
Sharding-JDBC分库连接数优化
一、背景
配运平台组的快递订单履约中心(cp-eofc)及物流平台履约中心(jdl-uep-ofc)系统都使用了ShardingSphere生态的sharding-jdbc作为分库分表中间件, 整个集群采用只分库不分表的设计,共16个MYSQL实例,每个实例有32个库,集群共512个库.
当每增加一台客户端主机,一个MYSQl实例最少要增加32个连接(通常都会使用连接池,根据配置的最大连接数,这个连接数可能会放大5~10倍).并且通常一个系统都会分为web,provider,worker等多个应用,这些应用共用一套数据源.随着应用机器数的增加,MYSQL实例的连接数会很快达到上限,这就对系统的扩容造成了阻碍,无法横向的增加机器数,只能纵向的提高机器的配置来应对流量的增长.
作为京东物流的核心系统,业务增长迅速,系统所承接的流量也是逐渐增加,所以急需解决这个制约系统扩展的瓶颈点。
二、分库分表的相关概念介绍
2.1 为什么要分库分表
2.1.1 分库
随着业务的发展,单库中的数据量不断增加,数据库的QPS会越来越高,对数据库的读写耗时也会相应的增长,这时单库的读写性能必然会成为系统的瓶颈点.这时可以通过将单个数据库拆分为多个数据库的方法,来分担数据库的压力,提升性能.同时多个数据库分布在不同的机器上也提高了数据库的可用性.
2.1.2 分表
随着单表数据量的增加,对于数据的查询和更新,即使在数据库底层有一定的优化,但是随着量变必定会引起质变,导致性能急剧下降.这时可以通过分表的方法,将单表数据按一定规则水平拆分到多个表中,减小单表的数据量,提升系统性能.
2.2 sharding-jdbc简介
ShardingSphere
是一套开源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar(计划中)这3款相互独立的产品组成.他们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如Java同构、异构语言、容器、云原生等各种多样化的应用场景。
Sharding-JDBC
定位为轻量级Java框架,在Java的JDBC层提供的额外服务。它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
适用于任何基于Java的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。基于任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。
支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer和PostgreSQL。
我们先看下ShardingSphere官网给出的基于Spring命名空间的规则配置示例:
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:sharding="http://shardingsphere.io/schema/shardingsphere/sharding"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://shardingsphere.io/schema/shardingsphere/sharding
