
超越ReLU却鲜为人知,3年后被挖掘:BERT、GPT-2等都在用的激活函数
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作为决定神经网络是否传递信息的「开关」,激活函数对于神经网络而言至关重要。不过今天被人们普遍采用的 ReLU 真的是最高效的方法吗?最近在社交网络上,人们找到了一个看来更强大的激活函数:GELU,这种方法早在 2016 年即被人提出,然而其论文迄今为止在 Google Scholar 上的被引用次数却只有 34 次。
其实,GELU 已经被很多目前最为领先的模型所采用。据不完全统计,BERT、RoBERTa、ALBERT 等目前业内顶尖的 NLP 模型都使用了这种激活函数。另外,在 OpenAI 声名远播的无监督预训练模型 GPT-2 中,研究人员在所有编码器模块中都使用了 GELU 激活函数。
GELU 论文的作者来自 UC Berkeley 和丰田工业大学芝加哥分校:

论文链接:https://arxiv.org/pdf/1606.08415.pdf
在讲述 GELU 之前,让我们先回顾一下目前最为流行的线性整流函数(Rectified Linear Unit, ReLU),它又称修正线性单元。RELU 是多伦多大学 Vinod Nair 与图灵奖获得者 Geoffrey Hinton 等人的研究,其研究被 ICML 2010 大会接收。
RELU 是人工神经网络中最常用的激活函数(activation function),通常指代以「斜坡」函数及其变种为代表的非线性函数族。这个函数族比较常见的有 ReLU 以及 Leaky ReLU。
