
工业蒸汽预测案例(天池大赛)
这是天池大赛其中一个项目数据,在拿这个项目练手几个模型,推导之后,留下了大部分内容。下面是具体案例。
竞赛资料相关:
基本介绍:根据经脱敏后的锅炉传感器采集的数据(采集频率是分钟级别),根据锅炉的工况,预测产生的蒸汽量。
竞赛地址:https://tianchi.aliyun.com/competition/entrance/231693/introduction?spm=5176.12281973.1005.9.56bb1f54ICNwSI
案例代码
导入模块
import warnings
warnings.filterwarnings("ignore")
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from sklearn.neighbors import KNeighborsRegressor
from sklearn.ensemble import RandomForestRegressor
import lightgbm as lgb
from sklearn.tree import DecisionTreeRegressor
from sklearn.svm import SVR
导入数据集
train_data_file = "./zhengqi_train.txt"
test_data_file = "./zhengqi_test.txt"
data_train = pd.read_csv(train_data_file,sep='\t',encoding='utf-8')
data_test = pd.read_csv(test_data_file,sep='\t',encoding='utf-8')
数据探索
data_train.info()
'pandas.core.frame.DataFrame'>
RangeIndex: 2888 entries, 0 to 2887
Data columns (total 39 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 V0 2888 non-null float64
1 V1 2888 non-null float64
2 V2 2888 non-null float64
3 V3 2888 non-null float64
4 V4 2888 non-null float64
5 V5 2888 non-null float64
6 V6 2888 non-null float64
7 V7 2888 non-null float64
8 V8 2888 non-null float64
9 V9 2888 non-null float64
10 V10 2888 non-null float64
11 V11 2888 non-null float64
12 V12 2888 non-null float64
13 V13 2888 non-null float64
14 V14 2888 non-null float64
15 V15 2888 non-null float64
16 V16 2888 non-null float64
17 V17 2888 non-null float64
18 V18 2888 non-null float64
19 V19 2888 non-null float64
20 V20 2888 non-null float64
21 V21 2888 non-null float64
22 V22 2888 non-null float64
23 V23 2888 non-null float64
24 V24 2888 non-null float64
25 V25 2888 non-null float64
26 V26 2888 non-null float64
27 V27 2888 non-null float64
28 V28 2888 non-null float64
29 V29 2888 non-null float64
30 V30 2888 non-null float64
31 V31 2888 non-null float64
32 V32 2888 non-null float64
33 V33 2888 non-null float64
34 V34 2888 non-null float64
35 V35 2888 non-null float64
36 V36 2888 non-null float64
37 V37 2888 non-null float64
38 target 2888 non-null float64
dtypes: float64(39)
memory usage: 880.1 KB
data_test.info()
'pandas.core.frame.DataFrame'>
RangeIndex: 1925 entries, 0 to 1924
Data columns (total 38 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 V0 1925 non-null float64
1 V1 1925 non-null float64
2 V2 1925 non-null float64
3 V3 1925 non-null float64
4 V4 1925 non-null float64
5 V5 1925 non-null float64
6 V6 1925 non-null float64
