
作为数据库核心成员,如何让淘宝不卡顿?
时间倒转穿越回2007年年底
一觉醒来,我还是照常去上班,走到西溪湿地附近,马路没有,高楼没有,有的是小山坡和金色的稻田。一番打听之后,才知道此时没有什么西溪园区。没办法,硬着头皮去滨江上班,一刷卡,才发现我并不是我,我现在的身份是淘宝数据库团队的核心成员。
此时全国上下在迎接着奥运的到来,一片祥和。淘宝网成交额突破400亿,日活用户达1000万。工程师们都非常兴奋,磨刀霍霍。但是也遇到了棘手的问题。
一 分析当前的现状
1.1 现有业务背景
淘宝网给中国市场提供了全新的购物形式,在互联网的大潮下,用户暴增,成交量暴增,公司持续飞速增长。
截止2007年,淘宝网成交额突破400亿,日活用户达1000万。
全天有1000万用户访问淘宝。而绝大多数用户都是在网上逛,什么也不买。
大量的用户在浏览商品,并不下单。这个人数和场景的比例有20:1。
说明:数据库模式事务,写操作会对表或者行加写锁,阻塞读操作。
业务数据集中在一张表里,如user表。一张表里数据破几千万。查询一条数据需要好几秒(单表数据量太大)。
说明:一张表数据提升,必然会导致检索变慢, 这是必然事实。不论如何加索引或者优化都无法解决的。
所有表集中在一个库里,所有库集中在一个机器里。数据库集中在一台机器上,动不动就说硬盘不够了(单机单库)。