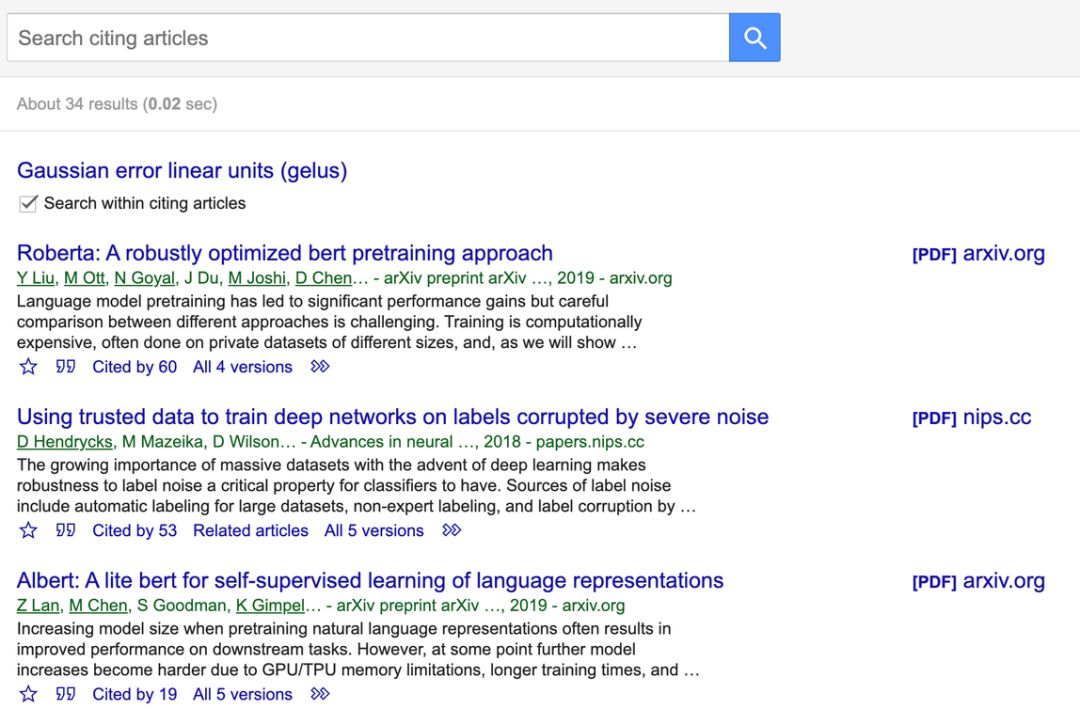
通常意义下,线性整流函数指代数学中的斜坡函数,即:
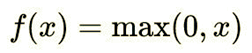
函数图像如下:
而在神经网络中,线性整流作为神经元的激活函数,定义了该神经元在线性变换之后的非线性输出结果。ReLU 可以对抗梯度爆炸/消失问题,相对而言计算效率也很高。因为在 2012 年被著名的计算机视觉模型 AlexNet 应用,ReLU 变得流行开来,目前它被普遍认为是效果最好的激活函数。
激活函数发展史
早期人工神经元使用二元阈值单元(Hopfield, 1982; McCulloch & Pitts, 1943)。这些困难的二元决策通过 Sigmoid 激活函数进行平滑化,从而具有非常快的解码速度,并可以利用反向传播进行训练。但是,随着网络深度的不断增加,利用 Sigmoid 激活函数来训练被证实不如非平滑、低概率性的 ReLU 有效(Nair & Hinton, 2010),因为 ReLU 基于输入信号做出门控决策。
尽管 ReLU 缺少统计学意义上的支持,但依然是一种非常有竞争力的工程解决方案,其收敛速度和效果好于 Sigmoid 激活函数。得益于 ReLU 的成功,近来有一个它的改进版——ELU 函数。这种函数可以让类似 ReLU 的非线性函数能够输出负值并提升训练速度。总之,对于激活函数的选择也是神经网络架构设计中重要的一部分。
