
标签平滑 - Label Smoothing概述
点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达
来源:素质云笔记
目 录
One-Hot -> Label Smoothing
label smoothing 降低feature norm
标签平滑归一化:Label Smoothing Regularization (LSR)
label smoothing在什么场景有奇效?
什么时候不使用标签平滑
Label Smoothing 更进一步的思考研究
关于label smoothing是一些比赛中,比较常用的技巧,特别是图像多分类之中,效果蛮好的。这边整理一下,该技巧的文章,其中文章[6]写的非常赞,由其开篇。
当然这里,还有多种对应的说法:
Hard target和Soft target
hard label 和 soft label
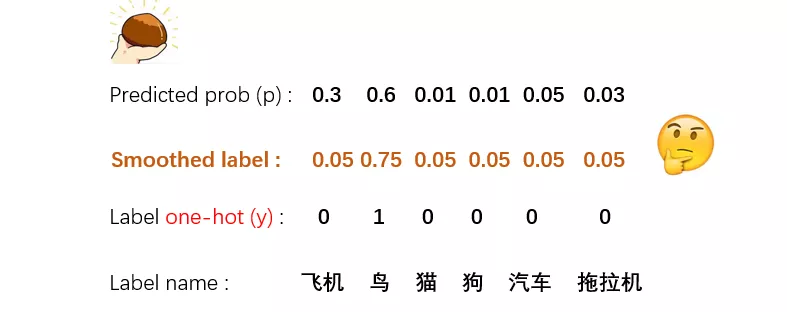
举一个问文章[2]的例子,Hard target和Soft target:

另一个hard label转变成soft label,文章[5]:
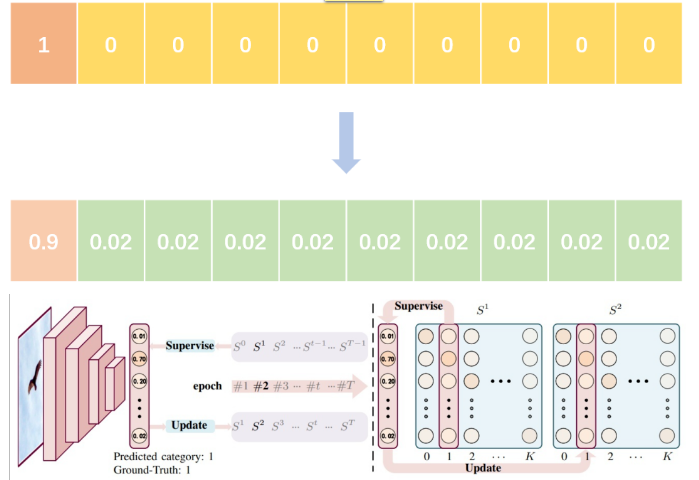
1 One-Hot -> Label Smoothing
文本分类和图像分类实际上在训练模式上是类似的,基本都遵循这样的一个流程:
step 1. 一个深度网络(DNN,诸如LSTM、CNN、BERT等)来得到向量表示
step 2. 一个softmax分类器来输出预测的标签概率分布p
step 3. 使用Cross-entropy来计算真实标签(one-hot表示)与p之间的损失,从而优化
这里使用cross-entropy loss(简称CE-loss)基本上成了大家训练模型的默认方法,但它实际上存在一些问题。下面我举个例子:
比如有一个六个类别的分类任务,CE-loss是如何计算当前某个预测概率p相对于y的损失呢:

可以看出,根据CE-loss的公式,只有y中为1的那一维度参与了loss的计算,其他的都忽略了。这样就会造成一些后果:
真实标签跟其他标签之间的关系被忽略了,很多有用的知识无法学到;比如:“鸟”和“飞机”本来也比较像,因此如果模型预测觉得二者更接近,那么应该给予更小的loss;
倾向于让模型更加“武断”,成为一个“非黑即白”的模型,导致泛化性能差;
面对易混淆的分类任务、有噪音(误打标)的数据集时,更容易受影响
总之,这都是由one-hot的不合理表示造成的,因为one-hot只是对真实情况的一种简化。
面对one-hot可能带来的容易过拟合的问题,有研究提出了Label Smoothing方法:
label smoothing就是把原来的one-hot表示,在每一维上都添加了一个随机噪音。这是一种简单粗暴,但又十分有效的方法,目前已经使用在很多的图像分类模型中了。
目前来看一下两者的优劣势:
one-hot 劣势:
- 可能导致过拟合。0或1的标记方式导致模型概率估计值为1,或接近于1,这样的编码方式不够soft,容易导致过拟合。为什么?
