
来!一起捋一捋机器学习分类算法
日期 : 2021年04月13日
正文共 :5700字

KNN算法的优缺点是什么?
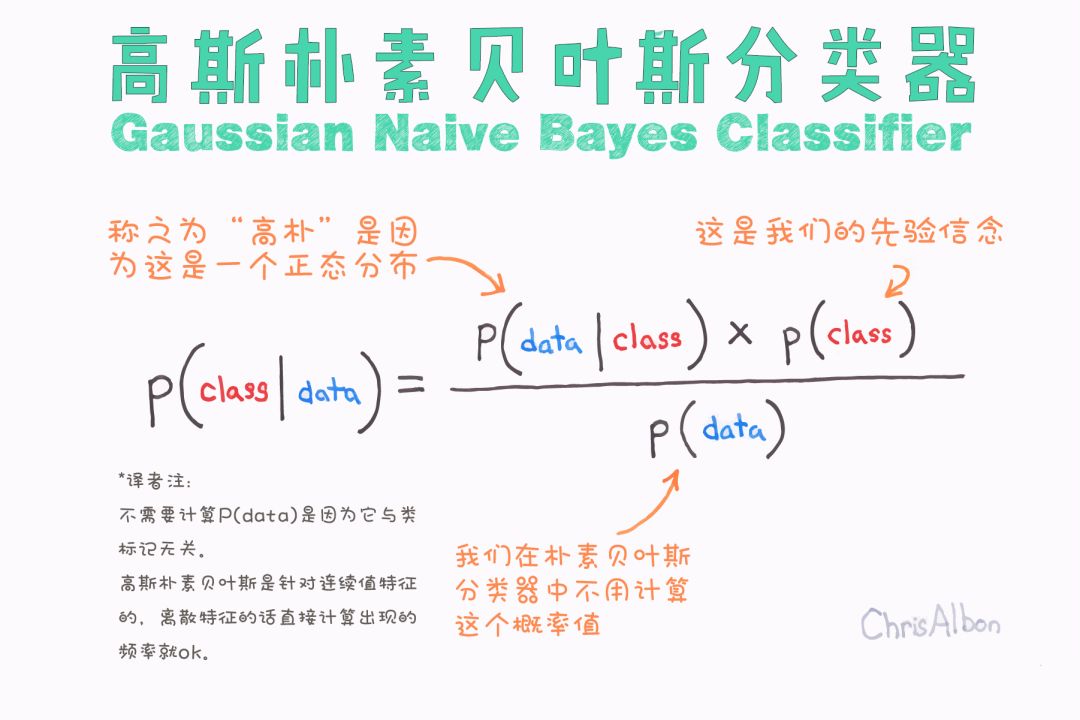
Naive Bayes算法的基本假设是什么?
entropy loss是如何定义的?
最后,分类算法调参常用的图像又有哪些?

机器学习是使计算机无需显式编程就能学习的研究领域。 ——阿瑟·塞缪尔,1959年