深度非线性分类器可以和数据拟合地很好,使得设计者需要面对随机正则化(如在隐层中加入噪声)或者采用 dropout 机制。这两个选择依然是和激活函数割裂的。一些随机正则化可以让网络表现得像是很多个网络的组合,并可以提升精确度。
因此,非线性和 dropout 共同决定了神经元的输出,但这两种创新依然存在区别。此外,非线性和 dropout 彼此也不将对方包含在内,因为流行的随机正则化在执行时与输入无关,并且非线性也获得此类正则化的辅助。
在本文中,研究者提出了一种新的非线性激活函数,名为高斯误差线性单元(Gaussian Error Linear Unit,GELU)。GELU 与随机正则化有关,因为它是自适应 Dropout 的修正预期(Ba & Frey, 2013)。这表明神经元输出的概率性更高。研究者发现,在计算机视觉、自然语言处理和自动语音识别等任务上,使用 GELU 激活函数的模型性能与使用 ReLU 或 ELU 的模型相当或超越了它们。
研究者表明,受到 Dropout、ReLU 等机制的影响,它们都希望将「不重要」的激活信息规整为零。我们可以理解为,对于输入的值,我们根据它的情况乘上 1 或 0。更「数学」一点的描述是,对于每一个输入 x,其服从于标准正态分布 N(0, 1),它会乘上一个伯努利分布 Bernoulli(Φ(x)),其中Φ(x) = P(X ≤ x)。
随着 x 的降低,它被归零的概率会升高。对于 ReLU 来说,这个界限就是 0,输入少于零就会被归零。这一类激活函数,不仅保留了概率性,同时也保留了对输入的依赖性。
