
BERT和GPT-3为啥总「不说人话」?因为它们看了太多reddit

新智元报道
新智元报道
来源:cacm
编辑:小匀
【新智元导读】BERT的深度学习模型展示了自然语言处理(NLP)的重大进步,那么如何证明这些语言模型很出色呢?
几年前,一个名为BERT的深度学习模型展示了自然语言处理(NLP)的重大进步。
BERT的核心结构基于一种被称为Transformer的神经网络,从完成搜索查询和用户写的句子到语言翻译,如今,它已经成为一系列NLP应用的基础。

那么,拿什么证明这些模型真的很出色呢?
就像好学生是用成绩来证明一样。
也有一些测试项目应运而生,例如卡内基梅隆大学开发的大规模重新理解(Large-scale ReAding Comprehension, RACE),这是一个与高中阶段理解能力相当的的测试基准。
这样一来,它们就成了人工智能淘金热中的营销工具。
在Nvidia的年度技术会议上,黄仁勋就用用RACE宣称其公司实施的BERT的高性能。
「普通人类得分73%,专家级人类得分95%。Nvidia的Megatron-BERT得分91%。」黄仁勋说,「Facebook AI Research开发了一个基于Transformer的聊天机器人,具有知识、个性和同理心,跟人类相比,一半的测试用户更喜欢它。」

随着GPT-3的发布,性能又提升了一个档次,GPT-3是OpenAI公司开发的一系列语言模型的最新迭代,拥有1750亿个可训练参数,是BERT最大版本的500倍。

「容量」赋予了GPT-3令人印象深刻的能力。
大多数其他基于Transformer的系统需要一个训练序列,对深度神经网络(DNN)管道的最后几层进行微调,以适应特定的应用,例如语言翻译,而OpenAI承诺GPT-3可以免除广泛的微调需求,因为其核心训练集的规模非常大。
测试表明,GPT-3有能力根据简短的提示构建长篇文章。

然而,这个庞大的系统也有容易显现的缺陷。
例如,向GPT-3提出的问题往往会得到一个难以理解的超现实主义答案。比如说它声称草有眼睛,或者在某些情况下声称一匹马有四只眼睛。
不久后,OpenAI发表了一篇论文,他们在文中质疑了纯粹为语言建模而训练的庞大模型的局限性。
这些语言模型性能的关键于他们的「知识储备」,但很遗憾,他们从维基百科、Reddit等社交媒体搜集了新源,这些信息本身就掺杂矛盾。
早期的方法使用了单词嵌入,其中每个离散的单词使用聚类算法转换为数字向量。在用于训练的语料中,最常围绕它的词决定了向量的值。但这些方法遇到了问题,因为它们无法对具有多重含义的词进行区分。
而BERT考虑到了单词的灵活含义。
他们使用多层神经网络构造,即所谓的Transformers,不是将向量分配给单独的词,而是分配给模型在扫描训练集时发现的不同语境中的词和子词。
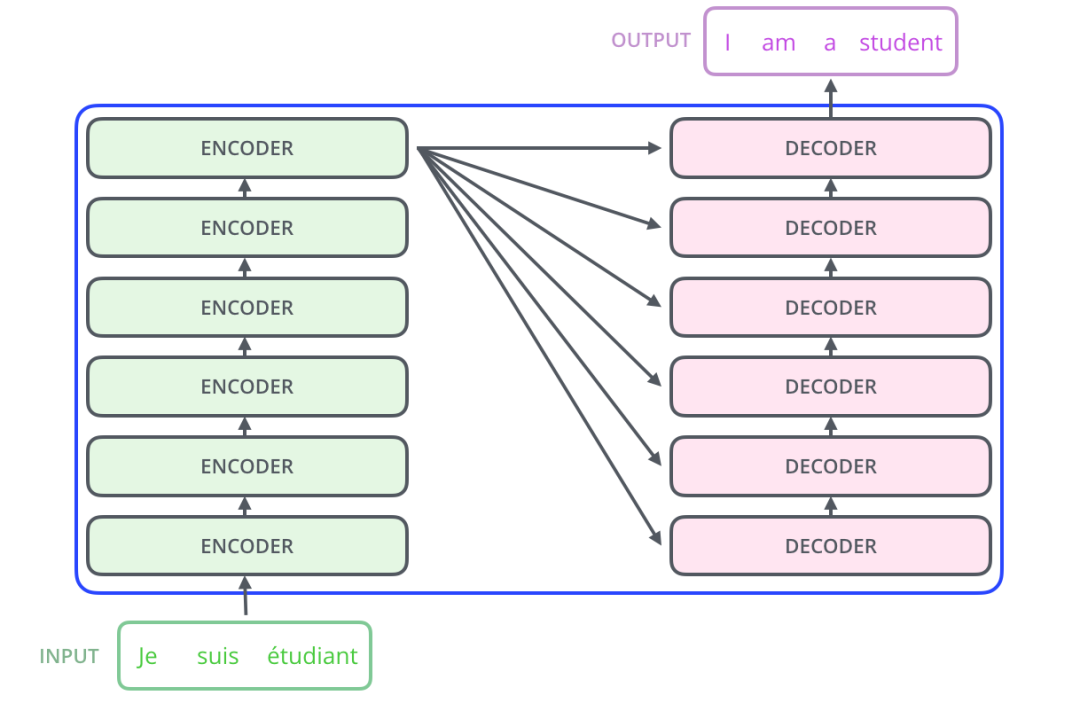
虽然Transformer会将单词及其词干与不同的语境联系起来,但他们实际学习的单词和语境之间是什么关系,仍然不够明确。
这种不确定性催生了马萨诸塞大学洛厄尔分校助理教授Anna Rumshisky及其同事所称的「BERT学」。

