
网易互娱的数据库选型和 TiDB 应用实践
点击上方蓝色字体,选择“设为星标”
回复”资源“获取更多资源


一、业务架构简介
1.1 MySQL 使用架构
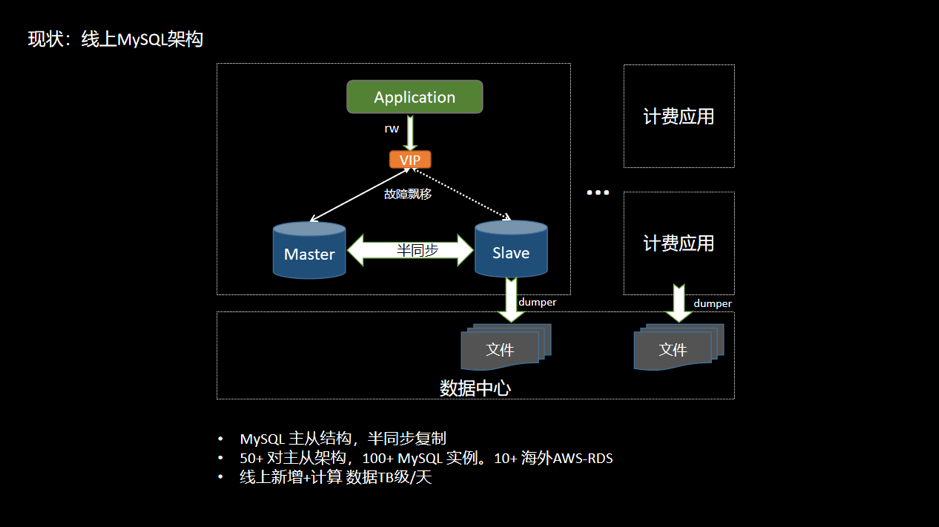
线上应用 Application 通过 Keepalive + 多机部署,流量经过负载均衡,可以有效保障应用服务的高可用; 数据库层架构是 Keepalive + 主从结构,利用半同步复制特性可以有效解决延迟和数据一致性的问题; Application 通过 VIP 访问后端数据库,在数据库主节点宕机后通过 VIP 飘移到从节点,保证服务正常对外提供; 通过 Slave 节点进行数据备份和线上数据采集,经过全量和增量同步方式导出数据到数据中心,然后进行在线和离线计算任务; 类似这样的架构组合线上大概有 50+ 套,涉及服务器 200~400 台,日均新增数据 TB 级。
1.2 MySQL 使用的现状与问题
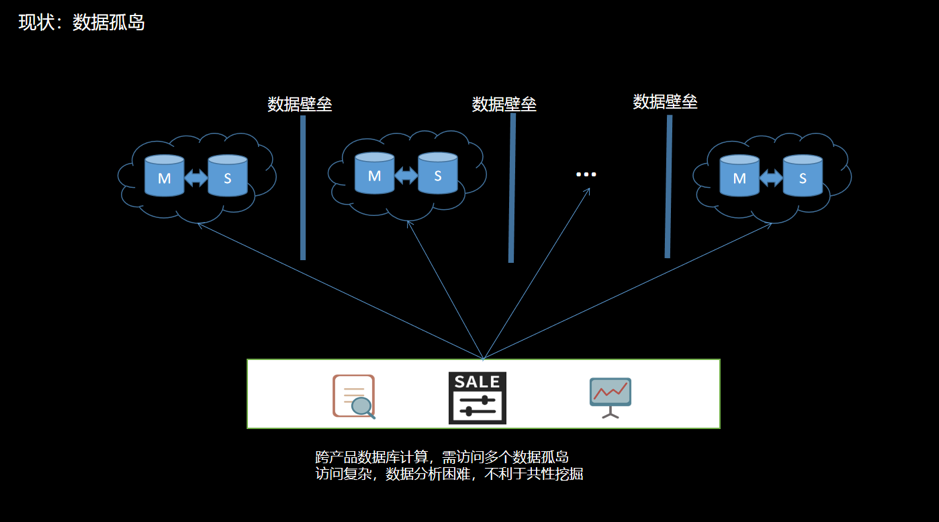
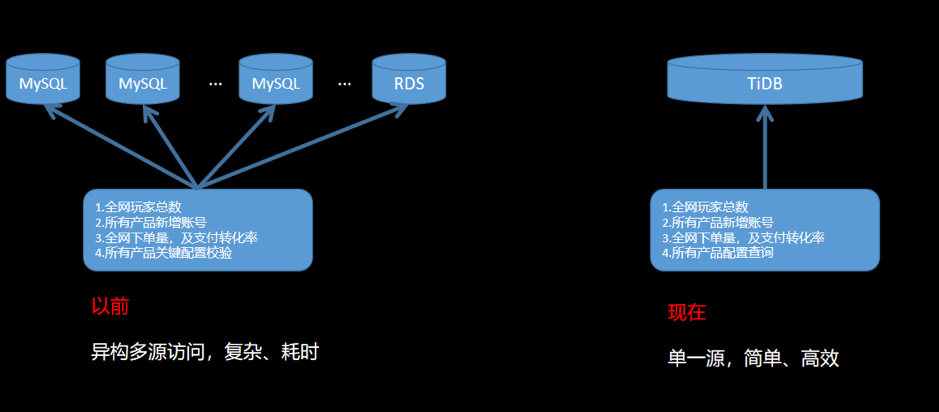
