
分库分表常见概念解读+Sharding-JDBC实战
之前有不少刚入坑 Java 的粉丝留言,想系统的学习一下分库分表相关技术,可我一直没下定决心搞,眼下赶上公司项目在使用 sharding-jdbc 对现有 MySQL 架构做分库分表的改造,所以借此机会出一系分库分表落地实践的文章,也算是自己对架构学习的一个总结。
我在网上陆陆续续的也看了一些有关于分库分表的文章,可发现网上同质化的资料有点多,而且知识点又都比较零碎,还没有详细的实战案例。为了更深入的学习下,我在某些平台买了点付费课程,看了几节课发现有点经验的人看还可以,但对于新手入门来说,其实学习难度还是蛮大的。
为了让新手也能看得懂,有些知识点我可能会用更多的篇幅加以描述,希望大家不要嫌我啰嗦,等这分库分表系列文章完结后,我会把它做成 PDF 文档开源出去,能帮一个算一个吧!如果发现文中有哪些错误或不严谨之处,欢迎大家交流指正。
具体实践分库分表之前在啰嗦几句,回头复习下分库分表的基础概念。
什么是分库分表
其实 分库 和 分表 是两个概念,只不过通常分库与分表的操作会同时进行,以至于我们习惯性的将它们合在一起叫做分库分表。
分库分表是为了解决由于库、表数据量过大,而导致数据库性能持续下降的问题。按照一定的规则,将原本数据量大的数据库拆分成多个单独的数据库,将原本数据量大的表拆分成若干个数据表,使得单一的库、表性能达到最优的效果(响应速度快),以此提升整体数据库性能。
如何分库分表
分库分表的核心理念就是对数据进行切分(Sharding),以及切分后如何对数据的快速定位与查询结果整合。而分库与分表都可以从:垂直(纵向)和 水平(横向)两种纬度进行切分。
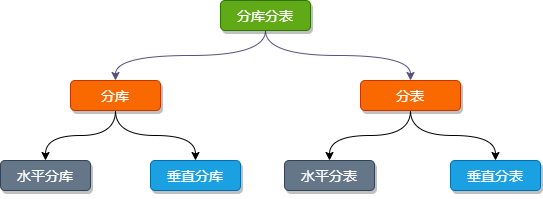
下边我们就以订单相关的业务举例,看看如何做库、表的 垂直 和 水平 切分。
垂直切分
垂直切分有 垂直 分库 和 垂直分表。
1、垂直分库
垂直分库相对来说是比较好理解的,核心理念就四个字:专库专用。
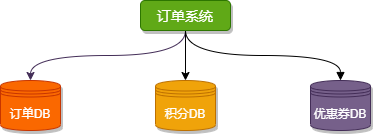
按业务类型对表进行分类,像订单、支付、优惠券、积分等相应的表放在对应的数据库中。开发者不可以跨库直连别的业务数据库,想要其他业务数据,对应业务方可以提供 API 接口,这就是微服务的初始形态。
垂直分库很大程度上取决于业务的划分,但有时候业务间的划分并不是那么清晰,比如:订单数据的拆分要考虑到与其他业务间的关联关系,并不是说直接把订单相关的表放在一个库里这么简单。
在一定程度上,垂直分库似乎提升了一些数据库性能,可实际上并没有解决由于单表数据量过大导致的性能问题,所以就需要配合水平切分方式来解决。
2、垂直分表
垂直分表是基于数据表的列(字段)为依据切分的,是一种大表拆小表的模式。
例如:一张 order 订单表,将订单金额、订单编号等访问频繁的字段,单独拆成一张表,把 blob 类型这样的大字段或访问不频繁的字段,拆分出来创建一个单独的扩展表 work_extend ,这样每张表只存储原表的一部分字段,再将拆分出来的表分散到不同的库中。
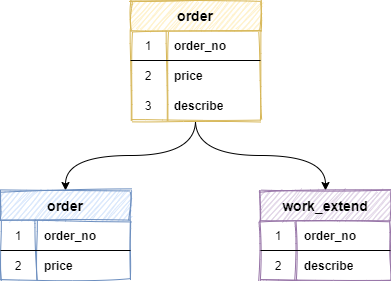
我们知道数据库是以行为单位将数据加载到内存中,这样拆分以后核心表大多是访问频率较高的字段,而且字段长度也都较短,因而可以加载更多数据到内存中,来增加查询的命中率,减少磁盘IO,以此来提升数据库性能。
垂直切分的优点:
业务间数据解耦,不同业务的数据进行独立的维护、监控、扩展。 在高并发场景下,一定程度上缓解了数据库的压力。
垂直切分的缺点:
提升了开发的复杂度,由于业务的隔离性,很多表无法直接访问,必须通过接口方式聚合数据。 分布式事务管理难度增加。 数据库还是存在单表数据量过大的问题,并未根本上解决,需要配合水平切分。
水平切分
前边说了垂直切分还是会存在单库、表数据量过大的问题,当我们的应用已经无法在细粒度的垂直切分时, 依旧存在单库读写、存储性能瓶颈,这时就要配合水平切分一起了,水平切分能大幅提升数据库性能。
1、水平分库
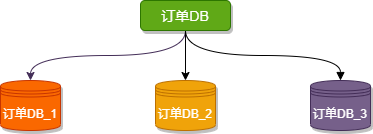
水平分库是把同一个表按一定规则拆分到不同的数据库中,每个库可以位于不同的服务器上,以此实现水平扩展,是一种常见的提升数据库性能的方式。
这种方案往往能解决单库存储量及性能瓶颈问题,但由于同一个表被分配在不同的数据库中,数据的访问需要额外的路由工作,因此系统的复杂度也被提升了。
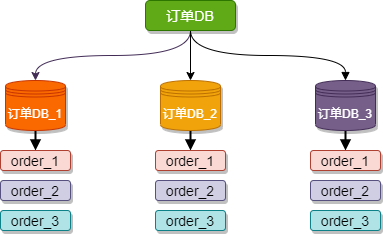
例如下图,订单DB_1、订单DB_1、订单DB_3 三个数据库内有完全相同的表 order,我们在访问某一笔订单时可以通过对订单的订单编号取模的方式 订单编号 mod 3 (数据库实例数) ,指定该订单应该在哪个数据库中操作。
2、水平分表
水平分表是在同一个数据库内,把一张大数据量的表按一定规则,切分成多个结构完全相同表,而每个表只存原表的一部分数据。
例如:一张 order 订单表有 900万数据,经过水平拆分出来三个表,order_1、order_2、order_3,每张表存有数据 300万,以此类推。
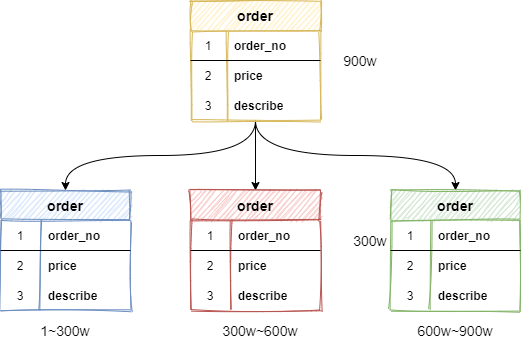
水平分表尽管拆分了表,但子表都还是在同一个数据库实例中,只是解决了单一表数据量过大的问题,并没有将拆分后的表分散到不同的机器上,还在竞争同一个物理机的CPU、内存、网络IO等。要想进一步提升性能,就需要将拆分后的表分散到不同的数据库中,达到分布式的效果。
水平切分的优点:
解决高并发时单库数据量过大的问题,提升系统稳定性和负载能力。 业务系统改造的工作量不是很大。
水平切分的缺点:
跨分片的事务一致性难以保证。 跨库的join关联查询性能较差。 扩容的难度和维护量较大,(拆分成几千张子表想想都恐怖)。
一定规则是什么
我们上边提到过很多次 一定规则 ,这个规则其实是一种路由算法,就是决定一条数据具体应该存在哪个数据库的哪张表里。
常见的有 取模算法 和 范围限定算法
1、取模算法
按字段取模(对hash结果取余数 (hash() mod N),N为数据库实例数或子表数量)是最为常见的一种切分方式。
