
从拉普拉斯矩阵说到谱聚类
日期 : 2021年10月01日
正文共 :3381字
1、拉普拉斯矩阵
1.1 、Laplacian matrix的定义
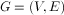 ,其拉普拉斯矩阵被定义为:
,其拉普拉斯矩阵被定义为: 为图的度矩阵,
为图的度矩阵, 为图的邻接矩阵。
为图的邻接矩阵。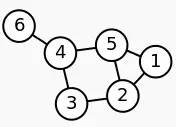 :
: 的每一列元素加起来得到
的每一列元素加起来得到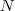 个数,然后把它们放在对角线上(其它地方都是零),组成一个
个数,然后把它们放在对角线上(其它地方都是零),组成一个 的对角矩阵,记为度矩阵,如下图所示:
的对角矩阵,记为度矩阵,如下图所示:
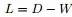 ,可得拉普拉斯矩阵
,可得拉普拉斯矩阵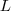 为:
为:
1.2、 拉普拉斯矩阵的性质
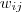 定义为节点
定义为节点 到节点
到节点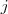 的权值,如果两个节点不是相连的,权值为零。
的权值,如果两个节点不是相连的,权值为零。②与某结点邻接的所有边的权值和定义为该顶点的度d,多个d 形成一个度矩阵
(对角阵) 具有如下性质:- 是对称半正定矩阵;
 ,即 的最小特征值是0,相应的特征向量是
,即 的最小特征值是0,相应的特征向量是 。证明: * = ( - ) * = 0 = 0 * 。(此外,别忘了,之前特征值和特征向量的定义:若数字
。证明: * = ( - ) * = 0 = 0 * 。(此外,别忘了,之前特征值和特征向量的定义:若数字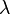 和非零向量
和非零向量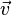 满足
满足 ,则为
,则为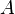 的一个特征向量,是其对应的特征值)。
的一个特征向量,是其对应的特征值)。- 有n个非负实特征值
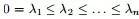
且对于任何一个属于实向量
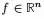 ,有以下式子成立
,有以下式子成立
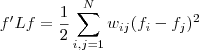 ,
,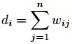 ,
,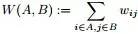 。
。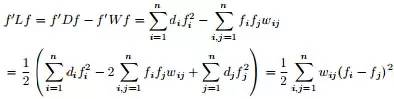
2、谱聚类
cut/Ratio Cut
Normalized Cut
不基于图,而是转换成SVD能解的问题
2.1、 相关定义
无向图
,顶点集V表示各个样本,带权的边表示各个样本之间的相似度与某结点邻接的所有边的权值和定义为该顶点的度d,多个d 形成一个度矩阵
(对角阵)
邻接矩阵
,A子图与B子图之间所有边的权值之和定义如下: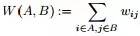
其中,
定义为节点到节点的权值,如果两个节点不是相连的,权值为零。
相似度矩阵的定义。相似度矩阵由权值矩阵得到,实践中一般用高斯核函数(也称径向基函数核)计算相似度,距离越大,代表其相似度越小。
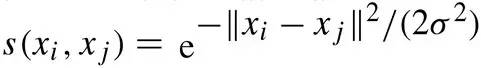
子图A的指示向量如下:
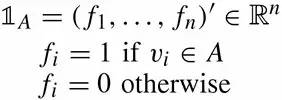
2.2、 目标函数
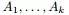 为图的几个子集(它们没有交集) ,为了让分割的Cut 值最小,谱聚类便是要最小化下述目标函数:
为图的几个子集(它们没有交集) ,为了让分割的Cut 值最小,谱聚类便是要最小化下述目标函数: 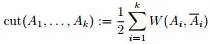
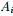 表示第i个组,
表示第i个组,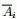 表示 的补集,
表示 的补集,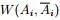 表示第 组与第组之间的所有边的权重之和(换言之,如果要分成K个组,那么其代价就是进行分割时去掉的边的权值的总和)。
表示第 组与第组之间的所有边的权重之和(换言之,如果要分成K个组,那么其代价就是进行分割时去掉的边的权值的总和)。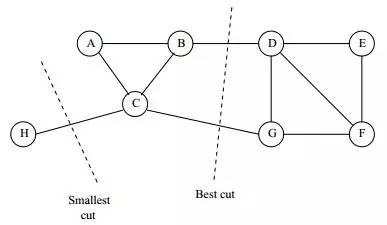
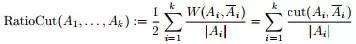
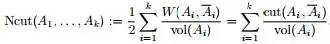
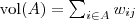 。
。2.3、最小化RatioCut 与最小化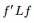 等价
等价
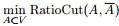
定义向量
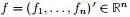 ,且:
,且: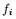 的定义式代入上式,我们将得到一个非常有趣的结论!推导过程如下:
的定义式代入上式,我们将得到一个非常有趣的结论!推导过程如下: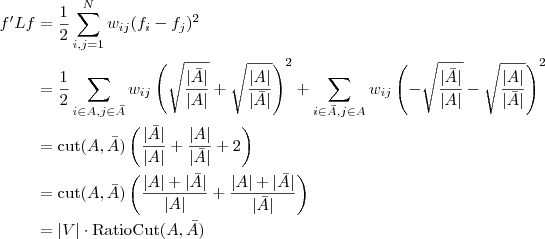 推出了RatioCut,换句话说,拉普拉斯矩阵L 和我们要优化的目标函数RatioCut 有着密切的联系。更进一步说,因为
推出了RatioCut,换句话说,拉普拉斯矩阵L 和我们要优化的目标函数RatioCut 有着密切的联系。更进一步说,因为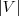 是一个常量,所以最小化RatioCut,等价于最小化。的各个元素全为1,所以直接展开可得到约束条件:
是一个常量,所以最小化RatioCut,等价于最小化。的各个元素全为1,所以直接展开可得到约束条件: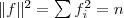 且
且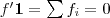 ,具体推导过程如下:
,具体推导过程如下: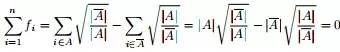
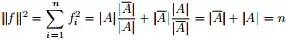 ,写成:
,写成:
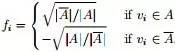 ,且因
,且因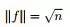 ,所以有:f'f = n(注:f是列向量的前提下,f'f是一个值,实数值,ff'是一个N*N的矩阵)。
,所以有:f'f = n(注:f是列向量的前提下,f'f是一个值,实数值,ff'是一个N*N的矩阵)。若数字
和非零向量满足,则为的一个特征向量,是其对应的特征值。
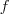 = ,此刻,是特征值, 是 的特征向量。两边同时左乘
= ,此刻,是特征值, 是 的特征向量。两边同时左乘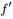 ,得到 = ,而f'f=n,其中n为图中顶点的数量之和,因此 = n,因n是个定值,所以要最小化,相当于就是要最小化。因此,接下来,我们只要找到 的最小特征值及其对应的特征向量即可。最小的特征值为零,并且对应的特征向量正好为”可知:其不满足
,得到 = ,而f'f=n,其中n为图中顶点的数量之和,因此 = n,因n是个定值,所以要最小化,相当于就是要最小化。因此,接下来,我们只要找到 的最小特征值及其对应的特征向量即可。最小的特征值为零,并且对应的特征向量正好为”可知:其不满足 的条件,因此,怎么办呢?根据论文“A Tutorial on Spectral Clustering”中所说的Rayleigh-Ritz 理论,我们可以取第2小的特征值,以及对应的特征向量
的条件,因此,怎么办呢?根据论文“A Tutorial on Spectral Clustering”中所说的Rayleigh-Ritz 理论,我们可以取第2小的特征值,以及对应的特征向量 。 里的元素是连续的任意实数,所以可以根据 是大于0,还是小于0对应到离散情况下的,决定 是取
。 里的元素是连续的任意实数,所以可以根据 是大于0,还是小于0对应到离散情况下的,决定 是取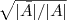 ,还是取
,还是取 。而如果能求取 的前K个特征向量,进行K-means聚类,得到K个簇,便从二聚类扩展到了K 聚类的问题。很困难,但RatioCut 巧妙地把一个NP难度的问题转换成拉普拉斯矩阵特征值(向量)的问题,将离散的聚类问题松弛为连续的特征向量,最小的系列特征向量对应着图最优的系列划分方法。剩下的仅是将松弛化的问题再离散化,即将特征向量再划分开,便可以得到相应的类别。不能不说妙哉!
。而如果能求取 的前K个特征向量,进行K-means聚类,得到K个簇,便从二聚类扩展到了K 聚类的问题。很困难,但RatioCut 巧妙地把一个NP难度的问题转换成拉普拉斯矩阵特征值(向量)的问题,将离散的聚类问题松弛为连续的特征向量,最小的系列特征向量对应着图最优的系列划分方法。剩下的仅是将松弛化的问题再离散化,即将特征向量再划分开,便可以得到相应的类别。不能不说妙哉!2.4、谱聚类算法过程
根据数据构造一个Graph,Graph的每一个节点对应一个数据点,将各个点连接起来(随后将那些已经被连接起来但并不怎么相似的点,通过cut/RatioCut/NCut 的方式剪开),并且边的权重用于表示数据之间的相似度。把这个Graph用邻接矩阵的形式表示出来,记为
。把
的每一列元素加起来得到个数,把它们放在对角线上(其他地方都是零),组成一个的对角矩阵,记为度矩阵,并把 - 的结果记为拉普拉斯矩阵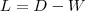 。
。求出
的前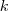 个特征值(前个指按照特征值的大小从小到大排序得到)
个特征值(前个指按照特征值的大小从小到大排序得到)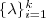 ,以及对应的特征向量
,以及对应的特征向量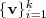 。
。把这
个特征(列)向量排列在一起组成一个 的矩阵,将其中每一行看作维空间中的一个向量,并使用 K-means 算法进行聚类。聚类的结果中每一行所属的类别就是原来 Graph 中的节点亦即最初的个数据点分别所属的类别。
的矩阵,将其中每一行看作维空间中的一个向量,并使用 K-means 算法进行聚类。聚类的结果中每一行所属的类别就是原来 Graph 中的节点亦即最初的个数据点分别所属的类别。

— THE END —