容量 单机 MySQL 实例存储空间有限,想要维持现有架构就得删除和轮转旧数据,达到释放空间的目的; 网易互娱某些场景单表容量达到 700GB 以上,订单数据需永久保存,同时也需要保持在线实时查询,按照之前的存储设计会出现明显的瓶颈。 性能 最大单表 15 亿行,行数过大,导致读写性能受到影响。 扩展性 MySQL 无法在线灵活扩展,无法解决存储瓶颈。 SQL 复杂 大表轮转后出现多个分表,联合查询时需要 join 多个分表,SQL 非常复杂并难以维护; 单机 MySQL 缺乏大规模数据分析的能力。 数据壁垒 不同产品的数据库独立部署; 数据不互通,导致数据相关隔离,形成数据壁垒; 当进行跨产品计算时,需要维护多个异构数据源,访问方式复杂。数据分散在不同的数据孤岛上会增加数据分析难度,不利于共性价值的挖掘。如下图:
二、数据库选型
2.1 调研目标
必须兼容 MySQL 协议;
支持事务,保证任务以事务为维度来执行或遇错回滚;
支持索引,尤其是二级索引;
扩展性,支持灵活在线扩展能力,包括性能扩展和容量扩展。
稳定性和可靠性; 备份和恢复; 容灾等。