用于训练模型的training set通常是很有限的,往往不能覆盖所有的情况,特别是在训练样本比较少的情况下更为明显。
以神经机器翻译(NMT)为例:假设预测句子“今天下午我们去..”中,“去”后面的一个词。假设只有“去钓鱼”和“去逛街”两种搭配,且真实的句子是“今天下午我们去钓鱼”。
training set中,“去钓鱼”这个搭配出现10次,“去逛街”搭配出现40次。“去钓鱼”出现概率真实概率是20%,
“去逛街”出现的真实概率是80%。
因为采用0或1的表示方式,随着training次数增加,模型逐渐倾向于“去逛街”这个搭配,使这个搭配预测概率为100%或接近于100%,“去钓鱼”这个搭配逐渐被忽略。(文章[1])
- 另外,也会造成模型对它的预测过于confident,导致模型对观测变量x的预测严重偏离真实的情况,比如上述例子中,把“去逛街”搭配出现的概率从80%放大到100%,这种放大是不合理的。
Label Smoothing 优势:
一定程度上,可以缓解模型过于武断的问题,也有一定的抗噪能力
弥补了简单分类中监督信号不足(信息熵比较少)的问题,增加了信息量;
提供了训练数据中类别之间的关系(数据增强);
可能增强了模型泛化能力
降低feature norm (feature normalization)从而让每个类别的样本聚拢的效果(文章[10]提及)
产生更好的校准网络,从而更好地泛化,最终对不可见的生产数据产生更准确的预测。(文章[11]提及)
Label Smoothing 劣势:
单纯地添加随机噪音,也无法反映标签之间的关系,因此对模型的提升有限,甚至有欠拟合的风险。
它对构建将来作为教师的网络没有用处,hard 目标训练将产生一个更好的教师神经网络。(文章[11]提及)
2 label smoothing 降低feature norm
文章[10]提及了一个有意思的知识点:
Hinton组对Label Smoothing的分析文章[When Does Label Smoothing Help? https://arxiv.org/pdf/1906.02629.pdf],里面有一张图比较有意思:
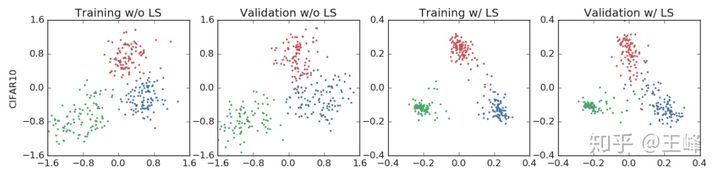
熟悉人脸识别loss的人会发现,这个Label Smoothing得到的特征分布,怎么跟人脸loss的效果这么像?
竟然都可以起到让每个类别的样本聚拢的效果。
而少数细心的朋友可能会发现这里的玄机:
不做Label Smoothing(标注为w/o LS)的feature norm,普遍比做了LS(标注为w/ LS)的要大很多!w/o LS时最大可以达到1.6,而w/ LS时只有0.4。
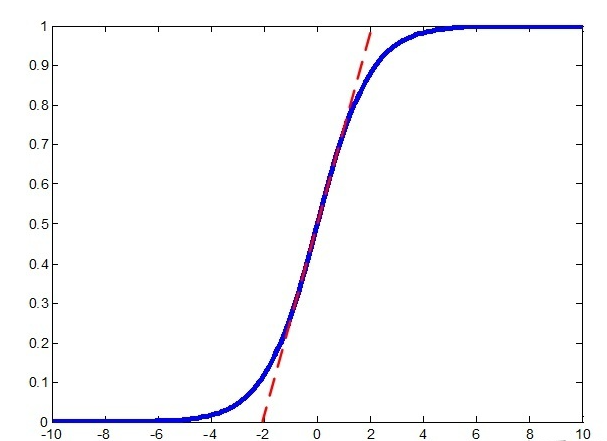
Label Smoothing也并不要求p优化到1,而是优化到0.9即可。Softmax Cross Entropy 的loss曲线其实跟sigmoid类似,越靠近1的时候,loss曲线会越平缓:
3 标签平滑归一化:Label Smoothing Regularization (LSR)
文章[1][2]提及该方法:
Label Smoothing Regularization(LSR)是一种通过在输出y中添加噪声,实现对模型进行约束,降低模型过拟合(overfitting)程度的一种约束方法(regularization methed)。
LSR也是对“硬目标”的优化:

Label Smoothing Regularization(LSR)就是为了缓解由label不够soft而容易导致过拟合的问题,使模型对预测less confident,把预测值过度集中在概率较大类别上,把一些概率分到其他概率较小类别上。
该方法应用在较多的论文中,譬如:
Attentional Encoder Network for Targeted Sentiment Classification
Müller R, Kornblith S, Hinton G. When Does Label Smoothing Help?[J]. arXiv preprint arXiv:1906.02629, 2019.
