
数据提取之JSON与JsonPATH
点击上方“IT共享之家”,进行关注
回复“资料”可获赠Python学习福利
蜡烛有心还惜别,替人垂泪到天明。
背景介绍
我们知道再爬虫的过程中我们对于爬取到的网页数据需要进行解析,因为大多数数据是不需要的,所以我们需要进行数据解析,常用的数据解析方式有正则表达式,xpath,bs4,这次我们来介绍一下另一个数据解析库--jsonpath,在此之前我们需要先了解一下什么是json。
一、初识Json
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,它使得人们很容易的进行阅读和编写。同时也方便了机器进行解析和生成。适用于进行数据交互的场景,比如网站前台与后台之间的数据交互。
Python 2.7及之后版本,自带了JSON模块,直接import json就可以使用了。
官方文档:http://docs.python.org/library/json.html
Json在线解析网站:http://www.json.cn/#
二、Json的基本使用
简介
json简单说就是javascript中的对象和数组,所以这两种结构就是对象和数组两种结构,通过这两种结构可以表示各种复杂的结构;
对象:对象在js中表示为
{ }括起来的内容,数据结构为{ key:value, key:value, ... }的键值对的结构,在面向对象的语言中,key为对象的属性,value为对应的属性值,所以很容易理解,取值方法为 对象.key 获取属性值,这个属性值的类型可以是数字、字符串、数组、对象这几种。数组:数组在js中是中括号
[ ]括起来的内容,数据结构为["Python", "javascript", "C++", ...],取值方式和所有语言中一样,使用索引获取,字段值的类型可以是 数字、字符串、数组、对象几种。
使用
json模块提供了四个功能:dumps、dump、loads、load,用于字符串 和 python数据类型间进行转换。
把Json格式字符串解码转换成Python对象 从json到python的类型转化对照如下:
| JSON | Python |
|---|---|
| object | dict |
| array | list |
| string | unicode |
| number(int) | int,long |
| number(real) | float |
| true(false) | True(False) |
| null | None |
1.json.loads()
import jsonstrDict = '{"city": "广州", "name": "小黑"}'r = json.loads(strDict) # json数据自动按Unicode存储print(r)
结果如下:
{'city': '广州', 'name': '小黑'}
2. json.load()
读取文件中json形式的字符串元素 转化成python类型
import jsons = json.load(open('test.json','r',encoding='utf-8'))print(s,type(s))
结果如下:
{'city': '广州', 'name': '小黑'}
3. json.dumps()
实现python类型转化为json字符串,返回一个str对象 把一个Python对象编码转换成Json字符串
import jsonlistStr = [1, 2, 3, 4]dictStr = {"city": "北京", "name": "大猫"}s1 = json.dumps(listStr)s2 = json.dumps(dictStr,ensure_ascii=False)print(s1,type(s1))print(s2)
结果如下:
[1, 2, 3, 4]
{"city": "北京", "name": "大猫"}
注意:
json.dumps() 序列化时默认使用的ascii编码
添加参数 ensure_ascii=False 禁用ascii编码,按utf-8编码
4. json.dump()
将Python内置类型序列化为json对象后写入文件
import jsonjson_info = "{'age': '12'}"file = open('ceshi.json','w',encoding='utf-8')json.dump(json_info,file)
结果如下:
ceshii,json(目录文件产生)
三、JsonPath
JsonPath 是一种信息抽取类库,是从JSON文档中抽取指定信息的工具,提供多种语言实现版本,包括:Javascript, Python, PHP 和 Java。
JsonPath 对于 JSON 来说,相当于 XPATH 对于 XML。
下载地址:https://pypi.python.org/pypi/jsonpath
安装方法:点击
Download URL链接下载jsonpath,解压之后执行python setup.py install官方文档:http://goessner.net/articles/JsonPath
JsonPath与XPath语法对比
Json结构清晰,可读性高,复杂度低,非常容易匹配,下表中对应了XPath的用法。
| XPath | JSONPath | 描述 |
|---|---|---|
/ | $ | 根节点 |
. | @ | 现行节点 |
/ | .or[] | 取子节点 |
.. | n/a | 取父节点,Jsonpath未支持 |
// | .. | 就是不管位置,选择所有符合条件的条件 |
* | * | 匹配所有元素节点 |
@ | n/a | 根据属性访问,Json不支持,因为Json是个Key-value递归结构,不需要。 |
[] | [] | 迭代器表示(可以在里边做简单的迭代操作,如数组下标,根据内容选值等) |
| | | [,] | 支持迭代器中做多选。 |
[] | ?() | 支持过滤操作. |
| n/a | () | 支持表达式计算 |
() | n/a | 分组,JsonPath不支持 |
四、案例测试
我们爬取淘票票官网的城市信息,保存为json文件,进行jsonpath语法测试,获取所有城市名称。
请求
import requestsimport timeurl = 'https://dianying.taobao.com/cityAction.json?activityId&_ksTS=1632211792156_137&jsoncallback=jsonp138&action=cityAction&n_s=new&event_submit_doGetAllRegion=true'headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36',}res = requests.get(url,headers=headers)result = res.content.decode('utf-8')print(result) # xxx省略
注意:
headers里面的键值对最好都加上,还是有反爬的,该网站,这里为了简便省去了;
保存数据
content = result.split('(')[1].split(')')[0] # 由于文件首尾的字符不需要需要剔除掉做字符串切割with open('tpp.json','w',encoding='utf-8')as fp:fp.write(content)
打开json文件如下所示:

解析数据
这里我们获取全部城市名称
import jsonimport jsonpathobj = json.load(open('tpp.json','r',encoding='utf-8')) # 注意,这里是文件的形式,不能直接放一个文件名的字符串city_list = jsonpath.jsonpath(obj,'$..regionName') # 文件对象 jsonpath语法print(city_list)
结果如下:
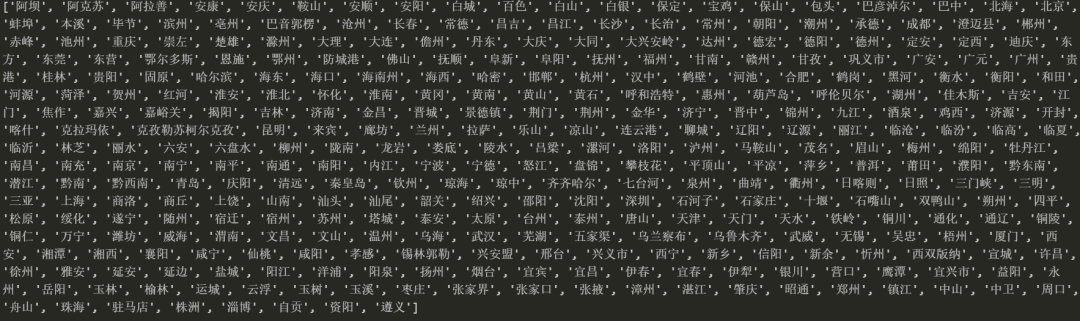
五、总结
我们知道json是一种常见的数据传输形式,所以对于爬取数据的数据解析,json的相关操作是比较重要的,能够加快我们的数据提取效率,本文简单介绍了json和jsonpath的相关操作,对于测试网站(淘票票)的json做了简单的数据解析,感兴趣的小伙伴可以把其他数据解析一下。
看完本文有收获?请转发分享给更多的人
IT共享之家
入群请在微信后台回复【入群】
------------------- End -------------------
往期精彩文章推荐: