
Python 批量下载BiliBili视频 打包成软件
一、项目概述
1.项目背景
有一天,我突然想找点事做,想起一直想学但是没有学的C语言,就决定来学一下。可是怎么学呢?看书的话太无聊,报班学呢又快吃土了没钱,不如去B站看看?果然,关键字C语言搜索,出现了很多C语言的讲课视频: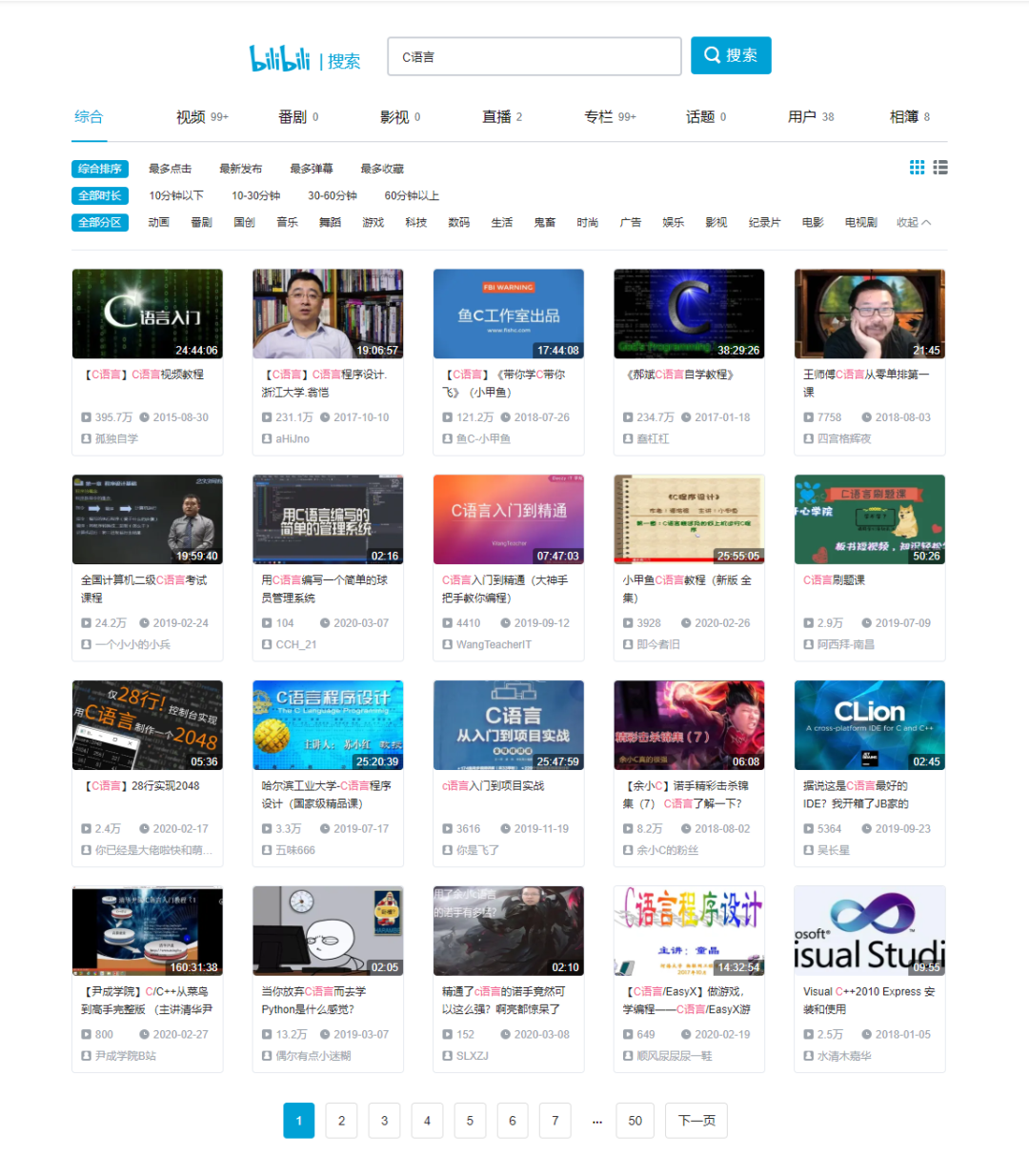 B站https://www.bilibili.com/是一个很神奇的地方,简直就是一个无所不有的宝库,几乎可以满足你一切的需求和视觉欲。不管你是想看动画、番剧 ,还是游戏、鬼畜 ,亦或科技和各类教学视频 ,只要你能想到的,基本上都可以在B站找到。对于程序猿或即将成为程序猿的人来说,B站上的编程学习资源是学不完的,可是B站没有提供下载的功能,如果想保存下载在需要的时候看,那就是一个麻烦了。我也遇到了这个问题,于是研究怎么可以实现一键下载视频,最终用Python这门神奇的语言实现了。
B站https://www.bilibili.com/是一个很神奇的地方,简直就是一个无所不有的宝库,几乎可以满足你一切的需求和视觉欲。不管你是想看动画、番剧 ,还是游戏、鬼畜 ,亦或科技和各类教学视频 ,只要你能想到的,基本上都可以在B站找到。对于程序猿或即将成为程序猿的人来说,B站上的编程学习资源是学不完的,可是B站没有提供下载的功能,如果想保存下载在需要的时候看,那就是一个麻烦了。我也遇到了这个问题,于是研究怎么可以实现一键下载视频,最终用Python这门神奇的语言实现了。
2.环境配置
这次项目不需要太多的环境配置,最主要的是有ffmpeg(一套可以用来记录、转换数字音频、视频,并能将其转化为流的开源计算机程序)并设置环境变量就可以了。ffmpeg主要是用于将下载下来的视频和音频进行合并形成完整的视频。
下载ffmpeg
可点击https://download.csdn.net/download/CUFEECR/12234789或进入官网http://ffmpeg.org/download.html进行下载,并解压到你想保存的目录。
设置环境变量
复制ffmpeg的bin路径,如 xxx\ffmpeg-20190921-ba24b24-win64-shared\bin此电脑右键点击属性,进入控制面板\系统和安全\系统 点击高级系统设置→进入系统属性弹窗→点击环境变量→进入环境变量弹窗→选择系统变量下的Path→点击编辑点击→进入编辑环境变量弹窗 点击新建→粘贴之前复制的bin路径 点击确定,逐步保存退出
动态操作示例如下: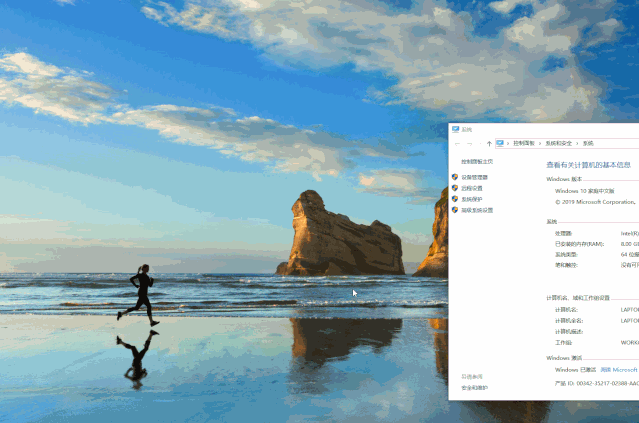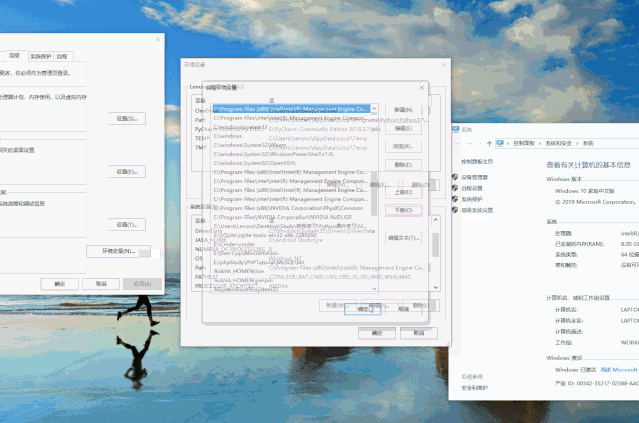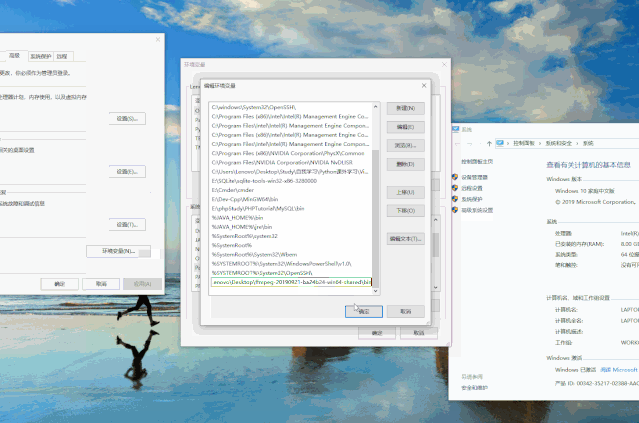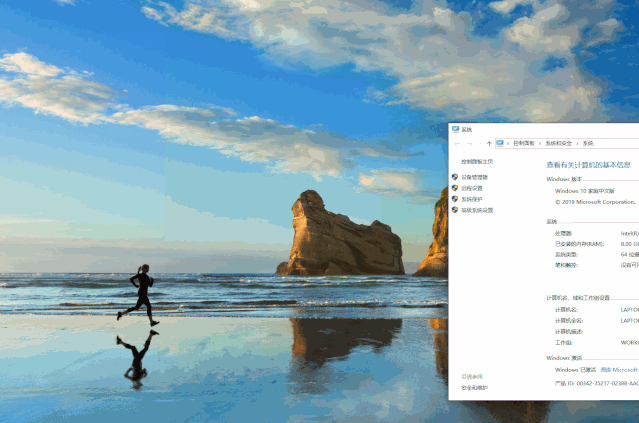
除了ffmpeg,还需要安装pyinstaller库用于程序打包。可用以下命令进行安装:
pip install pyinstaller
如果遇到安装失败或下载速度较慢,可换源:
pip install pyinstaller -i https://pypi.doubanio.com/simple/
二、项目实施
1.导入需要的库
import json
import os
import re
import shutil
import ssl
import time
import requests
from concurrent.futures import ThreadPoolExecutor
from lxml import etree
导入的库包括用于爬取和解析网页的库,还包括创建线程池的库和进行其他处理的库,大多数都是Python自带的,如有未安装的库,可使用pip install xxx命令进行安装。
2.设置请求参数
## 设置请求头等参数,防止被反爬
headers = {
'Accept': '*/*',
'Accept-Language': 'en-US,en;q=0.5',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Safari/537.36'
