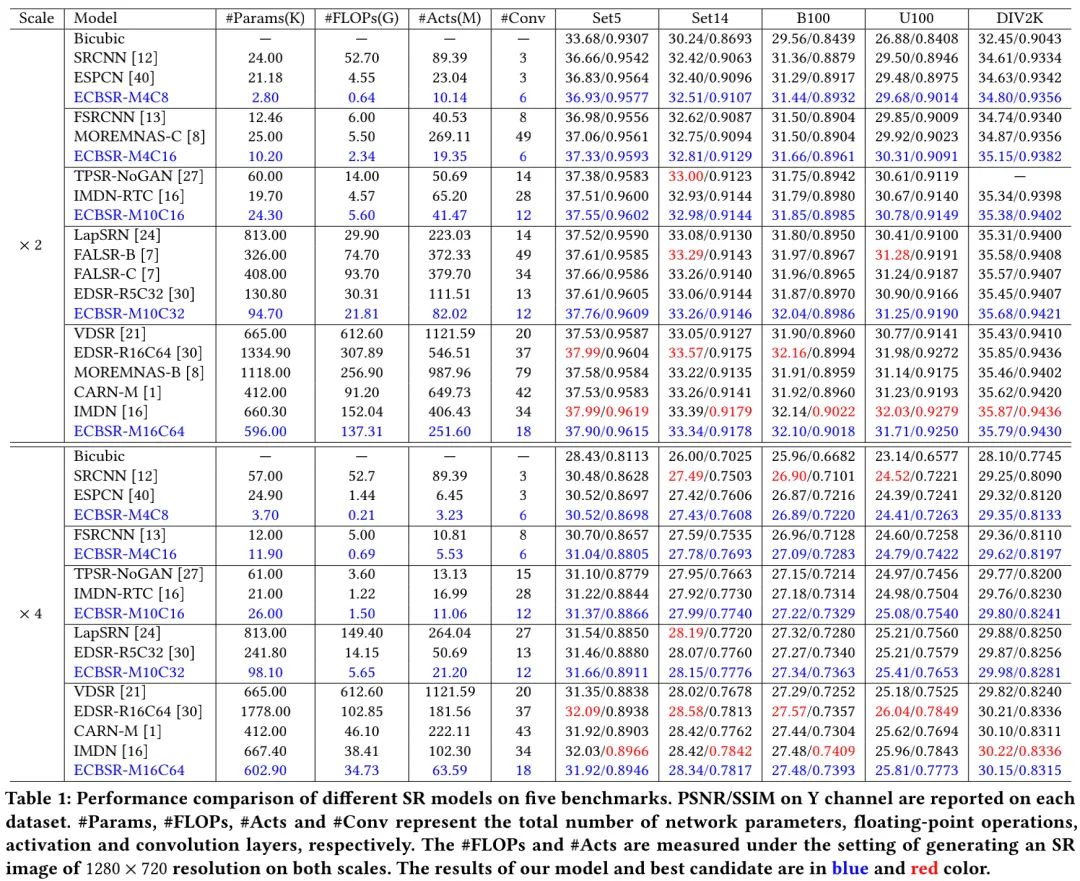
上表给出了不同尺度、不同模型的参数量、FLOPs、Acts、#Conv以及PSNR、SSIM等方面的对比,从中可以看到:
在最小模型量级方面,ECBSR-M4C8大幅优于SRCNN、ESPCN,同时具有更少的参数量(12x/10x)、更低的FLOPs(92x/9x)、更少的Activations(9x/2x)。
类似地,ECBSR-M4C16、ECBSR-M10C16以及ECBSR-M10C32等模型在不同量级方面均取得了显著的性能、计算复杂度优势。
值得一提的是,相比通过NAS搜到的MoreMNAS-C、FALSR-B以及FALSR-C,所提方案具有相当甚至更优的性能,同时更小模型、更低计算量、更少显存占用。
ECBSR-M16C64可以取得与EDSR-R16C64、CARN-M、IMDN相当的性能,同时更小、更轻量。

上图对比了不同方案的视觉效果对比(注:这里仅对比了可以满足实时推理的模型),从中可以看到:所提方案具有更锐利的边缘、更清晰的纹理 。
Hardware Running Speed
由于模型大小、参数量、FLOPs以及Activations无法精确的反映模型的真实推理速度,我们进一步在两台移动设备评估了其实际推理速度。在这里,我们选择了两个极具代表性的旗舰机型SOC:天玑1000+GPU 与骁龙865DSP 。