还拿 order 订单表举例,先对数据库从 0 到 N-1进行编号,对 order 订单表中 work_no 订单编号字段进行取模,得到余数 i,i=0存第一个库,i=1存第二个库,i=2存第三个库....以此类推。
这样同一笔订单的数据都会存在同一个库、表里,查询时用相同的规则,用 work_no 订单编号作为查询条件,就能快速的定位到数据。
优点:
数据分片相对比较均匀,不易出现请求都打到一个库上的情况。
缺点:
这种算法存在一些问题,当某一台机器宕机,本应该落在该数据库的请求就无法得到正确的处理,这时宕掉的实例会被踢出集群,此时算法变成hash(userId) mod N-1,用户信息可能就不再在同一个库中了。
2、范围限定算法
按照 时间区间 或 ID区间 来切分,比如:我们切分的是用户表,可以定义每个库的 User 表里只存10000条数据,第一个库只存 userId 从1 ~ 9999的数据,第二个库存 userId 为10000 ~ 20000,第三个库存 userId 为 20001~ 30000......以此类推,按时间范围也是同理。
优点:
单表数据量是可控的 水平扩展简单只需增加节点即可,无需对其他分片的数据进行迁移 能快速定位要查询的数据在哪个库
缺点:
由于连续分片可能存在数据热点,比如按时间字段分片,可能某一段时间内订单骤增,可能会被频繁的读写,而有些分片存储的历史数据,则很少被查询。
分库分表的难点
1、分布式事务
由于表分布在不同库中,不可避免会带来跨库事务问题。一般可使用 "三阶段提交 "和 "两阶段提交" 处理,但是这种方式性能较差,代码开发量也比较大。通常做法是做到最终一致性的方案,如果不苛求系统的实时一致性,只要在允许的时间段内达到最终一致性即可,采用事务补偿的方式。
这里我应用阿里的分布式事务框架Seata 来做分布式事务的管理,后边会结合实际案例。
2、分页、排序、跨库联合查询
分页、排序、联合查询是开发中使用频率非常高的功能,但在分库分表后,这些看似普通的操作却是让人非常头疼的问题。将分散在不同库中表的数据查询出来,再将所有结果进行汇总整理后提供给用户。
3、分布式主键
分库分表后数据库的自增主键意义就不大了,因为我们不能依靠单个数据库实例上的自增主键来实现不同数据库之间的全局唯一主键,此时一个能够生成全局唯一ID的系统是非常必要的,那么这个全局唯一ID就叫 分布式ID。
4、读写分离
不难发现大部分主流的关系型数据库都提供了主从架构的高可用方案,而我们需要实现 读写分离 + 分库分表,读库与写库都要做分库分表处理,后边会有具体实战案例。
5、数据脱敏
数据脱敏,是指对某些敏感信息通过脱敏规则进行数据转换,从而实现敏感隐私数据的可靠保护,如身份证号、手机号、卡号、账号密码等个人信息,一般这些都需要进行做脱敏处理。
分库分表工具
我还是那句话,尽量不要自己造轮子,因为自己造的轮子可能不那么圆,业界已经有了很多比较成熟的分库分表中间件,我们根据自身的业务需求挑选,将更多的精力放在业务实现上。
sharding-jdbc(当当)TSharding(蘑菇街)Atlas(奇虎360)Cobar(阿里巴巴)MyCAT(基于Cobar)Oceanus(58同城)Vitess(谷歌)
为什么选 Sharding-JDBC
sharding-jdbc 是一款轻量级 Java 框架,以 jar 包形式提供服务,是属于客户端产品不需要额外部署,它相当于是个增强版的 JDBC 驱动;相比之下像 Mycat 这类需要单独的部署服务的服务端产品,就稍显复杂了。况且我想把更多精力放在实现业务,不想做额外的运维工作。
sharding-jdbc的兼容性也非常强大,适用于任何基于JDBC的ORM框架,如:JPA,Hibernate,Mybatis,Spring JDBC Template或直接使用的JDBC。完美兼容任何第三方的数据库连接池,如: DBCP,C3P0,BoneCP,Druid,HikariCP等,几乎对所有关系型数据库都支持。
不难发现确实是比较强大的一款工具,而且它对项目的侵入性很小,几乎不用做任何代码层的修改,也无需修改 SQL 语句,只需配置待分库分表的数据表即可。
Sharding-JDBC 简介
Sharding-JDBC 最早是当当网内部使用的一款分库分表框架,到2017年的时候才开始对外开源,这几年在大量社区贡献者的不断迭代下,功能也逐渐完善,现已更名为 ShardingSphere,2020年4⽉16⽇正式成为 Apache 软件基⾦会的顶级项⽬。
随着版本的不断更迭 ShardingSphere 的核心功能也变得多元化起来。从最开始 Sharding-JDBC 1.0 版本只有数据分片,到 Sharding-JDBC 2.0 版本开始支持数据库治理(注册中心、配置中心等等),再到 Sharding-JDBC 3.0版本又加分布式事务 (支持 Atomikos、Narayana、Bitronix、Seata),如今已经迭代到了 Sharding-JDBC 4.0 版本。
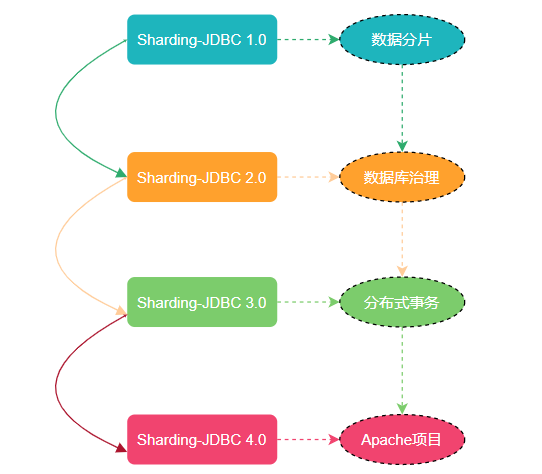
现在的 ShardingSphere 不单单是指某个框架而是一个生态圈,这个生态圈 Sharding-JDBC、Sharding-Proxy 和 Sharding-Sidecar 这三款开源的分布式数据库中间件解决方案所构成。
ShardingSphere 的前身就是 Sharding-JDBC,所以它是整个框架中最为经典、成熟的组件,我们先从 Sharding-JDBC 框架入手学习分库分表。
Sharding-JDBC核心概念
在开始 Sharding-JDBC分库分表具体实战之前,我们有必要先了解分库分表的一些核心概念。
分片
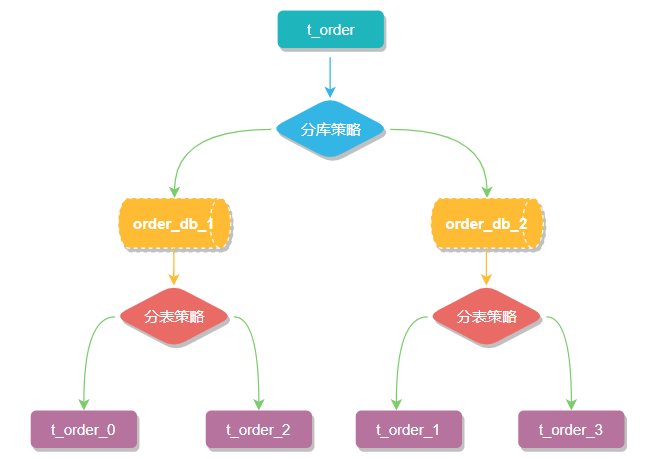
一般我们在提到分库分表的时候,大多是以水平切分模式(水平分库、分表)为基础来说的,数据分片将原本一张数据量较大的表 t_order 拆分生成数个表结构完全一致的小数据量表 t_order_0、t_order_1、···、t_order_n,每张表只存储原大表中的一部分数据,当执行一条SQL时会通过 分库策略、分片策略 将数据分散到不同的数据库、表内。
数据节点
数据节点是分库分表中一个不可再分的最小数据单元(表),它由数据源名称和数据表组成,例如上图中 order_db_1.t_order_0、order_db_2.t_order_1 就表示一个数据节点。