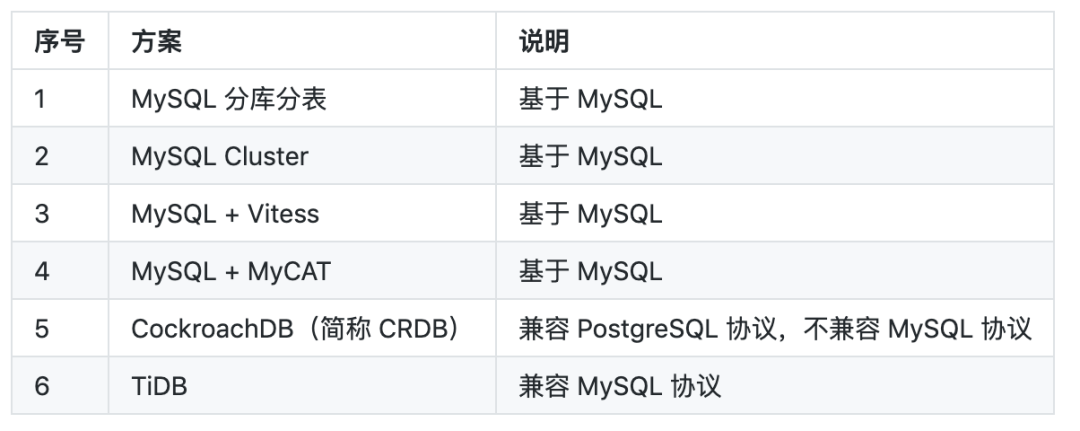
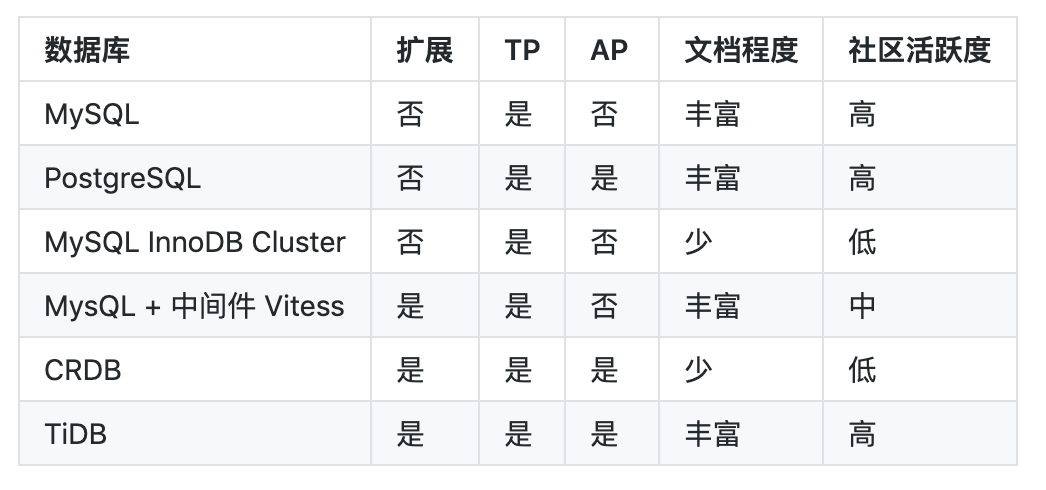
2.2 可选方案
2.3 测试
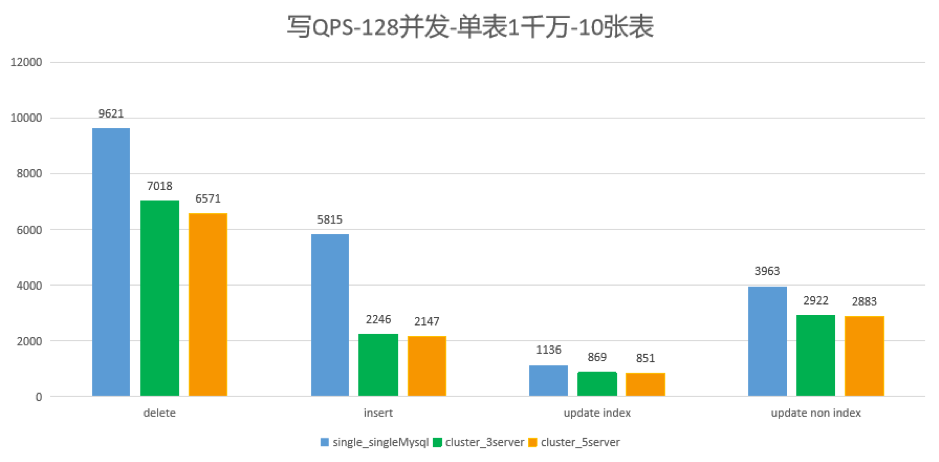
方案过于复杂
需要改业务代码
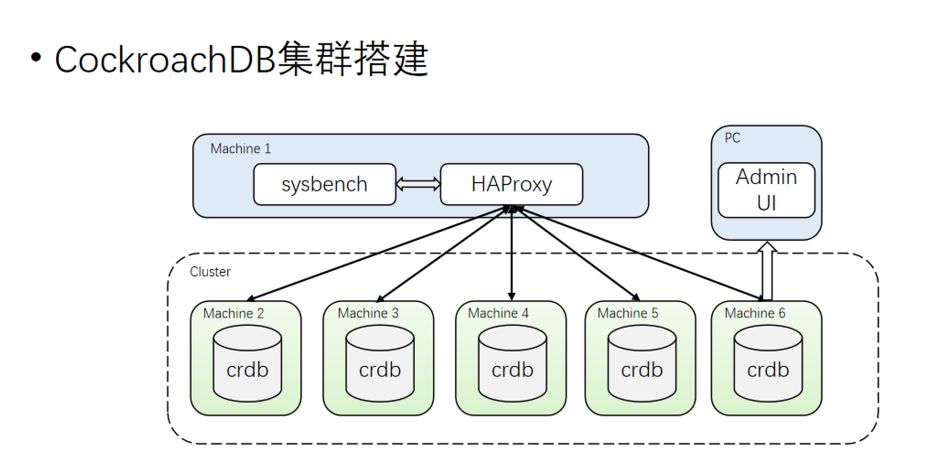
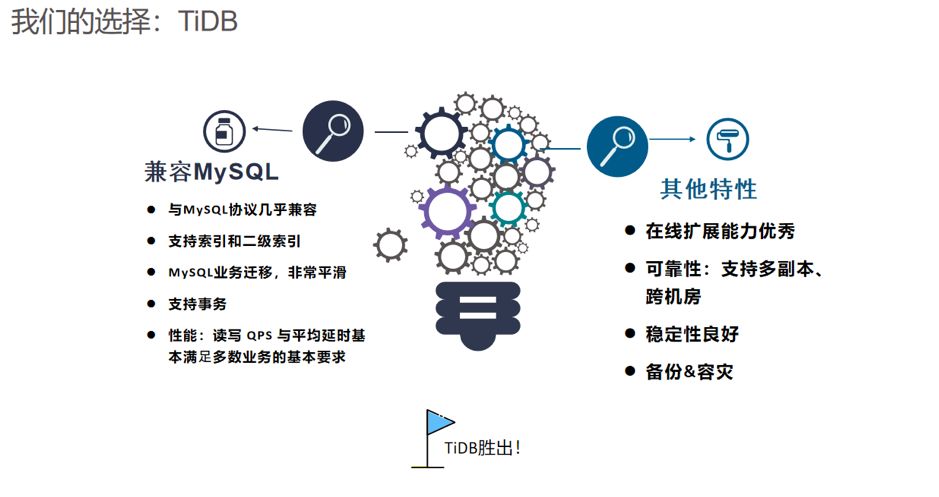
2.3.2 CockroachDB VS TiDB
TiDB 天然兼容 MySQL 协议,而 CRDB 兼容 PostgreSQL ; 如果业务以 MySQL 为主,那 TiDB 可能是比较好的选择;如果是 PostgreSQL,那CRDB 可能是优先的选择。
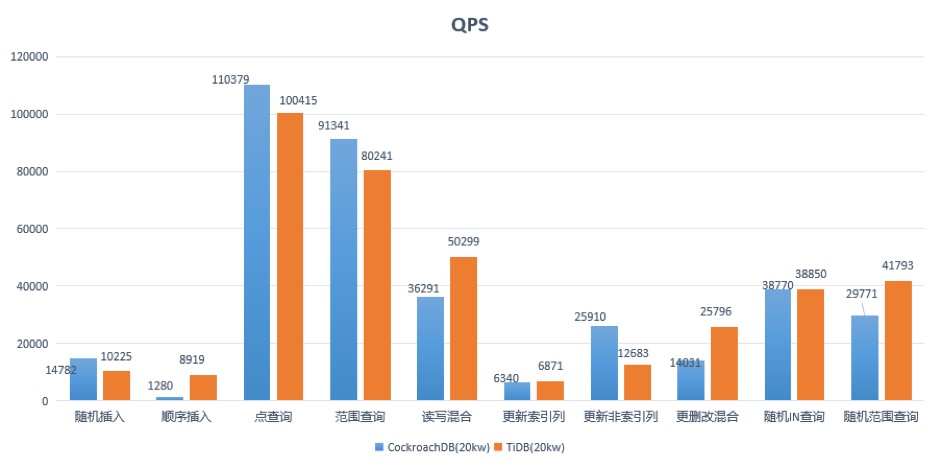
范围查询: SELECT c FROM sbtest%u WHERE id BETWEEN ? AND ?
SELECT SUM(k) FROM sbtest%u WHERE id BETWEEN ? AND ?