由于SDK对于推理速度影响非常大,我们在相同SDK相同配置下运行所有模型,采用AI benchmark AP运行模型。注:所有模型均进行量化并采用INT8算法推理 。
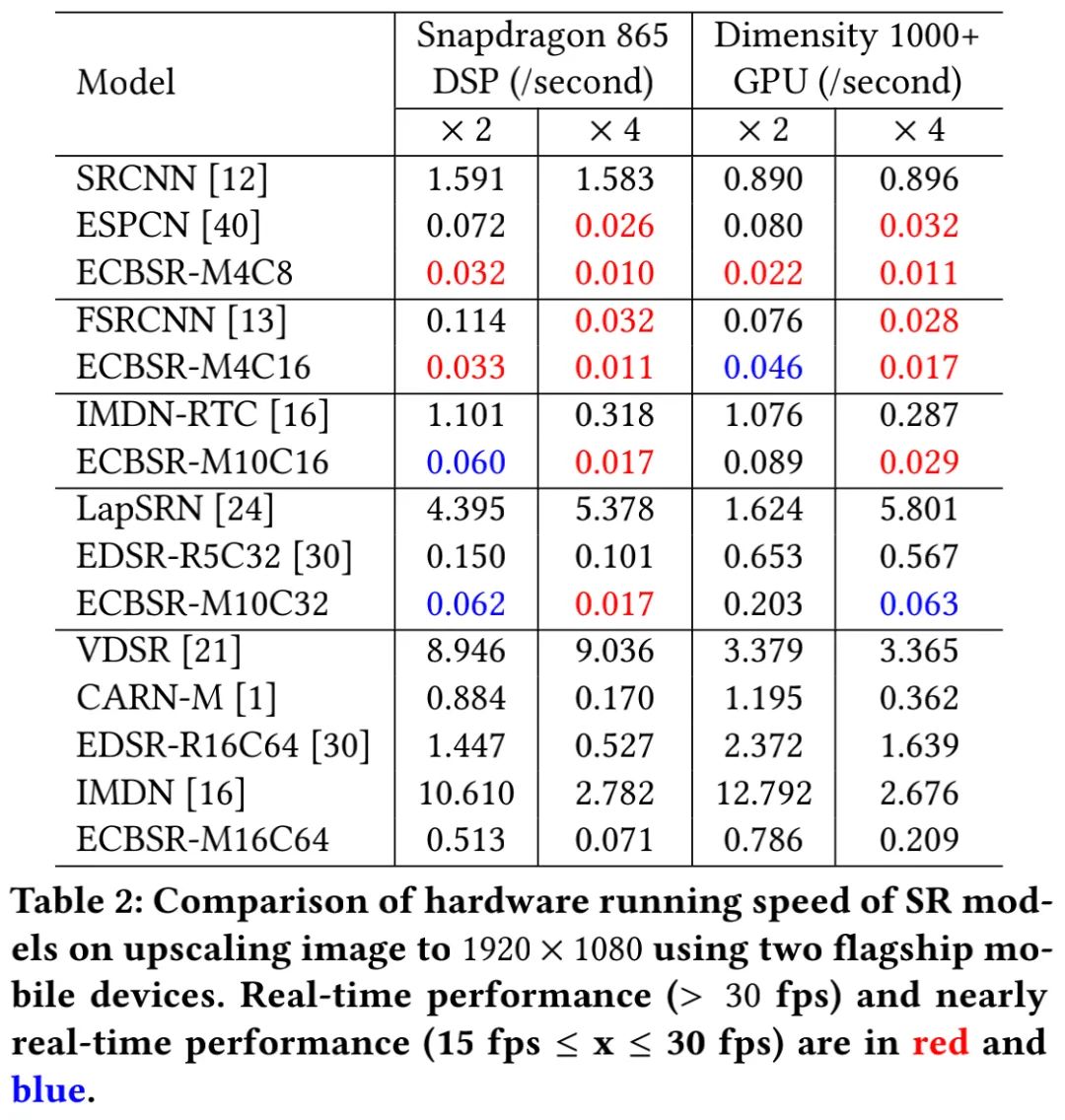
上表的推理速度均为上采样到1080p分辨率,从上表可以看到:
大部分对标超分方案远远无法达到实时推理;
ECBSR-M4C8、ECBSR-M4C16非常高效,在两个设备上均达到实时;而ECBSR-M16C64过于复杂,无法在移动设备达到实时;
尽管EDSR-R5C32与IMDN-RTC非常轻量,但仍无法达到实时推理,主要原因:稠密连接与多分支结构带来了过多MACs、降低了计算并行度。
Ablation Study
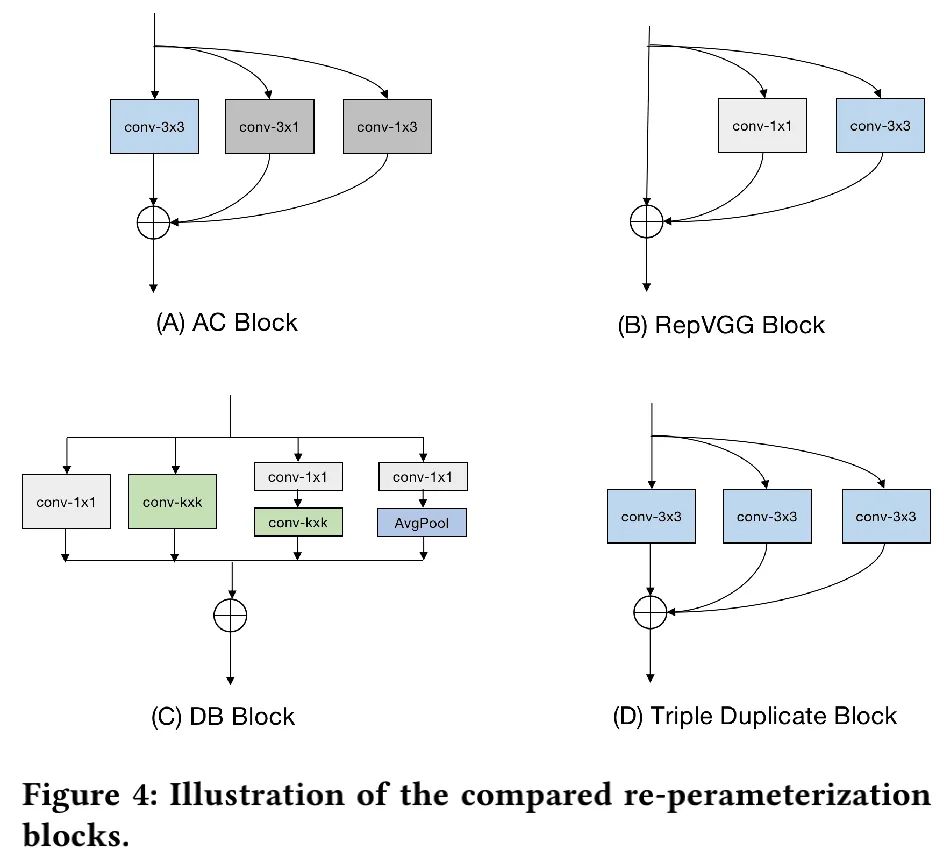
为更好说明ECB的作用,我们将其与其他重参数模块(包含AC模块、RepVGG模块模块以及DB模块)进行了对比,此外Triple Duplicate模块作为参考基线,这里所对比的几个模块可参见上图。
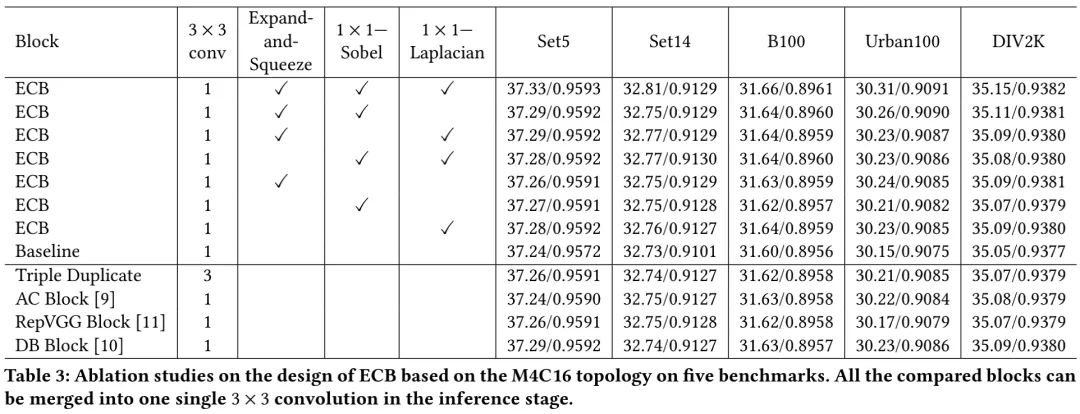
上表给出了消融实验对比(注:表中结果是在x2超分任务上统计所得),从中可以看到:
三个成分的任何一个都可以提升基线模型性能,移除任何一个均会导致ECBSR模型性能下降;