“如果一个程序在使用既有的经验(E)执行某类任务(T)的过程中被认为是“具备学习能力的”,那么它一定需要展现出:利用现有的经验(E),不断改善其完成既定任务(T)的性能(P)的特性。” ——Tom Mitchell, 1997
监督学习
分类问题

逻辑回归
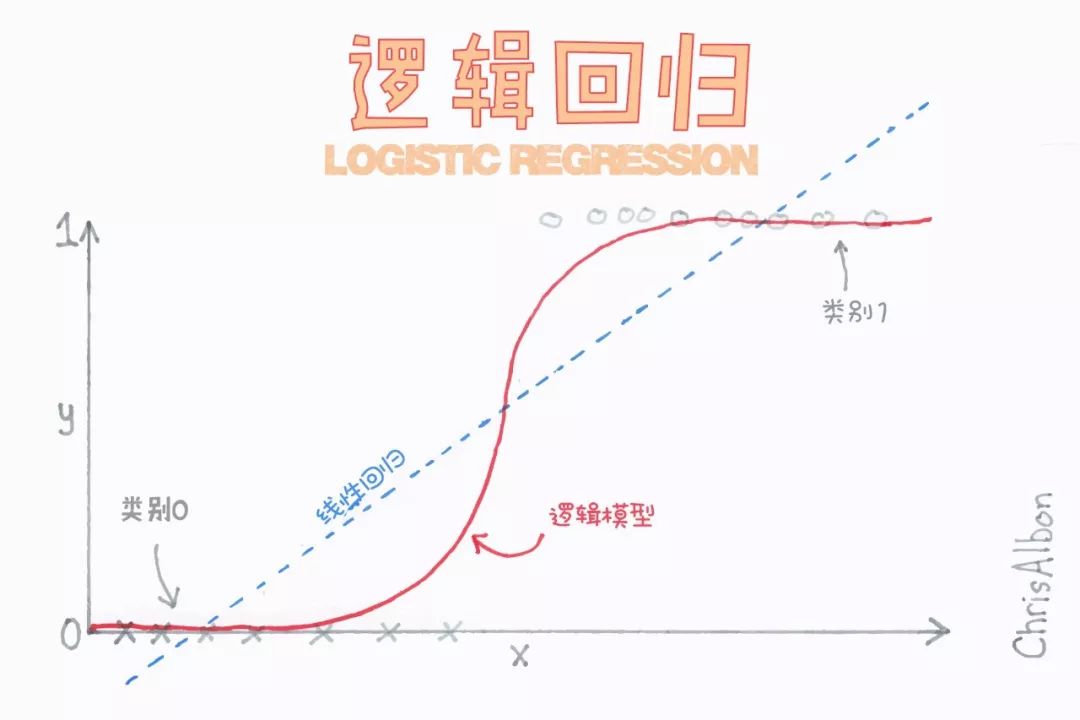
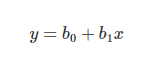