逻辑表
逻辑表是指一组具有相同逻辑和数据结构表的总称。比如我们将订单表t_order 拆分成 t_order_0 ··· t_order_9 等 10张表。此时我们会发现分库分表以后数据库中已不在有 t_order 这张表,取而代之的是 t_order_n,但我们在代码中写 SQL 依然按 t_order 来写。此时 t_order 就是这些拆分表的逻辑表。
真实表
真实表也就是上边提到的 t_order_n 数据库中真实存在的物理表。
分片键
用于分片的数据库字段。我们将 t_order 表分片以后,当执行一条SQL时,通过对字段 order_id 取模的方式来决定,这条数据该在哪个数据库中的哪个表中执行,此时 order_id 字段就是 t_order 表的分片健。
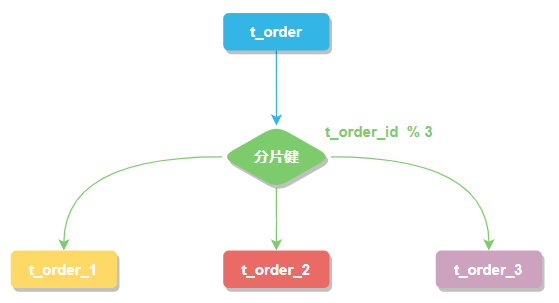
这样以来同一个订单的相关数据就会存在同一个数据库表中,大幅提升数据检索的性能,不仅如此 sharding-jdbc 还支持根据多个字段作为分片健进行分片。
分片算法
上边我们提到可以用分片健取模的规则分片,但这只是比较简单的一种,在实际开发中我们还希望用 >=、<=、>、<、BETWEEN 和 IN 等条件作为分片规则,自定义分片逻辑,这时就需要用到分片策略与分片算法。
从执行 SQL 的角度来看,分库分表可以看作是一种路由机制,把 SQL 语句路由到我们期望的数据库或数据表中并获取数据,分片算法可以理解成一种路由规则。
咱们先捋一下它们之间的关系,分片策略只是抽象出的概念,它是由分片算法和分片健组合而成,分片算法做具体的数据分片逻辑。
分库、分表的分片策略配置是相对独立的,可以各自使用不同的策略与算法,每种策略中可以是多个分片算法的组合,每个分片算法可以对多个分片健做逻辑判断。
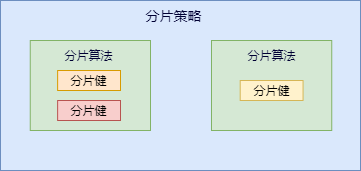
注意:sharding-jdbc 并没有直接提供分片算法的实现,需要开发者根据业务自行实现。
sharding-jdbc 提供了4种分片算法:
1、精确分片算法
精确分片算法(PreciseShardingAlgorithm)用于单个字段作为分片键,SQL中有 = 与 IN 等条件的分片,需要在标准分片策略(StandardShardingStrategy )下使用。
2、范围分片算法
范围分片算法(RangeShardingAlgorithm)用于单个字段作为分片键,SQL中有 BETWEEN AND、>、<、>=、<= 等条件的分片,需要在标准分片策略(StandardShardingStrategy )下使用。
3、复合分片算法
复合分片算法(ComplexKeysShardingAlgorithm)用于多个字段作为分片键的分片操作,同时获取到多个分片健的值,根据多个字段处理业务逻辑。需要在复合分片策略(ComplexShardingStrategy )下使用。
4、Hint分片算法
Hint分片算法(HintShardingAlgorithm)稍有不同,上边的算法中我们都是解析SQL 语句提取分片键,并设置分片策略进行分片。但有些时候我们并没有使用任何的分片键和分片策略,可还想将 SQL 路由到目标数据库和表,就需要通过手动干预指定SQL的目标数据库和表信息,这也叫强制路由。
分片策略
上边讲分片算法的时候已经说过,分片策略是一种抽象的概念,实际分片操作的是由分片算法和分片健来完成的。
1、标准分片策略
标准分片策略适用于单分片键,此策略支持 PreciseShardingAlgorithm 和 RangeShardingAlgorithm 两个分片算法。
其中 PreciseShardingAlgorithm 是必选的,用于处理 = 和 IN 的分片。RangeShardingAlgorithm 是可选的,用于处理BETWEEN AND, >, <,>=,<= 条件分片,如果不配置RangeShardingAlgorithm,SQL中的条件等将按照全库路由处理。
2、复合分片策略
复合分片策略,同样支持对 SQL语句中的 =,>, <, >=, <=,IN和 BETWEEN AND 的分片操作。不同的是它支持多分片键,具体分配片细节完全由应用开发者实现。
3、行表达式分片策略
行表达式分片策略,支持对 SQL语句中的 = 和 IN 的分片操作,但只支持单分片键。这种策略通常用于简单的分片,不需要自定义分片算法,可以直接在配置文件中接着写规则。
t_order_$->{t_order_id % 4} 代表 t_order 对其字段 t_order_id取模,拆分成4张表,而表名分别是t_order_0 到 t_order_3。
4、Hint分片策略
Hint分片策略,对应上边的Hint分片算法,通过指定分片健而非从 SQL中提取分片健的方式进行分片的策略。
分布式主键
数据分⽚后,不同数据节点⽣成全局唯⼀主键是⾮常棘⼿的问题,同⼀个逻辑表(t_order)内的不同真实表(t_order_n)之间的⾃增键由于⽆法互相感知而产⽣重复主键。
尽管可通过设置⾃增主键 初始值 和 步⻓ 的⽅式避免ID碰撞,但这样会使维护成本加大,乏完整性和可扩展性。如果后去需要增加分片表的数量,要逐一修改分片表的步长,运维成本非常高,所以不建议这种方式。
实现分布式主键⽣成器的方式很多,可以参考我之前写的《9种分布式ID生成方式》。
为了让上手更加简单,ApacheShardingSphere 内置了UUID、SNOWFLAKE 两种分布式主键⽣成器,默认使⽤雪花算法(snowflake)⽣成64bit的⻓整型数据。不仅如此它还抽离出分布式主键⽣成器的接口,⽅便我们实现⾃定义的⾃增主键⽣成算法。
广播表
广播表:存在于所有的分片数据源中的表,表结构和表中的数据在每个数据库中均完全一致。一般是为字典表或者配置表 t_config,某个表一旦被配置为广播表,只要修改某个数据库的广播表,所有数据源中广播表的数据都会跟着同步。
绑定表
绑定表:那些分片规则一致的主表和子表。比如:t_order 订单表和 t_order_item 订单服务项目表,都是按 order_id 字段分片,因此两张表互为绑定表关系。
那绑定表存在的意义是啥呢?