http://shardingsphere.io/schema/shardingsphere/sharding/sharding.xsd
">
<!-数据源ds0->
<bean id="ds0" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
<property name="driverClassName" value="com.mysql.jdbc.Driver" />
<property name="url" value="jdbc:mysql://localhost:3306/ds0" />
<property name="username" value="root" />
<property name="password" value="" />
</bean>
<!-数据源ds1->
<bean id="ds1" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
<property name="driverClassName" value="com.mysql.jdbc.Driver" />
<property name="url" value="jdbc:mysql://localhost:3306/ds1" />
<property name="username" value="root" />
<property name="password" value="" />
</bean>
<!-分片策略->
<sharding:inline-strategy id="databaseStrategy" sharding-column="user_id" algorithm-expression="ds$->{user_id % 2}" />
<sharding:inline-strategy id="orderTableStrategy" sharding-column="order_id" algorithm-expression="t_order$->{order_id % 2}" />
<sharding:inline-strategy id="orderItemTableStrategy" sharding-column="order_id" algorithm-expression="t_order_item$->{order_id % 2}" />
<!-sharding数据源配置->
<sharding:data-source id="shardingDataSource">
<sharding:sharding-rule data-source-names="ds0,ds1">
<sharding:table-rules>
<sharding:table-rule logic-table="t_order" actual-data-nodes="ds$->{0..1}.t_order$->{0..1}" database-strategy-ref="databaseStrategy" table-strategy-ref="orderTableStrategy" />