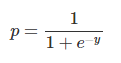
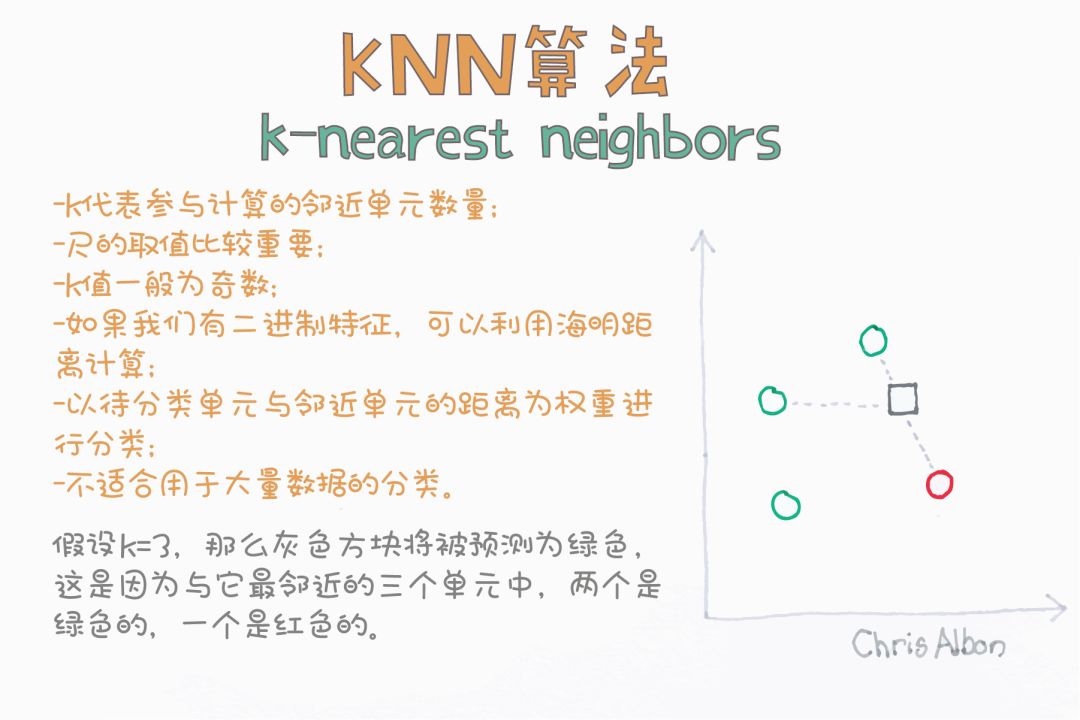
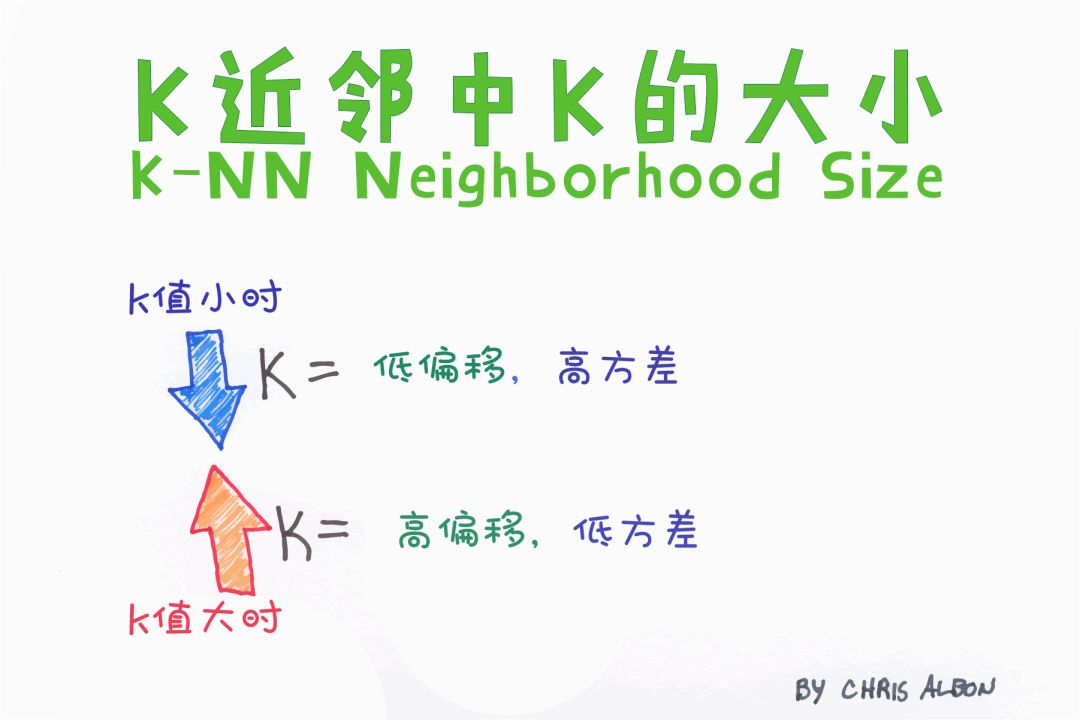
K-近邻算法(K-NN)


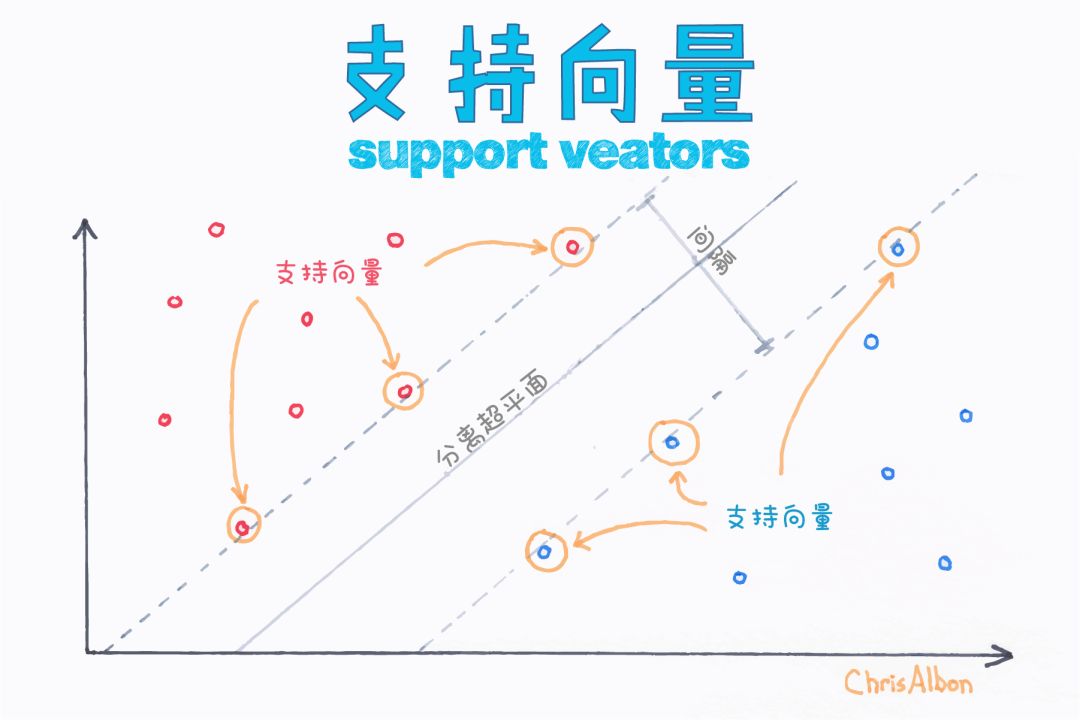
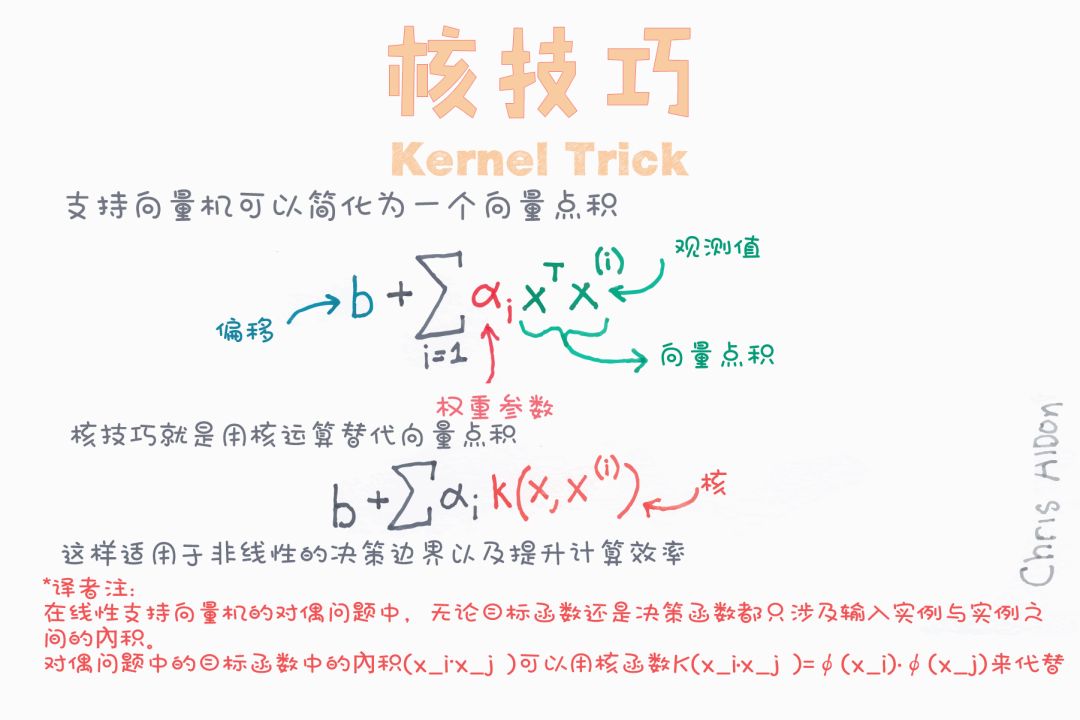