7 V7 1925 non-null float64
8 V8 1925 non-null float64
9 V9 1925 non-null float64
10 V10 1925 non-null float64
11 V11 1925 non-null float64
12 V12 1925 non-null float64
13 V13 1925 non-null float64
14 V14 1925 non-null float64
15 V15 1925 non-null float64
16 V16 1925 non-null float64
17 V17 1925 non-null float64
18 V18 1925 non-null float64
19 V19 1925 non-null float64
20 V20 1925 non-null float64
21 V21 1925 non-null float64
22 V22 1925 non-null float64
23 V23 1925 non-null float64
24 V24 1925 non-null float64
25 V25 1925 non-null float64
26 V26 1925 non-null float64
27 V27 1925 non-null float64
28 V28 1925 non-null float64
29 V29 1925 non-null float64
30 V30 1925 non-null float64
31 V31 1925 non-null float64
32 V32 1925 non-null float64
33 V33 1925 non-null float64
34 V34 1925 non-null float64
35 V35 1925 non-null float64
36 V36 1925 non-null float64
37 V37 1925 non-null float64
dtypes: float64(38)
memory usage: 571.6 KB
可以看出训练集有和测试集有38特征,且均无空值。
# 核密度估计(Kde)是在概率论中用来估计未知的密度函数,属于非参数检验方法之一。通过核密度估计图可以比较直观的看出
# 数据样本本身的分布特征。
dist_cols = 6
dist_rows = len(data_test.columns)
plt.figure(figsize=(4*dist_cols,4*dist_rows))
i=1
for col in data_test.columns:
ax=plt.subplot(dist_rows,dist_cols,i)
ax = sns.kdeplot(data_train[col], color="Red", shade=True)
ax = sns.kdeplot(data_test[col], color="Blue", shade=True)
ax.set_xlabel(col)
ax.set_ylabel("Frequency")
ax = ax.legend(["train","test"])
i+=1
plt.show()
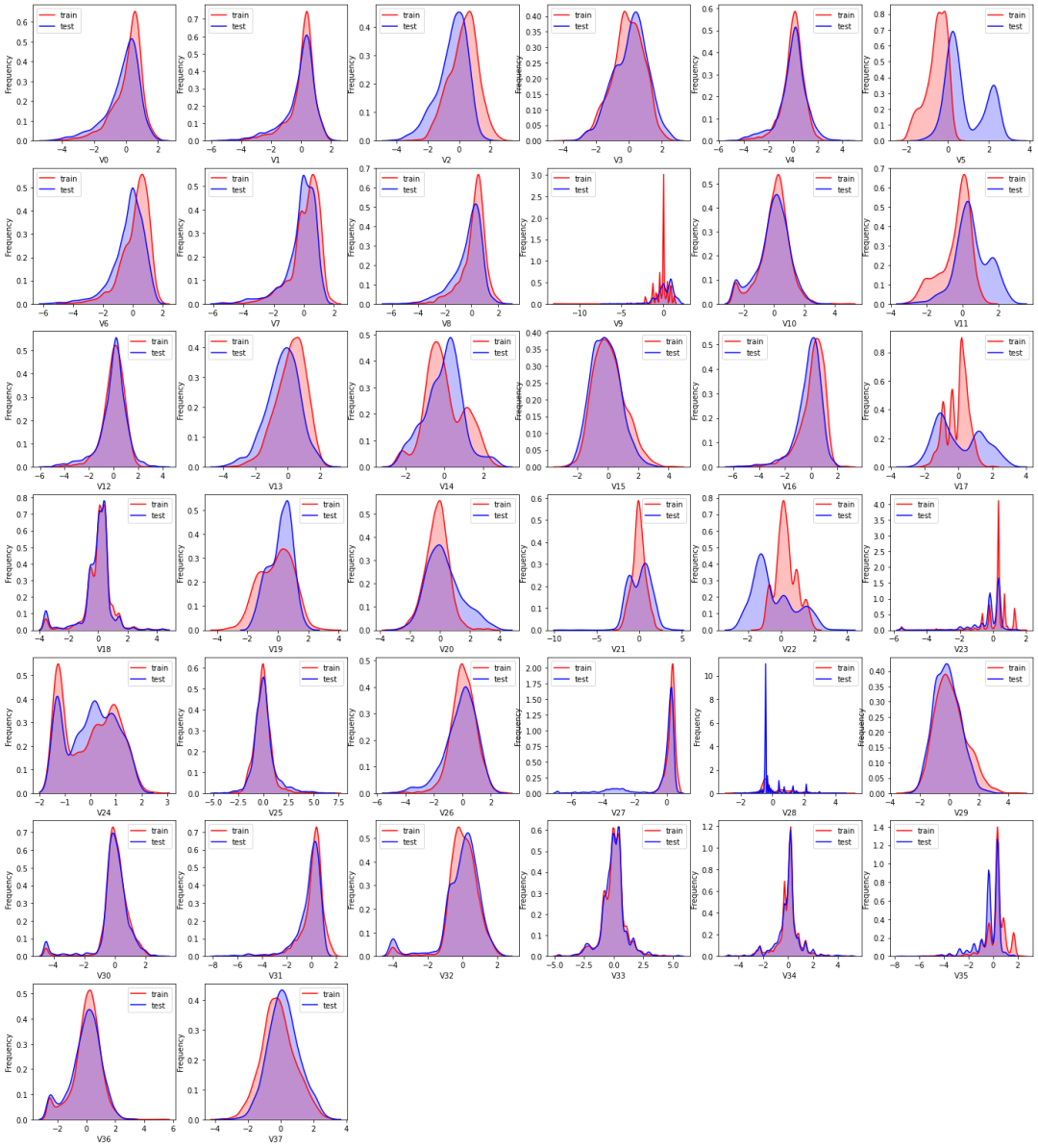 由上图的数据分布可以看到特征'V5','V9','V11','V17','V22','V23','V28' 训练集数据与测试集数据分布不一致,会导致模型泛化能力差,采用删除此类特征方法。
由上图的数据分布可以看到特征'V5','V9','V11','V17','V22','V23','V28' 训练集数据与测试集数据分布不一致,会导致模型泛化能力差,采用删除此类特征方法。
data_train.drop(["V5","V9","V11","V17","V22","V23","V28"],axis=1,inplace=True)
data_test.drop(["V5","V9","V11","V17","V22","V23","V28"],axis=1,inplace=True)
相关性分析
# 找出相关程度
plt.figure(figsize=(20, 16)) # 指定绘图对象宽度和高度
colnm = data_train.columns.tolist() # 列表头
mcorr = data_train[colnm].corr(method="spearman") # 相关系数矩阵,即给出了任意两个变量之间的相关系数
mask = np.zeros_like(mcorr, dtype=np.bool) # 构造与mcorr同维数矩阵 为bool型
mask[np.triu_indices_from(mask)] = True # 角分线右侧为True
cmap = sns.diverging_palette(220, 10, as_cmap=True) # 返回matplotlib colormap对象
g = sns.heatmap(mcorr, mask=mask, cmap=cmap, square=True, annot=True, fmt='0.2f') # 热力图(看两两相似度)
plt.show()

# 查找出特征变量和target变量相关系数大于0.3的特征变量
threshold = 0.3
corrmat = data_train.corr()
data_train_corr = corrmat.index[abs(corrmat["target"])>threshold]
