
如果 KNN 淘汰了,那么取而代之的将是 ANN
点击上方“程序员大白”,选择“星标”公众号
重磅干货,第一时间送达

选自 | towardsdatascience
作者 | Marie Stephen Leo
转自 | 机器之心
编辑 | 小舟、杜伟


Spotify 的 ANNOY
Google 的 ScaNN
Facebook 的 Faiss
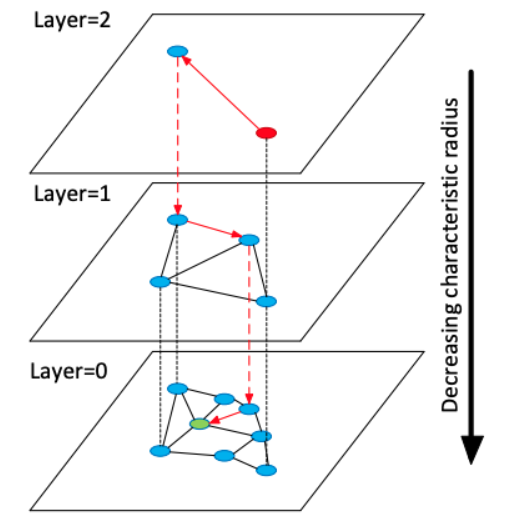
HNSW
import hnswlibimport numpy as npdef fit_hnsw_index(features, ef=100, M=16, save_index_file=False):# Convenience function to create HNSW graph# features : list of lists containing the embeddings# ef, M: parameters to tune the HNSW algorithmnum_elements = len(features)labels_index = np.arange(num_elements) EMBEDDING_SIZE = len(features[0]) # Declaring index# possible space options are l2, cosine or ipp = hnswlib.Index(space='l2', dim=EMBEDDING_SIZE) # Initing index - the maximum number of elements should be knownp.init_index(max_elements=num_elements, ef_construction=ef, M=M) # Element insertionint_labels = p.add_items(features, labels_index) # Controlling the recall by setting ef# ef should always be > kp.set_ef(ef)# If you want to save the graph to a fileif save_index_file:p.save_index(save_index_file)return p
ann_neighbor_indices, ann_distances = p.knn_query(features, k)# Imports# For input data pre-processingimport jsonimport gzipimport pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport fasttext.utilfasttext.util.download_model('en', if_exists='ignore') # English pre-trained modelft = fasttext.load_model('cc.en.300.bin')# For KNN vs ANN benchmarkingfrom datetime import datetimefrom tqdm import tqdmfrom sklearn.neighbors import NearestNeighborsimport hnswlib
# Data: http://deepyeti.ucsd.edu/jianmo/amazon/data = []with gzip.open('meta_Cell_Phones_and_Accessories.json.gz') as f:for l in f:data.append(json.loads(l.strip()))# Pre-Processing: https://colab.research.google.com/drive/1Zv6MARGQcrBbLHyjPVVMZVnRWsRnVMpV#scrollTo=LgWrDtZ94w89# Convert list into pandas dataframedf = pd.DataFrame.from_dict(data)df.fillna('', inplace=True)# Filter unformatted rowsdf = df[~df.title.str.contains('getTime')]# Restrict to just 'Cell Phones and Accessories'df = df[df['main_cat']=='Cell Phones & Accessories']# Reset indexdf.reset_index(inplace=True, drop=True)# Only keep the title columnsdf = df[['title']]# Check the dfprint(df.shape)df.head()

# Title Embedding using FastText Sentence Embeddingdf['emb'] = df['title'].apply(ft.get_sentence_vector)# Extract out the embeddings column as a list of lists for input to our NN algosX = [item.tolist() for item in df['emb'].values]
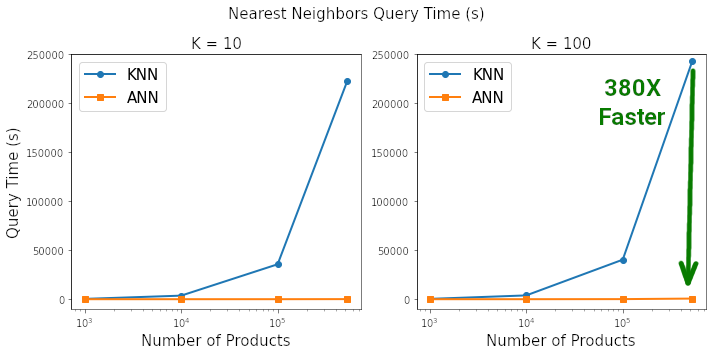
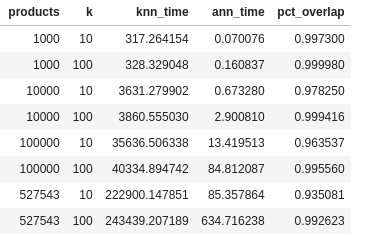
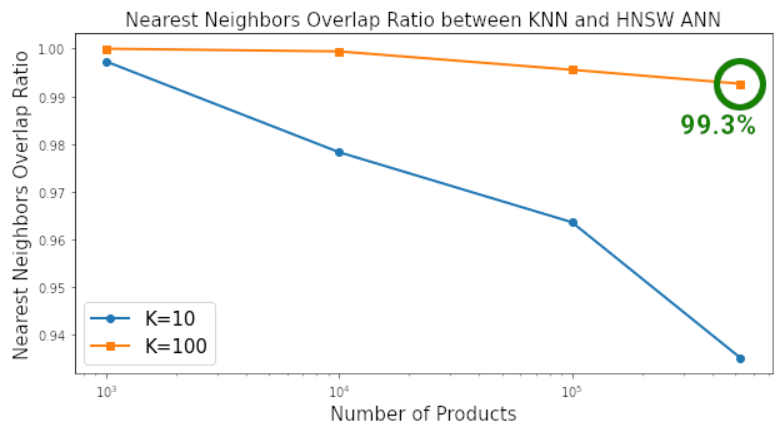
# Number of products for benchmark loopn_products = [1000, 10000, 100000, len(X)]# Number of neighbors for benchmark loopn_neighbors = [10, 100]# Dictionary to save metric results for each iterationmetrics = {'products':[], 'k':[], 'knn_time':[], 'ann_time':[], 'pct_overlap':[]}for products in tqdm(n_products):# "products" number of products included in the search spacefeatures = X[:products]for k in tqdm(n_neighbors):# "K" Nearest Neighbor search# KNNknn_start = datetime.now()nbrs = NearestNeighbors(n_neighbors=k, metric='euclidean').fit(features)knn_distances, knn_neighbor_indices = nbrs.kneighbors(X)knn_end = datetime.now()metrics['knn_time'].append((knn_end - knn_start).total_seconds())# HNSW ANNann_start = datetime.now()p = fit_hnsw_index(features, ef=k*10)ann_neighbor_indices, ann_distances = p.knn_query(features, k)ann_end = datetime.now()metrics['ann_time'].append((ann_end - ann_start).total_seconds())# Average Percent Overlap in Nearest Neighbors across all "products"metrics['pct_overlap'].append(np.mean([len(np.intersect1d(knn_neighbor_indices[i], ann_neighbor_indices[i]))/k for i in range(len(features))]))metrics['products'].append(products)metrics['k'].append(k)metrics_df = pd.DataFrame(metrics)metrics_df.to_csv('metrics_df.csv', index=False)metrics_df
推荐阅读
关于程序员大白
程序员大白是一群哈工大,东北大学,西湖大学和上海交通大学的硕士博士运营维护的号,大家乐于分享高质量文章,喜欢总结知识,欢迎关注[程序员大白],大家一起学习进步!
评论