好了,现在我们可以看看 GELU 到底长什么样子了。我们经常希望神经网络具有确定性决策,这种想法催生了 GELU 激活函数的诞生。这种函数的非线性希望对输入 x 上的随机正则化项做一个转换,听着比较费劲,具体来说可以表示为:Φ(x) × Ix + (1 − Φ(x)) × 0x = xΦ(x)。
我们可以理解为,对于一部分Φ(x),它直接乘以输入 x,而对于另一部分 (1 − Φ(x)),它们需要归零。不太严格地说,上面这个表达式可以按当前输入 x 比其它输入大多少来缩放 x。
因为高斯概率分布函数通常根据损失函数计算,因此研究者定义高斯误差线性单元(GELU)为:
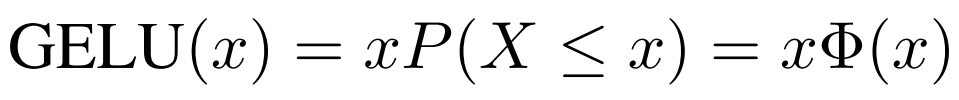
上面这个函数是无法直接计算的,因此可以通过另外的方法来逼近这样的激活函数,研究者得出来的表达式为:
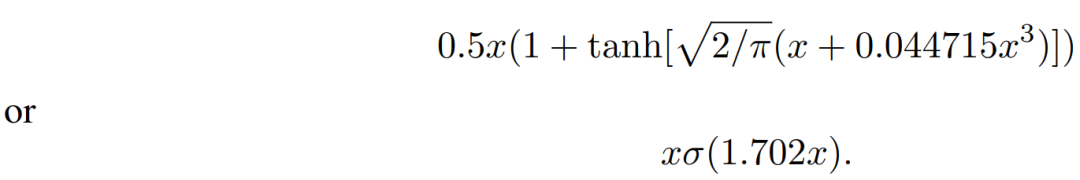
虽然研究者表示高斯概率分布函数的均值与方差都可以设置为可训练,但他们简单地采用均值为 0 方差为 1。看到这样的表达式,让人想到了谷歌 2017 年提出来的 Swish 激活函数,它的表达式可以简单写为:f(x) = x · sigmoid(x)。
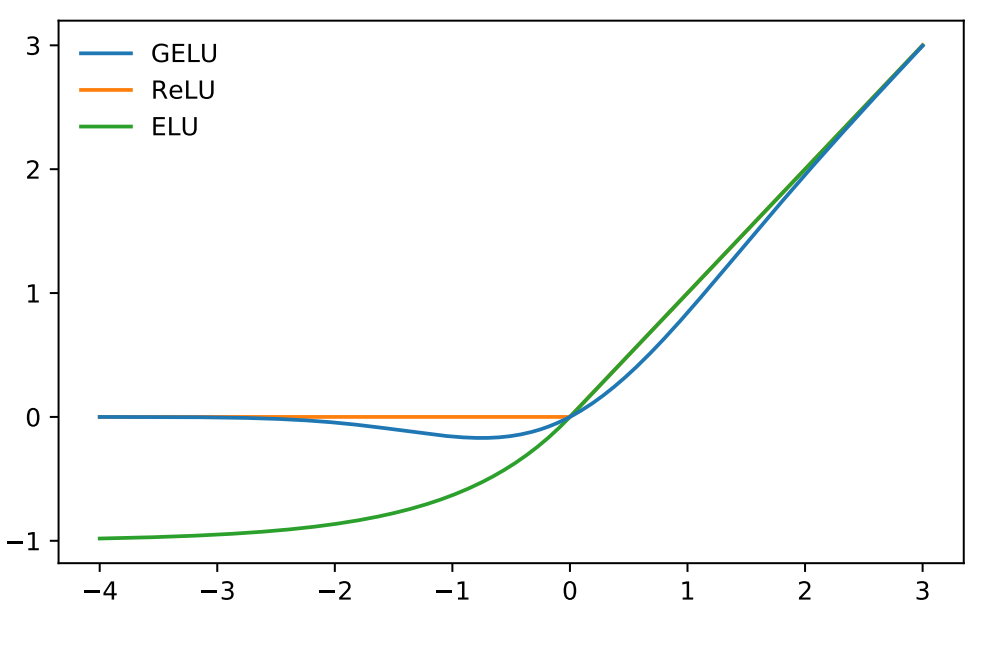 GELU 激活函数的图像。
GELU 激活函数的图像。
在 Quoc V. Le 等人研究的成果中,他们将 Swish 激活函数定义为 x · σ(βx),其中 σ() 是标准的 sigmoid 函数,β可以是常数,也可以是可训练的参数。这样的激活函数是「被搜索」出来的,研究者在一系列函数族中做自动搜索,并表示 Swish 激活函数的效果最好。