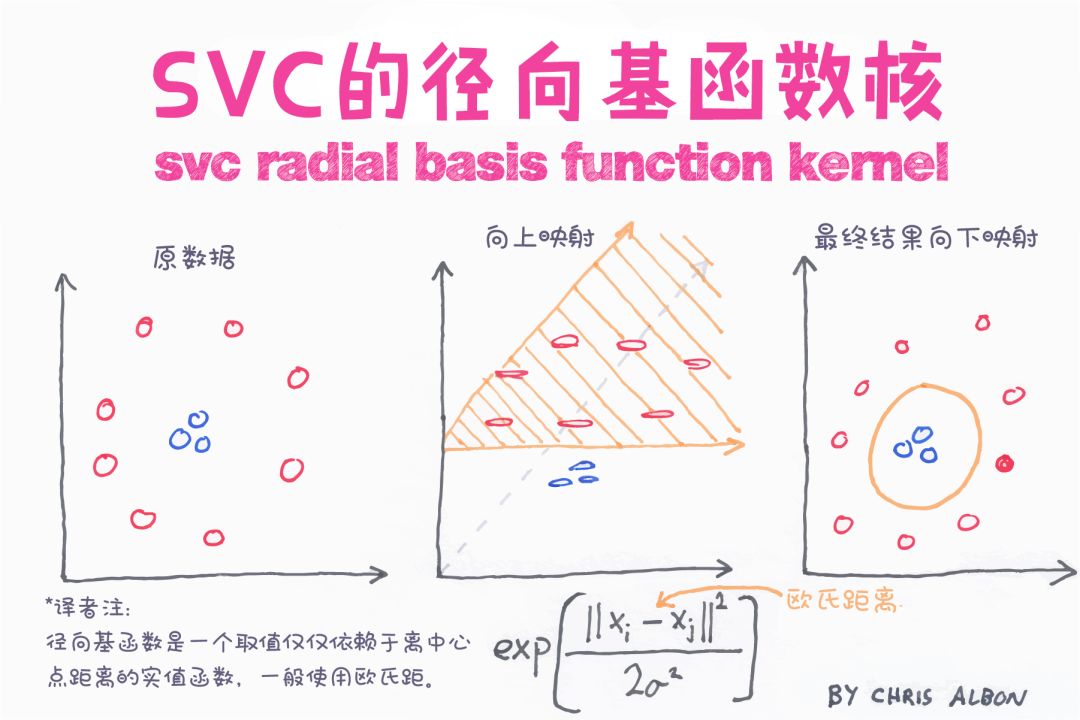
支持向量机(SVM)
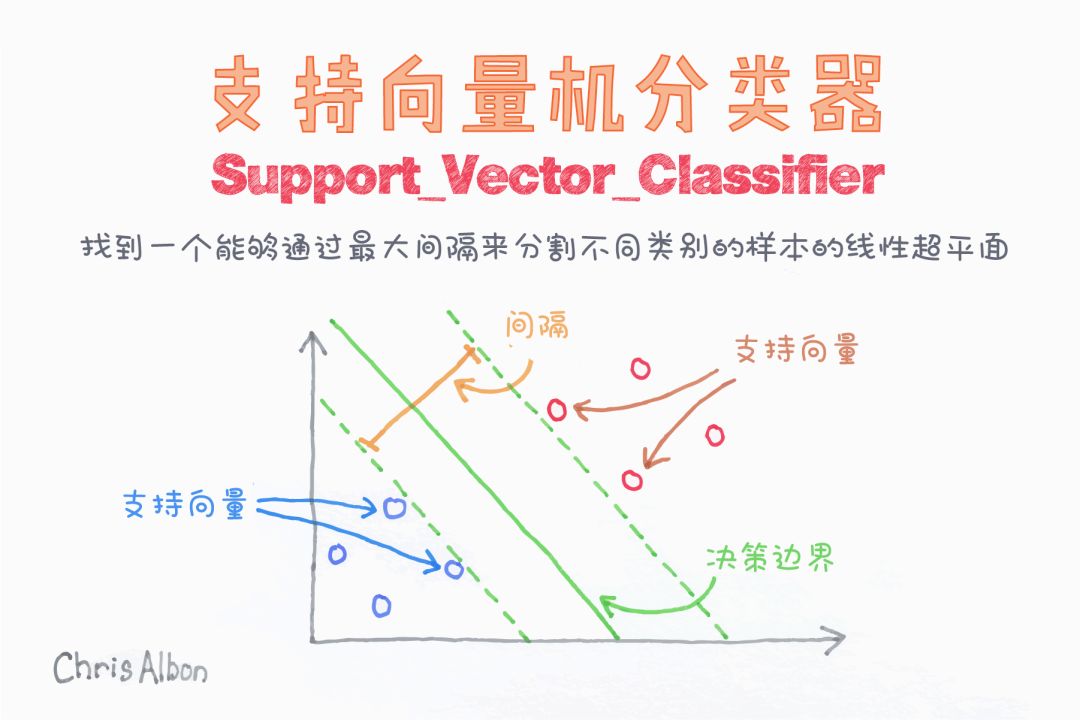
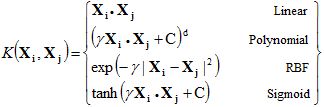
前文讨论的就是线性SVM。
多项式核中需要指定多项式的次数。它允许在输入空间中使用曲线进行分割。
径向基核(radial basis function, RBF)可用于非线性可分变量。