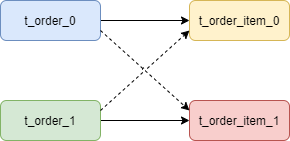
通常在我们的业务中都会使用 t_order 和 t_order_item 等表进行多表联合查询,但由于分库分表以后这些表被拆分成N多个子表。如果不配置绑定表关系,会出现笛卡尔积关联查询,将产生如下四条SQL。
SELECT * FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id
SELECT * FROM t_order_0 o JOIN t_order_item_1 i ON o.order_id=i.order_id
SELECT * FROM t_order_1 o JOIN t_order_item_0 i ON o.order_id=i.order_id
SELECT * FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id
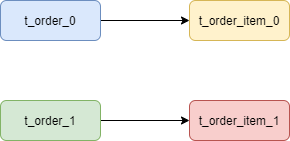
而配置绑定表关系后再进行关联查询时,只要对应表分片规则一致产生的数据就会落到同一个库中,那么只需 t_order_0 和 t_order_item_0 表关联即可。
SELECT * FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id
SELECT * FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id
注意:在关联查询时
t_order它作为整个联合查询的主表。所有相关的路由计算都只使用主表的策略,t_order_item表的分片相关的计算也会使用t_order的条件,所以要保证绑定表之间的分片键要完全相同。
Sharding-JDBC和JDBC的猫腻
从名字上不难看出,Sharding-JDBC 和 JDBC有很大关系,我们知道 JDBC 是一种 Java 语言访问关系型数据库的规范,其设计初衷就是要提供一套用于各种数据库的统一标准,不同厂家共同遵守这套标准,并提供各自的实现方案供应用程序调用。
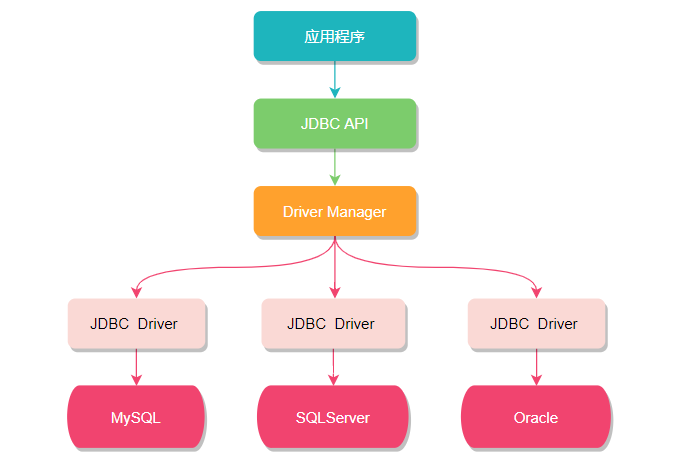
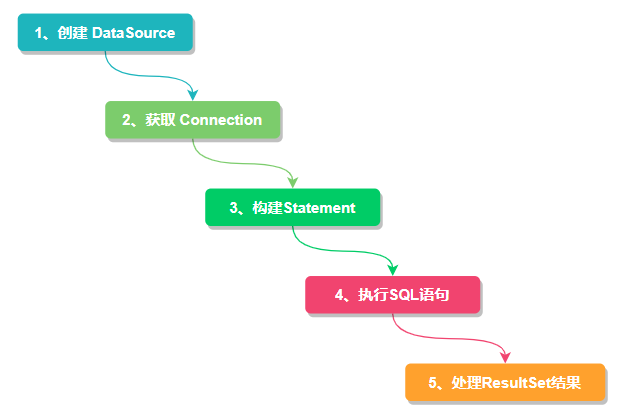
但其实对于开发人员而言,我们只关心如何调用 JDBC API 来访问数据库,只要正确使用 DataSource、Connection、Statement 、ResultSet 等 API 接口,直接操作数据库即可。所以如果想在 JDBC 层面实现数据分片就必须对现有的 API 进行功能拓展,而 Sharding-JDBC 正是基于这种思想,重写了 JDBC 规范并完全兼容了 JDBC 规范。
对原有的 DataSource、Connection 等接口扩展成 ShardingDataSource、ShardingConnection,而对外暴露的分片操作接口与 JDBC 规范中所提供的接口完全一致,只要你熟悉 JDBC 就可以轻松应用 Sharding-JDBC 来实现分库分表。
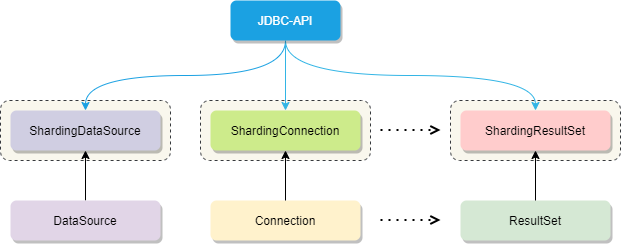
因此它适用于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate,Mybatis,Spring JDBC Template 或直接使用的 JDBC。完美兼容任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP,Druid, HikariCP 等,几乎对主流关系型数据库都支持。
那 Sharding-JDBC 又是如何拓展这些接口的呢?想知道答案我们就的从源码入手了,下边我们以 JDBC API 中的 DataSource 为例看看它是如何被重写扩展的。
数据源 DataSource 接口的核心作用就是获取数据库连接对象 Connection,我们看其内部提供了两个获取数据库连接的方法 ,并且继承了 CommonDataSource 和 Wrapper 两个接口。
public interface DataSource extends CommonDataSource, Wrapper {
/**
* Attempts to establish a connection with the data source that
* this {@code DataSource} object represents.
* @return a connection to the data source
*/
Connection getConnection() throws SQLException;
/**
* Attempts to establish a connection with the data source that
* this {@code DataSource} object represents.