说明:所有业务共用一份物理机器资源。机器存在瓶颈:磁盘和CPU不够用且后期拓展性不佳。
20:1读写比例场景。 单表单库数据量太大。 小型机与单机场景,抗不住当前规模。
如何满足当前每天1000万用户逛淘宝的需求,且用户体验好(最基本要求:响应快)。
如何满足未来有上亿用户的访问,甚至是同时访问,且用户体验好(最基本要求:响应快)。
提高数据库操作速度。 同时能应对未来规模变化。
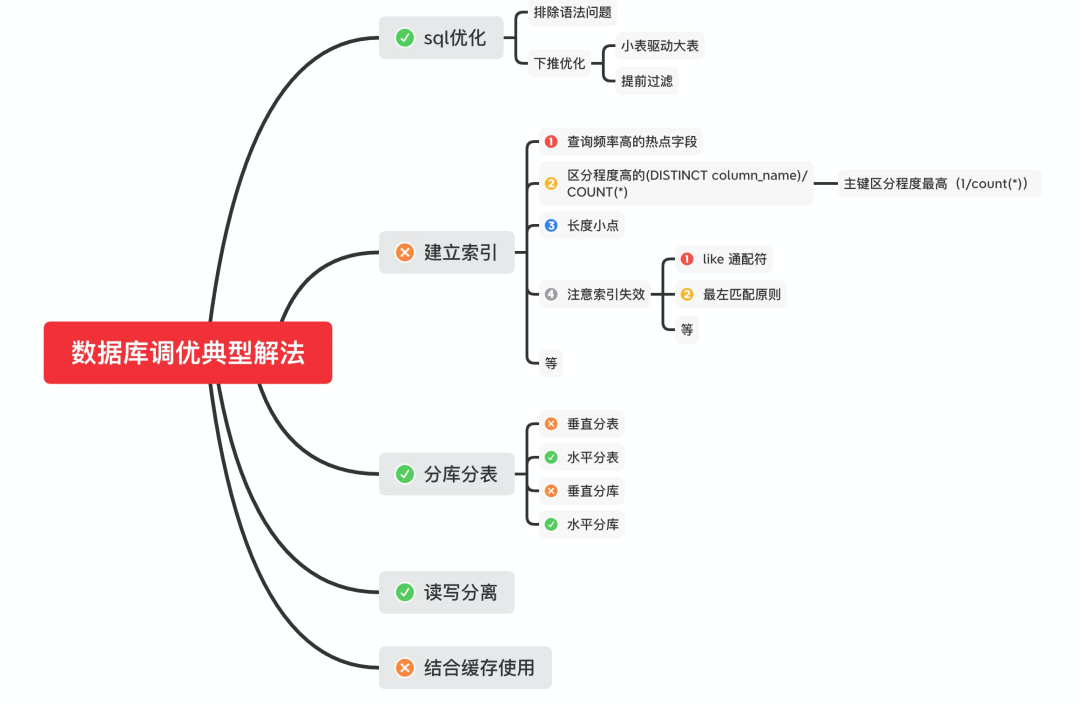
sql优化
排除语法问题,烂sql 下推优化
提前过滤数据 小表驱动大表等
建立索引
查询频率高的热点字段 区分度高的(DISTINCT column_name)/COUNT(*),以主键为榜样(1/COUNT(*)) 长度小 尽量能覆盖常用查询字段 注意索引失效的场景
分库分表
垂直分库分表 水平分库分表
读写分离 缓存的使用
必须支持动态扩容。 必须走分布式化路线,百分百不动摇。
我们要做通用型框架,不参与业务。
从软件设计原则出发,开闭原则:对扩展开放,对修改关闭。
索引,因为这个是设计阶段,强业务相关。与大前提冲突:我们不参与业务。
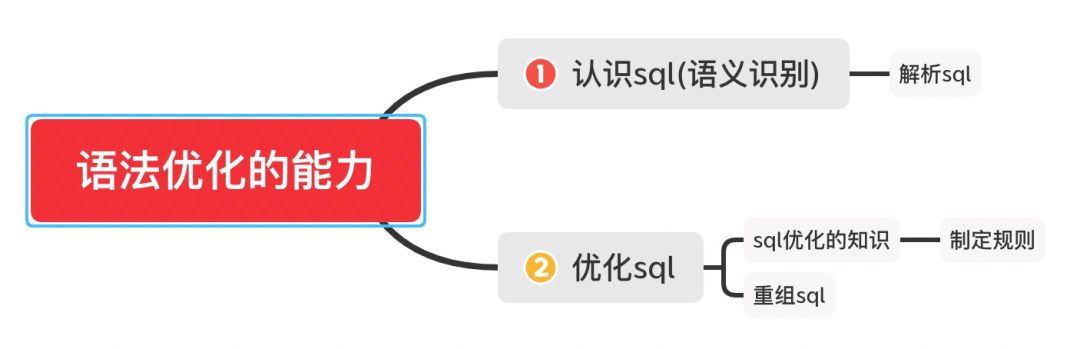
语法优化
排除sql问题 下推优化