使用平方欧几里德距离,参数的典型值会导致过度拟合。sklearn中默认使用RBF。
类似于与逻辑回归类似,sigmoid核用于二分类问题。
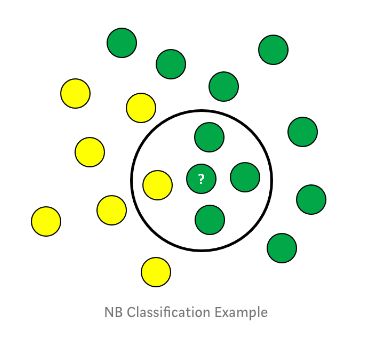
朴素贝叶斯

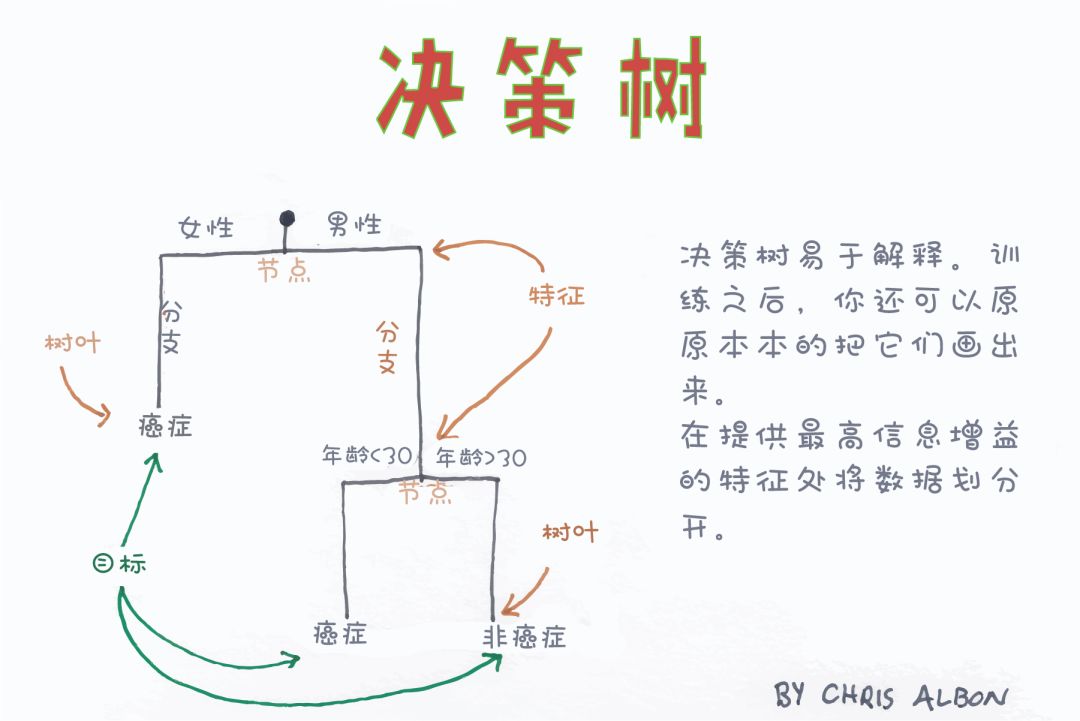
决策树分类
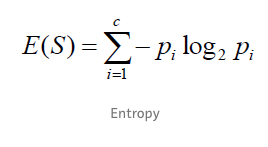
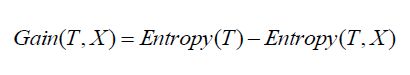
