
实时性迷思——实战RTOS多任务性能分析

【说在前面的话】
当前实时性任务所消耗的CPU资源百分比为:

这里的

就是“事件n”的CPU资源占用。
如果对细节还不清楚的小伙伴,可以单击这里。这里我们假设你已经对这个公式的基本原理了然于心。
/*! demo of __cycleof__() operation */__cycleof__() {printf("Hello world\r\n");}
start_cycle_counter(); {printf("Hello world\r\n");}int32_t cycles = stop_cycle_counter();
简单直观。

【如何测量一个任务的系统占用】
static void task_a (void *argument){...while (1) {uint32_t wTick = osKernelGetTickCount();any_workload(); // 我们用这个函数来模拟任意的功能代码// 该任务尝试以 20 ms(50Hz) 为“稳定”间隔,周期性的执行osDelayUntil(wTick + 20);}}
只要任务负载所消耗的时间小于20s,则该任务就能以给定的周期稳定的重复执行。这是借助了 osDelayUntil 的特性。
如果该任务具有实时性,则实时性窗口就是任务的重复周期——在这个例子中就是 20ms。
以固定时间间隔进行LCD刷新
以固定时间间隔扫描矩阵键盘
以固定时间间隔闪烁LED
以固定时间间隔读取传感器的值
……
static void task_a (void *argument){...while (1) {int32_t cycle_used;start_cycle_counter();//! 以下是原来的要测量的代码,我们打包起来不动它们{uint32_t wTick = osKernelGetTickCount();any_workload(); // 我们用这个函数来模拟任意的功能代码// 该任务尝试以 20 ms(50Hz)为“稳定”间隔,周期性的执行osDelayUntil(wTick + 20);}// 读取结果cycle_used = stop_cycle_counter();//! 把 cycle_used转化成毫秒,并保存在 cpu_usage里float cpu_usage = (float)cycle_used / (float)(SystemCoreClock / 1000ul);//! 计算CPU占用的百分比cpu_usage = (cpu_usage / 20.0f) * 100.0f;}}
在一次循环开始的时候,利用 perf_counter 所提供的函数 start_cycle_counter() 来开启CPU性能计数器;
在循环结束后,通过 stop_cycle_counter() 来读取计数器结果;
将测量结果转化为毫秒后,与任务周期(实时性窗口)相除,计算出该任务的CPU占用率。
但这里有个小瑕疵:osDelayUntil() 执行期间,当前任务其实是处于挂起状态——RTOS会进行任务调度,在该任务休眠期间执行别的任务——因此,不应该把这一期间的CPU周期数记录到最终结果里。实际上,正是因为这样的原因,上述代码的测量结果将始终是 100%——简直测了个寂寞。
static void task_a (void *argument){...while (1) {int32_t cycle_used;start_cycle_counter();//! 以下是原来的要测量的代码,我们打包起来不动它们{uint32_t wTick = osKernelGetTickCount();any_workload(); // 我们用这个函数来模拟任意的功能代码// 读取结果cycle_used = stop_cycle_counter();// 该任务尝试以 20 ms(50Hz)为“稳定”间隔,周期性的执行osDelayUntil(wTick + 20);}//! 把 cycle_used转化成毫秒,并保存在 cpu_usage里float cpu_usage = (float)cycle_used / (float)(SystemCoreClock / 1000ul);//! 计算CPU占用的百分比cpu_usage = (cpu_usage / 20.0f) * 100.0f;}}


static void task_a (void *argument){init_task_cycle_counter();...while (1) {int64_t cycle_used;start_task_cycle_counter();//! 以下是原来的要测量的代码,我们打包起来不动它们{uint32_t wTick = osKernelGetTickCount();any_workload(); // 我们用这个函数来模拟任意的功能代码// 该任务尝试以 20 ms(50Hz)为“稳定”间隔,周期性的执行osDelayUntil(wTick + 20);}// 读取结果cycle_used = stop_task_cycle_counter();//! 把 cycle_used转化成毫秒,并保存在 cpu_usage里float cpu_usage = (float)cycle_used / (float)(SystemCoreClock / 1000ul);//! 计算CPU占用的百分比cpu_usage = (cpu_usage / 20.0f) * 100.0f;}}
能不能不需要用户自己提供任务的实时性窗口信息啊
能不能少写点代码啊
能不能自己计算结果啊
能不能计算 n 次的平均结果啊
……

static void task_a (void *argument){init_task_cycle_counter();...__super_loop_monitor__(100) {uint32_t wTick = osKernelGetTickCount();any_workload(); // 我们用这个函数来模拟任意的功能代码// 该任务尝试以 20 ms(50Hz) 为“稳定”间隔,周期性的执行osDelayUntil(wTick + 20);}}