SELECT c FROM sbtest WHERE id BETWEEN ? AND ? ORDER BY c
SELECT DISTINCT c FROM sbtest%u WHERE id BETWEEN ? AND ? ORDER BY c随机 IN 查询: SELECT id, k, c, pad FROM sbtest1 WHERE k IN (?)随机范围查询: SELECT count(k) FROM sbtest1 WHERE k BETWEEN ? AND ? OR k BETWEEN ? AND ?更新索引列: UPDATE sbtest%u SET k=k+1 WHERE id=?更新非索引列: UPDATE sbtest%u SET c=? WHERE id=?读写混合:范围查询 + 更删改混合
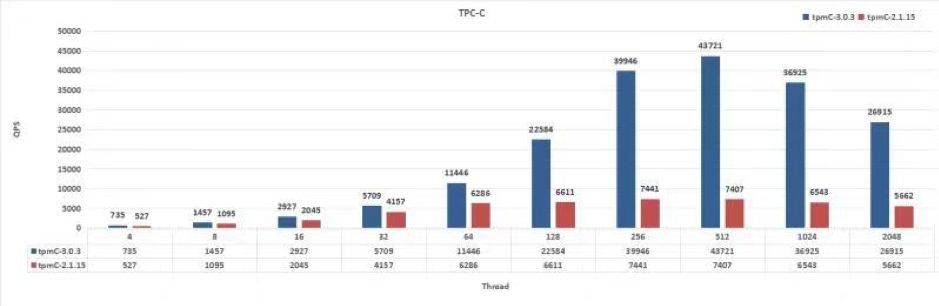
三、TiDB 在网易互娱计费组的使用
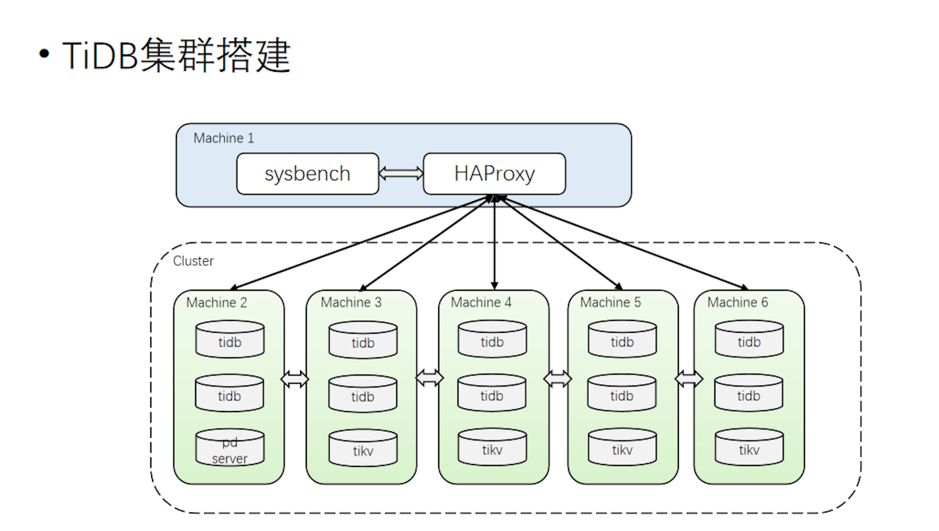
3.1 TiDB 使用架构
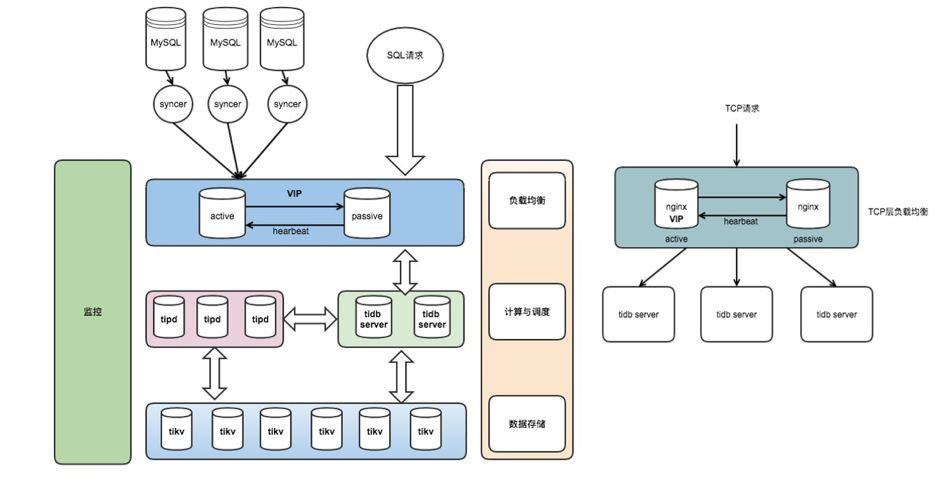