<sharding:table-rule logic-table="t_order_item" actual-data-nodes="ds$->{0..1}.t_order_item$->{0..1}" database-strategy-ref="databaseStrategy" table-strategy-ref="orderItemTableStrategy" />
</sharding:table-rules>
</sharding:sharding-rule>
</sharding:data-source>
</beans>
配置总结:
-
需要配置多个数据源ds0,ds1;
-
分片策略中配置分片键(sharding-column)和分片表达式(algorithm-expression)需符合groovy语法;
-
在sharding数据源中<sharding:table-rule>标签中配置逻辑表名(logic-table),库分片策略(database-strategy-ref)和表分片策略(table-strategy-ref),actual-data-node属性由数据源名 + 表名组成,以小数点分隔,用于广播表;
三、问题分析与解决方案
3.1 问题分析
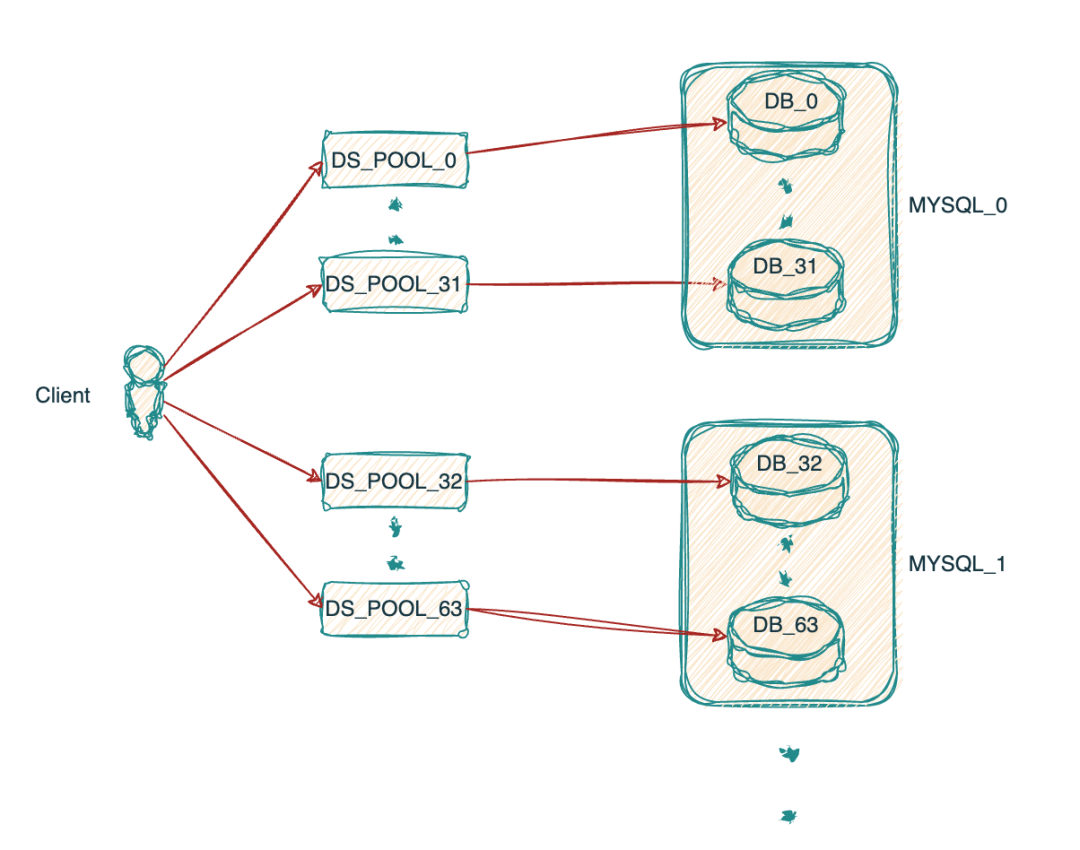
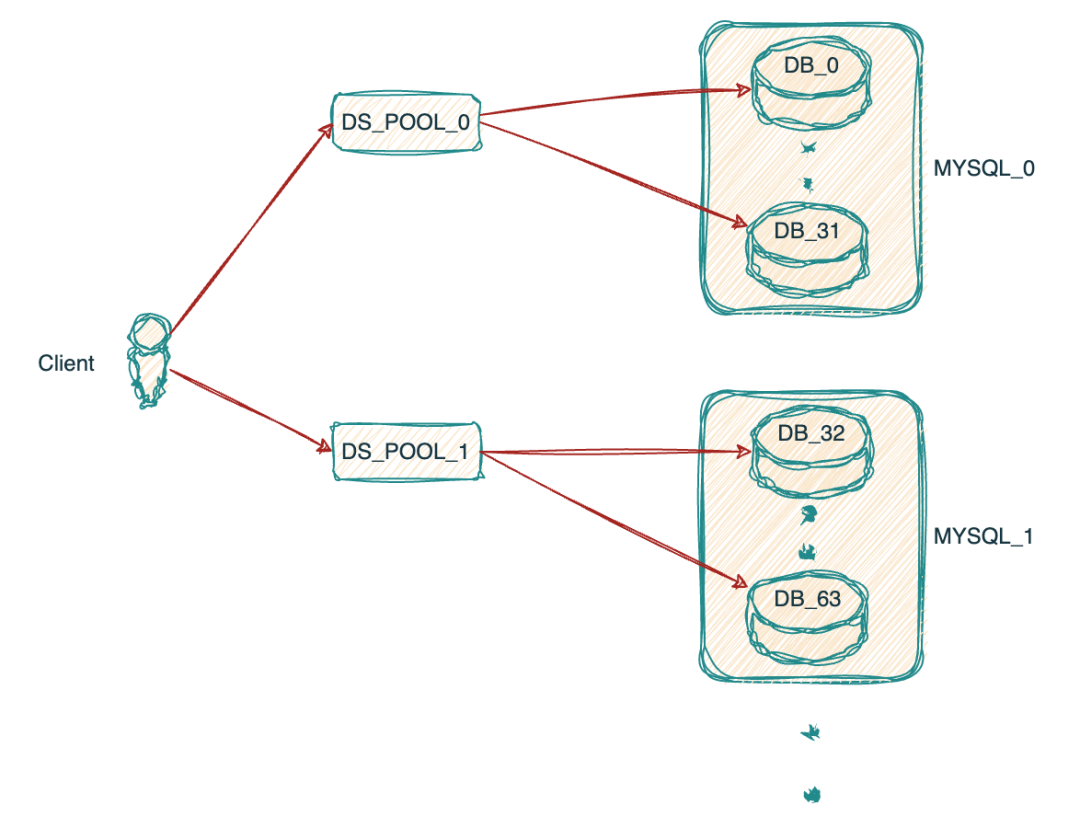
正如文章开头提到的目前我们的MYSQL集群架构如下,16个MYSQL实例,每个实例有32个库,集群共512个库.当客户端主机启动后与MYSQL_0实例中的32个库连接,分别会建立32个数据源,连接池配置的最大连接数为5,也就是说极端情况下一个客户端与一个MYSQL实例最多会建立32*5=160个连接数.对于物流的一些核心系统在大促时扩容上百台是很常见的,所以很快单个实例的最大连接数就会触达上限.
目前客户端连接连接数据库集群形式如图所示:
3.2 可行方案
我们的目标就是降低单个MYSQL实例的连接数,其中我们共探讨了几种方案如下:
3.2.1 单实例不分库只分表
这样一个客户端与单个数据库实例只需通过一个连接池连接,大大降低了连接数.但这种方案改变了现有的分片规则,需要新建一套数据库集群,根据新规则同步历史数据和增量数据,还有新旧数据验证,但难度和风险最高的还是线上切换过程,可能会造成数据不一致,且一旦出问题回滚方案也会非常复杂.
3.2.2 使用支持弹性扩展的数据库
使用京东的jed,tidb等支持弹性扩展的数据库,将数据同步到新库中,这类数据库的优势是开发人员只需关注业务,不需要再去处理数据库连接这些底层细节.
3.2.3 使用sharding-proxy
Sharding-Proxy的定位是透明化的数据库代理,我们可以在服务器上部署一套Sharding-Proxy,客户端只需连接proxy服务,再由proxy服务器连接MYSQL集群,这样MYSQL集群的连接数只与proxy服务器的数量有关,与客户端解耦.
