
谈一谈分布式系统中数据的安全和性能

在分布式系统中,我们知道CAP定理和BASE理论,数据的安全和性能是负相关的,数据的安全性提高了,那他的性能就会下降,相关,他的性能提高了,数据的安全性就会下降。我们从几个中间件来讨论这个问题。
mysql
当mysql性能出现瓶颈时,我们会做分库分表、读写分离等,读写分离需要我们做主从复制,对读的操作,我们指向从库,对写的操作,我们指向主库,下面看看主从复制的原理。
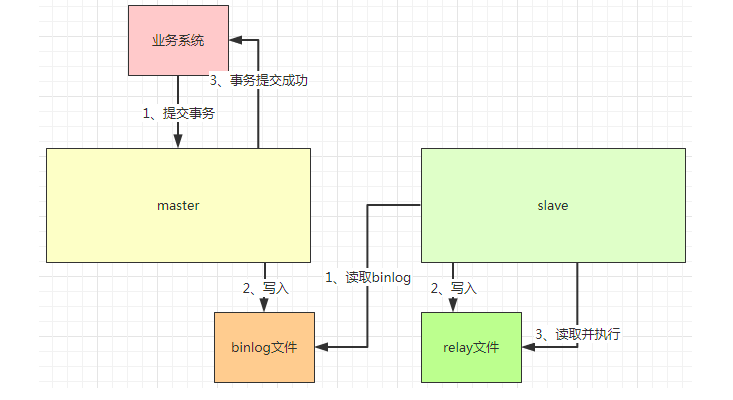
当业务系统提交数据的时候,master会将这变更的数据保存到binlog文件,写入成后,事务提交成功。
slave中会有一个线程,他会从master中读取binlog信息,然后写入relay文件。然后他还会有其他线程,读取relay文件的信息,把这个信息重新在slave库执行一遍。也就是说,如果在master中执行了一个update的语句,那在slave中同样也执行一模一样的update语句,这样两边的数据就会保持一致,由于master先执行,然后slave再执行,所以会有稍微的延迟。如果执行的语句比较久,那这个延时也会比较长,当然系统的压力也会影响延迟的时间。
除了延时以外,他还有一个比较大的问题,当写入binlog后,代表事务提交成功,此时master挂了,导致slave没办法读取这部分的binlog,所以就会出现数据的丢失,两边的数据就没办法保持一致性,所以我们通常会把上面的异步复制形式设置半同步复制,也就是semi-sync。
半同步复制与异步复制不同的是,当master写入到binlog后,他会主动的把数据同步到从库,从库把信息写入到relay文件,会返回ACK给master,此时master才会认为他的事务是提交的。
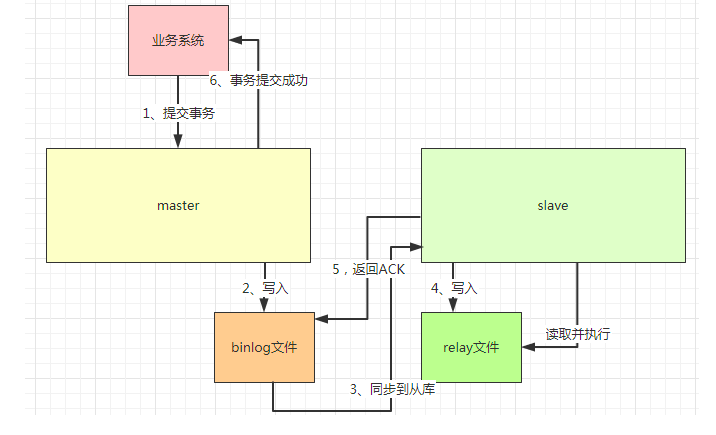
如果有多个slave的情况,则至少返回1个ACK才认为事务的提交的。半同步复制虽然解决了数据安全的问题,但是他需要从库写入relay文件并返回ACK才算提交事务,与异步复制对比,他的性能是下降的。
单体
在单体中,也同样存在着数据安全和性能的负相关问题。
这里简述一下mysql对update语句的一个流程。
当执行update的时候,会先从磁盘里把数据读取到缓存。
写入undo文件,这里是在我们事务回滚的时候用的。