整个集群分为 TiDB、TiKV 和 PD 3 个模块分层部署; 使用 Nginx 作为前端负载均衡。
3.2 TiDB 解决了哪些需求
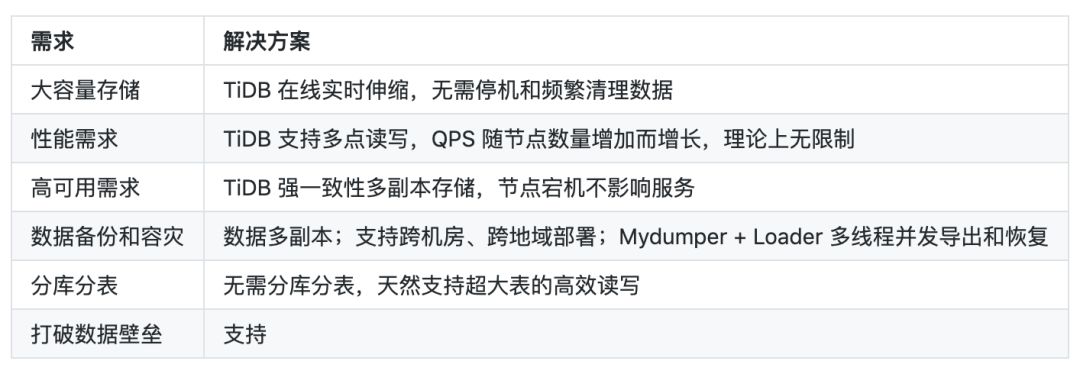
3.3 TiDB 使用现状
业务
TiDB 作为线上 MySQL 数据镜像,负责线上数据的收集和集中管理,形成数据湖泊;
应用于数据平台服务,包括报表、监控、运营、用户画像、大数据计算等场景;
HTAP:OLTP + OLAP。
集群
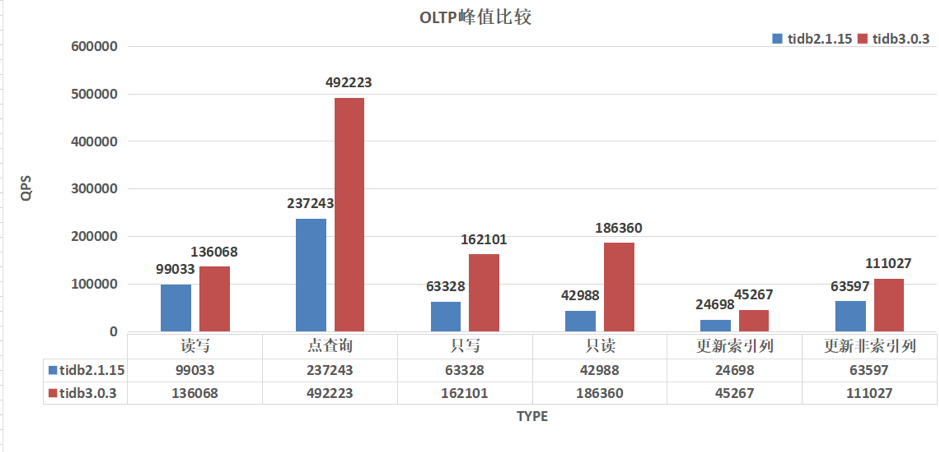
测试集群:v2.1.15,用于功能测试、特性尝鲜;
线上集群:v2.1.15,80% 离线大数据计算任务 + 20% 线上业务。
规模
41 台服务器,88 个实例节点,38 个 Syncer 实时同步流(将升级为 DM);
存储:20TB/总 50TB,230 万个 Region;
QPS 均值 4k/s,高峰期万级 QPS,读写比约 1:5;
延迟时间:80% 在 8ms 以内,95% 在 125ms 以下,99.9% 在 500ms 以下。
四、最佳实践分享
4.1 集群管理