在任务开头处加了一个 init_task_cycle_counter() 对当前任务的CPU计数器进行了初始化;
将 while(1) 换成了 __super_loop_monitor__(100)——这里的100表示将100次测量结果进行平均
那结果呢?结果输出在哪里?答案是:
默认情况下,测量结果会通过 printf 打印出来,类似这样:
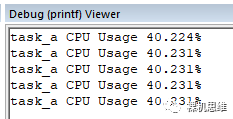
如果你不想使用printf进行打印,而是想读取测量的结果,则可以通过下面的代码来实现:
static void task_a (void *argument){init_task_cycle_counter();int64_t cycle_used;int64_t time_elapsed;__super_loop_monitor__(100, {cycle_used = __cpu_usage__.lTaskUsedCycles;time_elapsed = __cpu_usage__.lTimeElapsed;}) {uint32_t wTick = osKernelGetTickCount();any_workload(); // 我们用这个函数来模拟任意的功能代码// 该任务尝试以 20 ms(50Hz) 为“稳定”间隔,周期性的执行osDelayUntil(wTick + 20);}}
__super_loop_monitor__(<平均多少次输出结果>,{//任意的代码片断,其中可以通过匿名结构体 __cpu_usage__// 来读取所需的结果}) {// 任务的超级循体}
int64_t cycle_used;int64_t time_elapsed;__super_loop_monitor__(100,{cycle_used = __cpu_usage__.lTaskUsedCycles;time_elapsed = __cpu_usage__.lTimeElapsed;}) {...}
将100次测量所经过的总周期数保存在 time_elapsed 中;
将任务在100次循环过程中实际使用的周期数保存在 cycle_used 中;
借助这两个变量,我们就可以自己计算CPU系统占用啦。
【重要的使用注意事项】
每个任务默认都拥有一个CPU性能计数器,它们彼此独立,互不干扰。
不要忘记在任务一开头用 init_task_cycle_counter() 对其进行初始化。