* @param username the database user on whose behalf the connection is
* being made
* @param password the user's password
*/
Connection getConnection(String username, String password)
throws SQLException;
}
其中 CommonDataSource 是定义数据源的根接口这很好理解,而 Wrapper 接口则是拓展 JDBC 分片功能的关键。
由于数据库厂商的不同,他们可能会各自提供一些超越标准 JDBC API 的扩展功能,但这些功能非 JDBC 标准并不能直接使用,而 Wrapper 接口的作用就是把一个由第三方供应商提供的、非 JDBC 标准的接口包装成标准接口,也就是适配器模式。
既然讲到了适配器模式就多啰嗦几句,也方便后边的理解。
适配器模式个种比较常用的设计模式,它的作用是将某个类的接口转换成客户端期望的另一个接口,使原本因接口不匹配(或者不兼容)而无法在一起工作的两个类能够在一起工作。
比如用耳机听音乐,我有个圆头的耳机,可手机插孔却是扁口的,如果我想要使用耳机听音乐就必须借助一个转接头才可以,这个转接头就起到了适配作用。举个栗子:假如我们 Target 接口中有 hello() 和 word() 两个方法。
public interface Target {
void hello();
void world();
}
可由于接口版本迭代Target 接口的 word() 方法可能会被废弃掉或不被支持,Adaptee 类的 greet()方法将代替hello() 方法。
public class Adaptee {
public void greet(){
}
public void world(){
}
}
但此时旧版本仍然有大量 word() 方法被使用中,解决此事最好的办法就是创建一个适配器Adapter,这样就适配了 Target 类,解决了接口升级带来的兼容性问题。
public class Adapter extends Adaptee implements Target {
@Override
public void world() {
}
@Override
public void hello() {
super.greet();
}
@Override
public void greet() {
}
}
而 Sharding-JDBC 提供的正是非 JDBC 标准的接口,所以它也提供了类似的实现方案,也使用到了 Wrapper 接口做数据分片功能的适配。除了 DataSource 之外,Connection、Statement、ResultSet 等核心对象也都继承了这个接口。
下面我们通过 ShardingDataSource 类源码简单看下实现过程,下图是继承关系流程图。
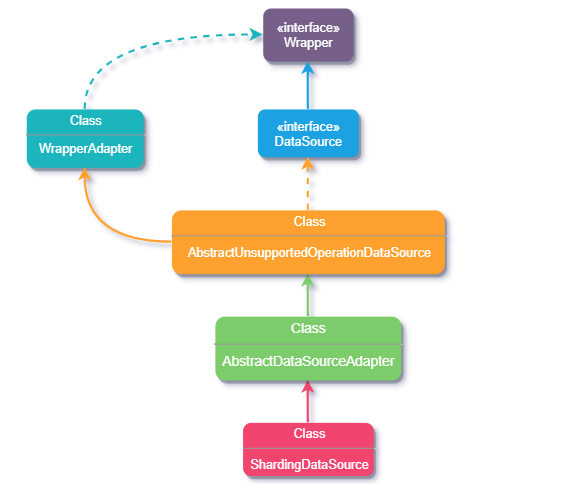
ShardingDataSource 类它在原 DataSource 基础上做了功能拓展,初始化时注册了分片SQL路由包装器、SQL重写上下文和结果集处理引擎,还对数据源类型做了校验,因为它要同时支持多个不同类型的数据源。到这好像也没看出如何适配,那接着向上看 ShardingDataSource 的继承类 AbstractDataSourceAdapter 。
@Getter
public class ShardingDataSource extends AbstractDataSourceAdapter {
private final ShardingRuntimeContext runtimeContext;
/**
* 注册路由、SQl重写上下文、结果集处理引擎
*/
static {
NewInstanceServiceLoader.register(RouteDecorator.class);
NewInstanceServiceLoader.register(SQLRewriteContextDecorator.class);
NewInstanceServiceLoader.register(ResultProcessEngine.class);
}
/**
* 初始化时校验数据源类型 并根据数据源 map、分片规则、数据库类型得到一个分片上下文,用来获取数据库连接
*/
public ShardingDataSource(final Map dataSourceMap, final ShardingRule shardingRule, final Properties props) throws SQLException {
super(dataSourceMap);
checkDataSourceType(dataSourceMap);
runtimeContext = new ShardingRuntimeContext(dataSourceMap, shardingRule, props, getDatabaseType());
}
private void checkDataSourceType(final Map dataSourceMap) {
for (DataSource each : dataSourceMap.values()) {
Preconditions.checkArgument(!(each instanceof MasterSlaveDataSource), "Initialized data sources can not be master-slave data sources.");
}
}
/**
* 数据库连接
*/
@Override
public final ShardingConnection getConnection() {
return new ShardingConnection(getDataSourceMap(), runtimeContext, TransactionTypeHolder.get());
}
}
AbstractDataSourceAdapter 抽象类内部主要获取不同类型的数据源对应的数据库连接对象,实现 AutoCloseable 接口是为在使用完资源后可以自动将这些资源关闭(调用 close方法),那再看看继承类 AbstractUnsupportedOperationDataSource 。
@Getter
public abstract class AbstractDataSourceAdapter extends AbstractUnsupportedOperationDataSource implements AutoCloseable {
private final Map dataSourceMap;
private final DatabaseType databaseType;
public AbstractDataSourceAdapter(final Map dataSourceMap) throws SQLException {
this.dataSourceMap = dataSourceMap;
databaseType = createDatabaseType();
}
public AbstractDataSourceAdapter(final DataSource dataSource) throws SQLException {
dataSourceMap = new HashMap<>(1, 1);
dataSourceMap.put("unique", dataSource);
databaseType = createDatabaseType();
}
private DatabaseType createDatabaseType() throws SQLException {
DatabaseType result = null;
for (DataSource each : dataSourceMap.values()) {
DatabaseType databaseType = createDatabaseType(each);
Preconditions.checkState(null == result || result == databaseType, String.format("Database type inconsistent with '%s' and '%s'", result, databaseType));
result = databaseType;
}
return result;
}
/**
* 不同数据源类型获取数据库连接
*/
private DatabaseType createDatabaseType(final DataSource dataSource) throws SQLException {
if (dataSource instanceof AbstractDataSourceAdapter) {
return ((AbstractDataSourceAdapter) dataSource).databaseType;
}
try (Connection connection = dataSource.getConnection()) {
return DatabaseTypes.getDatabaseTypeByURL(connection.getMetaData().getURL());
}
}
@Override
public final Connection getConnection(final String username, final String password) throws SQLException {
return getConnection();
}
@Override
public final void close() throws Exception {
close(dataSourceMap.keySet());
}
}
AbstractUnsupportedOperationDataSource 实现DataSource 接口并继承了 WrapperAdapter 类,它内部并没有什么具体方法只起到桥接的作用,但看着是不是和我们前边讲适配器模式的例子方式有点相似。
public abstract class AbstractUnsupportedOperationDataSource extends WrapperAdapter implements DataSource {
@Override
public final int getLoginTimeout() throws SQLException {
throw new SQLFeatureNotSupportedException("unsupported getLoginTimeout()");
}
@Override
public final void setLoginTimeout(final int seconds) throws SQLException {
throw new SQLFeatureNotSupportedException("unsupported setLoginTimeout(int seconds)");
}
}
WrapperAdapter 是一个包装器的适配类,实现了 JDBC 中的 Wrapper 接口,其中有两个核心方法 recordMethodInvocation 用于添加需要执行的方法和参数,而 replayMethodsInvocation 则将添加的这些方法和参数通过反射执行。仔细看不难发现两个方法中都用到了 JdbcMethodInvocation类。
public abstract class WrapperAdapter implements Wrapper {
private final Collection jdbcMethodInvocations = new ArrayList<>();
/**
* 添加要执行的方法
*/
@SneakyThrows
public final void recordMethodInvocation(final Class targetClass, final String methodName, final Class[] argumentTypes, final Object[] arguments) {
jdbcMethodInvocations.add(new JdbcMethodInvocation(targetClass.getMethod(methodName, argumentTypes), arguments));
}
/**
* 通过反射执行 上边添加的方法
*/
public final void replayMethodsInvocation(final Object target) {
for (JdbcMethodInvocation each : jdbcMethodInvocations) {
each.invoke(target);
}
}
}
JdbcMethodInvocation 类主要应用反射通过传入的 method 方法和 arguments 参数执行对应的方法,这样就可以通过 JDBC API 调用非 JDBC 方法了。
@RequiredArgsConstructor
public class JdbcMethodInvocation {
@Getter
private final Method method;
@Getter
private final Object[] arguments;
/**
* Invoke JDBC method.
*
* @param target target object
*/
@SneakyThrows
public void invoke(final Object target) {
method.invoke(target, arguments);
}
}
那 Sharding-JDBC 拓展 JDBC API 接口后,在新增的分片功能里又做了哪些事情呢?