3.2.4 通过改造sharding-jdbc
理论上我们只要获取数据库实例上某个库的连接,我们就可以通过"库名.表名"的方式访问这台实例上其他库中的数据(当然前提是用户要拥有要访问库的权限),我们是否可以通过改造sharding-jdbc来实现这种访问方式?
以上几种方案,3.2.1和3.2.2都需要新建数据库,同步历史和增量数据,还涉及线上切换数据源,3.2.3需要部署一套proxy服务,并且为了高可用必定要以集群方式部署,这三种方案工作量和风险都较高,我们基于成本最小原则,最终选择改造sharding-jdbc的方案.
3.3 探究sharding-jdbc
3.3.1 工作流程
sharding-jdbc的工作流程可以分为以下步骤:
-
sql解析-词法解析和语法解析;
-
sql路由-根据解析上下文匹配数据库和表的分片策略,并生成路由路径;
-
sql改写-将逻辑SQL改写为在真实数据库中可以正确执行的SQL;
-
sql执行-使用多线程并发执行sql;
-
结果归并-将从各个数据节点获取的多数据结果集,组合成为一个结果集并正确的返回至请求客户端;
显然数据库和表的分片是在sql路由阶段处理,所以我们以sql路由逻辑为入口分析下源码.
3.3.2 源码分析
ShardingStandardRoutingEngine类中的route方法为计算路由的入口,返回的结果是数据库和表的分片集合:
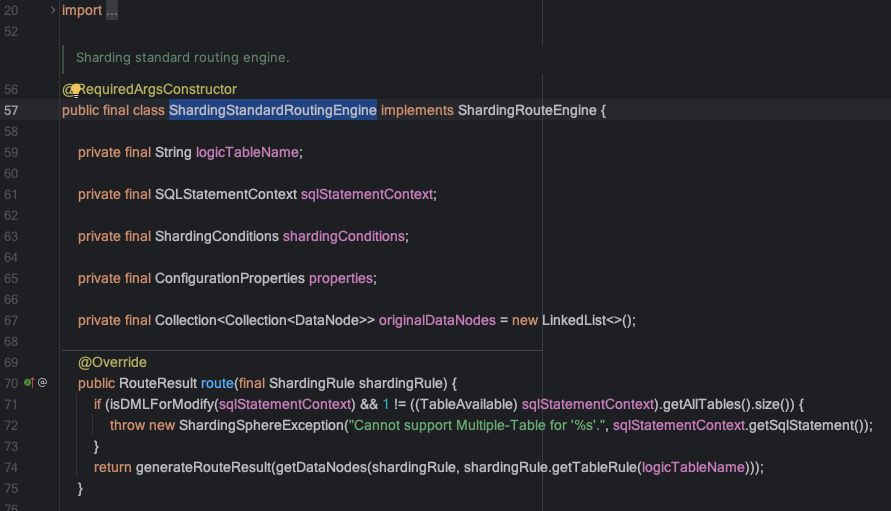
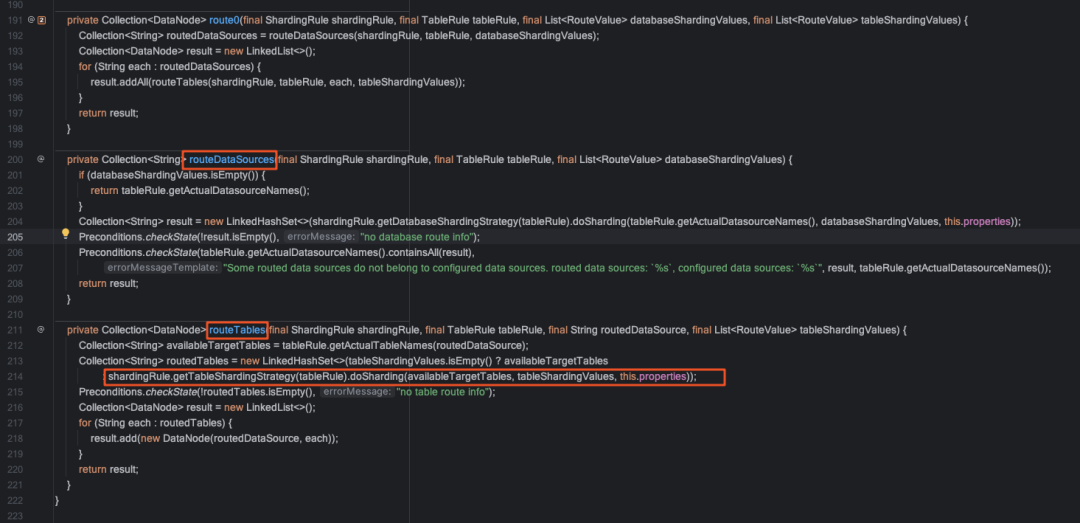
route方法中的核心逻辑在该类的route0方法中,其中routeDataSources方法负责database路由,routeTables方法负责table路由,实际路由计算在StandardShardingStrategy的doSharding方法中,我们继续深入.
