
CV岗位面试题:DPM(Deformable Parts Model)算法流程

文 | 七月在线
编 | 小七
解析1:
将原图与已经准备好的每个类别的“模板”做卷积操作,生成一中类似热力图(hot map)的图像,将不同尺度上的图合成一张,图中较量点就是与最相关“模板”相似的点。
拓展:
* SGD(stochastic gradient descent)到training里
* NMS(non-maximum suppression)对后期testing的处理非常重要
* Data mining hard examples这些概念至今仍在使用
解析2:
DPM算法由Felzenszwalb于2008年提出,是一种基于部件的检测方法,对目标的形变具有很强的鲁棒性。目前DPM已成为众多分类、分割、姿态估计等算法的核心部分,Felzenszwalb本人也因此被VOC授予"终身成就奖"。
DPM算法采用了改进后的HOG特征,SVM分类器和滑动窗口(Sliding Windows)检测思想,针对目标的多视角问题,采用了多组件(Component)的策略,针对目标本身的形变问题,采用了基于图结构(Pictorial Structure)的部件模型策略。此外,将样本的所属的模型类别,部件模型的位置等作为潜变量(Latent Variable),采用多示例学习(Multiple-instance Learning)来自动确定。
1、通过Hog特征模板来刻画每一部分,然后进行匹配。并且采用了金字塔,即在不同的分辨率上提取Hog特征。
2、利用提出的Deformable PartModel,在进行object detection时,detect window的得分等于part的匹配得分减去模型变化的花费。
3、在训练模型时,需要训练得到每一个part的Hog模板,以及衡量part位置分布cost的参数。文章中提出了LatentSVM方法,将deformable part model的学习问题转换为一个分类问题:利用SVM学习,将part的位置分布作为latent values,模型的参数转化为SVM的分割超平面。具体实现中,作者采用了迭代计算的方法,不断地更新模型。
rootfilters根滤波器数组,其每个元素表示一个组件模型的根滤波器的信息,每个元素包括3个字段:
size:根滤波器的尺寸,以cell为单位,w*h
w:根滤波器的参数向量,维数为(w*h)*31
blocklabel:此根滤波器所在的数据块标识
滤波器(模版)就是一个权重向量,一个w * h大小的滤波器F是一个含w * h * 9 * 4个权重的向量(9*4是一个HOG细胞单元的特征向量的维数)。所谓滤波器的得分就是此权重向量与HOG金字塔中w * h大小子窗口的HOG特征向量的点积(DotProduct)。
DPM的特征
de
DPM采用了HOG特征,并对HOG特征进行了一些改进。
Hog特征提取的过程:
1.对原图像gamma校正,img=sqrt(img);
2.求图像竖直边缘,水平边缘,边缘强度,边缘斜率。
3.将图像每16*16(取其他也可以)个像素分到一个cell中。对于256*256的lena来说,就分成了16*16个cell了。
4.对于每个cell求其梯度方向直方图。通常取9(取其他也可以)个方向(特征),也就是每360/9=40度分到一个方向,方向大小按像素边缘强度加权。最后归一化直方图。
5.每2*2(取其他也可以)个cell合成一个block,所以这里就有(16-1)*(16-1)=225个block。
6.所以每个block中都有2*2*9=36个特征,一共有225个block,所以总的特征有225*36个。
当然一般HOG特征都不是对整幅图像取的,而是对图像中的一个滑动窗口取的。
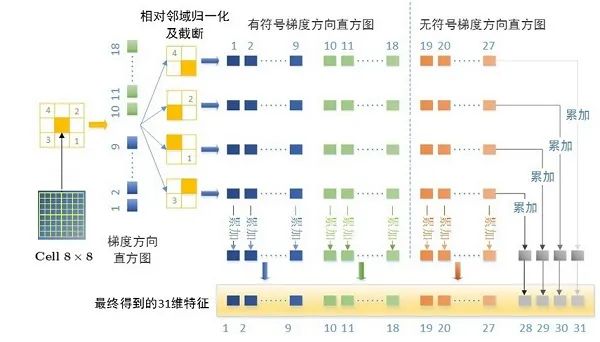
DPM改进后的HOG特征取消了原HOG中的块(Block),只保留了单元(Cell),如上图所示,假设一个8*8的Cell,将该细胞单元与其对角线临域的4个细胞单元做归一化操作,所以效果和原HOG特征非常类似。计算梯度方向时可以计算有符号(0-360°)或无符号(0-180°)的梯度方向,有些目标适合使用有符号的梯度方向,而有些目标适合使用无符号的梯度,作为一种通用的目标检测方法,DPM与原HOG不同,采用了有符号梯度和无符号梯度相结合的策略。