Ansible(推荐) 一键部署弹性伸缩,可在线灵活扩缩容; 升级,单节点轮转平滑升级; 集群启停和下线; Prometheus 监控。 Docker K8s 使用 TiDB Operator 可以在私有云和公有云上一键管理。
4.2 运维实践
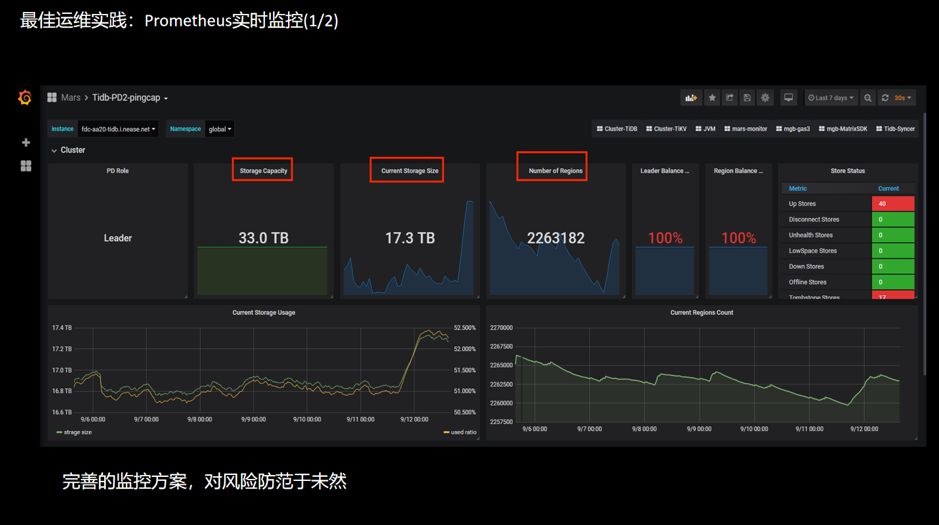
4.2.1 Prometheus 监控
服务器基础资源的监控:内存、CPU、存储空间、IO 等;
集群组件的监控:TiDB、PD、TiKV 等;
数据监控:实时同步流、上下游数据一致性检验等。
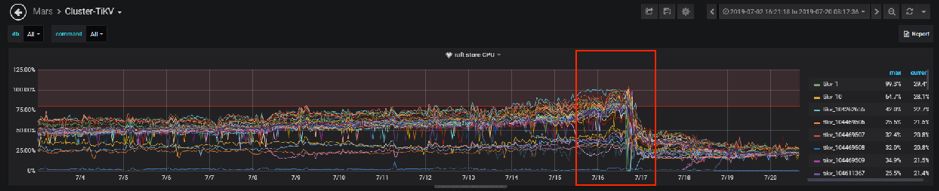
Region 数量过多,Raft Store 还要处理 heartbeat message。 Raft Store 单线程处理速度跟不上集群写入速度。
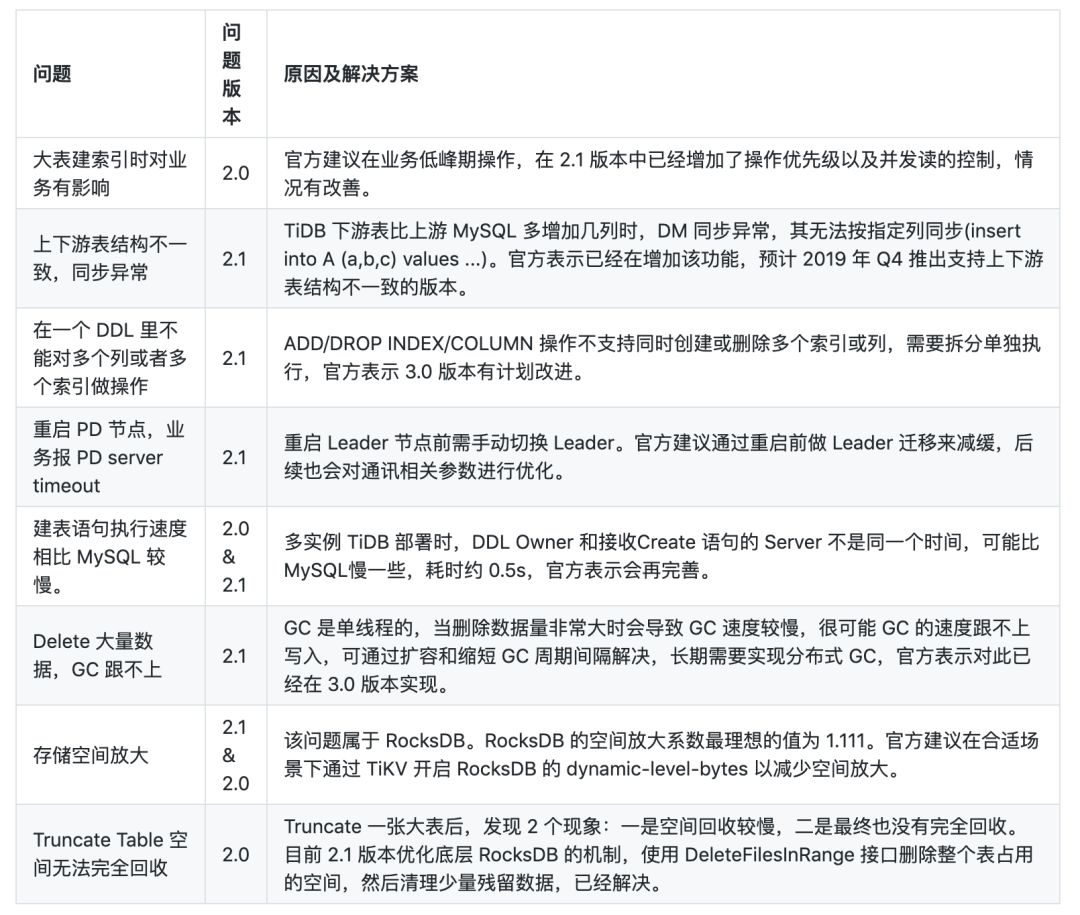
4.3 全网数据库遍历
4.4 数据迁移
4.4.1 MySQL 到 TiDB
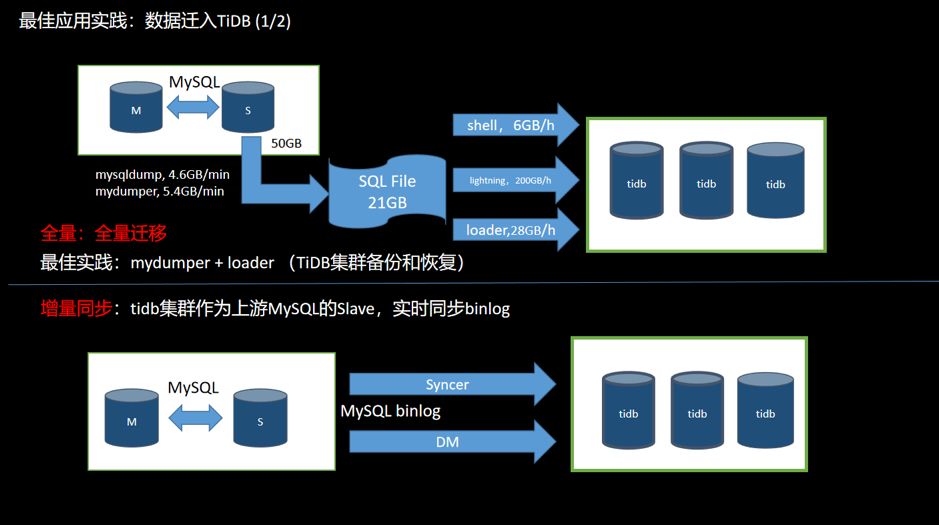
图 14 数据从 MySQL 迁移到 TiDB