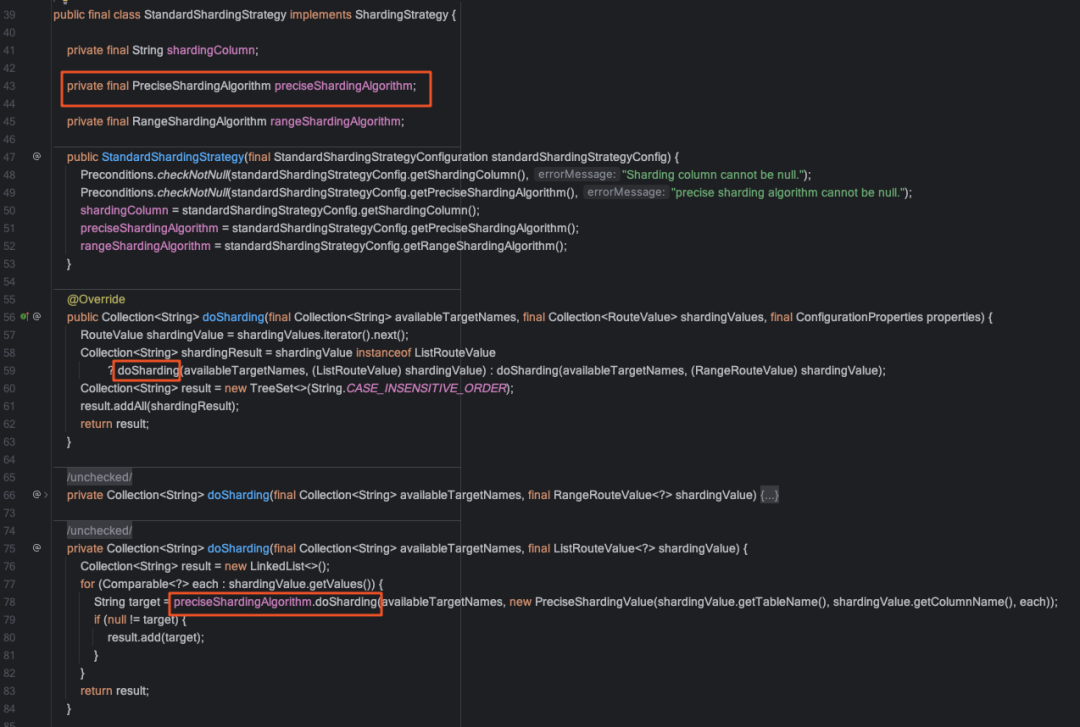
在StandardShardingStrategy类中有两个成员属性,preciseShardingAlgorithm(精准分片算法),rangeShardingAlgorithm(范围分片算法),由于我们的sql都只指定分片键精准查询,使用的都是preciseShardingAlgorithm计算出的结果,PreciseShardingAlgorithm是个接口,那我们就可以实现这个接口来自定义分片算法.
同时在sharding-sphere官网上也找到了相应的标签支持:

所以我们只需要自己实现PreciseShardingAlgorithm接口并配置在标签内即可实现自定义分片策略.