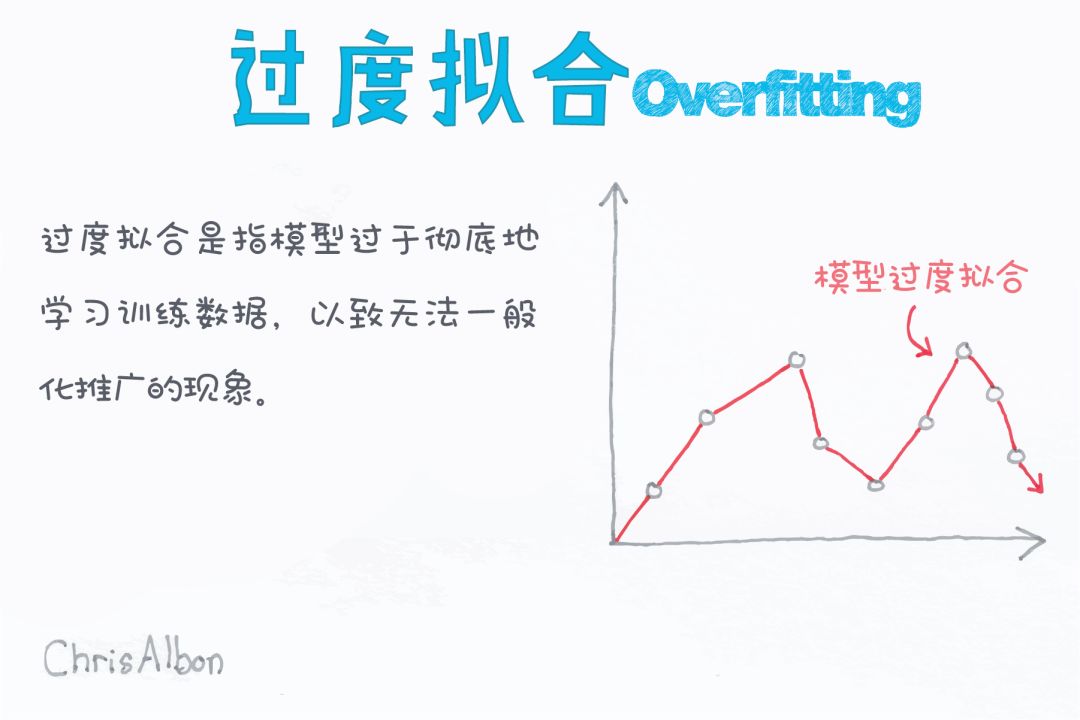
分类的集成算法

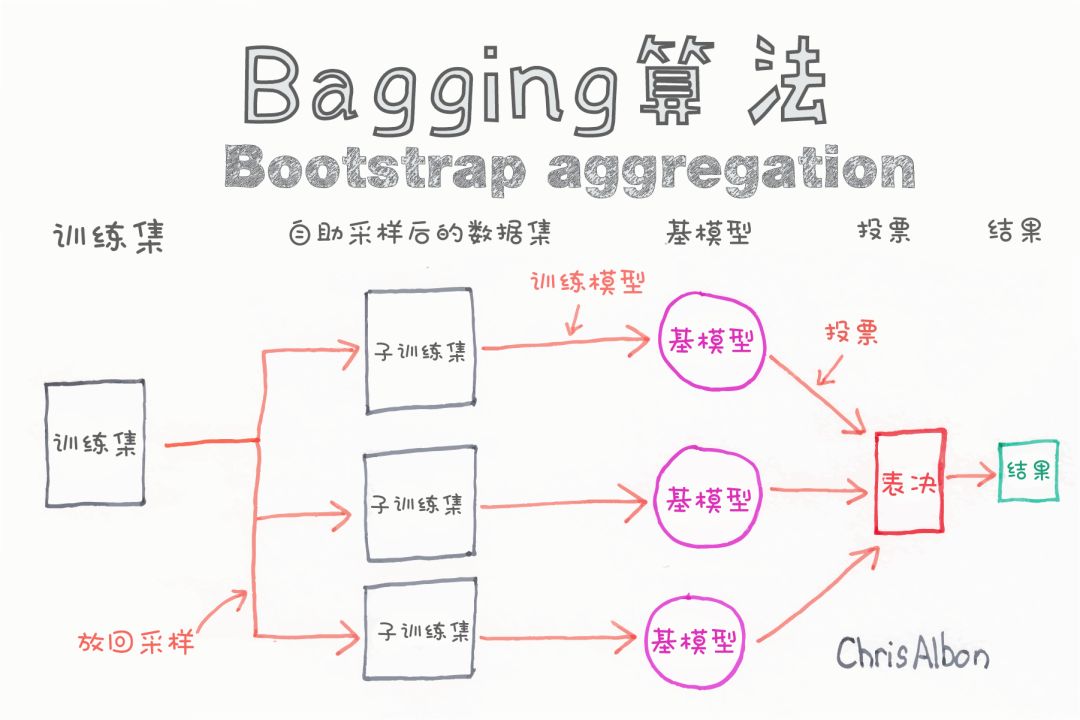
随机森林分类器
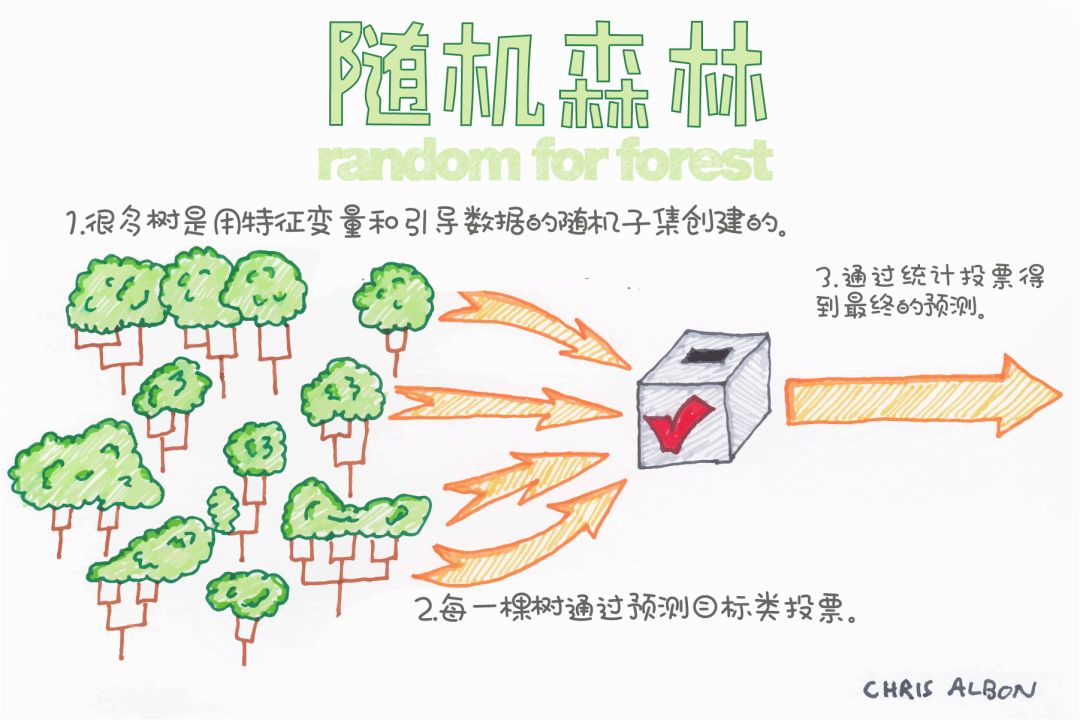
梯度提升分类器

使用浅层决策树初始化预测结果。
计算残差值(实际预测值)。
构建另一棵浅层决策树,将上一棵树的残差作为输入进行预测。