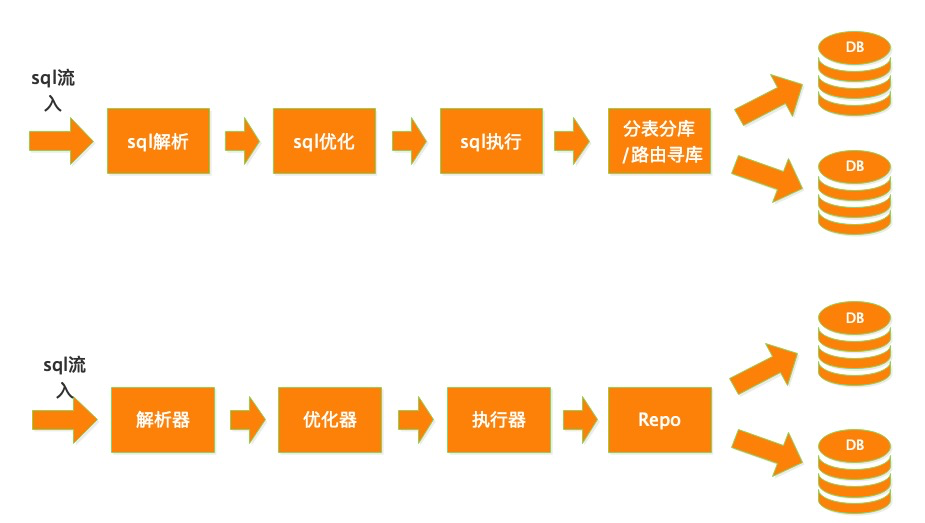
分表分库(自动水平分表,水平分库) 读写分离(读写分离/分布式化与动态扩容)
我们需要认识这个别人提交给我的sql。 我能拆解sql。 优化与重组这个sql。
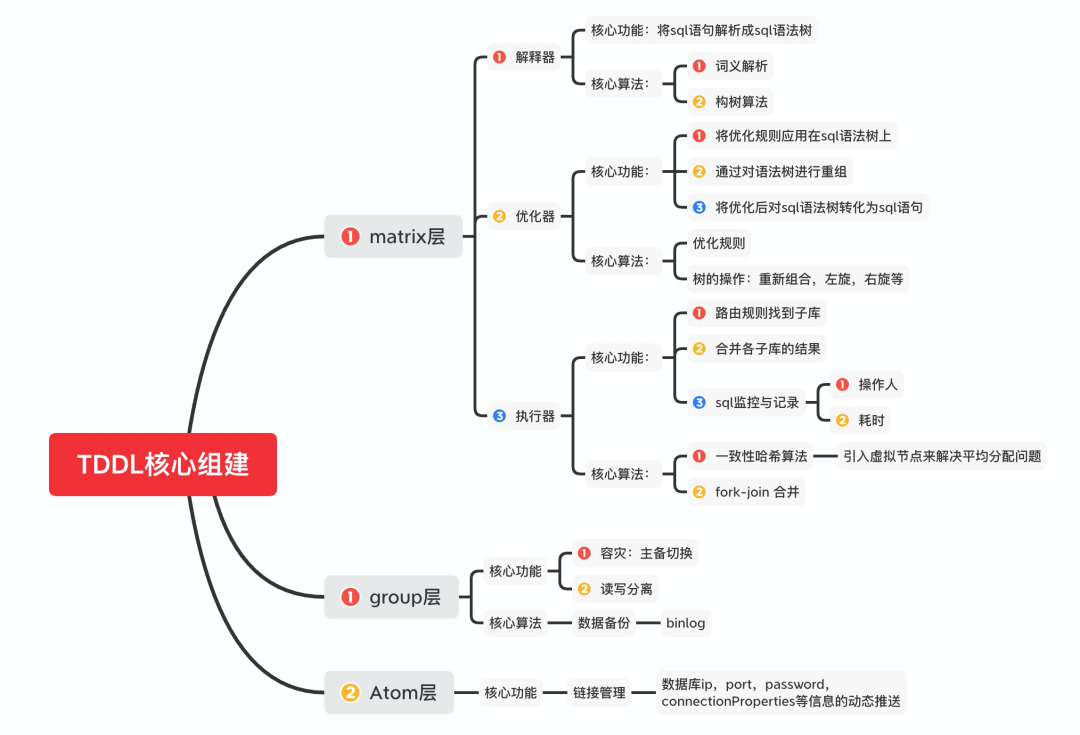
sql解析 sql规则制定 sql优化 sql重组
SELECT id, member_id FROM wp_image WHERE member_id = ‘123’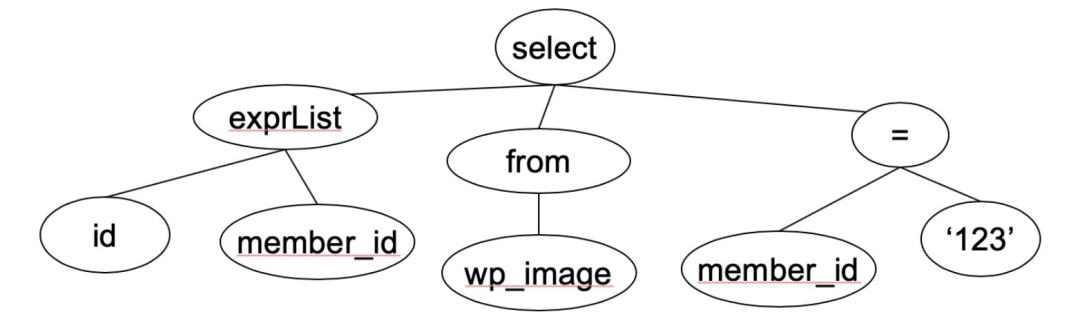
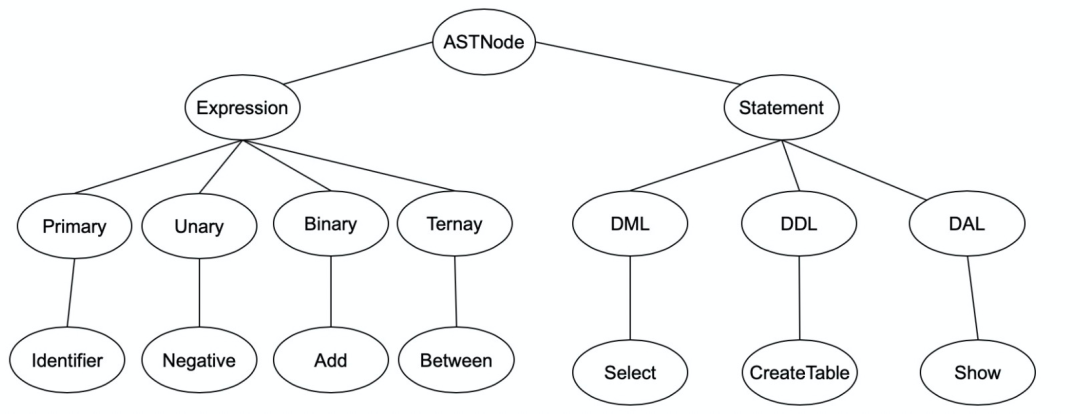
在sql解析成sql语法树后,使用sql优化规则(1. 语法优化 2. 下推优化), 通过对树进行左旋,右旋,删除子树来对语法树进行重构sql语法树。
将重构的语法树进行遍历得到优化后的sql。
函数提前计算
a. id = 1 + 1 => id = 2判断永真/永假式
1 = 1 and id = 1 => id = 10 = 1 and id = 1 => 空结果
合并范围
id > 1 or id < 5 => 永真式id > 1 and id = 3 => id = 3
类型处理