一张表经过分库分表后被拆分成多个子表,并分散到不同的数据库中,在不修改原业务 SQL 的前提下,Sharding-JDBC 就必须对 SQL进行一些改造才能正常执行。
大致的执行流程:SQL 解析 -> 执⾏器优化 -> SQL 路由 -> SQL 改写 -> SQL 执⾏ -> 结果归并 六步组成,一起瞅瞅每个步骤做了点什么。
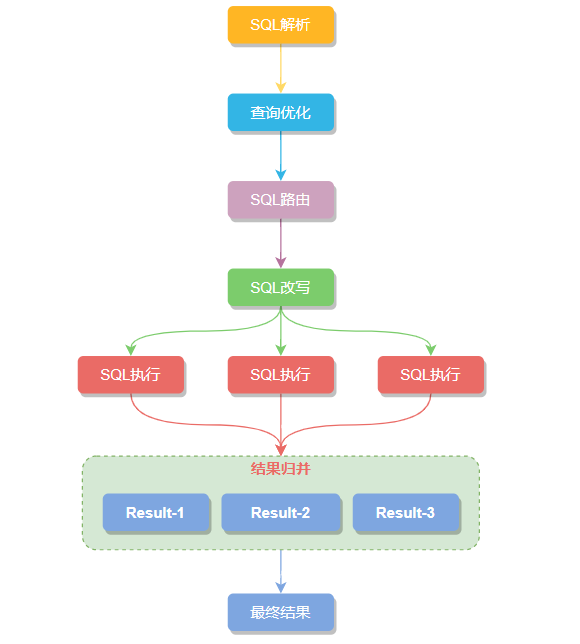
SQL 解析
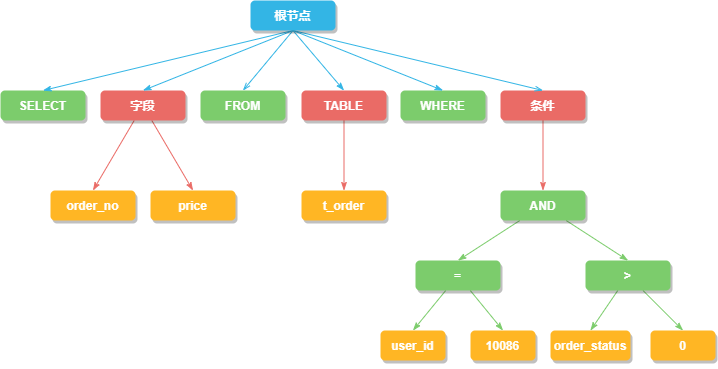
SQL解析过程分为词法解析和语法解析两步,比如下边这条查询用户订单的SQL,先用词法解析将SQL拆解成不可再分的原子单元。在根据不同数据库方言所提供的字典,将这些单元归类为关键字,表达式,变量或者操作符等类型。
SELECT order_no,price FROM t_order_ where user_id = 10086 and order_status > 0
接着语法解析会将拆分后的SQL转换为抽象语法树,通过对抽象语法树遍历,提炼出分片所需的上下文,上下文包含查询字段信息(Field)、表信息(Table)、查询条件(Condition)、排序信息(Order By)、分组信息(Group By)以及分页信息(Limit)等,并标记出 SQL中有可能需要改写的位置。
执⾏器优化
执⾏器优化对SQL分片条件进行优化,处理像关键字 OR这种影响性能的坏味道。
SQL 路由
SQL 路由通过解析分片上下文,匹配到用户配置的分片策略,并生成路由路径。简单点理解就是可以根据我们配置的分片策略计算出 SQL该在哪个库的哪个表中执行,而SQL路由又根据有无分片健区分出 分片路由 和 广播路由。
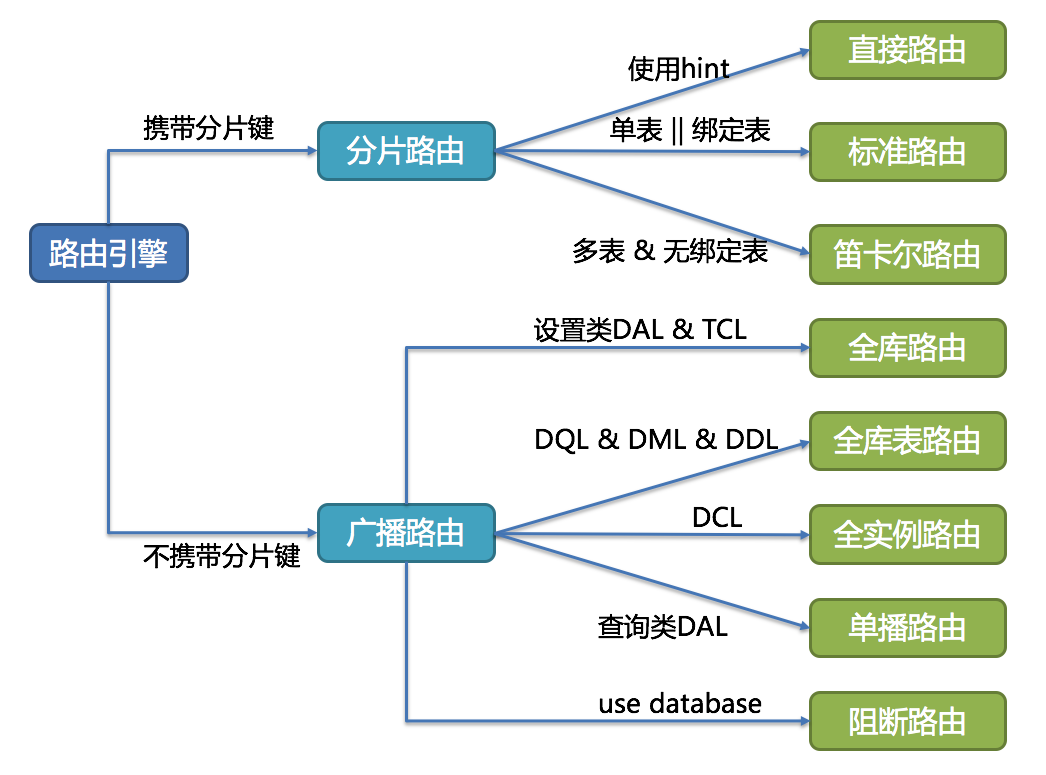
有分⽚键的路由叫分片路由,细分为直接路由、标准路由和笛卡尔积路由这3种类型。
标准路由
标准路由是最推荐也是最为常⽤的分⽚⽅式,它的适⽤范围是不包含关联查询或仅包含绑定表之间关联查询的SQL。
当 SQL分片健的运算符为 = 时,路由结果将落⼊单库(表),当分⽚运算符是BETWEEN 或IN 等范围时,路由结果则不⼀定落⼊唯⼀的库(表),因此⼀条逻辑SQL最终可能被拆分为多条⽤于执⾏的真实SQL。
SELECT * FROM t_order where t_order_id in (1,2)
SQL路由处理后
SELECT * FROM t_order_0 where t_order_id in (1,2)
SELECT * FROM t_order_1 where t_order_id in (1,2)
直接路由
直接路由是通过使用 HintAPI 直接将 SQL路由到指定⾄库表的一种分⽚方式,而且直接路由可以⽤于分⽚键不在SQL中的场景,还可以执⾏包括⼦查询、⾃定义函数等复杂情况的任意SQL。
比如根据 t_order_id 字段为条件查询订单,此时希望在不修改SQL的前提下,加上 user_id作为分片条件就可以使用直接路由。
笛卡尔积路由
笛卡尔路由是由⾮绑定表之间的关联查询产生的,查询性能较低尽量避免走此路由模式。
无分⽚键的路由又叫做广播路由,可以划分为全库表路由、全库路由、 全实例路由、单播路由和阻断路由这 5种类型。
全库表路由
全库表路由针对的是数据库 DQL和 DML,以及 DDL等操作,当我们执行一条逻辑表 t_order SQL时,在所有分片库中对应的真实表 t_order_0 ··· t_order_n 内逐一执行。
全库路由
全库路由主要是对数据库层面的操作,比如数据库 SET 类型的数据库管理命令,以及 TCL 这样的事务控制语句。
对逻辑库设置 autocommit 属性后,所有对应的真实库中都执行该命令。
SET autocommit=0;
复制代码
全实例路由
全实例路由是针对数据库实例的 DCL 操作(设置或更改数据库用户或角色权限),比如:创建一个用户 order ,这个命令将在所有的真实库实例中执行,以此确保 order 用户可以正常访问每一个数据库实例。
CREATE USER order@127.0.0.1 identified BY '程序员内点事';
单播路由
单播路由用来获取某一真实表信息,比如获得表的描述信息:
DESCRIBE t_order;
t_order 的真实表是 t_order_0 ···· t_order_n,他们的描述结构相完全同,我们只需在任意的真实表执行一次就可以。
阻断路由
⽤来屏蔽SQL对数据库的操作,例如:
USE order_db;
这个命令不会在真实数据库中执⾏,因为 ShardingSphere 采⽤的是逻辑 Schema(数据库的组织和结构) ⽅式,所以无需将切换数据库的命令发送⾄真实数据库中。
SQL 改写
将基于逻辑表开发的SQL改写成可以在真实数据库中可以正确执行的语句。比如查询 t_order 订单表,我们实际开发中 SQL是按逻辑表 t_order 写的。
SELECT * FROM t_order
但分库分表以后真实数据库中 t_order 表就不存在了,而是被拆分成多个子表 t_order_n 分散在不同的数据库内,还按原SQL执行显然是行不通的,这时需要将分表配置中的逻辑表名称改写为路由之后所获取的真实表名称。
SELECT * FROM t_order_n
SQL执⾏
将路由和改写后的真实 SQL 安全且高效发送到底层数据源执行。但这个过程并不是简单的将 SQL 通过JDBC 直接发送至数据源执行,而是平衡数据源连接创建以及内存占用所产生的消耗,它会自动化的平衡资源控制与执行效率。
结果归并
将从各个数据节点获取的多数据结果集,合并成一个大的结果集并正确的返回至请求客户端,称为结果归并。而我们SQL中的排序、分组、分页和聚合等语法,均是在归并后的结果集上进行操作的。
Sharding-JDBC快速实践
下面我们结合 Springboot + mybatisplus 快速搭建一个分库分表案例。
1、准备工作
先做准备工作,创建两个数据库 ds-0、ds-1,两个库中分别建表 t_order_0、t_order_1、t_order_2 、t_order_item_0、t_order_item_1、t_order_item_2,t_config,方便后边验证广播表、绑定表的场景。
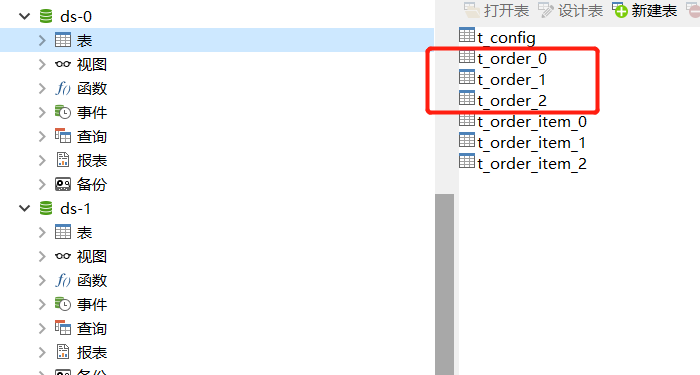
表结构如下:
t_order_0 订单表
CREATE TABLE `t_order_0` (