}
params = {
'from': 'search',
'seid': '9698329271136034665'
}
设置请求头等参数,减少被反爬的可能。
3.基本处理
def re_video_info(text, pattern):
'''利用正则表达式匹配出视频信息并转化成json'''
match = re.search(pattern, text)
return json.loads(match.group(1))
def create_folder(aid):
'''创建文件夹'''
if not os.path.exists(aid):
os.mkdir(aid)
def remove_move_file(aid):
'''删除和移动文件'''
file_list = os.listdir('./')
for file in file_list:
## 移除临时文件
if file.endswith('_video.mp4'):
os.remove(file)
pass
elif file.endswith('_audio.mp4'):
os.remove(file)
pass
## 保存最终的视频文件
elif file.endswith('.mp4'):
if os.path.exists(aid + '/' + file):
os.remove(aid + '/' + file)
shutil.move(file, aid)
主要包括两方面的基本处理,为正式爬取下载做准备:
利用正则表达式提取信息
通过requests库请求得到请求后的网页,属于文本,通过正则表达式提取得到关于将要下载的视频的有用信息,便于后一步处理。文件处理
将下载视频完成后的相关文件进行处理,包括删除生成的临时的音视频分离的文件和移动最终视频文件到指定文件夹。
4.下载视频
def download_video_batch(referer_url, video_url, audio_url, video_name, index):
'''批量下载系列视频'''
## 更新请求头
headers.update({"Referer": referer_url})
## 获取文件名
short_name = video_name.split('/')[2]
print("%d.\t视频下载开始:%s" % (index, short_name))
## 下载并保存视频
video_content = requests.get(video_url, headers=headers)
print('%d.\t%s\t视频大小:' % (index, short_name),
round(int(video_content.headers.get('content-length', 0)) / 1024 / 1024, 2), '\tMB')
received_video = 0
with open('%s_video.mp4' % video_name, 'ab') as output:
headers['Range'] = 'bytes=' + str(received_video) + '-'
response = requests.get(video_url, headers=headers)
output.write(response.content)
## 下载并保存音频
audio_content = requests.get(audio_url, headers=headers)
print('%d.\t%s\t音频大小:' % (index, short_name),
round(int(audio_content.headers.get('content-length', 0)) / 1024 / 1024, 2), '\tMB')
received_audio = 0
with open('%s_audio.mp4' % video_name, 'ab') as output:
headers['Range'] = 'bytes=' + str(received_audio) + '-'