plt.figure(figsize=(10,10))
g = sns.heatmap(data_train[data_train_corr].corr(),annot=True,cmap="RdYlGn")
data_train_corr
Index(['V0', 'V1', 'V2', 'V3', 'V4', 'V6', 'V8', 'V10', 'V12', 'V16', 'V20',
'V27', 'V31', 'V36', 'V37', 'target'],
dtype='object')

建模
from sklearn.model_selection import train_test_split
x = data_train.iloc[:,data_train.columns != 'target']
y = data_train.iloc[:,data_train.columns == 'target']
Xtrain, Xtest, Ytrain, Ytest = train_test_split(x,y,test_size=0.3)
# 恢复数据索引
for i in [Xtrain ,Xtest,Ytrain,Ytest]:
i.index = range(i.shape[0])
# 不同模型的名称列表
model_names = ['RandomForest', 'KNeighborsRegressor', "DecisionTree",'SVR',"lgb"]
model_RandomForest = RandomForestRegressor(n_estimators=200)
model_KNN = KNeighborsRegressor(n_neighbors=8)
model_tree = DecisionTreeRegressor(random_state=0)
model_svr = SVR(gamma='scale')
model_lgb = lgb.LGBMRegressor(
learning_rate=0.01,
max_depth=-1,
n_estimators=5000,
boosting_type='gbdt',
random_state=2019,
objective='regression',
)
# 不同回归模型对象的集合
model_list = [model_RandomForest,model_KNN,model_tree, model_svr,model_lgb]
# 各个回归模型预测的y值列表
pre_y_list = [model.fit(Xtrain ,Ytrain).predict(Xtest) for model in model_list]
from sklearn.metrics import explained_variance_score, mean_absolute_error, mean_squared_error, r2_score
# 总样本量,总特征数
n_samples, n_features = x.shape
# 回归评估指标对象集
model_metrics_functions = [explained_variance_score, mean_absolute_error, mean_squared_error,r2_score]
# 回归评估指标列表
model_metrics_list = [[m(Ytest, pre_y_list[i]) for m in model_metrics_functions] for i in range(len(model_list))]
# 建立回归指标的数据dataframe
regresstion_score = pd.DataFrame(model_metrics_list, index=model_names,
columns=['explained_variance', 'mae', 'mse', 'r2'])
# 打印输出样本量和特征数量
print('all samples: %d \t features: %d' % (n_samples, n_features),'\n','-'*60)
# 打印输出标题
print('\n','regression metrics:','\n','-'*60)
# 打印输出回归指标的数据框
print(regresstion_score)
all samples: 2888 features: 31
------------------------------------------------------------
regression metrics:
------------------------------------------------------------
explained_variance mae mse r2
RandomForest 0.882672 0.246085 0.117992 0.882585
KNeighborsRegressor 0.827096 0.315223 0.180750 0.820134
DecisionTree 0.753935 0.361561 0.247357 0.753851
SVR 0.862009 0.253634 0.138674 0.862003
lgb 0.896023 0.228566 0.104491 0.896020
数据集直接在天池竞赛地址获取就可以。
这份代码已经传到云盘。关注公众号,在对话框回复“1128”获取代码。
另外,天池竞赛最近出了一本书,讲了一些实际案例,感兴趣可以买实体书看看(目前这本书不打算出电子版)。
评论