4 label smoothing在什么场景有奇效?
文章[4]提及了一些NLP领域使用场景的思考:
真实场景下,尤其数据量大的时候 数据里是会有噪音的(当然如果你非要说我100%确定数据都是完全正确的, 那就无所谓了啊),为了避免模型错误的学到这些噪音可以加入label smoothing
2.避免模型太自信了,有时候我们训练一个模型会发现给出相当高的confidence,但有时候我们不希望模型太自信了(可能会导致over-fit 等别的问题),希望提高模型的学习难度,也会引入label smoothing
3.分类的中会有一些模糊的case,比如图片分类,有些图片即像猫又像狗, 利用soft-target可以给两类都提供监督效果
hinton的这篇[when does label smoothing help? ]论文从另一个角度去解释了 label smoothing的作用:
多分类可能更效果, 类别更紧密,不同类别分的更开;小类别可能效果弱一些
发散一下,该策略如果用到序列标注等模型上,是不是效果会变好?
文章[5]提及,该策略可以使网络优化更加平滑:
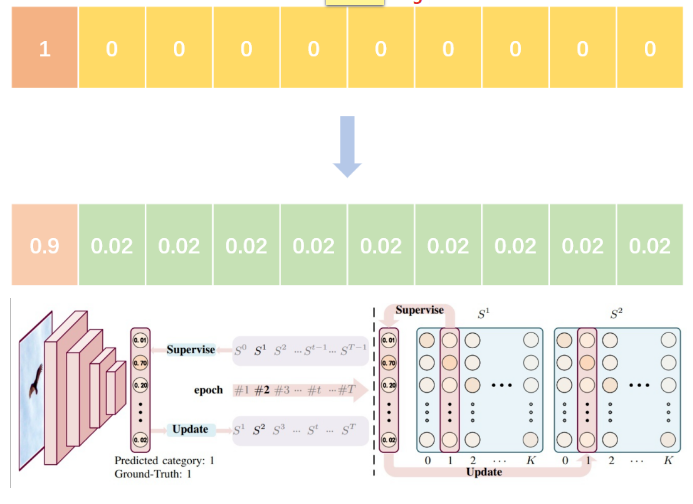
label smoothing将hard label转变成soft label,使网络优化更加平滑。标签平滑是用于深度神经网络(DNN)的有效正则化工具,该工具通过在均匀分布和hard标签之间应用加权平均值来生成soft标签。
它通常用于减少训练DNN的过拟合问题并进一步提高分类性能。
targets = (1 - label_smooth) * targets + label_smooth / num_classes
文章[8]在[观点阅读理解任务]比赛中也使用该策略:
focal loss的损失函数中加入了标签平滑(label smoothing),标签平滑[6]是一种防止模型过拟合的正则化手段。
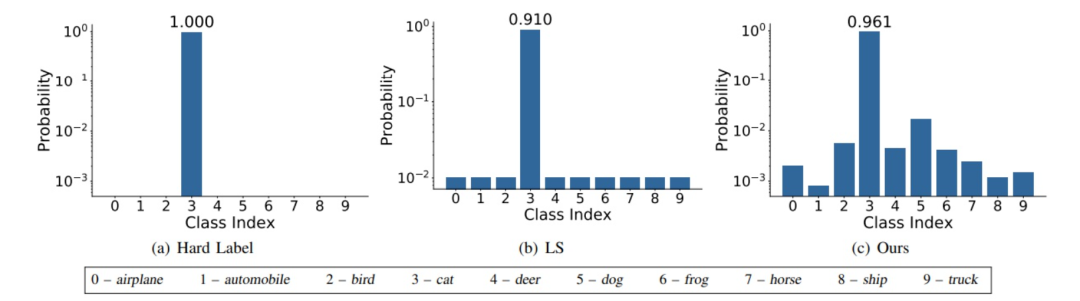
label smoothing是将真实的one hot标签做一个标签平滑处理,使得标签变成soft label。
其中,在真实label处的概率值接近于1,其他位置的概率值是个非常小的数。
在label smoothing中有个参数epsilon,描述了将标签软化的程度,该值越大,经过label smoothing后的标签向量的标签概率值越小,标签越平滑,反之,标签越趋向于hard label。
较大的模型使用label smoothing可以有效的提升模型的精度,较小的模型使用此种方法可能会降低模型精度。
本次比赛中,在多个roberta_large预训练模型微调过程中使用有一定的提升。
文章[9]提到在早先Google在Inception网络上就使用过这个技巧
