先从一个问题开始:Java中的ArrayList是线程安全的吗?
大家都知道是线程不安全的,那么问题来了,你如何去证明它是线程不安全的呢?那好,写个例子吧:
public static void main(String[] args) { List list = new ArrayList();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
list.add(5);
System.out.println(list);
}
OK,以上是热个身,既然要证明线程不安全,那就得需要多个线程去操作啊,那继续:
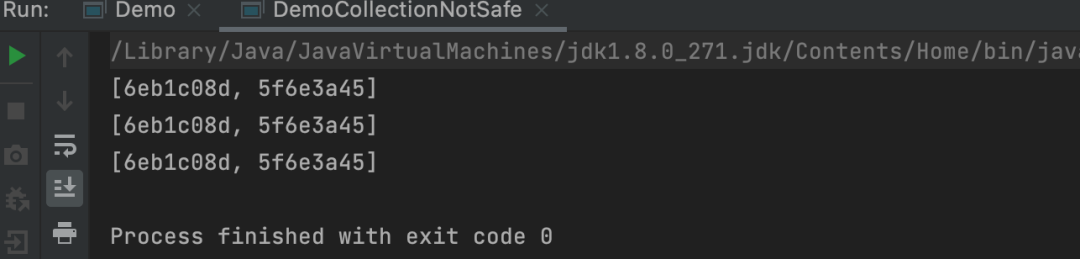
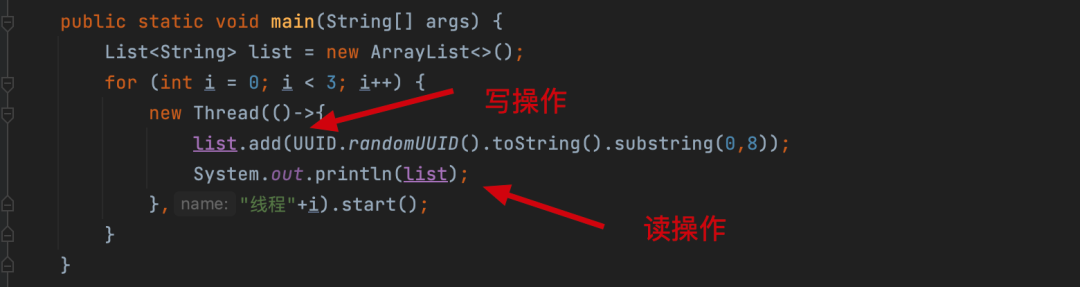
public static void main(String[] args) { List<String> list = new ArrayList<>();
for (int i = 0; i < 3; i++) { new Thread(()->{ list.add(UUID.randomUUID().toString().substring(0,8));
System.out.println(list);
},"线程"+i).start();
}
}
OK,代码改写完成,那这样会出现什么样的问题呢?运行看看呗:咋样,结果是不是很是丰富多彩啊,为什么?给你看个图:另外有个很重要的知识点,请问,多线程start开启之后,他们是顺序执行还是乱序执行?答案是乱序执行,而且执行速度很快,那这就产生问题了,比如1线程还没有写,2线程就读了,或者1和3线程都写了,2线程才读……所以,结果是丰富多彩的!