用新预测值和学习率的乘积作为最新预测结果,更新原有预测结果。
重复步骤2-4,进行一定次数的迭代(迭代的次数即为构建的决策树的个数)。
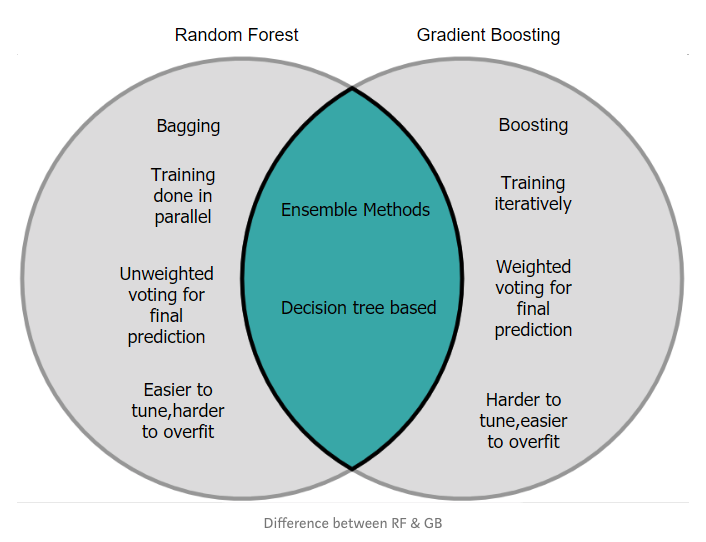
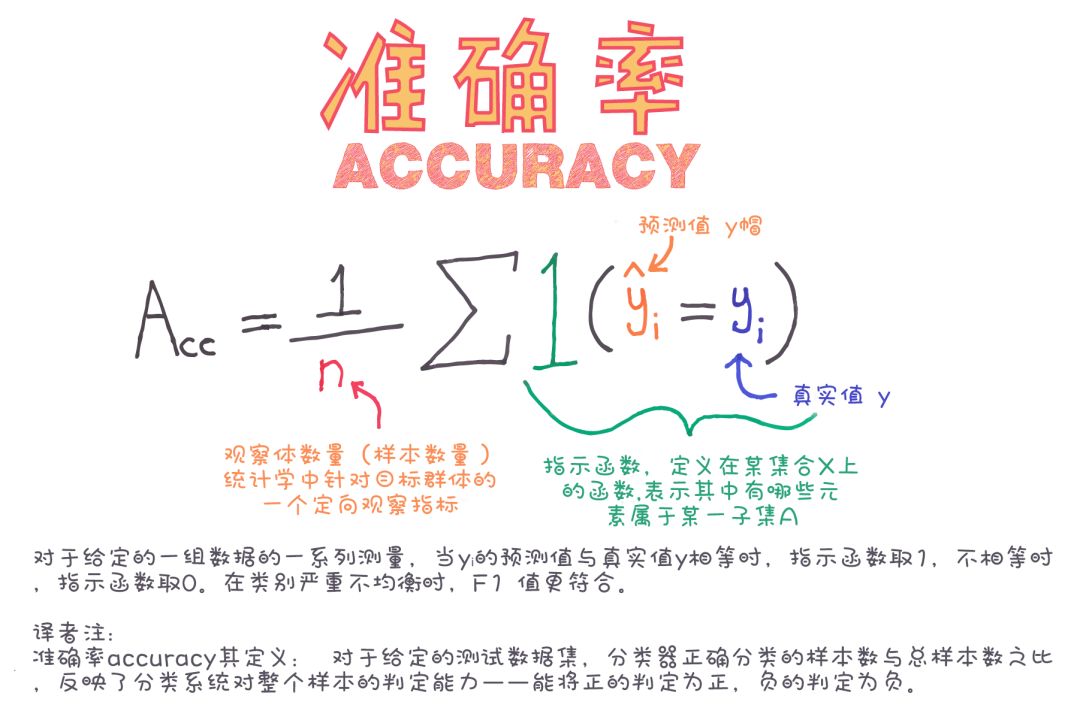
分类器的性能
混淆矩阵

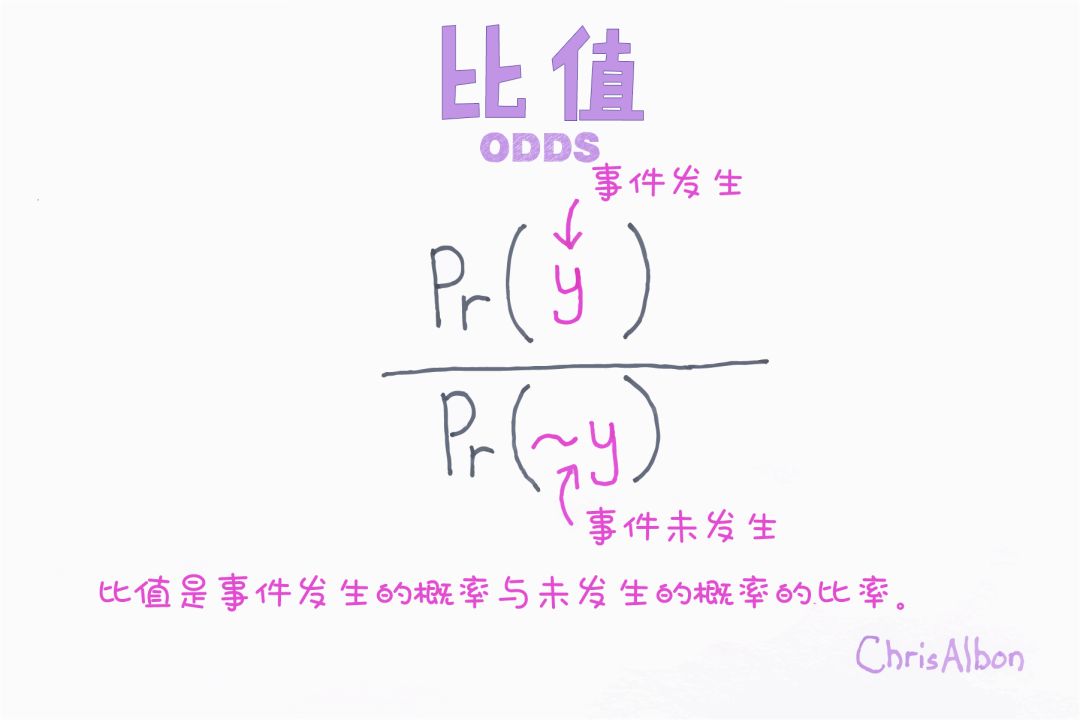