3.4 改造步骤
3.4.1 库分片改造
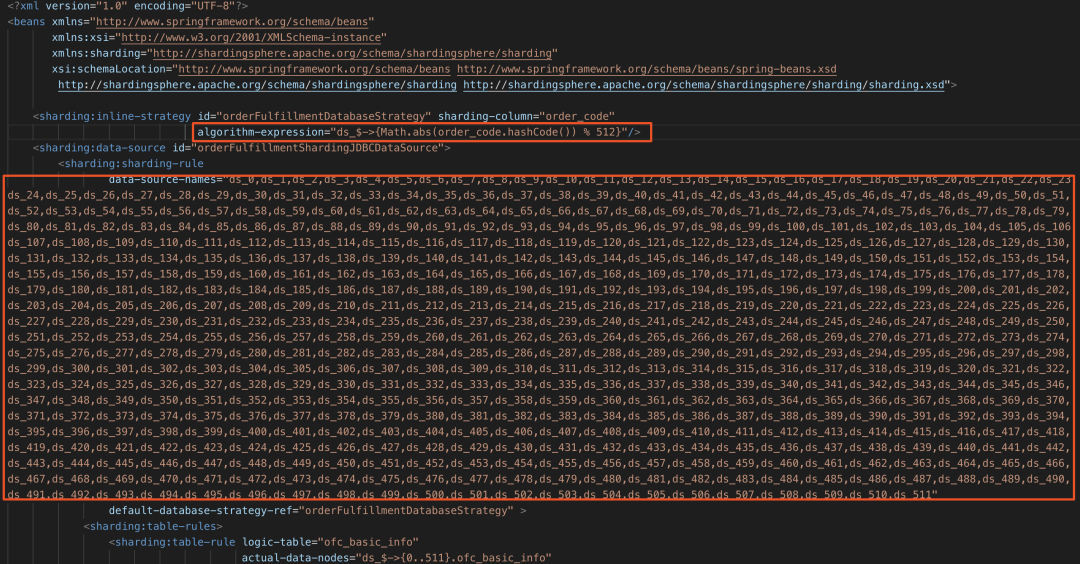
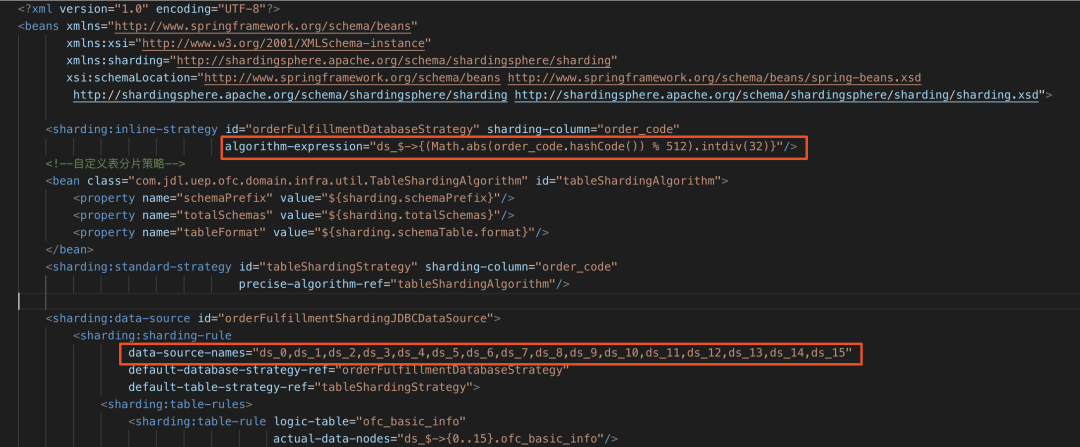
目前应用配置了ds_0~ds_511共512个数据源,我们只需配置ds_0~ds_15共16个数据源,每个数据源配置的是单个实例上的第一个库.
对于分片规则,我们可以依然使用<sharding:inline-strategy>标签,只需对Groovy表达式进行重写,分片键为order_code,之前分片算法为(Math.abs(order_code.hashCode()) % 512)即用order_code列的哈希值对512取模得到0~511,我们只需要将结果再整除32即可得到0~16,即表达式改写为(Math.abs(order_code.hashCode()) % 512).intdiv(32).
