
自动驾驶中的3D物体状态检测
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

摘要
3D物体检测是自动驾驶的一项重要技术,KITTI提供了一种用于训练和评估不同的3D对象检测器的性能的标准化数据集。在这里,我们使用来自KITTI的数据来总结和突出3D对象检测方案中的优劣,这些方案通常可以分为使用LIDAR和使用LIDAR + Image(RGB)。
激光雷达
CNN用于2D对象检测和分类的机器已经成熟。但是,用于自动驾驶的3D对象检测带来至少两个独特的挑战:
与RGB图像不同,LIDAR点云是3D的并且是非结构化的。
自动驾驶的3D检测必须快速(<〜100ms)。
几个3 d的检测方法已通过离散化LIDAR点云成3D体素网格和解决的第一个问题中应用3D卷积。但是,与2D卷积相比,3D卷积具有更大的计算成本并因此具有更高的延迟。或者,可以在自顶向下的鸟瞰图(BEV)或激光雷达的本机范围视图(RV)中将点云投影到2D图像。优点是可以通过更快的2D卷积有效地处理投影图像,从而降低延迟。
我们从KITTI BEV中选择了一些方法,以突出显示RV,BEV和在体素功能上运行的方法之间的一些优劣。该图显示了检测器延迟(ms)与车辆AP的关系:

检测器(仅LIDAR)延迟与车辆AP
可得到如下结果:
BEV投影保留了物体的大小和距离,为学习提供了强大的先决条件。
Z轴被视为2D卷积的特征通道。
地面高度可用于展平Z轴上的点(例如HDNet),从而减轻由于道路坡度而引起的平移差异的影响。
具有学习功能(PointNet)的BEV可以整合Z轴,从而获得强大的性能。
SECOND通过体素特征编码层和稀疏卷积来实现此目的;
SECOND(v1.5)的新版本报告了更好的AP(86.6%)和低延迟(40ms)。
PointPillars在Z轴支柱上应用了简化的PointNet,从而产生了2D BEV图像,该图像被馈送到2D CNN中。
RV投影会因距离而发生遮挡和物体大小变化。
在KITTI的7.5k帧序列数据集上, RV检测器(例如LaserNet)的性能落后于BEV检测器。
但是, LaserNet在1.2M帧ATG4D数据集上的性能与BEV检测器 (例如HDNet)相当。
RV投影具有低延迟(例如LaserNet),这可能是由于相对于稀疏BEV的RV表示密集。
VoxelNet率先使用了体素功能,但由于3D卷积而遭受高延迟。
较新的方法(例如SECOND)可以使用相同的体素特征编码层,但是避免使用稀疏卷积来减少延迟的3D卷积。
激光雷达+RGB
LIDAR + RGB融合改善了3D检测性能,特别是对于LIDAR数据经常稀疏的较小物体(例如行人)或远距离(>50m-70m)而言。下面总结了一些融合方法。基于提议的方法以RGB(例如F-Pointnet)或BEV(例如MV3D)生成对象提议。密集融合方法将LIDAR和RGB特征直接融合到一个普通的投影中,并且通常以各种分辨率进行融合。
