
视频压缩:谷歌基于GAN实现
机器之心编译 编辑:陈萍
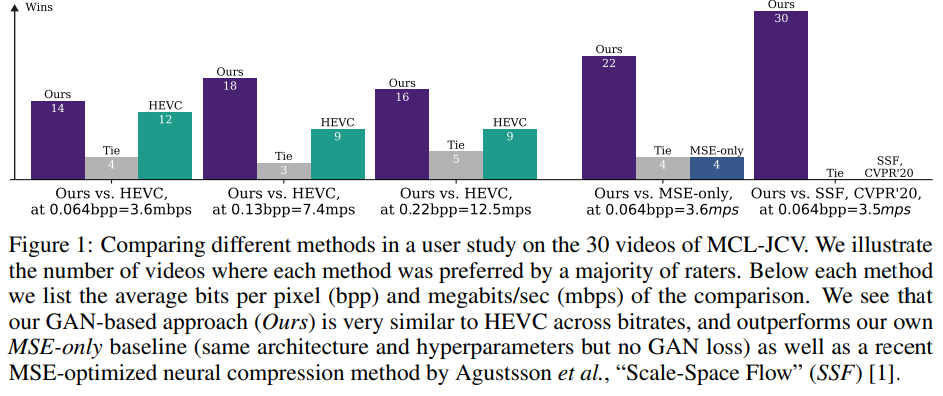
来自谷歌的研究者提出了一种基于生成对抗网络 (GAN) 的神经视频压缩方法,该方法优于以前的神经视频压缩方法,并且在用户研究中与 HEVC 性能相当。

该研究提出了首个在视觉质量方面与 HEVC 具有竞争性的神经压缩方法,这是在用户研究中衡量的。研究表明,在 PSNR 方面具有竞争力的方法在视觉质量方面的表现要差得多;
该研究提出了一种减少展开时时间误差累积的技术,该技术通过随机移动残差输入,然后保持输出不变,激励频谱分析,研究表明该技术在系统和 toy 线性 CNN 模型中具备有效性;
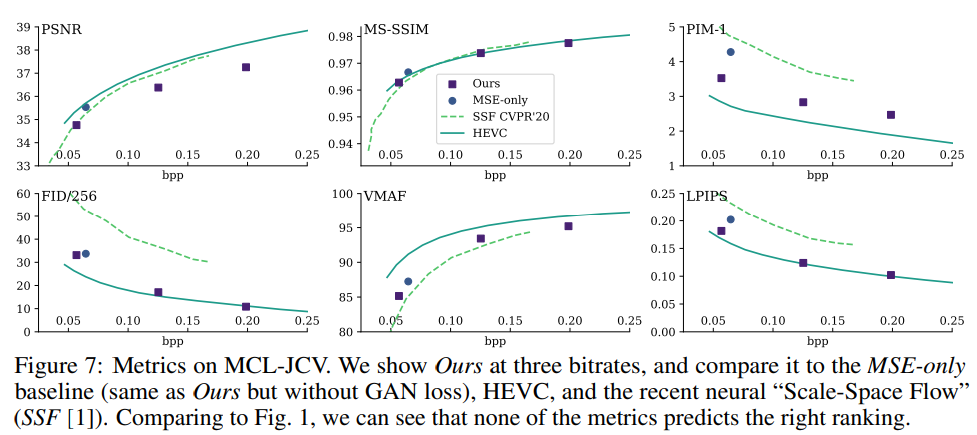
该研究探索了由用户研究测量的视觉质量与可用视频质量指标之间的相关性。为了促进未来的研究,研究者发布了对 MCL-JCV 视频数据集的重建以及从用户研究中获得的所有数据(附录 B 中的链接)。
 是重建视频。
是重建视频。
在 I-frame 中合成可信的细节;
尽可能清晰地传递这些可信细节;
对于出现在 P-frame 中的新内容,研究者希望能够合成可信细节。
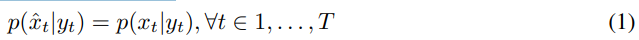
1) 仅在随机选择的帧上训练 E_I 、 G_I 、 D_I ,1 000000 step。
2) 冻结 E_I、G_I、D_I ,并从 E_I 、G_I 初始化 E_res、G_res 权重。使用分阶段展开( staged unrolling )训练 E_flow、G_flow、E_res、G_res、D_P 450000step,即使用 T = 2 直到 80k step,T = 3 直到 300step,T = 4 直到 350step,T = 6 直到 400k,T = 9 直到 450k。

猜您喜欢:
CVPR 2021 | GAN的说话人驱动、3D人脸论文汇总
附下载 |《TensorFlow 2.0 深度学习算法实战》
附下载 | 超100篇!CVPR 2020最全GAN论文梳理汇总!
评论