id = ‘1’ => id为数字类型,自动Long.valueof(1)create=‘2015-02-14 12:12:12’ => create为timestamp类型,解析为时间类型
Where条件下推
select from (A) o where o.id = 1=>select from (A.query(id = 1))
JOIN中非join列的条件下推
A join B on A.id = B.id where A.name = 1 and B.title = 2=>A.query(name = 1) join B.query(title = 2) on A.id = B.id
等值条件的推导
A join B on A.id = B.id where A.id = 1 => B.id = 1=>A join B.query(B.id=1) on A.id = B.id
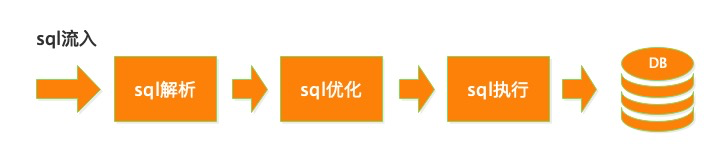
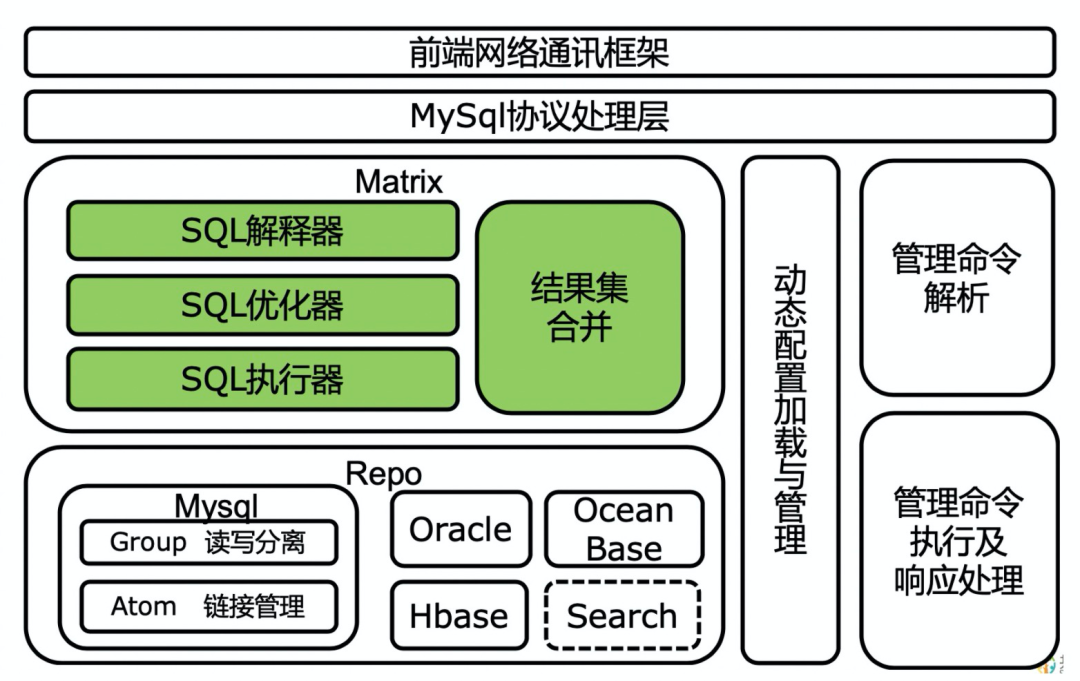
sql解析器
负责将sql语句化为sql语法树。
sql优化器
负责将sql语法树利用sql优化规则,重构sql语法树。
将sql语法树转化为sql语句。

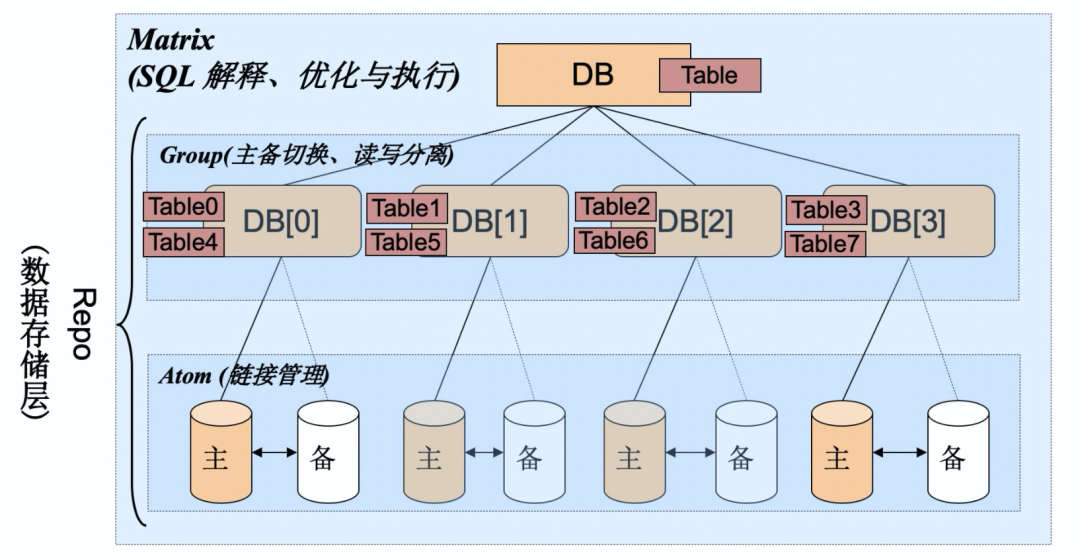