改造前分库规则配置:
改造后分库规则配置:
3.4.2 表分片改造
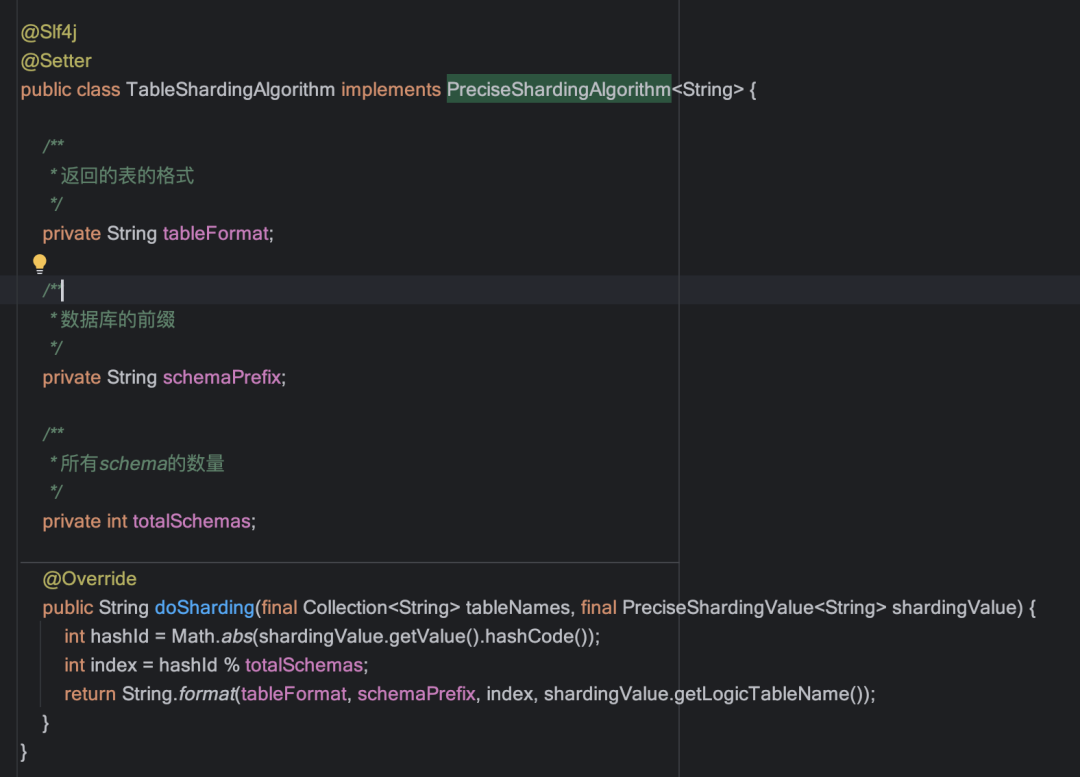
实现PreciseShardingAlgorithm接口,重写表分片算法,使计算结果返回"实际库名+表名"的形式;
例如:查询DB_31库上t_order表的user_id=35711的数据,数据库分片算法返回的数据源为"DB_0",表分片算法返回"DB_31.t_order";
自定义表分片算法:
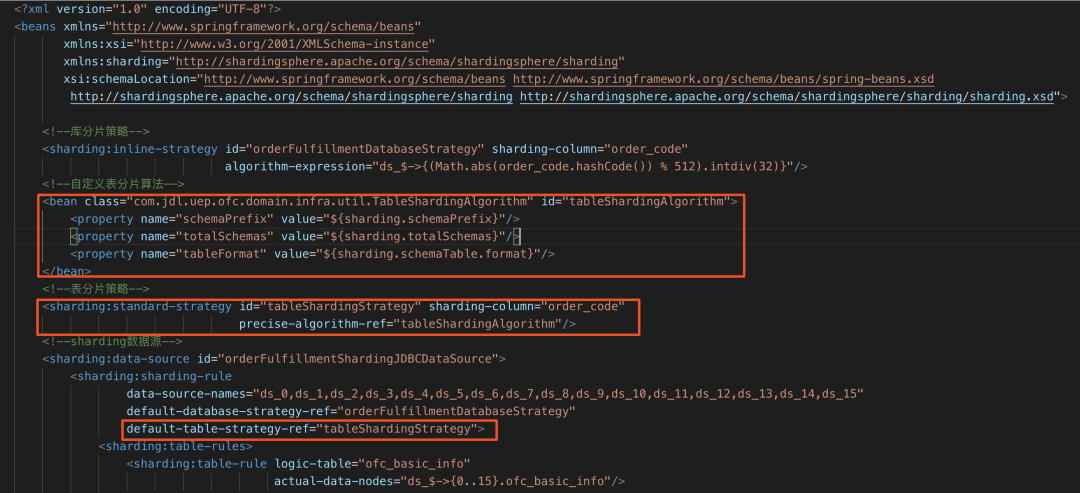
在xml中定义<sharding:standard-strategy>标签,其属性precise-algorithm-ref配置为我们自定义的分表算法.
