
正则化技巧:标签平滑(Label Smoothing)以及在 PyTorch 中的实现

来源:DeepHub IMBA 本文约1200字,建议阅读5分钟
在这篇文章中,我们研究了标签平滑,这是一种试图对抗过度拟合和过度自信的技术。
标签平滑
标签平滑将目标向量改变少量 ε。因此,我们不是要求我们的模型为正确的类别预测 1,而是要求它为正确的类别预测 1-ε,并将所有其他类别预测为 ε。
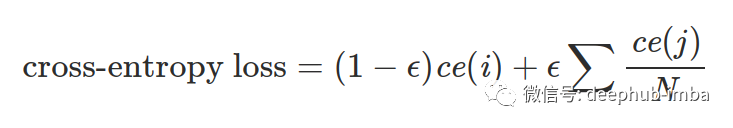
PyTorch 实现
def linear_combination(x, y, epsilon):return epsilon*x + (1-epsilon)*y
import torch.nn.functional as Fdef reduce_loss(loss, reduction='mean'):return loss.mean() if reduction=='mean' else loss.sum() if reduction=='sum' else lossclass LabelSmoothingCrossEntropy(nn.Module):def __init__(self, epsilon:float=0.1, reduction='mean'):super().__init__()self.epsilon = epsilonself.reduction = reductiondef forward(self, preds, target):n = preds.size()[-1]log_preds = F.log_softmax(preds, dim=-1)loss = reduce_loss(-log_preds.sum(dim=-1), self.reduction)nll = F.nll_loss(log_preds, target, reduction=self.reduction)return linear_combination(loss/n, nll, self.epsilon)
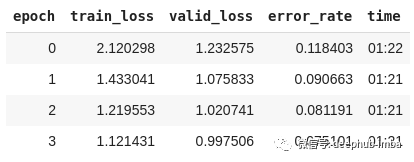
from fastai.vision import *from fastai.metrics import error_rate# prepare the datapath = untar_data(URLs.PETS)path_img = path/'images'fnames = get_image_files(path_img)bs = 64np.random.seed(2)pat = r'/([^/]+)_\d+.jpg$'data = ImageDataBunch.from_name_re(path_img, fnames, pat, ds_tfms=get_transforms(), size=224, bs=bs) \.normalize(imagenet_stats)# train the modellearn = cnn_learner(data, models.resnet34, metrics=error_rate)learn.loss_func = LabelSmoothingCrossEntropy()learn.fit_one_cycle(4)
总结
评论