别再问如何用Python提取PDF内容了!


导读
大家好,在之前的办公自动化系列文章中我们已经详细介绍了?如何使用Python批量处理PDF文件,包括合并、拆分、水印、加密等操作。
今天我们再次回到PDF,详细讲解如何使用Python从PDF提取指定的信息。我们将以一份年度报告PDF为例进行介绍,内含大量文字、表格、图片,具体如下
模块安装
首先需要安装两个模块,第一个是pdfplumber,在命令行使用pip安装即可?
pip install pdfplumber
第二个是fitz, 它是pymupdf中的一个模块,同样可以使用pip轻松安装
pip install pymupdf
文字信息提取
使用Python提取PDF中文字代码思路如下
利用 pdfplumber打开一个 PDF 文件获取指定的页,或者遍历每一页 利用 .extract_text()方法提取当前页的文字
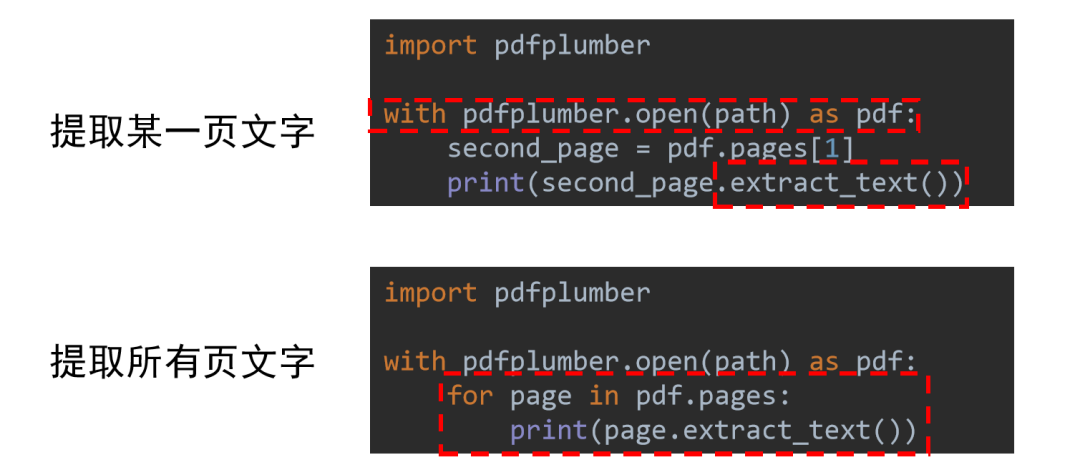 现在让我们用上述代码尝试提取示例数据中第12页的文字?
现在让我们用上述代码尝试提取示例数据中第12页的文字?
import pdfplumber
file_path = r'C:\xxxx\practice.PDF'
with pdfplumber.open(file_path) as pdf:
page = pdf.pages[11]
print(page.extract_text())
结果如下图所示 接着可以将内容通过导入
接着可以将内容通过导入python-docx并借助wordfile.add_paragraph()写入Word文件中,而这个模块我们已经讲解很多次,此处就不再赘述。
表格信息提取
使用Python提取单个表格和提取单页文字的代码非常类似,用的是.extract_table()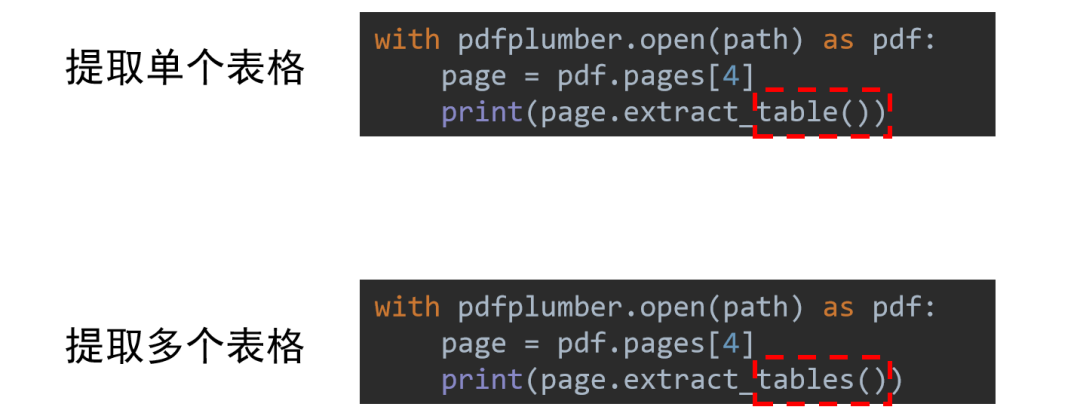 但需要注意的是