垂直分表 水平分表
垂直分库 水平分库
冷热分离,把常用的列放在一个表,不常用的放在一个表。
大字段列独立存放,如描述信息。
关联关系的列紧密的放在一起。
为了避免IO争抢并减少锁表的几率,查看详情的用户与商品信息浏览互不影响。
充分发挥热门数据的操作效率,商品信息的操作的高效率不会被商品描述的低效率所拖累。
库内的水平分表,解决了单一表数据量过大的问题,分出来的小表中只包含一部分数据,从而使得单个表的数据量变小,提高检索性能。
避免IO争抢并减少锁表的几率。
解决业务层面的耦合,业务清晰。
高并发场景下,垂直分库一定程度的提升IO、数据库连接数、降低单机硬件资源的瓶颈。
能对不同业务的数据进行分级管理、维护、监控、扩展等。
垂直分库通过将表按业务分类,然后分布在不同数据库,并且可以将这些数据库部署在不同服务器上,从而达到多个服务器共同分摊压力的效果,但是依然没有解决单表数据量过大的问题。
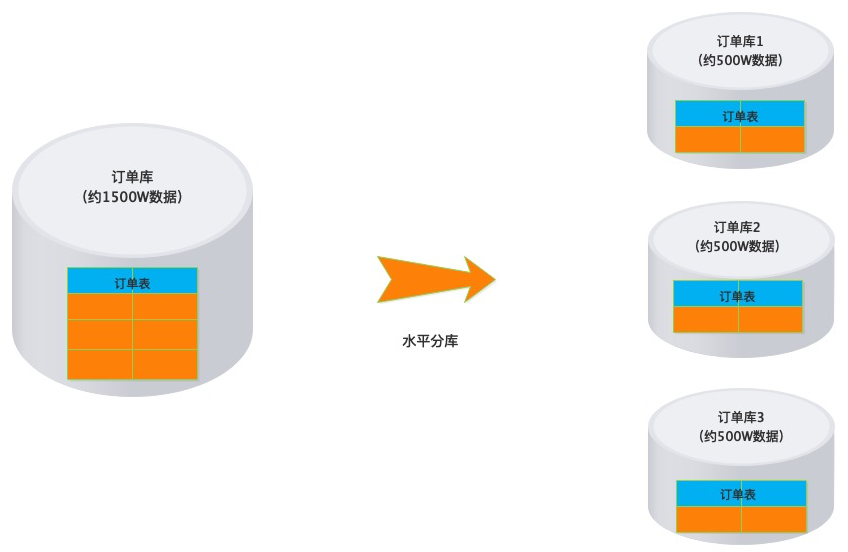
解决了单库单表数据量过大的问题,理论上解决了高并发的性能瓶颈。
如何知道数据在哪个库里?- 路由问题
结果合并
全局唯一主键ID
分布式事务(暂时不支持)