3.4.3 数据库连接池参数调整
改造前是一个库对应一个数据源连接池,改造后一个实例上的32个库共用一个数据源连接池,那么连接池的最大连接数,最小空闲连接数等参数需要相应的做调整.这个需要根据业务流量做合理的评估,当然最严谨的还是要以压测结果作为依据.
改造后客户端连接集群的形式如图:
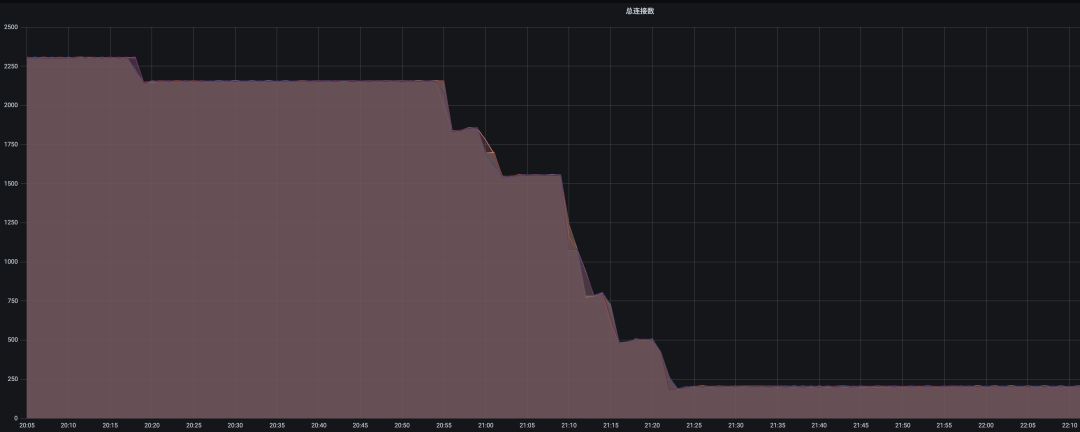
优化前后数据库集群连接数对比:
四、小插曲
在改写库分片规则的Groovy表达式时,整除32直接在原有表达式上配置"/32"即Math.abs(order_code.hashCode()) % 512 / 32 ,在调试中发现执行sql会报"no database route info"错误信息,经过debug发现sharding-jdbc计算分片规则时会出现小数(例如:ds_14.6857),导致找不到数据源,这是因为Groovy没有提供专用的整数除法运算符,所以要用.intdiv()方法,最终表达式改写为(Math.abs(order_code.hashCode()) % 512).intdiv(32).
五、总结
本文介绍了分库分表的概念及优势,以及sharding-jdbc分库分表中间件,探究了sharding-jdbc的路由规则的执行流程.当然在系统设计之初,对于数据库的分库分表,到底需不需要做?是多分库好还是多分表好?并没有一个放之四海而皆准的法则,需结合系统的特点(例如qps,tps,单表数据量,磁盘规格,数据保留时间,业务增量,数据冷热方案等因素)来决策权衡,有利有弊才需决策,有取有舍才需权衡.
-end-