但需要注意的是.extract_table()默认提取指定页面的第一个表格,如果当前页面有多个表格都需要提取,则要直接使用.extract_tables()
例如示例文件中第 13 页有 2 个表格,我们分别利用.extract_table()和.extract_tables()观察输出结果
import pdfplumber
file_path = r'C:\xxxx\practice.PDF'
with pdfplumber.open(file_path) as pdf:
page = pdf.pages[12]
print(page.extract_table())
结果如下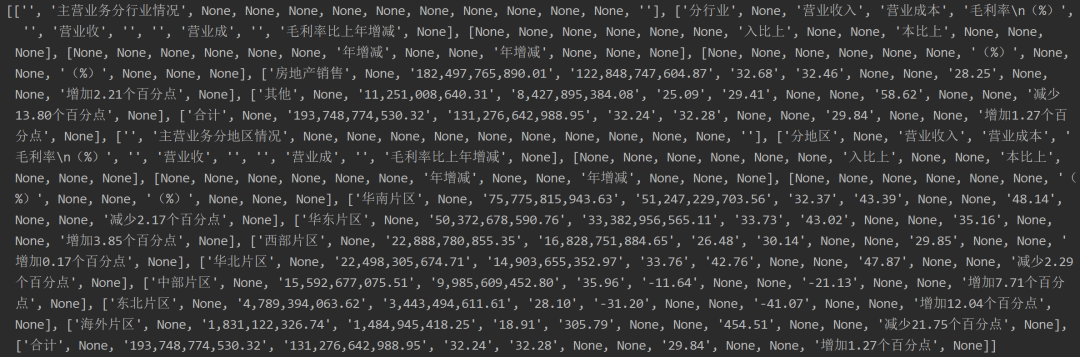 可以看到是一个嵌套列表,熟悉这种格式的人会理解想到可以
可以看到是一个嵌套列表,熟悉这种格式的人会理解想到可以pandas或者遍历该嵌套列表后借助openpyxl的sheet.append(list)写入Excel文件中,
import pdfplumber
file_path = r'C:\xxxx\practice.PDF'
with pdfplumber.open(file_path) as pdf:
page = pdf.pages[12]
print(page.extract_tables())
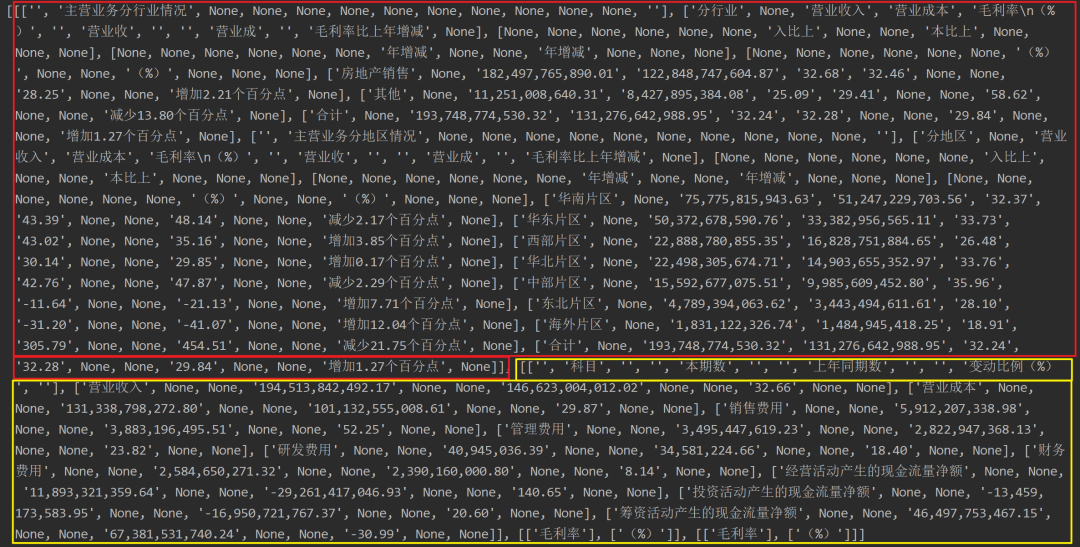 而
而.extract_tables()提取当前页所有表格会产生了一个三级嵌套列表,第一层的列表就代表每一个表格,之后也可以利用其他库写入Excel。
图片提取
对于图片提取,现在没有任何一个模块可以做到百分之百的提取。本文只介绍基于fitz模块的代码,基本思路是通过正则查找图片并将其输出
例如提取示例文件中的图片,代码可以这么写?