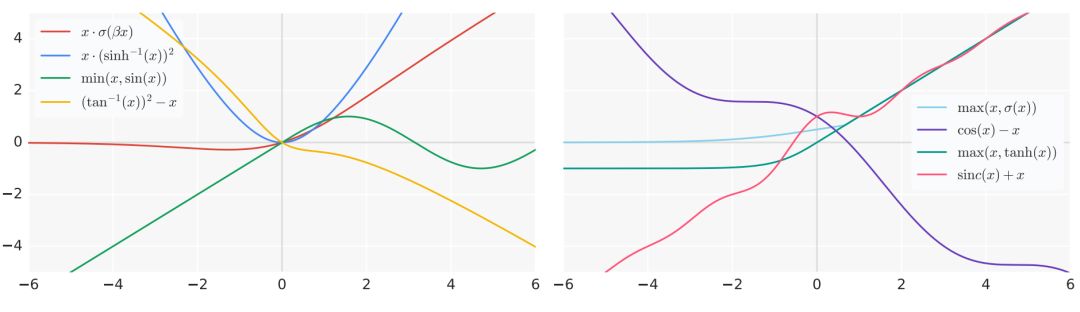
通过搜索查找到的激活函数,它们效果都还不错,选自 arXiv: 1710.05941。
研究者对 GELU 和 ReLU、ELU 三个激活函数进行了性能上的比较。他们选择了以下任务:
MNIST 图片分类(10 类,6 万张训练图片和 1 万张测试图片);
TIMIT 语音识别(3696 个训练样本、1152 个验证样本和 192 个测试样本);
CIFAR-10/100 分类(10/100 个类,5 万的训练样本和 1 万的测试样本)。
MNIST 图片分类任务
研究者在一个全连接网络中测试了 MNIST 分类任务,其中 GELU 的参数是μ = 0、σ = 1。ELU 则是α = 1。每个网络都有 8 个层、128 个神经元。
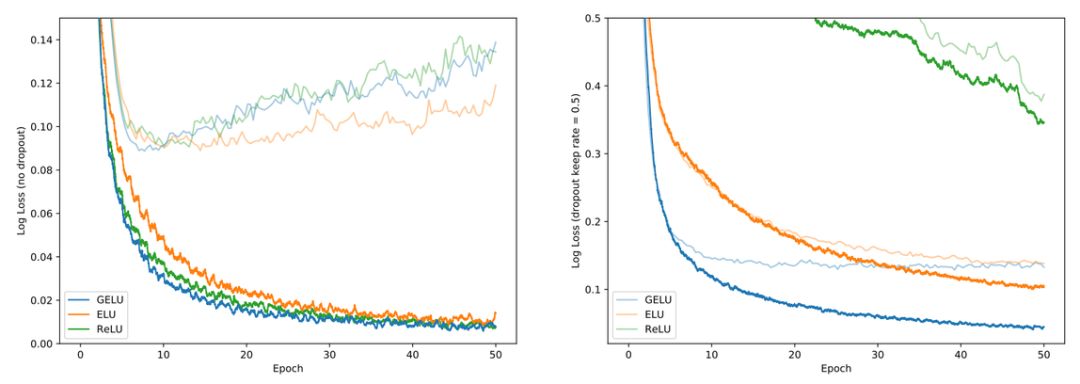
图 2 左:无 dropout 模型,图右:模型设置 dropout 为 0.5。
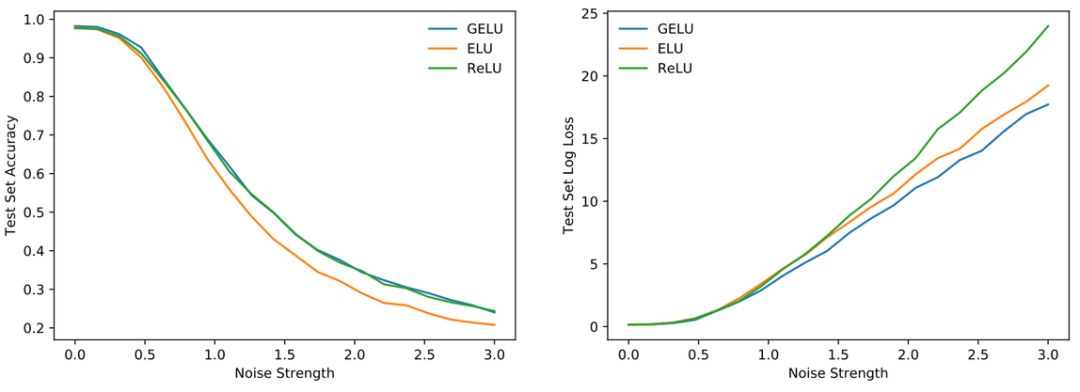
图 3:MNIST 鲁棒性结果。
TIMIT 语音识别任务
研究者需要解决的另一项挑战是利用 TIMIT 数据集进行音素识别(phone recognition),该数据集包含 680 名说话者在无声环境中的录音。该系统是一个包含 2048 个神经元的 5 层宽分类器(Mohamed et al., 2012),包含 39 个输出语音标签。
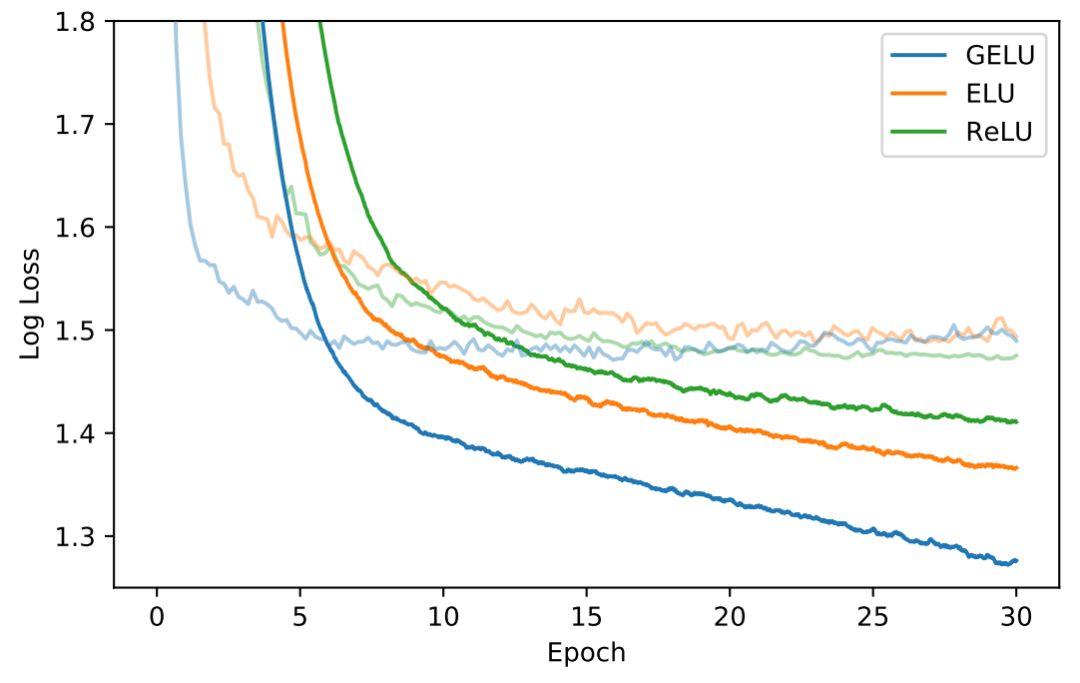