`order_id` bigint(200) NOT NULL,
`order_no` varchar(100) DEFAULT NULL,
`create_name` varchar(50) DEFAULT NULL,
`price` decimal(10,2) DEFAULT NULL,
PRIMARY KEY (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;
t_order_0 与 t_order_item_0 互为关联表
CREATE TABLE `t_order_item_0` (
`item_id` bigint(100) NOT NULL,
`order_no` varchar(200) NOT NULL,
`item_name` varchar(50) DEFAULT NULL,
`price` decimal(10,2) DEFAULT NULL,
PRIMARY KEY (`item_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;
广播表 t_config
CREATE TABLE `t_config` (
`id` bigint(30) NOT NULL,
`remark` varchar(50) CHARACTER SET utf8 DEFAULT NULL,
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
`last_modify_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
ShardingSphere 提供了4种分片配置方式:
Java 代码配置 Yaml 、properties 配置 Spring 命名空间配置 Spring Boot配置
为让代码看上去更简洁和直观,后边统一使用 properties 配置的方式,引入 shardingsphere 对应的 sharding-jdbc-spring-boot-starter 和 sharding-core-common 包,版本统一用的 4.0.0-RC1。
2、分片配置
<dependency>
<groupId>org.apache.shardingspheregroupId>
<artifactId>sharding-jdbc-spring-boot-starterartifactId>
<version>4.0.0-RC1version>
dependency>
<dependency>
<groupId>org.apache.shardingspheregroupId>
<artifactId>sharding-core-commonartifactId>
<version>4.0.0-RC1version>
dependency>
准备工作做完( mybatis 搭建就不赘述了),接下来我们逐一解读分片配置信息。
我们首先定义两个数据源 ds-0、ds-1,并分别加上数据源的基础信息。
# 定义两个全局数据源
spring.shardingsphere.datasource.names=ds-0,ds-1
# 配置数据源 ds-0
spring.shardingsphere.datasource.ds-0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds-0.driverClassName=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds-0.url=jdbc:mysql://127.0.0.1:3306/ds-0?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
spring.shardingsphere.datasource.ds-0.username=root
spring.shardingsphere.datasource.ds-0.password=root
# 配置数据源 ds-1
spring.shardingsphere.datasource.ds-1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds-1.driverClassName=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds-1.url=jdbc:mysql://127.0.0.1:3306/ds-1?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
spring.shardingsphere.datasource.ds-1.username=root
spring.shardingsphere.datasource.ds-1.password=root
配置完数据源接下来为表添加分库和分表策略,使用 sharding-jdbc 做分库分表需要我们为每一个表单独设置分片规则。
# 配置分片表 t_order
# 指定真实数据节点
spring.shardingsphere.sharding.tables.t_order.actual-data-nodes=ds-$->{0..1}.t_order_$->{0..2}
actual-data-nodes 属性指定分片的真实数据节点,$是一个占位符,{0..1}表示实际拆分的数据库表数量。
ds-$->{0..1}.t_order_$->{0..2} 表达式相当于 6个数据节点
ds-0.t_order_0 ds-0.t_order_1 ds-0.t_order_2 ds-1.t_order_0 ds-1.t_order_1 ds-1.t_order_2
### 分库策略
# 分库分片健
spring.shardingsphere.sharding.tables.t_order.database-strategy.inline.sharding-column=order_id
# 分库分片算法
spring.shardingsphere.sharding.tables.t_order.database-strategy.inline.algorithm-expression=ds-$->{order_id % 2}
为表设置分库策略,上边讲了 sharding-jdbc 它提供了四种分片策略,为快速搭建我们先以最简单的行内表达式分片策略来实现,在下一篇会介绍四种分片策略的详细用法和使用场景。