对于Imagenet这个分类问题标签的种类是确定的K=1000类,所以在Inception论文[2]里直接用一个系数来控制平滑的强度,即平滑后的标签
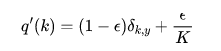
但是如果用同样方法在这些长短不一的句子上做平滑,其实是不合适的。每个位置的平滑概率反比于句子的长度,也就是K,所以我认为更好的确定平滑强度的方法是先确定一个单位平滑强度,再根据句子总长来确定原标签的权重。
文章[10]的大佬还细细研究了该策略为什么不能在人脸任务取得效果:
Label Smoothing起到的作用实际上是抑制了feature norm,此时softmax prob永远无法达到设定的 ,loss曲面上不再存在平缓区域,处处都有较大的梯度指向各个类中心,所以特征会更加聚拢。
而之所以人脸上不work,是因为我们通常会使用固定的s,此时Label Smoothing无法控制feature norm,只能控制角度,就会起到反向优化的作用,因此在人脸loss上加Label Smoothing效果会变差。
文章[11]也提及了与文章[10]类似的结论:
标签平滑强制对分类进行更紧密的分组,同时强制在聚类之间进行更等距的间隔。
标签平滑为最终的激活产生了更紧密的聚类和更大的类别间的分离。
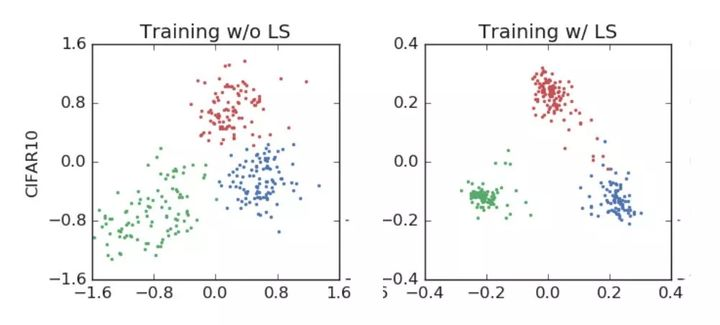
左:没有使用标签平滑进行训练,右:使用标签标签平滑进行训练
标签平滑可以产生更多的正则化和鲁棒的神经网络的主要原因,重要的是趋向于更好地泛化未来的数据
因此,标签平滑应该是大多数深度学习训练的一部分。然而,有一种情况是,它对构建将来作为教师的网络没有用处,hard 目标训练将产生一个更好的教师神经网络。
5 什么时候不使用标签平滑
文章[11]提及了一种不适用的场景:
尽管标签平滑可以产生用于各种任务的改进的神经网络……如果最终的模型将作为其他“学生”网络的老师,那么它不应该被使用。
尽管使用标签平滑化训练提高了教师的最终准确性,但与使用“硬”目标训练的教师相比,它未能向学生网络传递足够多的知识(没有标签平滑化)。
标签平滑“擦除”了在hard目标训练中保留的一些细节。
这样的泛化有利于教师网络的性能,但是它传递给学生网络的信息更少。
标签平滑产生的模型是不好的教师模型的原因可以通过初始的可视化或多或少的表现出来。
通过强制将最终的分类划分为更紧密的集群,该网络删除了更多的细节,将重点放在类之间的核心区别上。
这种“舍入”有助于网络更好地处理不可见数据。
然而,丢失的信息最终会对它教授新学生模型的能力产生负面影响。
因此,准确性更高的老师并不能更好地向学生提炼信息。
Label Smoothing 更进一步的思考研究
文章[6]针对label smoothing随机噪音 以及 smoothing值都为固定的缺陷,提出一个更优质的策略:
最终的目标,是能够使用更加合理的标签分布来代替one-hot分布训练模型,最好这个过程能够和模型的训练同步进行。