相比基线模型,AC与RepVGG带来的性能非常有限,而DB模块带来的性能提升稍好;
总而言之:ECB在所有数据及上均可以带来~0.1dB指标提升。
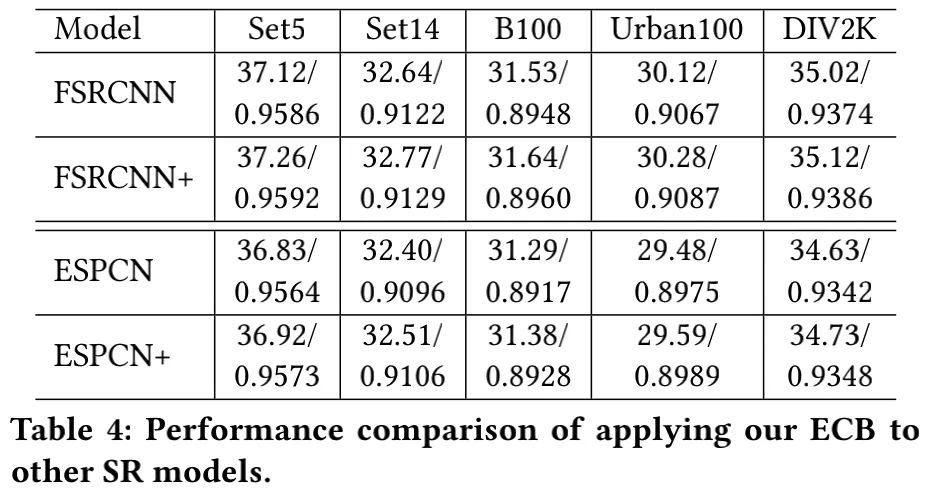
我们还在SRCNN、ESPCNN结果上验证所提ECB模块的有效性,见上表。从中可以看到:增强版模型可以取得 指标提升 。这说明:ECB是一种广义的、“无痛”提升超分性能的即插即用型 模块。
吐槽时刻
全文一共也没几个图啊,结果核心的结构图竟然存在问题。这是在赶稿子吗 ?
We, for the first time, investigate the structure re-parameterizable technique for SR task and propose an Edge-oriented Convolution Block (ECB)。
此外,论文中提出:ECBSR是首个将结构重参数化用于超分任务的方案。看到这里,估计ARM的研究员第一个不服,因为在今年的3月份他们就将他们的SESR工作上传到arxiv,可参考笔者的之前的解读:
46FPS+1080Px2超分+手机NPU,arm提出一种基于重参数化思想的超高效图像超分方案
也许,哈工大的左老师团队也会反对(机智如我),同样是在今年3月份将其采用非对称卷积(同样是一种重参数结构)用于超分的文章上传到arxiv,可参考笔者之前的解读:
ACNet|增强局部显著特征,哈工大左旺孟老师团队提出非对称卷积用于图像超分
此外,非对称卷积ACNet(https://github.com/DingXiaoH/ACNet)可以有效提升low-level的性能已得到了多次验证,比如NTIRE2020的几个竞赛中就有几个方案把当做涨点技巧。当然,以上仅为吐槽,别无恶意。
ECBSR这篇文章最大的亮点是:将low-level的领域特征与结构重参数思想进行了结合。在low-level领域,图像的梯度是非常重要的一个考虑,如何有效提升生成图像的边缘锐利度一直是业界的关注点。ECBSR就巧妙的就一阶梯度与二阶段梯度进行了结合,在超分任务上达到了比DBB、RepVGG、ACNet等重参数模块更优秀的性能。
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“CVPR21检测”获取CVPR2021目标检测论文下载~

# 极市平台签约作者#

happy
知乎:AIWalker
AIWalker运营、CV领域八年深耕码农
研究领域:专注low-level领域,同时对CNN、Transformer、MLP等前沿网络架构保持学习心态,对detection的落地应用甚感兴趣。
公众号:AIWalker
作品精选