图 5:TIMIT 语音识别变化曲线图。
CIFAR-10/100 分类任务
研究者利用 5000 个验证样本来对初始学习率 {10^−3,10^−4,10^−5} 进行微调,然后基于交叉验证的学习率再次在整个训练集上进行训练。他们通过 Adam 对 200 个 epoch 优化,并在第 100 个 epoch 上学习率衰减为零。如下图 6 所示,每条曲线是三次运行结果取中间值得出的。
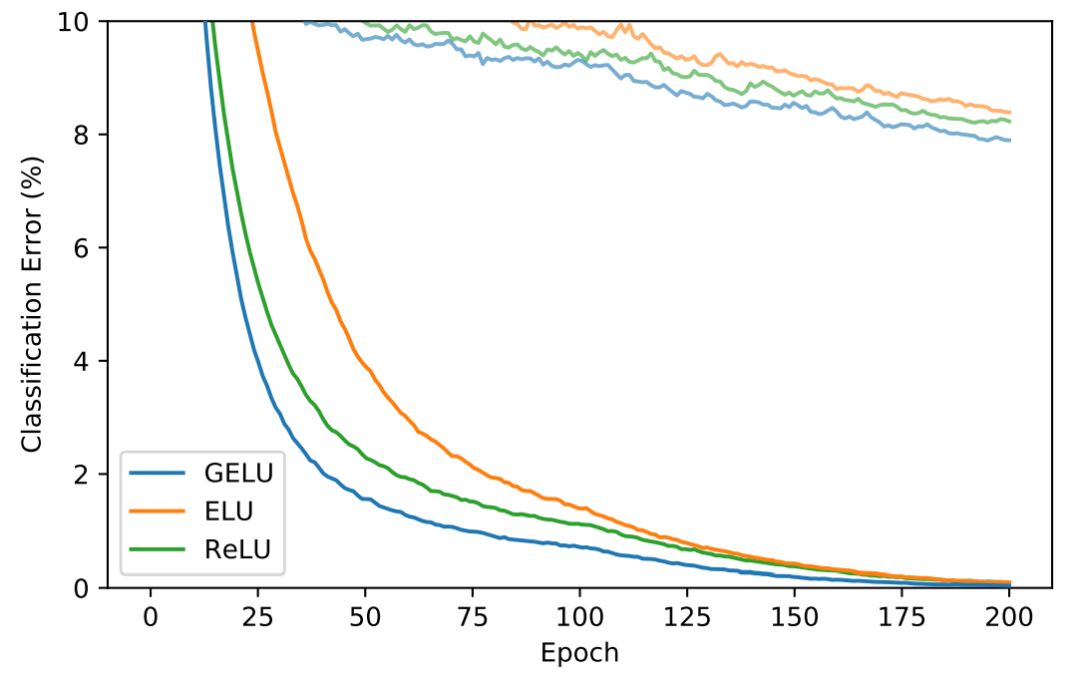
图 6:CIFAR-10 数据集上的结果。
因为表达式差不多,一个是固定系数 1.702,另一个是可变系数 β,Swish 和 GELU 的性质与效果非常类似。在 Swish 论文(SEARCHING FOR ACTIVATION FUNCTIONS)中,研究者对比了不同激活函数的效果,我们可以看到在视觉或语言任务中,Swish 效果要更好一些。
例如在 ImageNet 中训练 Inception-ResNet-v2,Swish 还是要稍微超过 GELU,其中每一个评估值都记录了三次运行的结果。
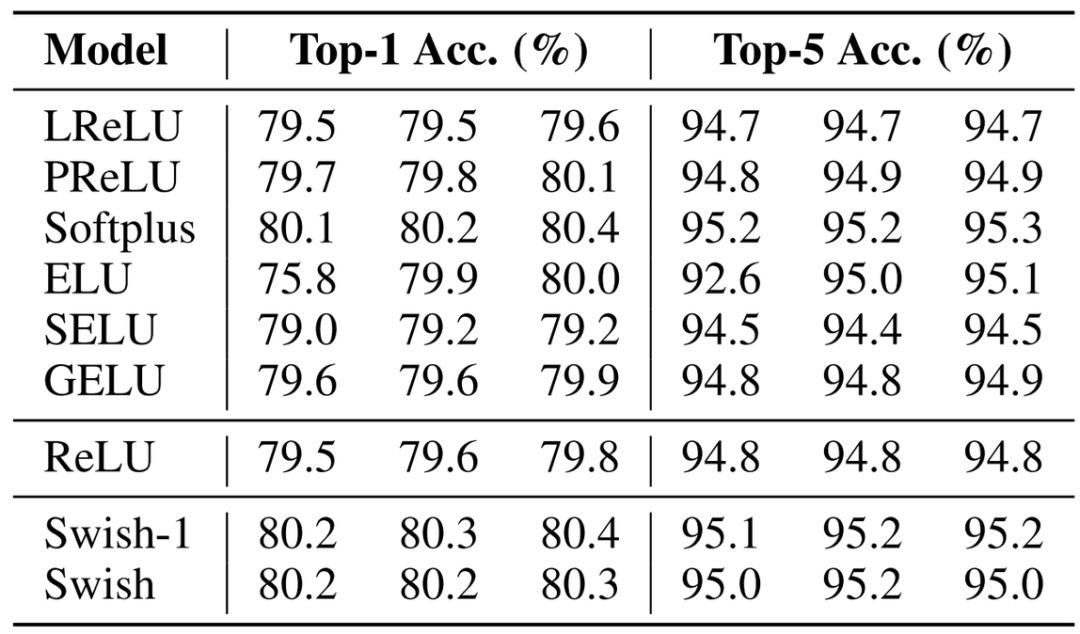
在机器翻译任务上,研究者在 WMT 2014 English→German 数据集上测试了 12 层 Transformer 的效果。在不同的测试集上,似乎 Swish 激活函数都是最好的,当然 GELU 的效果也不差,它们相差并不大。
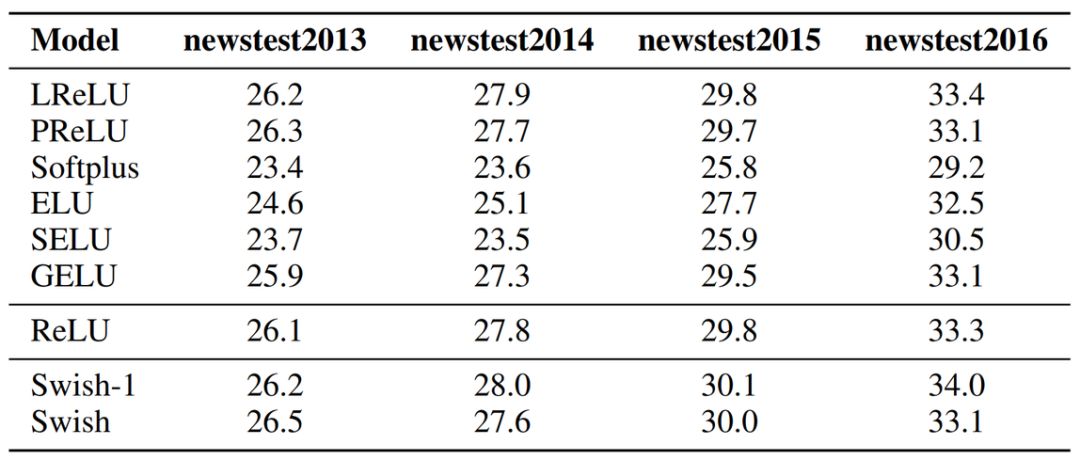
最后,我们在 GELU 的引用文献中发现了大量序列建模都采用它作为激活函数,不论是语言建模还是声学建模。也许之前序列建模常采用 tanh() 而不是 ReLU() 作为激活函数,在发现有更好的选择后,更多的研究者尝试接受这种非线性单元。
如前文所述,GELU 的近似实现方式有两种,借助 tanh() 和借助σ()。我们在 GPT-2 的官方代码中也发现,更多研究者采用了 tanh() 的实现方式尽管它看起来要比 xσ(1.702x) 复杂很多。
# GPT-2 的 GELU 实现def gelu(x):return 0.5*x*(1+tf.tanh(np.sqrt(2/np.pi)*(x+0.044715*tf.pow(x, 3))))
不管怎么样,作为神经网络最基础的模块,我们总希望在 ReLU 之上,在 GELU 和 Swish 之上能有更多的创新与观点。
好消息!
小白学视觉知识星球
开始面向外开放啦👇👇👇
下载1:OpenCV-Contrib扩展模块中文版教程 在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。 下载2:Python视觉实战项目52讲 在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。 下载3:OpenCV实战项目20讲 在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。 交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~