response = requests.get(audio_url, headers=headers)
output.write(response.content)
received_audio += len(response.content)
return video_name, index
def download_video_single(referer_url, video_url, audio_url, video_name):
'''单个视频下载'''
## 更新请求头
headers.update({"Referer": referer_url})
print("视频下载开始:%s" % video_name)
## 下载并保存视频
video_content = requests.get(video_url, headers=headers)
print('%s\t视频大小:' % video_name, round(int(video_content.headers.get('content-length', 0)) / 1024 / 1024, 2), '\tMB')
received_video = 0
with open('%s_video.mp4' % video_name, 'ab') as output:
headers['Range'] = 'bytes=' + str(received_video) + '-'
response = requests.get(video_url, headers=headers)
output.write(response.content)
## 下载并保存音频
audio_content = requests.get(audio_url, headers=headers)
print('%s\t音频大小:' % video_name, round(int(audio_content.headers.get('content-length', 0)) / 1024 / 1024, 2), '\tMB')
received_audio = 0
with open('%s_audio.mp4' % video_name, 'ab') as output:
headers['Range'] = 'bytes=' + str(received_audio) + '-'
response = requests.get(audio_url, headers=headers)
output.write(response.content)
received_audio += len(response.content)
print("视频下载结束:%s" % video_name)
video_audio_merge_single(video_name)
这部分包括系列视频的批量下载和单个视频的下载,两者的大体实现原理近似,但是由于两个函数的参数有差别,因此分别实现。在具体的实现中,首先更新请求头,请求视频链接并保存视频(无声音),再请求音频链接并保存音频,在这个过程中得到相应的视频和音频文件的大小。
5.视频和音频合并成完整的视频
def video_audio_merge_batch(result):
'''使用ffmpeg批量视频音频合并'''
video_name = result.result()[0]
index = result.result()[1]
import subprocess
video_final = video_name.replace('video', 'video_final')
command = 'ffmpeg -i "%s_video.mp4" -i "%s_audio.mp4" -c copy "%s.mp4" -y -loglevel quiet' % (
video_name, video_name, video_final)
subprocess.Popen(command, shell=True)
print("%d.\t视频下载结束:%s" % (index, video_name.split('/')[2]))