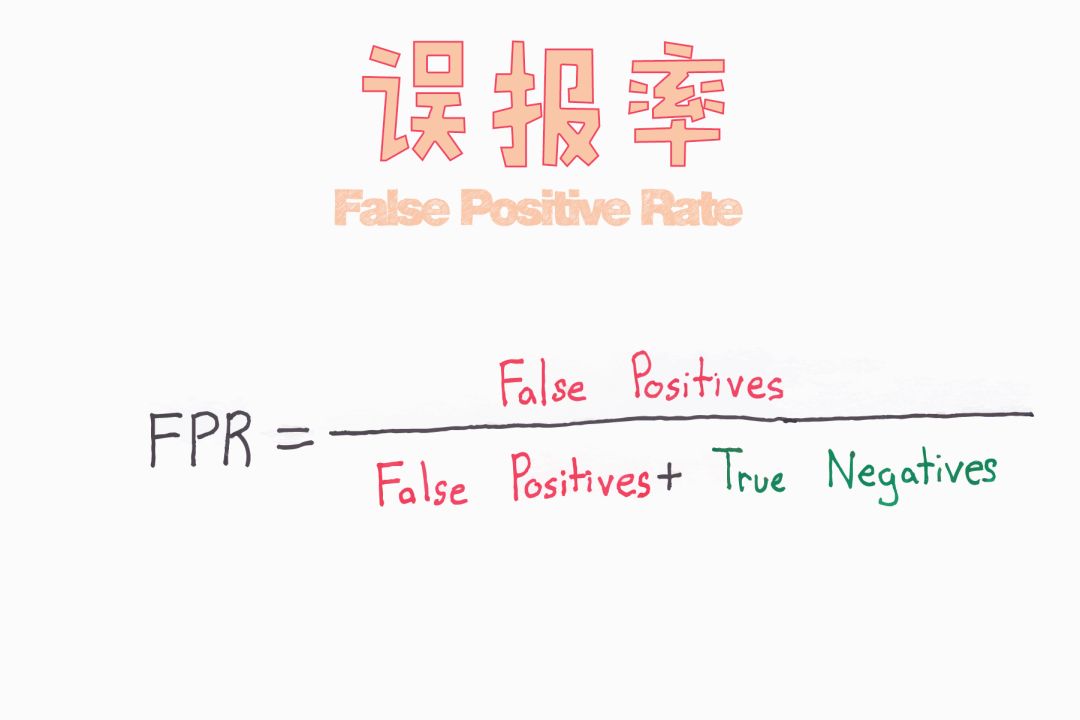
假正例&假负例

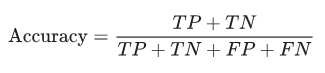



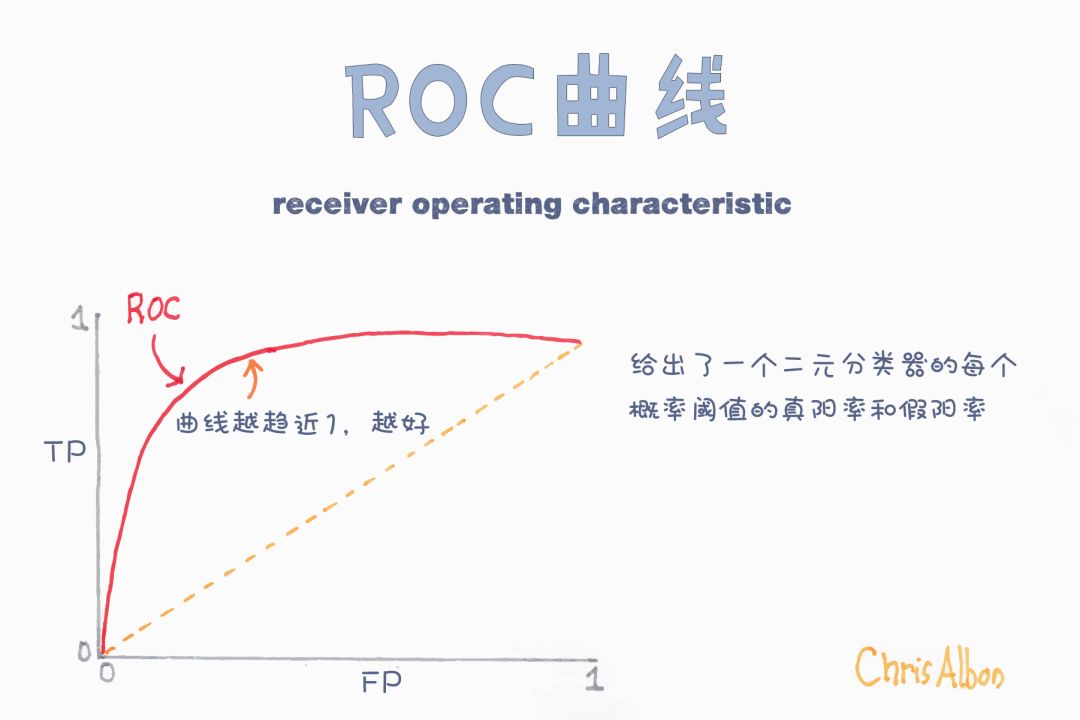
接受者操作曲线(ROC)和曲线下的面积(AUC)
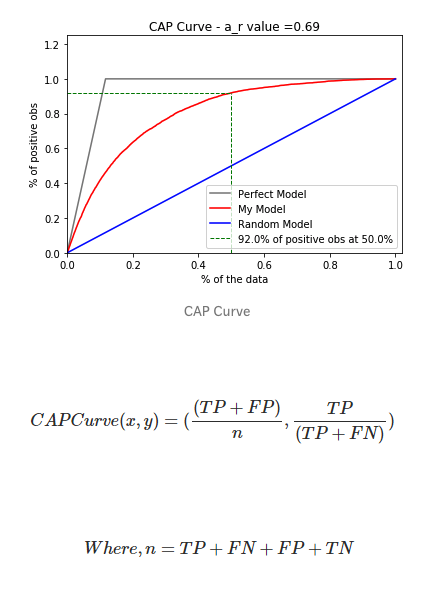
累积精度曲线
— THE END —

评论