修改缓存数据,比如把id为1的name由张三改为李四。
写入redo缓存,redo主要是为了宕机重启时,恢复数据用的。
写入redo缓存后,写入到磁盘。
写入binlog文件。
写入binlog后,提交commit给redo,跟redo说已经写入到binlog了。
定期把缓存的数据写入到磁盘。
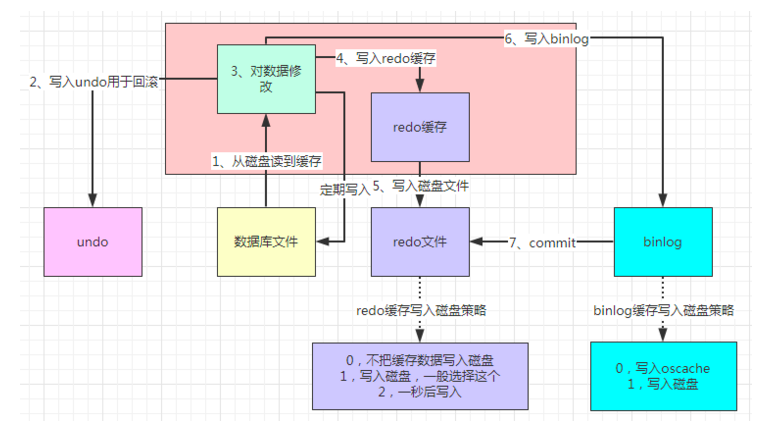
我们对数据的更新,都是在缓存中进行的,这样可以保证性能的提高。同时为了数据的安全性,还引入了undo、redo、binlog等东西。我们可以看redo和binlog两种写入磁盘的策略。
在redo中,我们可以选择0,即不把缓存数据写入磁盘,这样可以快速执行完redo操作,如果此时宕机了,还没写入磁盘的数据就丢失了,虽然提高了性能,但是数据安全性没有了。如果选择1,由于要写入磁盘才可以完成redo操作,虽然保证了数据的安全性,但是性能却下降了。
同样的,binlog写入oscache是提高了性能,但是服务器宕机会导致oscache的数据不能及时的写入磁盘,导致数据的安全性没有。如果直接写入磁盘,性能又下降。
redis
与mysql已有,redis的复制也是异步复制的,当业务系统往master写入数据的时候,他就会通过异步复制的方式把数据同步给slave,所以和mysql类似,当业务系统认为他已经把数据写入到redis的时候,此时master挂了,但是数据还没同步到slave,他的数据就丢失了。
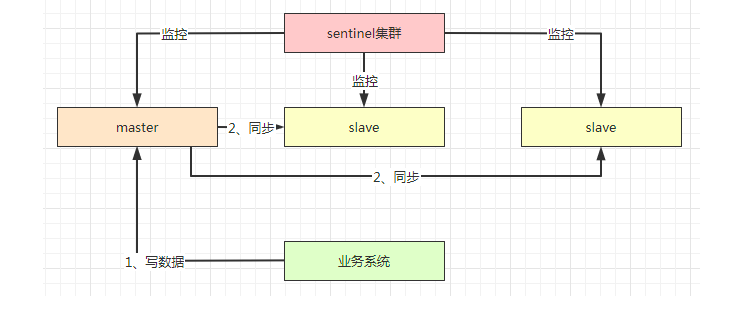
另外一个场景,就是发生了脑裂,也就是sentinel认为master挂了,然后重新选举了master,此时业务系统和master是正常通讯的,他把数据提交到原master节点,但是原master节点的数据此时是没办法同步到其他节点,导致数据不一致。
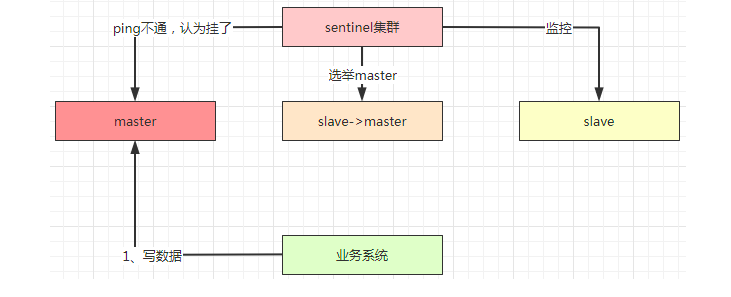
在这情况下,我们会做以下配置:
min-replicas-to-write 1
min-replicas-max-lag 10这个意思是至少有1个slave已经有10秒没有同步,则master暂停接收请求。所以不会说master一直写入数据,而slave没有同步。如果发生以上两个场景,最多丢失10秒的数据。虽然没有严格的做到数据安全性,但是也保证了数据的不一致性不会超过10秒,超过10秒后,由于不能写数据,写性能下降为0。