database-strategy.inline.sharding-column 属性中 database-strategy 为分库策略,inline 为具体的分片策略,sharding-column 代表分片健。
database-strategy.inline.algorithm-expression 是当前策略下具体的分片算法,ds-$->{order_id % 2} 表达式意思是 对 order_id字段进行取模分库,2 代表分片库的个数,不同的策略对应不同的算法,这里也可以是我们自定义的分片算法类。
# 分表策略
# 分表分片健
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.sharding-column=order_id
# 分表算法
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.algorithm-expression=t_order_$->{order_id % 3}
# 自增主键字段
spring.shardingsphere.sharding.tables.t_order.key-generator.column=order_id
# 自增主键ID 生成方案
spring.shardingsphere.sharding.tables.t_order.key-generator.type=SNOWFLAKE
分表策略 和 分库策略 的配置比较相似,不同的是分表可以通过 key-generator.column 和 key-generator.type 设置自增主键以及指定自增主键的生成方案,目前内置了SNOWFLAKE 和 UUID 两种方式,还能自定义的主键生成算法类,后续会详细的讲解。
# 绑定表关系
spring.shardingsphere.sharding.binding-tables= t_order,t_order_item
必须按相同分片健进行分片的表才能互为成绑定表,在联合查询时就能避免出现笛卡尔积查询。
# 配置广播表
spring.shardingsphere.sharding.broadcast-tables=t_config
广播表,开启 SQL解析日志,能清晰的看到 SQL分片解析的过程
# 是否开启 SQL解析日志
spring.shardingsphere.props.sql.show=true
3、验证分片
分片配置完以后我们无需在修改业务代码了,直接执行业务逻辑的增、删、改、查即可,接下来验证一下分片的效果。
我们同时向 t_order、t_order_item 表插入 5条订单记录,并不给定主键 order_id ,item_id 字段值。
public String insertOrder() {
for (int i = 0; i < 4; i++) {
TOrder order = new TOrder();
order.setOrderNo("A000" + i);
order.setCreateName("订单 " + i);
order.setPrice(new BigDecimal("" + i));
orderRepository.insert(order);
TOrderItem orderItem = new TOrderItem();
orderItem.setOrderId(order.getOrderId());
orderItem.setOrderNo("A000" + i);
orderItem.setItemName("服务项目" + i);
orderItem.setPrice(new BigDecimal("" + i));
orderItemRepository.insert(orderItem);
}
return "success";
}
看到订单记录被成功分散到了不同的库表中, order_id 字段也自动生成了主键ID,基础的分片功能就完成了。
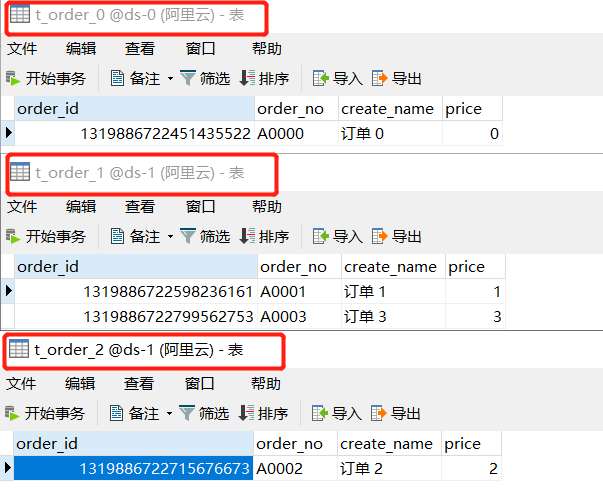
那向广播表 t_config 中插入一条数据会是什么效果呢?
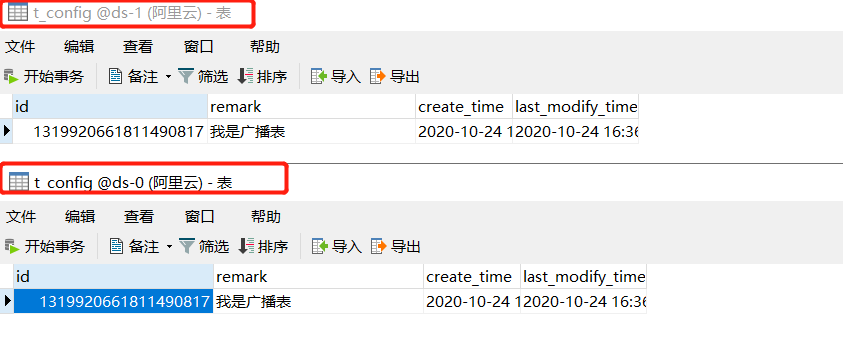
public String config() {
TConfig tConfig = new TConfig();
tConfig.setRemark("我是广播表");
tConfig.setCreateTime(new Date());
tConfig.setLastModifyTime(new Date());
configRepository.insert(tConfig);
return "success";
}
发现所有库中 t_config 表都执行了这条SQL,广播表和 MQ广播订阅的模式很相似,所有订阅的客户端都会收到同一条消息。
简单SQL操作验证没问通,接下来在试试复杂一点的联合查询,前边我们已经把 t_order 、t_order_item 表设为绑定表,直接联表查询执行一下。
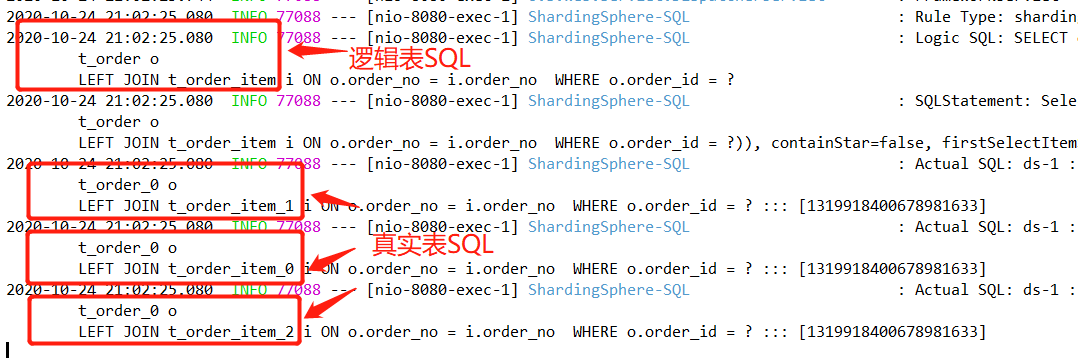
通过控制台日志发现,逻辑表SQL 经过解析以后,只对 t_order_0 和 t_order_item_0 表进行了关联产生一条SQL。

那如果不互为绑定表又会是什么情况呢?去掉 spring.shardingsphere.sharding.binding-tables试一下。
发现控制台解析出了 3条真实表SQL,而去掉 order_id 作为查询条件再次执行后,结果解析出了 9条SQL,进行了笛卡尔积查询。所以相比之下绑定表的优点就不言而喻了。
总结
这篇文章首先简单的回顾一下分库分表的基础知识。
然后对分库分表中间件 sharding-jdbc 的基础概念做了简单梳理,快速的搭建了一个分库分表案例,但这只是实践分库分表的第一步,下一篇我们会详细的介绍四种分片策略的具体用法和使用场景(必知必会),后边将陆续讲解自定义分布式主键、分布式数据库事务、分布式服务治理,数据脱敏等。
案例
GitHub地址:https://github.com/chengxy-nds/Springboot-Notebook/tree/master/springboot-sharding-jdbc
后记
最近写的一些干货,每篇都很用心,欢迎各位小伙伴阅读/点赞/分享:
我是Guide哥,Java后端开发,会一点前端知识,喜欢烹饪,自由的少年。一个三观比主角还正的技术人。我们下期再见!