select * from tb1 where member_id in ('test1234', 'pavaretti17', 'abcd');=>select * from tb1 where member_id in ('test1234', 'pavaretti17', 'abcd');select * from tb1 where member_id in ('abcd');

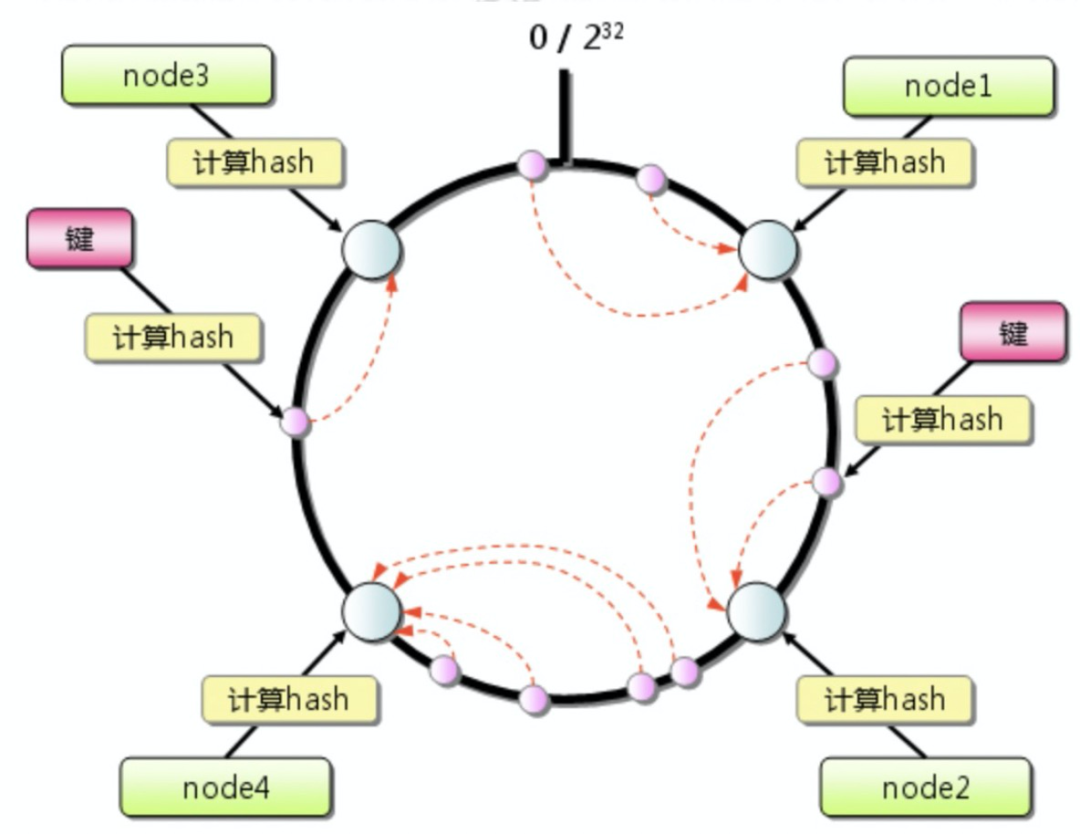
极好的应对了服务器宕机的场景。
很好的支持后期服务器扩容。
在引入虚拟节点后:能很好的平衡各节点的数据分布。
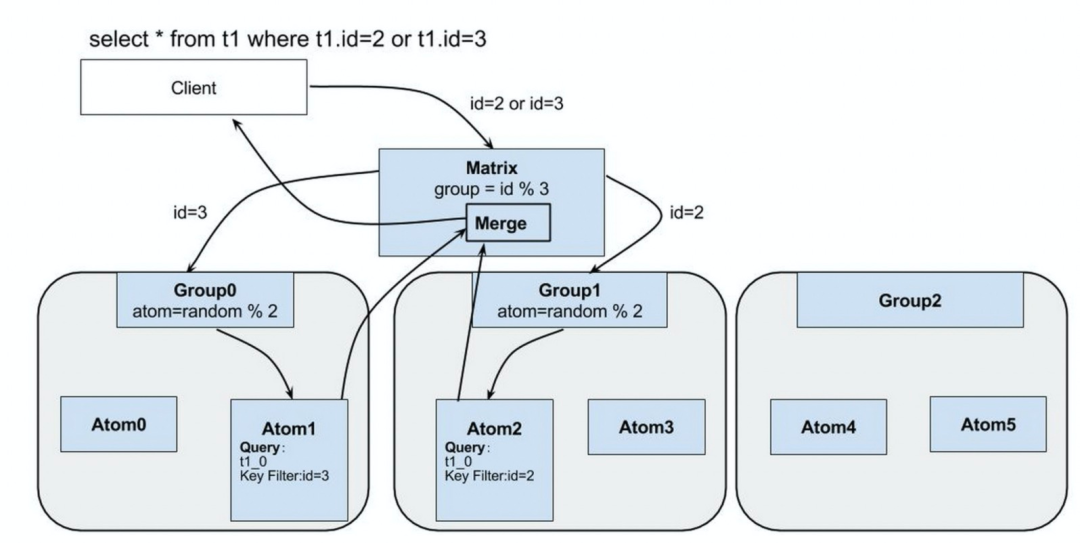
任务拆分 多路并行操作 结果合并
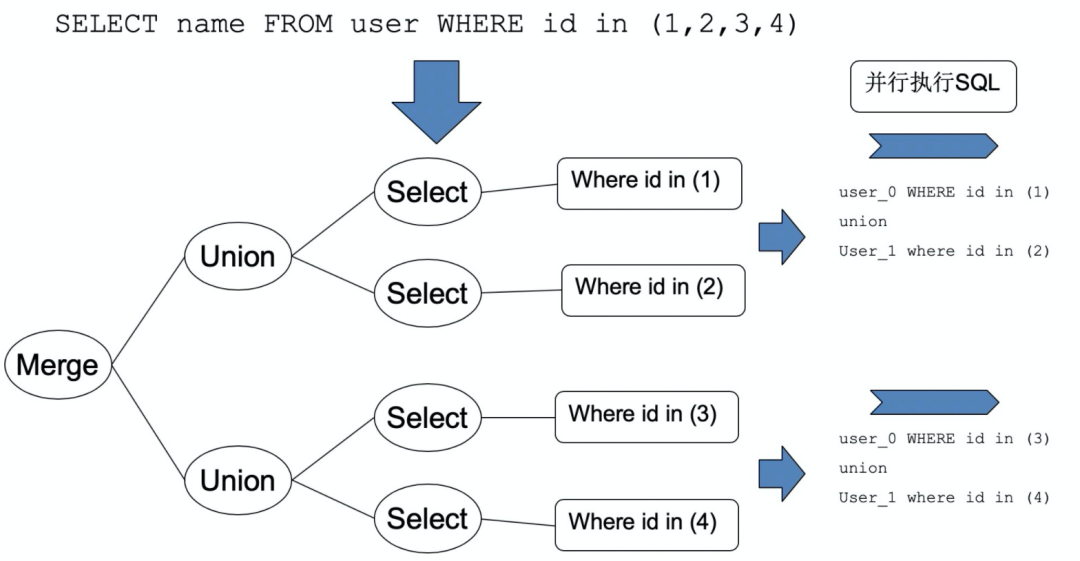
优势:简单高效。 缺点:无法保证自增顺序。
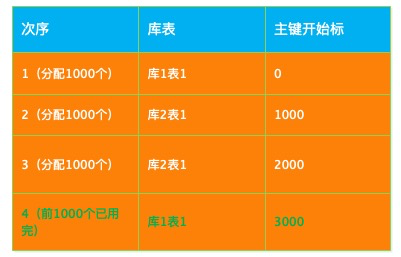
水平分库分表:一拆三场景。主键分隔值:1000。
表1新增一条数据,于是给表1分配1000个主键ID, 直到它用完。
同理,表2、表3在新增数据时,也给它们分配1000个主键ID。直到它用完。
当它们的1000个主键ID用完后,继续给它们分配1000个即可。
重复下去,可保证各库表上的主键不重叠,唯一。
优先考虑缓存降低对数据库的读操作。