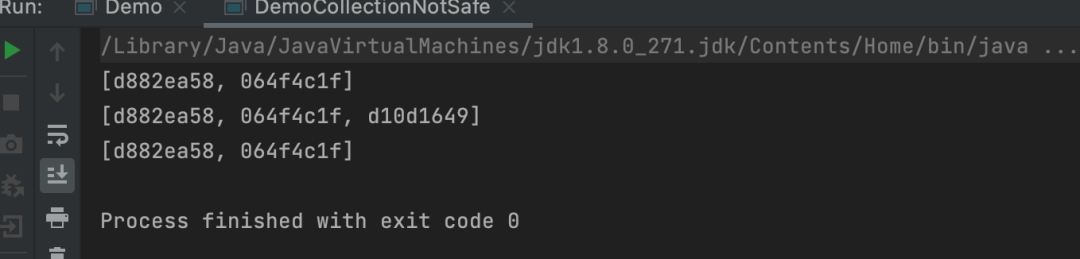
public static void main(String[] args) { List<String> list = new ArrayList<>();
for (int i = 0; i < 30; i++) { new Thread(()->{ list.add(UUID.randomUUID().toString().substring(0,8));
System.out.println(list);
},"线程"+i).start();
}
}
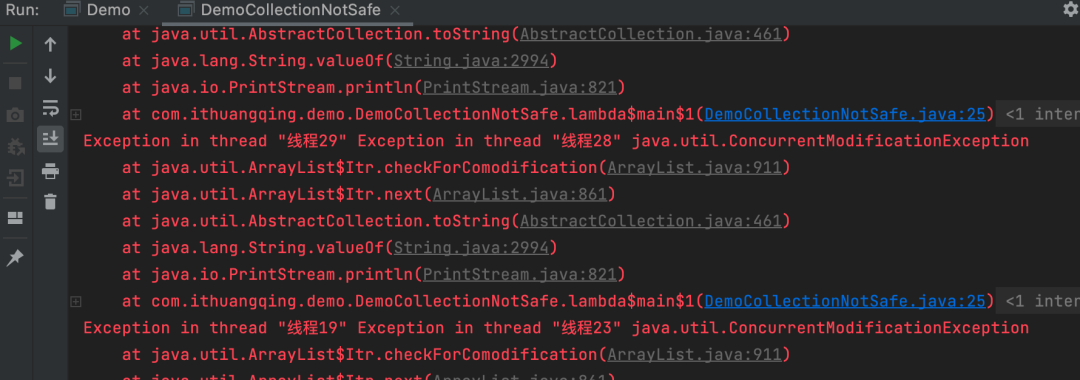
看到区别没?这里开启30个线程,请问,程序会报错吗?⚠️这是因为ArrayList是线程不安全的,当比较多的线程去同时对其进行快速读写的时候,它就会发生崩溃导致并发修改异常
解决方案一:替换vector
这个时候你能想到怎么做吗?加锁?可以,但是不用你自己加锁,因为有vector,还记得这货吗?
public static void main(String[] args) { List<String> list = new Vector<>();
for (int i = 0; i < 30; i++) { new Thread(()->{ list.add(UUID.randomUUID().toString().substring(0,8));
System.out.println(list);
},"线程"+i).start();
}
}
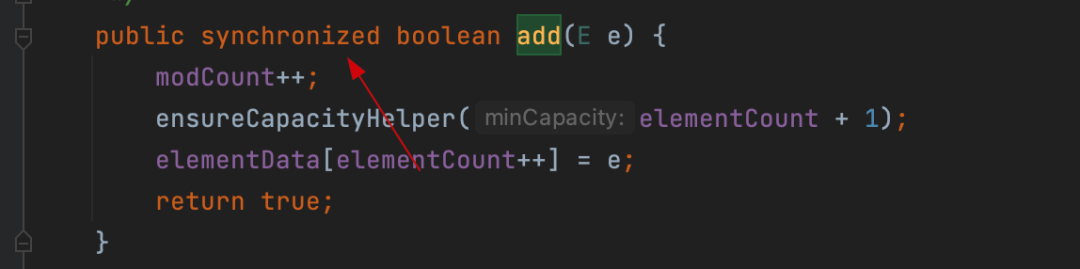
看到没,它的add上增加了synchronized,所以Vector是线程安全的,但是不要用它,为啥?虽然不推荐用这种,但是使用Vector的确可以解决并发修改的异常,程序运行看下:解决方案二:Collections
public static void main(String[] args) { List<String> list = Collections.synchronizedList(new ArrayList<>());
for (int i = 0; i < 30; i++) { new Thread(()->{ list.add(UUID.randomUUID().toString().substring(0,8));
System.out.println(list);
},"线程"+i).start();
}
}
Collections.synchronizedList(new ArrayList<>());
将线程不安全的list变成线程安全的list,但是这样的方式依然不推荐,原因还是一样的,就是性能受到影响!所以,尽管此种方式可以解决并发修改异常,但是依然不推荐!我们上面说的使用Vector或者集合工具类的形式,这些都是同步容器,就是通过加锁的形式,比如Vector的add方法:这里是加上了synchronized,如此一来,同一个时间只能有一个线程来访问,那这样的话,的确保证了数据的读取一致性,但是效率也就下降了!那对于使用集合工具类的形式来说,其实也可以用,为什么不推荐使用呢?因为作为一个看起来很牛逼的程序员,我们有更好的选择,那就使用到并发容器!解决方案三:写时复制