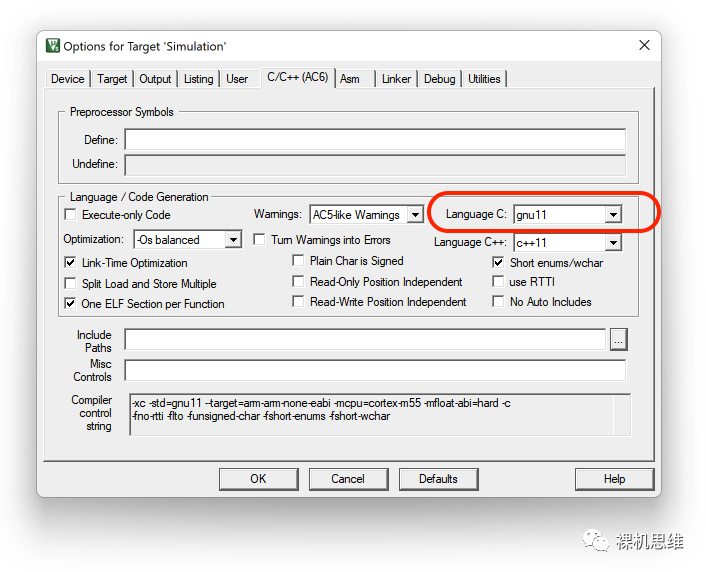
__super_loop_monitor__() 依赖 GNU 扩展,一定要在编译器选项中打开哦。
比如 Arm Compiler 6(armclang)中要把 Language C设置为 gnu99或者 gnu11:
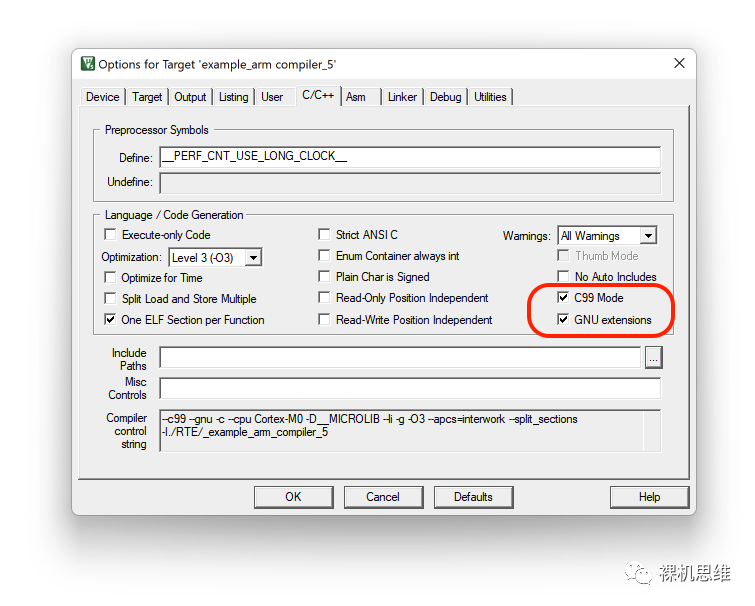
在 Arm Compiler 5(armcc)中要选择 C99和GNU extensions选项:
如果你的MDK中找不到上述两个选项,则说明你的MDK版本太低了,推荐升级。你可以在关注公众号【裸机思维】后发送关键字"MDK"或者通过菜单获取最新的MDK网盘链接。
如果一个任务并非是以稳定的周期进行执行的,而是完全取决于信号量来进行挂起和唤醒的,也可以使用 __super_loop_monitor__() 配合一个较大的基数(比如1000或者10000)来获取一个较为可信的平均结果。
使用 __super_loop_monitor__() 或者 xxxx_task_cycle_counter() 函数所测量的结果是任务的“净”周期数。因此,即便它的值恒定小于实时性窗口,也只能说明任务本身执行时间“有潜力”满足实时性要求,但“根本不足以”证明一个任务的实时性得到了满足——因为“任务净周期”加上抢占或者轮转到其它任务执行所消耗的时间可能就超过实时性窗口要求了。要想测量一个任务是否满足实时性要求,还是要用普通版本的 start_cycle_counter() 、stop_cycle_counter()和 __cycleof__()之类传统的手段进行测量。
【perf_counter和RTOS补丁的部署】
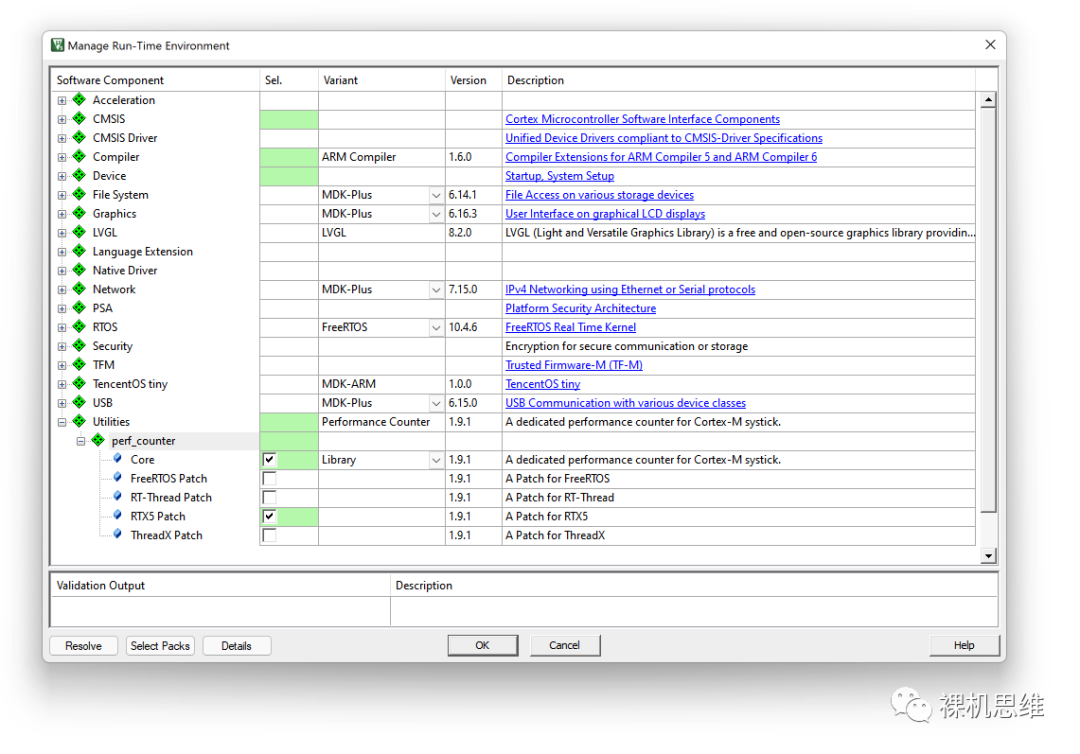
可以看到, perf_counter支持了目前市面上比较主流的一些RTOS。目前,对列表中的大部分RTOS来说,勾选对应的patch就完成了对应的支持。
【ThreadX的注意事项】
你需要打开工程配置,跳转到 Asm界面,在Misc Controls中追加如下的命令行选项:
-include "Pre_Include_Global.h"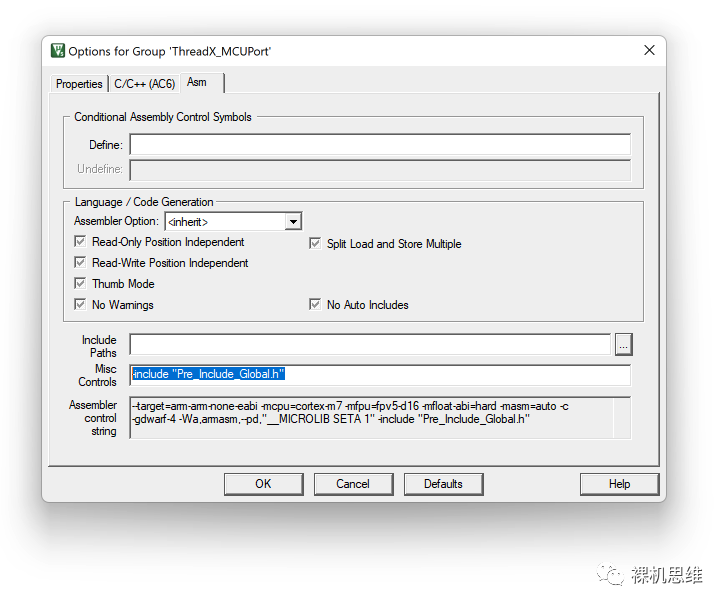
此外,目前 perf_counter的ThreadX补丁仅在 Arm Compiler 6(armclang)下有效,对于Arm Compiler 5(armcc)的用户来说,我尽力了……但很抱歉。
