
【baseline】Kaggle新赛!信用违约预测大赛
日前,Kaggle发布了American Express - Default Prediction 信用违约预测大赛。要求参赛者:
运用机器学习技能来预测信用违约

这是一个金融风控场景下的结构化数据挖掘任务,对本领域感兴趣的小伙伴,千万不要错过。
下面是本场比赛的baseline。
加我回复“运通”获取baseline+数据集
https://www.kaggle.com/competitions/amex-default-prediction
信用违约预测是管理消费贷款业务风险的核心。信用违约预测允许贷方优化贷款决策,从而带来更好的客户体验和稳健的商业经济。当前的模型可以帮助管理风险。但是有可能创建更好的模型,这些模型的性能优于当前使用的模型。美国运通是一家全球综合支付公司。作为世界上最大的支付卡发行商,他们为客户提供丰富生活和建立商业成功的产品、见解和体验。
在本次比赛中,您将运用机器学习技能来预测信用违约。具体来说,您将利用工业规模的数据集来构建机器学习模型,以挑战生产中的当前模型。训练、验证和测试数据集包括时间序列行为数据和匿名客户档案信息。您可以自由探索任何技术来创建最强大的模型,从创建特征到在模型中以更有机的方式使用数据。
3、评价指标
本次比赛的评估指标 𝑀 是排名排序的两个度量的平均值:归一化基尼系数 𝐺 和 4% 的违约率 𝐷组成: .
.
对于子指标 𝐺 和 𝐷,负标签的权重为 20 以调整下采样。计算过程可以从这里找到
https://www.kaggle.com/code/inversion/amex-competition-metric-python
4、数据介绍
本次比赛的目的是根据客户每月的客户资料预测客户未来不偿还信用卡余额的概率。目标二元变量是通过观察最近一次信用卡账单后 18 个月的绩效窗口来计算的,如果客户在最近一次账单日后的 120 天内未支付到期金额,则将其视为违约事件。
该数据集包含每个客户在每个报表日期的汇总配置文件特征。特征通过了匿名和归一化处理,特征可以分为以下类别:
D_* = 拖欠变量
S_* = 支出变量
P_* = 付款变量
B_* = 平衡变量
R_* = 风险变量
加我回复“运通”获取baseline+数据集
其中这些变量为类别变量:
['B_30', 'B_38', 'D_114', 'D_116', 'D_117', 'D_120', 'D_126', 'D_63', 'D_64', 'D_66', 'D_68']
是为每个customer_ID预测未来付款违约的概率(目标 = 1),每个文件内容的介绍如下:
train_data.csv - 每个 customer_ID 具有多个日期的训练数据
train_labels.csv - 每个 customer_ID 的目标标签
test_data.csv - 对应的测试数据;您的目标是预测每个 customer_ID 的目标标签
sample_submission.csv - 格式正确的示例提交文件
首先我们来查看下数据集,在数据集中的数据字段基本进行了匿名处理:
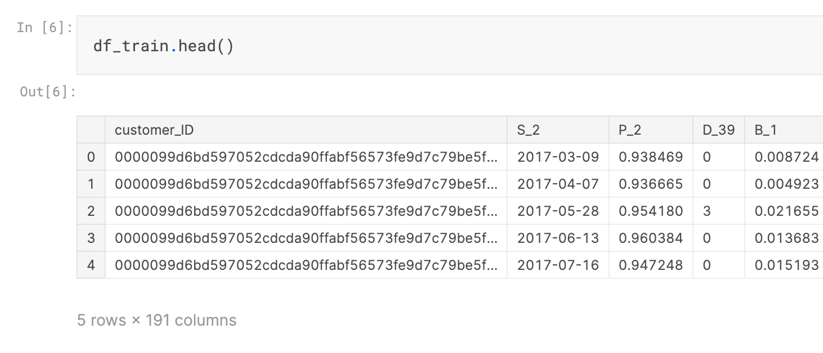
在数据集中也有较多的字段包含了缺失值:

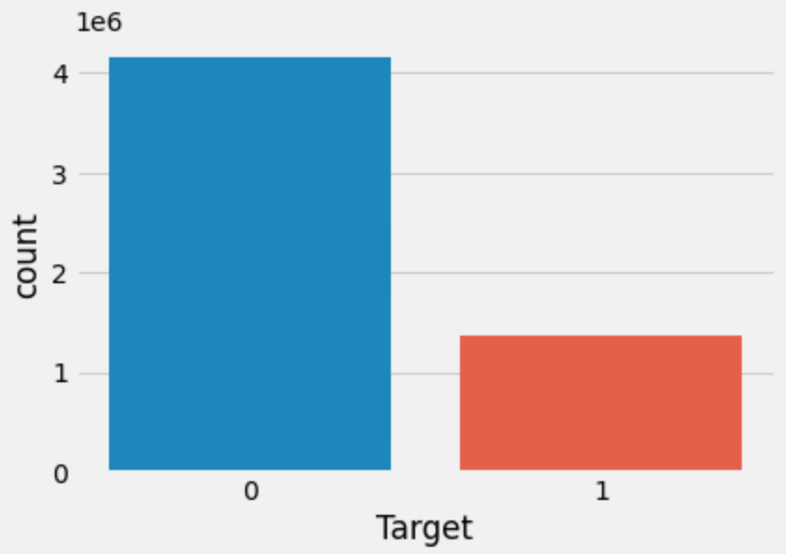
比赛标签分布中违约用户占比较少,类别分布比较均衡:
接下来我们可以查看字段按照分类之后的统计,如下图所示:

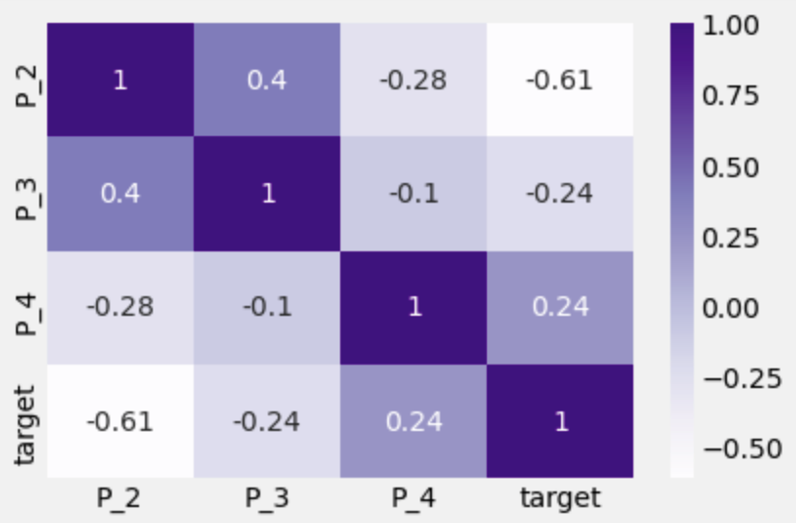
进一步我们也可以统计字段与标签的相关性:
由于数据集原始数据集文件较大(50GB左右),直接进行读取并进行分析并不可取。在进行送入模型进行之前可以考虑对数据值进行压缩,具体的压缩方法包括:
•将数据集中的类别字段,使用Pandas的category进行代替;
•将数据集中的数值字段,使用flaoat16和float32代替原始的float64;
•将数据集使用feather或者parquet格式进行存储;
通过上述方法可以将数据集压缩到总共5GB左右,接下来就可以尝试后续的建模过程。
数据集压缩和转换的过程可以参考:
https://www.kaggle.com/code/abdellatifsassioui/create-pickeld-data-from-50-gb-to-6gb
加我回复“运通”获取baseline+数据集
本次赛题是一个典型的匿名结构化比赛,因此可以考虑直接使用树模型来进行建模,具体的步骤为:
•对数据集进行处理
•定义树模型进行训练
•五折交叉完成预测
# XGB MODEL PARAMETERSxgb_parms = {'max_depth':4,'learning_rate':0.05,'subsample':0.8,'colsample_bytree':0.6,'eval_metric':'logloss','objective':'binary:logistic','tree_method':'gpu_hist','predictor':'gpu_predictor','random_state':SEED}
skf = KFold(n_splits=FOLDS)for fold,(train_idx, valid_idx) in enumerate(skf.split(train.target )):# TRAIN, VALID, TEST FOR FOLD KXy_train = IterLoadForDMatrix(train.loc[train_idx], FEATURES, 'target')X_valid = train.loc[valid_idx, FEATURES]y_valid = train.loc[valid_idx, 'target']dtrain = xgb.DeviceQuantileDMatrix(Xy_train, max_bin=256)dvalid = xgb.DMatrix(data=X_valid, label=y_valid)# TRAIN MODEL FOLD Kmodel = xgb.train(xgb_parms,dtrain=dtrain,evals=[(dtrain,'train'),(dvalid,'valid')],num_boost_round=9999,early_stopping_rounds=100,verbose_eval=100)model.save_model(f'XGB_v{VER}_fold{fold}.xgb')# GET FEATURE IMPORTANCE FOR FOLD Kdd = model.get_score(importance_type='weight')df = pd.DataFrame({'feature':dd.keys(),f'importance_{fold}':dd.values()})importances.append(df)# INFER OOF FOLD Koof_preds = model.predict(dvalid)acc = amex_metric_mod(y_valid.values, oof_preds)Metric =',acc,'\n')# SAVE OOFdf = train.loc[valid_idx, ['customer_ID','target'] ].copy()= oof_predsdf )del dtrain, Xy_train, dd, dfdel X_valid, y_valid, dvalid, model_ = gc.collect()
由于本次比赛数据量比较多,因此深度学习模型也可以考虑。深度学习模型主要需要调整网络结构,下面是一个基础的全连接网络代码:
def my_model(n_inputs=len(train.columns)):activation = 'swish'l1 = 1e-7l2 = 4e-4inputs = Input(shape=(n_inputs, ))x0 = BatchNormalization()(inputs)x0 = Dense(256,kernel_regularizer=tf.keras.regularizers.L1L2(l1=l1,l2=l2),activation=activation,)(x0)x0 = Dropout(0.1)(x0)x = Dense(64,kernel_regularizer=tf.keras.regularizers.L1L2(l1=l1,l2=l2),activation=activation,)(x0)x = Dense(64,kernel_regularizer=tf.keras.regularizers.L1L2(l1=l1,l2=l2),activation=activation,)(x)x = Concatenate()([x, x0])x = Dropout(0.1)(x)x = Dense(16,kernel_regularizer=tf.keras.regularizers.L1L2(l1=l1,l2=l2),activation=activation,)(x)x = Dense(1,activation='sigmoid',)(x)model = Model(inputs, x)=tf.keras.optimizers.Nadam(learning_rate=LR_START,clipvalue= 0.5,clipnorm = 1.0 # prevent gradient explosion),loss=tf.keras.losses.BinaryCrossentropy(),)del x,x0return model
加我回复“运通”获取baseline+数据集
本次比赛是一个典型的匿名结构化比赛,因此主要的关注点可以放在模型结构和模型集成。
• 可以优先调整每额每个模型,树模型和深度学习模型都可以取得0.796左右的精度;
• 增加每个模型的随机性,大量使用bagging进行训练;