public static void main(String[] args) { List<String> list = new CopyOnWriteArrayList<>();
for (int i = 0; i < 30; i++) { new Thread(()->{ list.add(UUID.randomUUID().toString().substring(0,8));
System.out.println(list);
},"线程"+i).start();
}
}
就是这个CopyOnWriteArrayList,记住了,以后就用这个!
看到没,首先人家就是Java并发包里面的,所以人家是专门针对并发的,那么在效率和性能上绝对比其他的强!那这个CopyOnWriteArrayList为什么就那么强呢?原理是啥?我们从字面意思去看啥是CopyOnWrite,是不是“复制在写”???好啦,人家其实叫做“写时复制”,是读写分离思想的一种,高就高在这,我们来看看具体是咋回事!原理初探
啥叫做写时复制,啥又是CopyOnWrite,说实话,看起来很高大上,其实思想很简单,首先明确这里要达成的一个效果:如此一来读写就是被分离开来的,保证了数据一致性的同时也保证的效率,那是怎么做的,重点就在这个“copy”上,啥?复制啊,也就是说,在对一个资源进行读写的时候,假如一个线程在进行写操作,那么这个时候它就获得相应的锁,此时是不允许其他线程去进行写操作的,但是其他线程可以进行读操作,也就是你该写写,不耽误别人的读操作,而且重点就是,这个线程在写的这个数据不是原数据而是拷贝的原数据,也就是把原数据拷贝一份拿来进行写操作,而原数据还在供其他线程读!此时,读写就分离开来了,一旦这个线程的写操作完成,那此时这个数据就是最新的数据,这时就会把原来的那个原数据给干掉,只保留写之后的这个数据!这就是写时复制,就是CopyOnWriteArrayList神秘面纱之后的真相!源代码
明白了简单的原理之后,我们看看源代码!首先看下其底层数据类型:看到没,依旧是一个Object数组,但是容量为0!接下里去看add的方法:
Object[] newElements = Arrays.copyOf(elements, len + 1);
当你增加一个元素的时候,底层数据就扩容1来容纳你增加的这个元素,然后会得到新的数组并覆盖掉原来的数组!小总结
OK,以上就是写时复制CopyOnWriteArrayList的一个介绍,下面进行简单的小总结,所谓的CopyOnWriteArrayList我们一般叫它为写时复制的容器,既然是容器那就是装载数据的,通过后面的ArrayList我们也不应该觉得很陌生,这家伙就是对我们熟知的ArrayList进行增强!当你往CopyOnWriteArrayList中去添加容器的时候,不是立马就往其底层数组中去添加,而是先把底层的数组复制一份,往复制的这份里面去添加,添加完成之后就把原有的数组给覆盖掉,这样一来,就可以实现单个写,多个读,在进行数据添加的时候因为是对原数组的拷贝的数组进行写操作,这个是加锁的,但是对原数组的读是不加锁的,可以实现并发的读,这样,性能效率就都有了!







 下载APP
下载APP