def video_audio_merge_single(video_name):
'''使用ffmpeg单个视频音频合并'''
print("视频合成开始:%s" % video_name)
import subprocess
command = 'ffmpeg -i "%s_video.mp4" -i "%s_audio.mp4" -c copy "%s.mp4" -y -loglevel quiet' % (
video_name, video_name, video_name)
subprocess.Popen(command, shell=True)
print("视频合成结束:%s" % video_name)
这个过程也是批量和单个分开,大致原理差不多,都是调用subprogress模块生成子进程,Popen类来执行shell命令,由于已经将ffmpeg加入环境变量,所以shell命令可以直接调用ffmpeg来合并音视频。
6.3种下载方式的分别实现
def batch_download():
'''使用多线程批量下载视频'''
## 提示输入需要下载的系列视频对应的id
aid = input('请输入要下载的视频id(举例:链接https://www.bilibili.com/video/av91748877?p=1中id为91748877),默认为91748877\t')
if aid:
pass
else:
aid = '91748877'
## 提示选择清晰度
quality = input('请选择清晰度(1代表高清,2代表清晰,3代表流畅),默认高清\t')
if quality == '2':
pass
elif quality == '3':
pass
else:
quality = '1'
acc_quality = int(quality) - 1
## ssl模块,处理https请求失败问题,生成证书上下文
ssl._create_default_https_context = ssl._create_unverified_context
## 获取视频主题
url = 'https://www.bilibili.com/video/av{}?p=1'.format(aid)
html = etree.HTML(requests.get(url, params=params, headers=headers).text)
title = html.xpath('//*[@id="viewbox_report"]/h1/span/text()')[0]
print('您即将下载的视频系列是:', title)
## 创建临时文件夹
create_folder('video')
create_folder('video_final')
## 定义一个线程池,大小为3
pool = ThreadPoolExecutor(3)
## 通过api获取视频信息
res_json = requests.get('https://api.bilibili.com/x/player/pagelist?aid={}'.format(aid)).json()
video_name_list = res_json['data']
print('共下载视频{}个'.format(len(video_name_list)))
for i, video_content in enumerate(video_name_list):
video_name = ('./video/' + video_content['part']).replace(" ", "-")
origin_video_url = 'https://www.bilibili.com/video/av{}'.format(aid) + '?p=%d' % (i + 1)
## 请求视频,获取信息
res = requests.get(origin_video_url, headers=headers)
## 解析出视频详情的json
video_info_temp = re_video_info(res.text, '__playinfo__=(.*?)