在这样的研究中,BERT是一个特别的焦点,因为它的源代码是可用的,相比之下,规模大得多的GPT-3只能通过API访问。
仔细观察,就会发现这些「傻瓜」模型显然缺乏对世界的理解,恰恰这也是被推向真正的应用最需要的。
在实践中,它们大多是根据训练材料中单词的近似性进行联想,因此,基于Transformer的模型经常会弄错基本信息。
例如,南加州大学(USC)Xiang Ren团队的博士生Bill Yuchen Lin就发了一套测试,来探究语言模型对数字问题给出合理答案的能力。

例如,在运行BERT时,它声称一只鸟「有两条腿」的概率是「两条腿」的2倍。它也可以给出矛盾的答案。
另一方面,虽然BERT「坚信」一辆车拥有四个轮子,但如果将说法限定为「圆形轮子」,那么该车型声称它更有可能「只运动两个轮子」。
潜在的偏见是另一个亟需解决的问题。
艾伦人工智能研究所的Yejin Choi及其同事的工作表明,原因在于语料库的来源——很遗憾,它们大多为reddit。然而,即使是维基百科这种偏见稍弱的地方,也会得到激进偏见的结果。
「对内容进行消毒是非常可取的,但由于潜在有毒语言的微妙之处,这可能并不完全可能。」Choi说。
当然,「常识性训练」是个解决办法。
但Choi指出,「偏见」无处不在。
所以,要想进行「常识性训练」,就需要手工建立一个库,例如现在的ConceptNet,ConceptNet是由MIT构建的语义网络,其中包含了大量计算机应该了解的关于这个世界的信息,这些信息有助于计算机做更好的搜索、回答问题以及理解人类的意图。它由一些代表概念的结点构成,这些概念以自然语言的单词或者短语形式表达,并且其中标示了这些概念的关系。
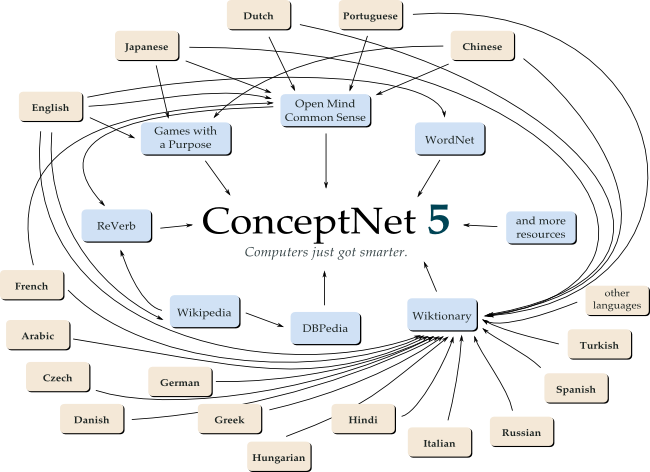
但它远非全面。
然而,目前仍不清楚Transformer的神经网络设计本身是否提供了一个合适的结构来表示它试图存储的知识。斯坦福大学的博士后研究员Antoine Bosselut说:「这是这个领域最有趣的问题之一,需要回答。我们还不知道常识性知识究竟是如何被编码的。而我们也不知道语言属性是如何被编码的。」
为了提高语言模型的能力,日本IBM的高级技术人员Tetsuya Nasukawa表示,他和他的同事在创建他们的视觉概念命名(VCN)系统时,从图像和语言共同用于教育儿童的方式中获得了灵感。
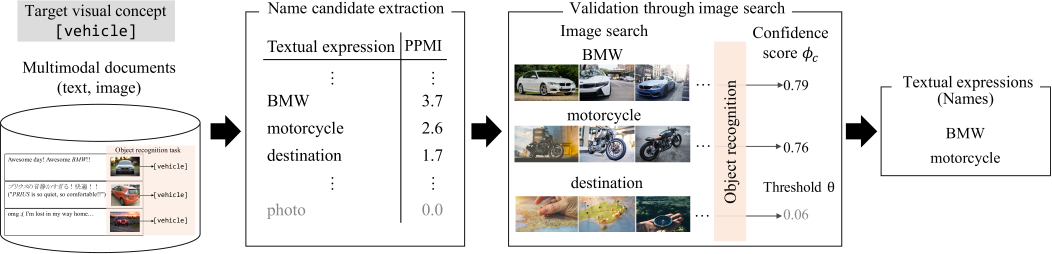
这利用社交媒体上的图片和文字,将物体与经常用来描述它们的词语联系起来,因为不同的文化和民族可能会使用截然不同的术语来指称同一事物,而仅靠文字的传统训练是无法捕捉到的。
「我们认为,通过使用视觉信息来处理位置、形状和颜色等非文字信息是必不可少的。」他说。
另一种方法,Ren的小组已经使用过,就是将现有的手工构建的知识库与Transformer进行耦合,而不是试图教授语言模型的常识。KagNet结合第二个神经网络对BERT实现进行微调,该神经网络对ConceptNet知识库中存储的信息进行编码。
很多人在这条道路走得很远,但事实上,语言建模的下一次迭代可能会开启一套新的能力,而这些能力是当前一代人所不具备的。
这就是The Best of NLP:对不同的观点持开放态度。
参考资料:
https://cacm.acm.org/magazines/2021/4/251336-the-best-of-nlp/fulltext

AI家,新天地。西山新绿,新智元在等你!
【新智元高薪诚聘】主笔、高级编辑、商务总监、运营经理、实习生等岗位,欢迎投递简历至wangxin@aiera.com.cn (或微信: 13520015375)
办公地址:北京海淀中关村软件园3号楼1100
