
前端高级进阶:网站的缓存控制策略最佳实践及注意事项
对于一个网站来讲,性能关乎用户体验,你在更短的时间内打开网站,你将会留住更多的用户。如果你的页面十秒才能打开,那再好的用户交互也是徒然。
缓存控制是网站性能优化中至为常见及重要的一环,好的缓存控制,除了使网站在性能方面有所提升,在财务方面也有重要提升: 更好的缓存策略意味着更少的请求,更少的流量,更少的峰值带宽,从而节省一大笔服务器或者 CDN 的费用。
缓存控制策略就是 http caching 的策略,化繁为简,最有效的策略往往是很简单的。在最简单的粗略下,你对 http cache 只需要了解一个 Cache-Control 的头部。
一个较好的缓存策略只需要两部分,而它们只需要通过 Cache-Control 控制:
- 带指纹资源: 永久缓存
- 非带指纹资源: 每次进行新鲜度校验
作图如下:
 缓存控制策略
缓存控制策略带指纹资源: 永久缓存
Cache-Control: max-age=31536000
天下武功,无坚不摧,唯快不破。资源请求最快的方式就是不向服务器发起请求,通过以上响应头可以对资源设置永久缓存。
- 静态资源带有 hash 值,即指纹
- 对资源设置一年过期时间,即 31536000,一般认为是永久缓存
- 在永久缓存期间浏览器不需要向服务器发送请求
那为什么带有 hash 值的资源可以永久缓存呢?
因为该文件的内容发生变化时,会生成一个带有新的 hash 值的 URL。 前端将会发起一个新的 URL 的请求。
非带指纹资源: 每次进行新鲜度校验
Cache-Control: no-cache
- 由于不带有指纹,每次都需要校验资源的新鲜度。(从缓存中取到资源,可能是过期资源)
- 如果校验为最新资源,则从浏览器的缓存中加载资源
index.html 为不带有指纹资源,如果把它置于缓存中,则如何保证服务器刷新数据时,被浏览器可以获取到新鲜的资源?
因此,使用 Cache-Control: no-cache 时,客户端每次对服务器进行新鲜度校验。
PS:no-cache 与 no-store 的区别是什么?
即使每次校验新鲜度,也不需要每次都从服务器下载资源: 如果浏览器/CDN上缓存经校验没有过期。这被称为协商缓存,此时 http 状态码返回 304,指 Not Modified,即没有变更。
幸运的是,关于协商缓存,你无需管理,也无需配置, nginx 或者一些 OSS 都会自动配置协商缓存。
而对于协商缓存,也有它们自己的算法,协商缓存的背后基于响应头 Last-Modified/ETag。浏览器每次请求资源时,会携带上次服务器响应的 ETag/Last-Modified 作为标志,与服务端此时的 ETag/Last-Modified 作比较,来判断内容更改。
http 响应头中的 ETag 值是如何生成的?
而在操作系统底层,Last-Modified 往往通过文件系统(file system)中的 mtime 属性生成。而 ETag 提供比 Last-Modified 更精细的检验粒度,由文件内容的 hash 或者 mtime/size 生成。当然,这是后话。
一定要为你的资源添加 Cache-Control 响应头
我会经常接触到一些网站,他们的资源文件并没有 Cache-Control 这个响应头。究其原因,在于缓存策略配置这个工作的职责不清,有时候它需要协调前端和运维。
那如果不添加 Cache-Control 这个响应头会怎么样?
是不是每次都会自动去服务器校验新鲜度,很可惜,不是。此时会对资源进行强制缓存,而对不带有指纹信息的资源很有可能获取到过期资源。 如果过期资源存在于浏览器上,还可以通过强制刷新浏览器来获取最新资源。但是如果过期资源存在于 CDN 的边缘节点上,CDN 的刷新就会复杂很多,而且有可能需要多人协作解决。
那默认的强制缓存时间是多少
首先要明确两个响应头代表的含义:
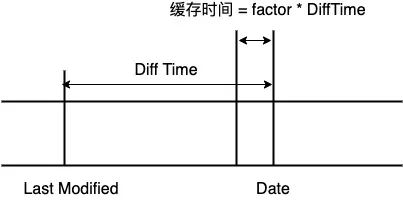
Date: 指源服务器响应报文生成的时间,差不多与发请求的时间等价Last-Modified: 指静态资源上次修改的时间,取决于mtime
LM factor 算法认为当请求服务器时,如果没有设置 Cache-Control,如果距离上次的 Last-Modified 越远,则生成的强制缓存时间越长。
用公式表示如下,其中 factor 介于 0 与 1 之间:
MaxAge = (Date - LastModified) * factor
 LM factor
LM factorBundle Splitting:尽量减少资源变更
得益于单页应用与前端工程化的发展,经过打包后,基本上所有资源都是带有指纹信息的,这意味着所有的资源都是能够设置永久缓存。打包策略如下图所示:
缓存控制策略但仅仅如此了吗?
如果你所有的 js 资源都打包成一个文件,它确实有永久缓存的优势。但是当有一行文件进行修改时,这一个大包的指纹信息发生改变,永久缓存失效。
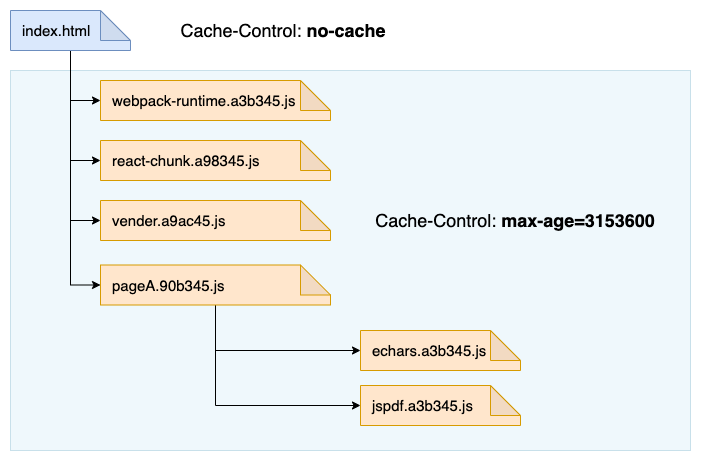
所以我们现在需要做到的是:当修改文件后,造成最小范围的缓存失效。webpack 等打包工具虽然在 optimization 上内置了很多性能优化,但它不会帮你做这件事,这件事情需要自己动手。
 缓存控制策略
缓存控制策略此时我们可以对资源进行分层次缓存的打包方案,这是一个建议方案:
webpack-runtime: 应用中的webpack的版本比较稳定,分离出来,保证长久的永久缓存react/react-dom:react的版本更新频次也较低vendor: 常用的第三方模块打包在一起,如lodash,classnames基本上每个页面都会引用到,但是它们的更新频率会更高一些。另外对低频次使用的第三方模块不要打进来pageA: A 页面,当 A 页面的组件发生变更后,它的缓存将会失效pageB: B 页面echarts: 不常用且过大的第三方模块单独打包mathjax: 不常用且过大的第三方模块单独打包jspdf: 不常用且过大的第三方模块单独打包
随着 http2 的发展,特别是多路复用,初始页面的静态资源不受资源数量的影响。因此为了更好的缓存效果以及按需加载,也有很多方案建议把所有的第三方模块进行单模块打包。
小结
缓存控制策略本篇文章地址在 前端工程化系列,欢迎订阅。
推荐阅读
我的公众号能带来什么价值?(文末有送书规则,一定要看)
每个前端工程师都应该了解的图片知识(长文建议收藏)
为什么现在面试总是面试造火箭?