一个合理的标签分布,应该有什么样的性质。
**① 很自然地,标签分布应该可以反映标签之间的相似性。**比方下面这个例子:
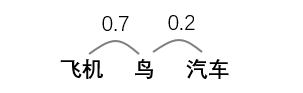
② 标签间的相似性是相对的,要根据具体的样本内容来看。比方下面这个例子,同样的标签,对于不同的句子,标签之间的相似度也是不一样的:
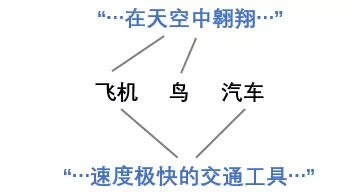
③ 构造得到的标签分布,在01化之后应该跟原one-hot表示相同。
啥意思呢,就是我们不能构造出了一个标签分布,最大值对应的标签跟原本的one-hot标签还不一致,我们最终的标签分布,还是要以one-hot为标杆来构造。
根据上面的思考,我们这样来设计模型:
使用一个Label Encoder来学习各个label的表示,与input sample的向量表示计算相似度,从而得到一个反映标签之间的混淆/相似程度的分布。
最后,使用该混淆分布来调整原来的one-hot分布,从而得到一个更好的标签分布。
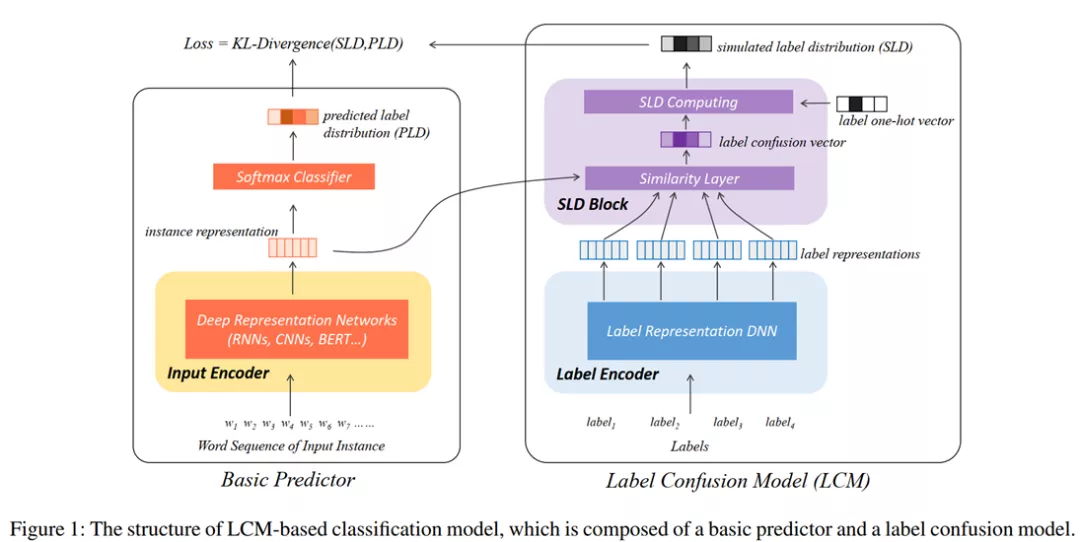
这个结构分两部分,左边是一个Basic Predictor,就是各种我们常用的分类模型。右边的则是LCM的模型。注意LCM是一个插件,所以左侧可以更换成任何深度学习模型。
参考文献
1 Label Smoothing Regularization_LSR原理是什么?
2 一文总览知识蒸馏概述
3 小方案蕴藏大改变,人物识别挑战赛TOP2团队依靠创新突围
4 label smoothing + knowledge distill + nlp
5 大道至简:算法工程师炼丹Trick手册
6 用模型“想象”出来的target来训练,可以提高分类的效果!
7 样本混进了噪声怎么办?通过Loss分布把它们揪出来!
8 百度人工智能开源大赛冠军分享——如何在观点阅读理解任务取得高分
9 Kaggle Tweet Sentiment Extraction 第七名复盘
10 Label Smoothing分析
11 标签平滑&深度学习:Google Brain解释了为什么标签平滑有用以及什么时候使用它
关联阅读
训练集 和 测试集分布是否一致——对抗验证(Adversarial Validation)
笔记︱模型压缩:knowledge distillation知识蒸馏(一)
竞赛技巧:TTA(Test Time Augmentation)与数据增强
个人微信(如果没有备注不拉群!)
请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021
在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
点亮  ,告诉大家你也在看
,告诉大家你也在看