【RTX的注意事项】
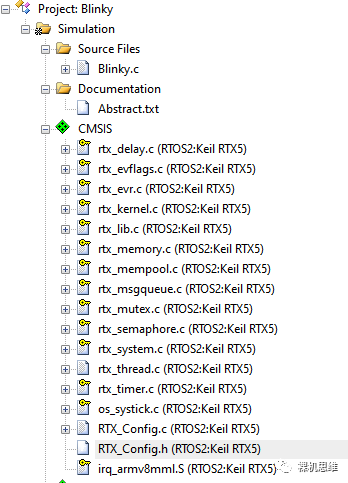
去除 stack overrun checking的勾选
去除 stack usage watermark的勾选
将 Processor mode for Thread execution 设置为 Privileged mode(否则会触发hardfault)
【其它注意事项】
1、需要特别说明的是:如果你使用的 RTOS 是使用 library 的形式部署的,请切换回 Source形式。
这是由于 Patch 所附着的一些 RTOS调度器函数可能会在 Library中以 inline 的形式存在——无法被我们的Patch附着——只有以Source源代码形式进行编译,Compiler才能意识到不能在这些关键的函数身上耍小聪明。
2、由于 perf_counter 是在每个任务的栈底消耗 48个字节作为CPU计数器,因此请务必关闭RTOS的栈溢出检测功能——因为这 48个字节显然破坏了水印,会导致栈溢出的误判。此外,perf_counter提供了额外的水印,如果你发现48个字节的最后4字节不是 0xDEADBEEF或者0x8492A53C,则说明发生了栈溢出。
3、由于 perf_counter 的API要访问 SysTick寄存器,因此请务必在配置RTOS的任务时,让其工作在特权模式下——如果RTOS任务工作在非特权模式下,任何针对SysTick寄存器的访问都将触发Hardfault。
【说在后面的话】
很多 RTOS 自带的计数器是32位的,无法在系统高频率的情况下,提供长时间的统计,而 perf_counter 的计数器是64位的;
perf_counter允许用户实现跨越多个任务的测量,这对测量一个涉及多个任务的数据流的系统性能消耗非常——限于篇幅,我们将在下一期文章中着重介绍。
‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧ END ‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧
关注我的微信公众号,回复“加群”按规则加入技术交流群。
点击下面图片,有星球具体介绍,新用户有新人优惠券,老用户半价优惠,期待大家一起学习一起进步。
点击“阅读原文”查看更多分享,欢迎点分享、收藏、点赞、在看。