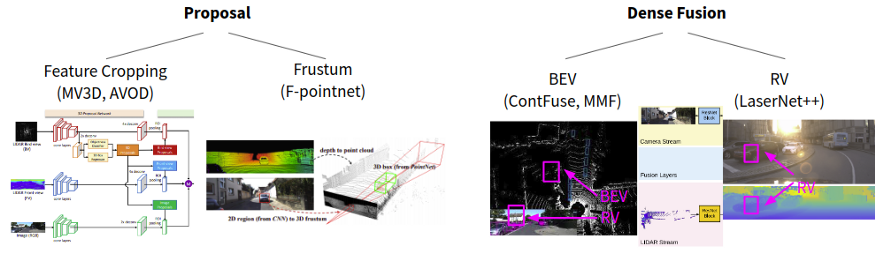
LIDAR + RGB融合的一般方法。图像改编自MV3D(Chen等人,2016),F-Pointnet(Qi等人,2017),ContFuse(Liang等人,2018)和LaserNet(Meyer等人,2018)。
该图显示了相对于车辆AP的延迟(ms):
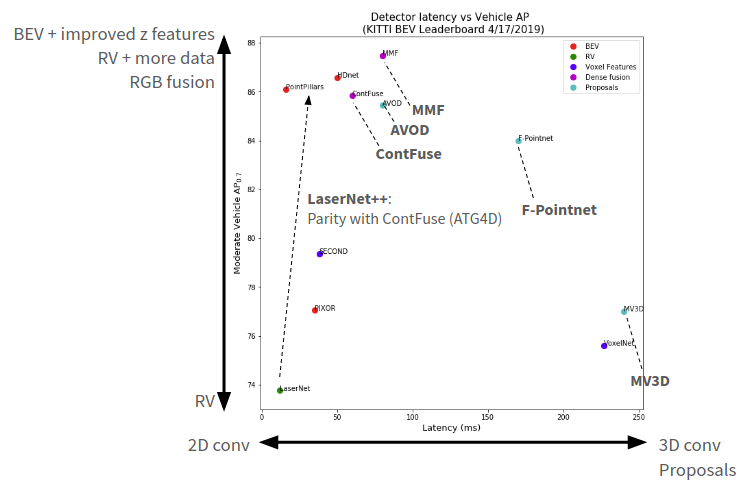
检测器(带有LIDAR + RGB融合标记)的延迟与车辆AP的关系
得到如下结果:
RV密集融合具有所有方法中最低的延迟,并且基于提议的方法通常比密集融合具有更高的延迟。由于RGB和LIDAR功能都在RV中,因此RV密集融合(例如LaserNet ++)速度很快。LIDAR特征可以直接投影到图像中进行融合。相比之下, ContFuse确实BEV密集的融合。它从RGB特征生成BEV特征图,并与LIDAR BEV特征图融合。这具有挑战性,因为并非BEV中的所有像素都能在RV中观察到 RGB图像。几个步骤可以解决这个问题。例如,一个未观察到的BEV像素,将提取附近的K个LIDAR点。计算每个点与目标BEV像素之间的偏移。将这些点投影到RV以检索相应的RGB特征。偏移量和RGB特征被馈送给连续卷积,该连续卷积在RGB特征之间进行插值以在目标BEV像素处生成未观察到的特征。对所有BEV像素完成此操作,生成RGB特征的密集插值BEV贴图。
通常,在LIDAR稀疏的情况下以及在小物体上,融合方法的性能增益最高。相对于LIDAR(LaserNet),LIDAR + RGB特征融合(LaserNet ++)的AP改进在车辆上是适度的(0-70m时为+1%AP),但在较小的类别上尤其是较大范围时。LaserNet ++在ATG4D上具有很强的性能,但未体现其KITTI性能。
总结
在BEV和RV预测之间需要权衡取舍。BEV保留度量空间,使对象大小相对于范围保持一致。相反,RV在范围和遮挡方面受尺度变化的影响。其结果是,BEV检测器(例如,PointPillars)实现优越的性能RV(例如,LaserNet)上小的数据集(例如,在KITTI 7.5K帧)具有相似的延迟(例如,对于16ms的PointPillars VS 12ms的用于LaserNet)。但是,RV性能与BEV相当在较大的数据集(例如1.2M帧ATG4D)上。尽管存在此缺点,但RV中的密集特征融合比BEV更快。LaserNet ++报告令人印象深刻的潜伏期(38MS)和比性能更好致密BEV融合检测器(例如,ContFuse在60ms的)。这些对比总结在下图中。新的LIDAR + RGB融合架构可以利用每个投影仪的优势,找到在投影之间移动的方法。
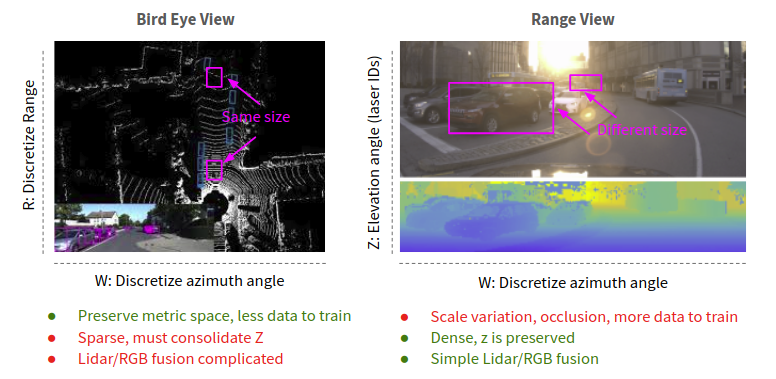
RV和BEV预测之间的对比
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~