全量 使用工具 (Mydumper 或 MySQL Dump 等)从 MySQL 导出数据,并且记录当前数据的 binlog 位置; 使用工具(Loader 或 Lightning 等)将数据导入到 TiDB 集群; 可以用作数据的备份和恢复操作。 增量 TiDB 伪装成为上游 MySQL 的一个 Slave,通过工具(Syncer 或 DM)实时同步 binlog 到 TiDB 集群; 通常情况上游一旦有数据更新,下游就会实时同步过来。同步速度受网络和数据量大小的影响。
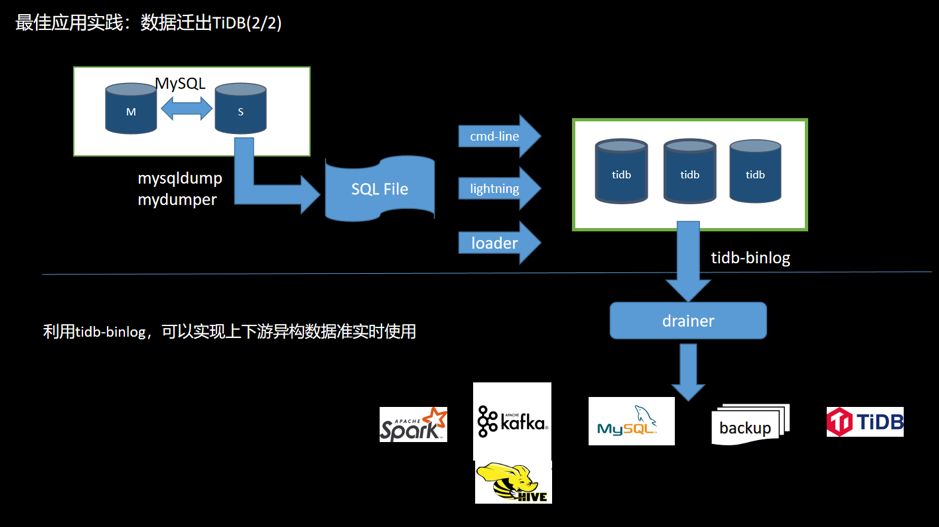
图 15 数据迁出 TiDB
数据同步:同步 TiDB 集群数据到其他数据库; 实时备份和恢复:备份 TiDB 集群数据,同时可以用于 TiDB 集群故障时恢复。
全量:TiDB 兼容 MySQL 协议,在 MySQL 容量足够大的情况下,也可用工具将数据从 TiDB 导出后再导入 MySQL。 增量:打开 TiDB 的 binlog 开关,部署 binlog 收集组件(Pump+Drainer),可以将 binlog 数据同步到下游存储架构(MySQL、TiDB、Kafka、S3 等)。
4.5 优雅地「去分库分表」
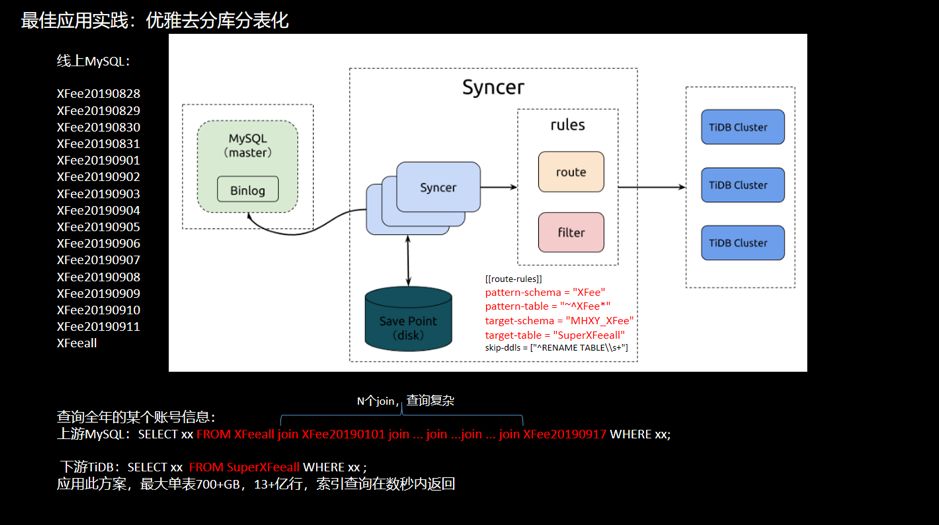
图 16 去分库分表举例