RocketMQ
我们看看基于Dledger是怎么做broker同步的。
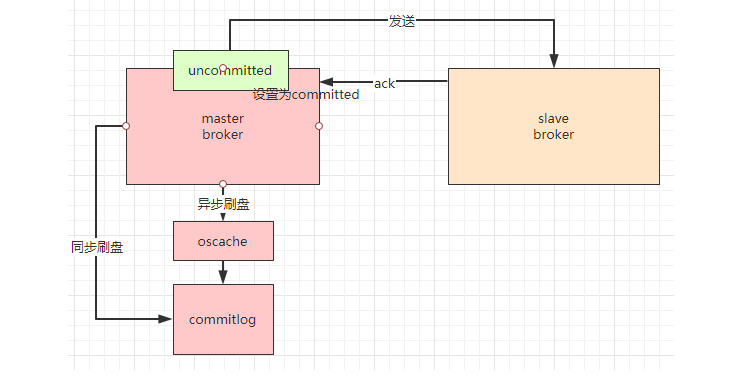
首先,master broker收到消息后,会把这个消息置为unconmmited状态,然后把这个消息发送给slave broker,slave broker收到消息后,会发送ack进行确认,如果有多个slave broker,当超过一半的slave broker发送ack时,master broker才会把这个消息置为committed状态。在这种机制下,保证了数据的安全性,当master broker挂了,我们还有至少超过一半的slave broker的数据是完整的,由于需要多个slave broker进行ack确认,也降低了性能。
从单体上来说,异步刷盘和同步刷盘跟mysql的redo写入磁盘的一样的。
另外,kafka的同步机制跟这个类似,而且他也有写入oacache的操作。
Zookeeper
Zookeeper是CP模型的,那他的数据安全性是可以保证的,那他的性能呢?我们假设此时master节点挂了,此时需要重新选主,这个时候Zookeeper集群是不可用状态的。那Zookeeper是如何保证数据的一致性呢?
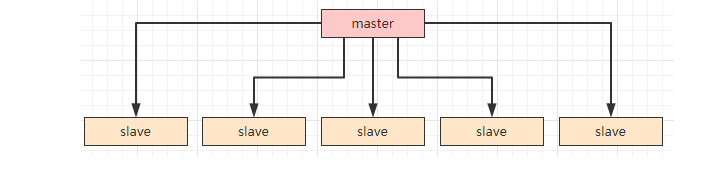
我们假设master同步给5个slave。
当master不用确认是否已经同步给slave就直接返回,这个时候性能是最高的,但是安全性是最低的,因为master数据没同步到slave的时候挂了,那这个数据是丢失的。
当master确认已经同步给所有slave(这里是5个)才返回,这个时候,性能是最低的,但是安全性是最高的,因为不管哪个slave,他的数据都是完整的。
不管是RocketMQ还是Zookeeper,都是折中选择超过一半的slave同步,才算成功。当我们访问Zookeeper的时候,他会根据已经同步好的slave服务器让我们来读取对应的信息,这样我们读取的数据肯定都是最新的。
来源:
https://segmentfault.com/a/1190000039422422相关推
推荐阅读:
不是你需要中台,而是一名合格的架构师(附各大厂中台建设PPT)