import fitz
import re
import os
file_path = r'C:\xxx\practice.PDF'
dir_path = r'C:\xxx' # 存放图片的文件夹
def pdf2pic(path, pic_path):
checkXO = r"/Type(?= */XObject)"
checkIM = r"/Subtype(?= */Image)"
pdf = fitz.open(path)
lenXREF = pdf._getXrefLength()
imgcount = 0
for i in range(1, lenXREF):
text = pdf._getXrefString(i)
isXObject = re.search(checkXO, text)
isImage = re.search(checkIM, text)
if not isXObject or not isImage:
continue
imgcount += 1
pix = fitz.Pixmap(pdf, i)
new_name = f"img_{imgcount}.png"
if pix.n < 5:
pix.writePNG(os.path.join(pic_path, new_name))
else:
pix0 = fitz.Pixmap(fitz.csRGB, pix)
pix0.writePNG(os.path.join(pic_path, new_name))
pix0 = None
pix = None
pdf2pic(file_path, dir_path)
结果如下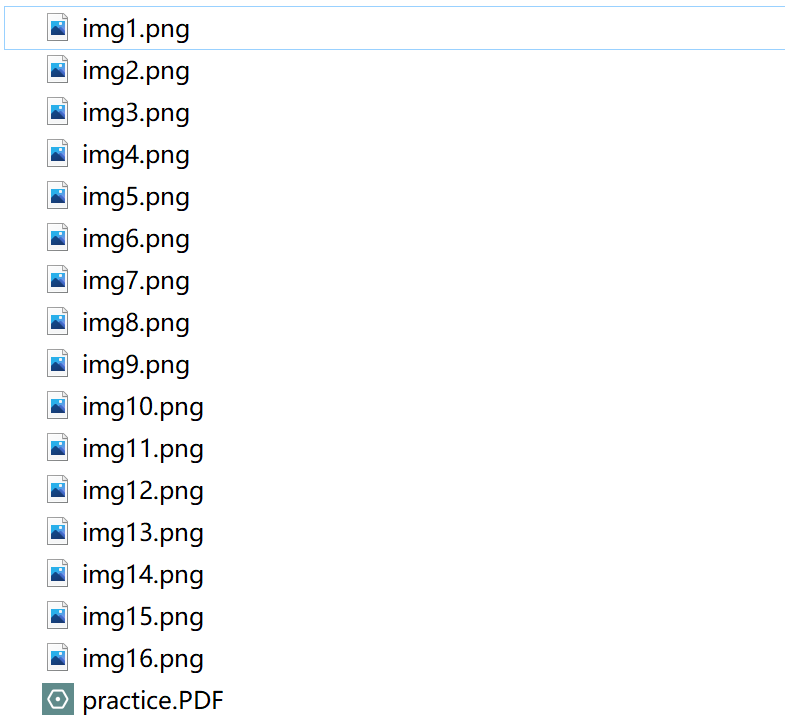 可以看到成功提取了图片,但PDF中的图片远不止这些,如果你有其他思路或者方法可以在留言区与我交流。
可以看到成功提取了图片,但PDF中的图片远不止这些,如果你有其他思路或者方法可以在留言区与我交流。
写在最后
最后要说明的是,在上一篇文章及本文中我们剖析了每一行代码。但针对PDF的模块较多,且有些模块功能并不完善,代码也没有类似OFFICE三件套操作那般简洁,因此更多时候以理解为主,不需要完全掌握写,会用会改即可!
当然还是希望大家能够理解Python办公自动化的一个核心就是批量操作-解放双手,并且能与日常办公结合让复杂的工作自动化!
今天的文章就到这里,原创不易,如果喜欢的话请给我一波三连支持吧(在看、转发、留言)
-END-
本文为公众号早起Python专栏作者陈熹原创,转载请后台联系,未经授权的任何形式转载均视为侵权!