SELECT xx FROM HFeeall join HFee20190101 join ... join ...join ... join HFee20190917 WHERE xx;
SELECT xx FROM SuperHfeeall WHERE xx ;
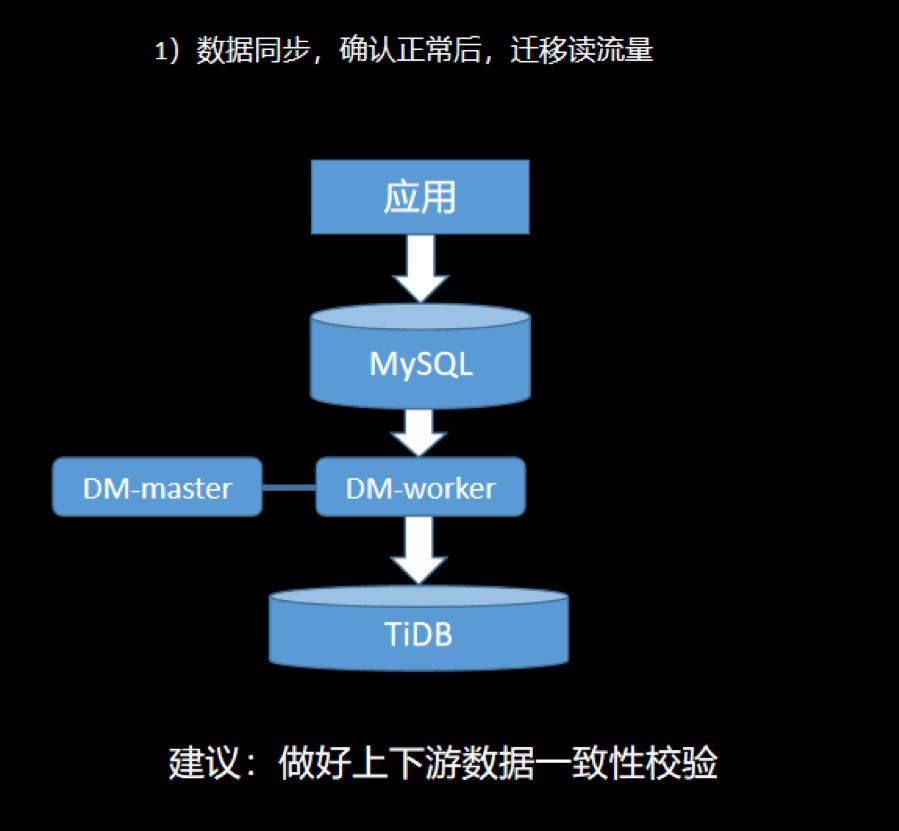
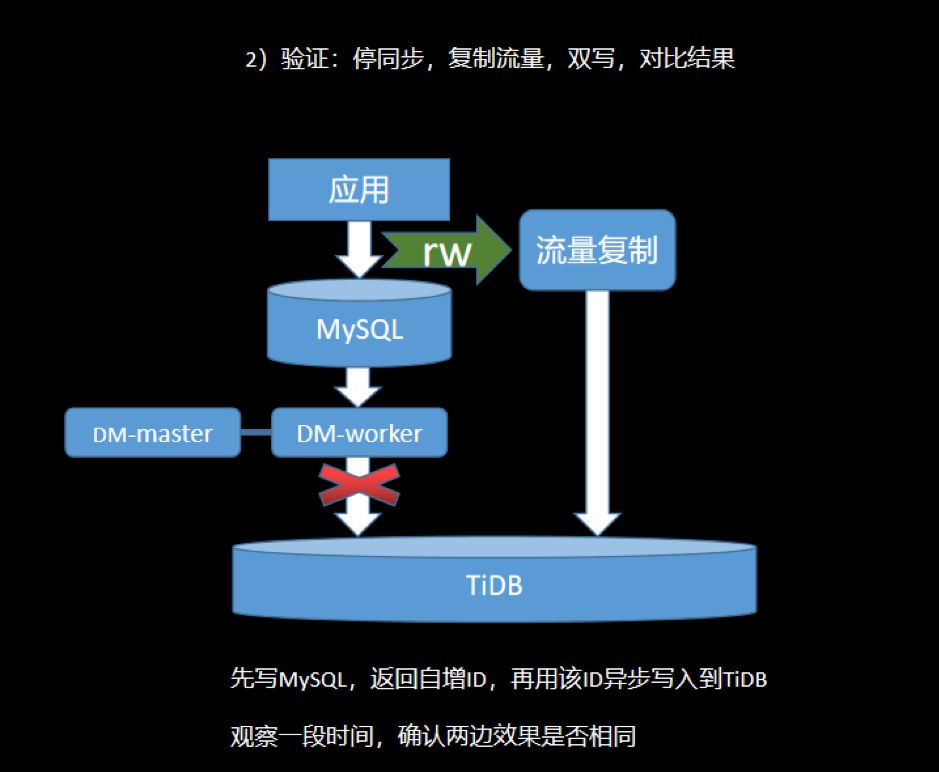
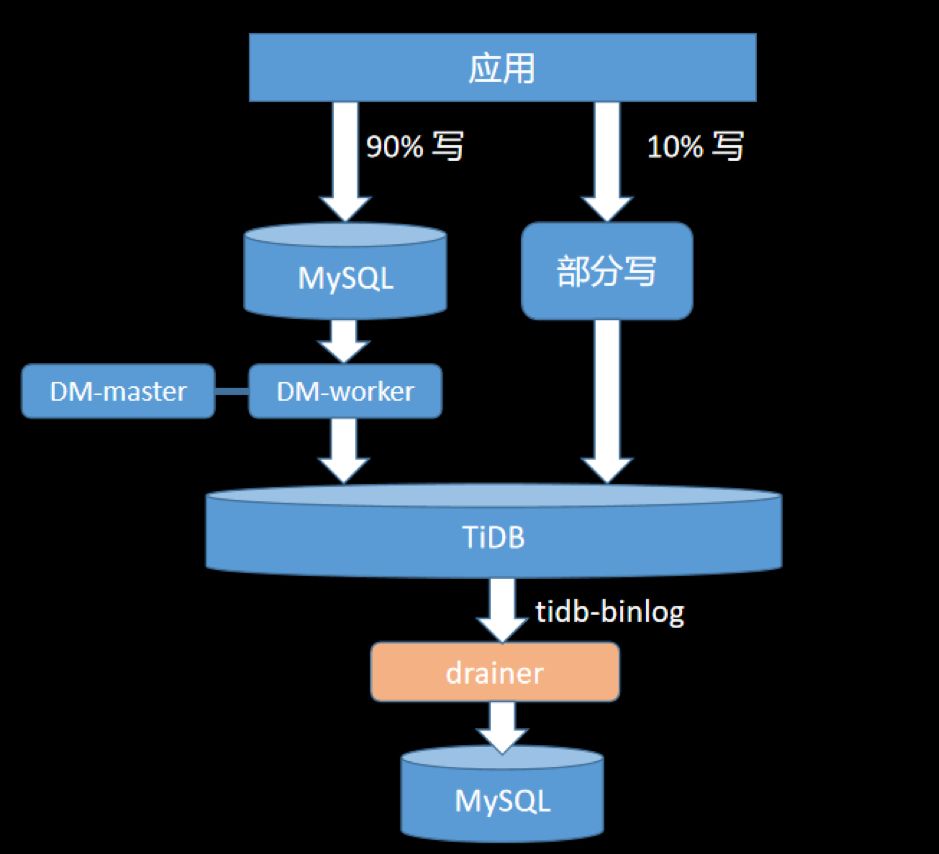
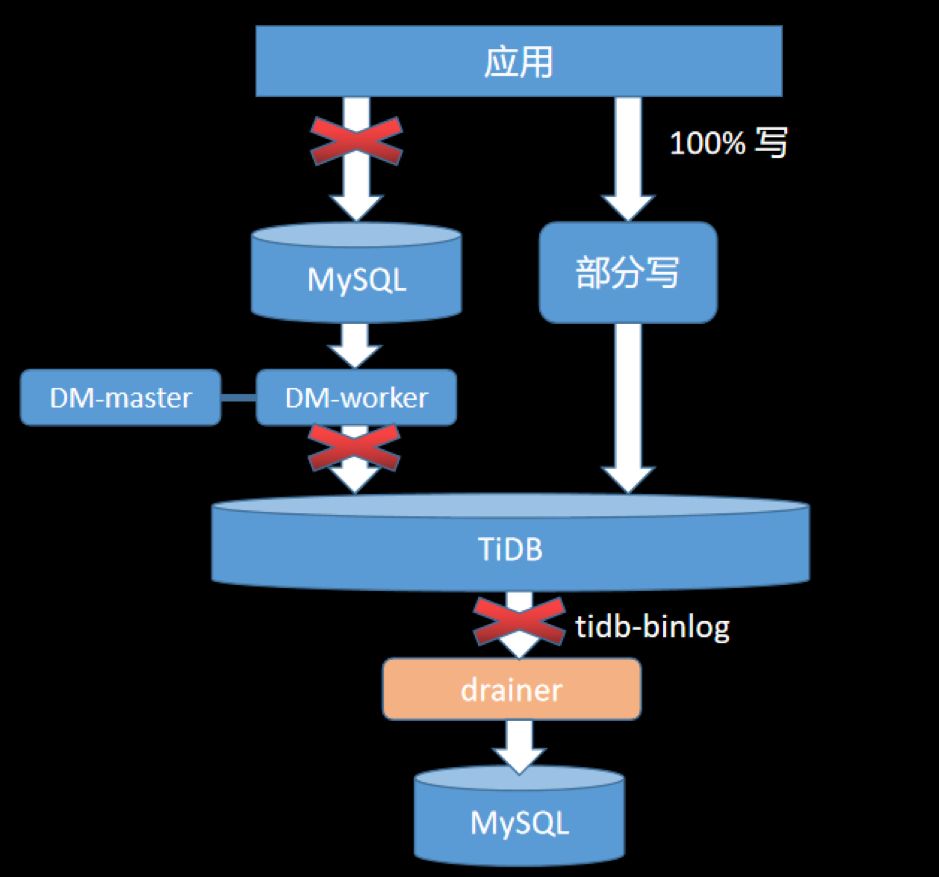
4.6 业务迁移
数据完整和准确:数据很重要,保证数据不错、不丢; 迁移平滑和迅速:服务敏感度高,停服时间要短; 可回滚:遇到问题可随时切回到 MySQL。
五、总结与展望
集群数据备份:希望提供集群更高效地备份和恢复 SST 文件的方式; 事务限制:希望可以放宽大事务的限制,现在仍需要人工切分大事务,比较复杂; 同步:希望 DM 支持上下游表结构不一致的同步; 数据热点问题:建议加强自动检测和清除热点功能; 客户端重试:目前客户端代码需要封装重试逻辑,对用户不友好,希望可以改进。

评论