提取有符号的HOG梯度,0-360度将产生18个梯度向量,提取无符号的HOG梯度,0-180度将产生9个梯度向量。如果直接将特征向量化,一个8*8的细胞单元将会产生(18+9)*4=108,维度有点高 。
Felzenszwalb提取了大量单元的无符号梯度,每个单元共 维特征,并进行了主成分分析(Principal Component Analysis,PCA),发现使用前11个特征向量基本上可以包含所有的信息,不过为了快速计算,作者由主成分可视化的结果得到了一种近似的PCA降维效果。
具体来说:首先,只提取无符号的HOG梯度,将会产生4*9=36维特征,将其看成一个4*9的矩阵,分别将行和列分别相加,最终将生成4+9=13个特征向量,得到13维特征,基本上能达到HOG特征36维的检测效果。为了提高那些适合使用有符号梯度目标的检测精度,作者再对18个有符号梯度方向求和得到18维向量,也加进来,这样,一共产生13+18=31维梯度特征。实现了很好的目标检测。
DPM的检测模型
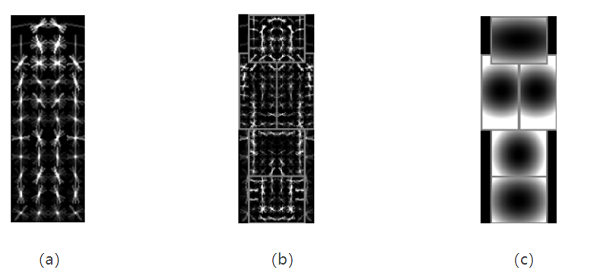
DPM V3版本的目标检测模型由两个组件构成,每一个组件由一个根模型和若干部件模型组成。上图(a)和(b)是其中一个组件的根模型和部件模型的可视化的效果(这个只是可视化的结果,不要认为是用这个当做模板与原图特征图做卷积!!,真正与原图特征图做卷积计算的是检测算子,即SVM分类模型系数w),每个单元内都是SVM分类模型系数w对梯度方向加权叠加,梯度方向越亮的方向可以解释为行人具有此方向梯度的可能性越大。
上图(a),根模型比较粗糙,大致呈现了一个直立的正面/背面行人。
上图(b)所示,部件模型为矩形框内的部分,共有6个部件,分辨率是根模型的两倍,这样获得更好的效果。从中,我们可以明显地看到头、手臂等部位。为了降低模型的复杂度,根模型和部件模型都是轴对称的。
上图(c)为部件模型的偏离损失,越亮的区域表示偏离损失代价越大,部件模型的理想位置的偏离损失为0。
DPM检测流程
DPM采用了传统的滑动窗口检测方式,通过构建尺度金字塔在各个 尺度搜索。下图为某一尺度下的行人检测流程,即行人模型的匹配过程。某一位置与根模型/部件模型的响应得分,为该模型与以该位置为锚点(即左上角坐标)的子窗口区域内的特征的内积。也可以将模型看作一个滤波算子,响应得分为特征与待匹配模型的相似程度,越相似则得分越高。
左侧为根模型的检测流程,跟模型响应的图中,越亮的区域代表响应得分越高。右侧为各部件模型的检测过程。首先,将特征图像与模型进行匹配得到部件模型响应图。然后,进行响应变换:以锚点为参考位置,综合考虑部件模型与特征的匹配程度和部件模型相对理想位置的偏离损失,得到的最优的部件模型位置和响应得分。
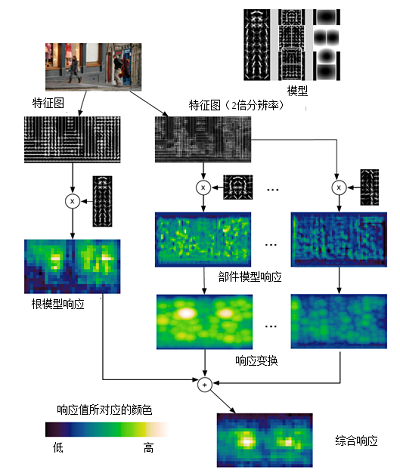
如上图所示,对于任意一张输入图像,提取其DPM特征图,然后将原始图像进行高斯金字塔上采样放大原图像,然后提取其DPM特征图(2倍分辨率)。将原始图像的DPM特征图和训练好的Root filter做卷积操作,从而得到Root filter的响应图。对于2倍图像的DPM特征图,和训练好的Part filter做卷积操作,从而得到Part filter的响应图。然后对其精细高斯金字塔的下采样操作。这样Root filter的响应图和Part filter的响应图就具有相同的分辨率了。然后将其进行加权平均,得到最终的响应图,亮度越大表示响应值越大。
回顾精品内容
推荐系统
机器学习
自然语言处理(NLP)
1、AI自动评审论文,CMU这个工具可行吗?我们用它评审了下Transformer论文
2、Transformer强势闯入CV界秒杀CNN,靠的到底是什么"基因"
计算机视觉(CV)
1、9个小技巧让您的PyTorch模型训练装上“涡轮增压”...
GitHub开源项目:
1、火爆GitHub!3.6k Star,中文版可视化神器现身
2、两次霸榜GitHub!这个神器不写代码也可以完成AI算法训练
3、登顶GitHub大热项目 | 非监督GAN算法U-GAT-IT大幅改进图像转换
每周推荐:
1、本周优秀开源项目分享:无脑套用格式、开源模板最高10万赞
2、本周优秀开源项目分享:YOLOv4的Pytorch存储库、用pytorch增强图像数据等7大项目
七月在线学员面经分享:
1、 双非应届生拿下大厂NLP岗40万offer:面试经验与路线图分享