再考虑读写分离,降低数据库写操作。
最后开始数据拆分,切分模式:首先垂直(纵向)拆分、再次水平拆分。
首先考虑按照业务垂直拆分。
再考虑水平拆分:先分库(设置数据路由规则,把数据分配到不同的库中)。
最后再考虑分表,单表拆分到数据1000万以内。
优先使用分表分库框架(直接使用)。 优先考虑缓存降低对数据库的读操作。 自己垂直分表。 自己水平分表。
主从只负责各自的写和读,极大程度的缓解X锁和S锁的竞争。
从库可配置myisam引擎,提升查询性能以及节约系统开销。
数据的备份同步问题:参考4.4.3。
读写比例支持动态设置:结合业务,如淘宝可设置为20:1。
数据的备份同步问题:binlog 参考4.4.3。
检测数据库的在线状态:心跳机制。
主库负责写操作,在数据变更时,会写入binlog,同时通知各从库。
从库收到通知后,IO线程会主动过来读取主库的binlog,并写入自己的log。
写完从库log后,通知sql线程,sql线程读取自己的日志,写入从库。
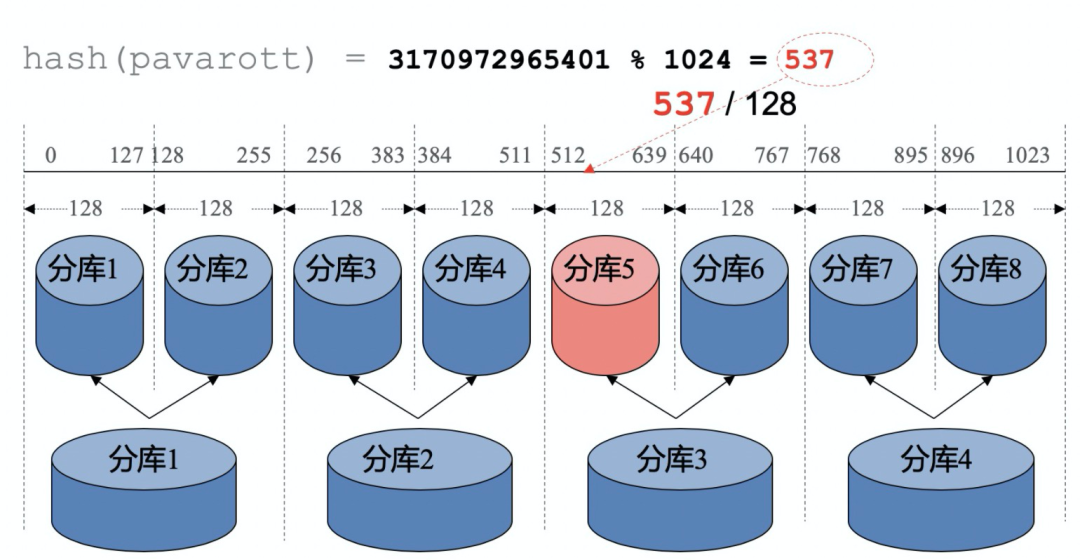
在添加新库时
注册机器与库
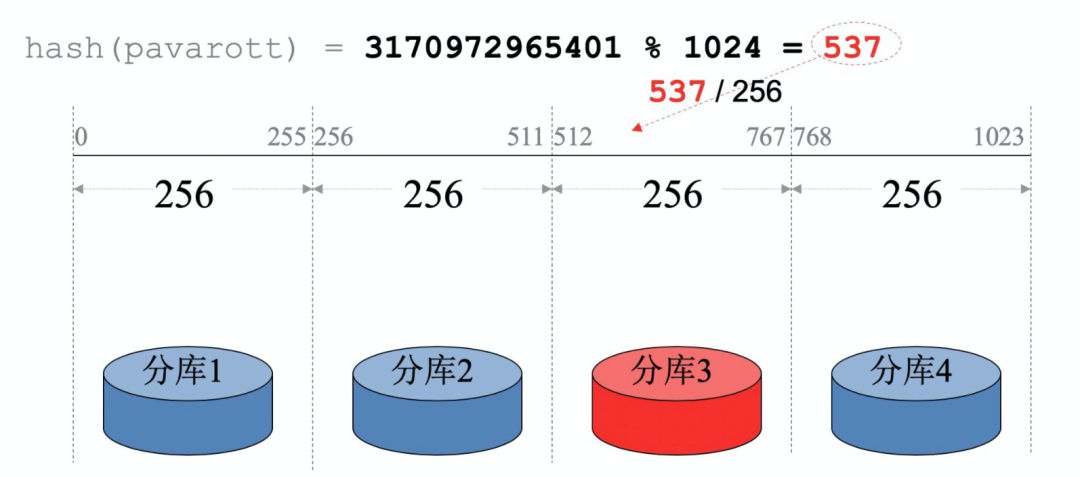
路由算法调整:固定哈希算法-调整模数/一致性哈希算法天然支持扩容
可选的权重调整
修改权重,数据插入偏向于新库5。
在各库数量平衡时,触发修改回原来平衡的权重,以保证后续的均衡分配。
参考
TDDL 官方文档
http://mw.alibaba-inc.com/products/tddl/_book/
TDD产品原理介绍
http://gitlab.alibaba-inc.com/middleware/tddl5-wiki/raw/master/docs/Tddl_Intro.ppt
TDDL(07-10年)初始版本介绍
https://wenku.baidu.com/view/9cb630ab7f1922791788e825.html
阿里云SQL调优指南
https://help.aliyun.com/document_detail/144293.html
一致性哈希算法原理
https://www.cnblogs.com/lpfuture/p/5796398.html
TDDL初期源码(码云)
https://gitee.com/justwe9891/TDDL
MyISAM与InnoDB 的区别(9个不同点)
https://blog.csdn.net/qq_35642036/article/details/82820178
有道无术,术可成;有术无道,止于术
欢迎大家关注Java之道公众号
好文章,我在看❤️
评论