
如何组装一个注册中心?
hello,大家好呀,我是小楼。今天不写BUG,来聊一聊注册中心。
标题本来想叫《如何设计一个注册中心》,但网上已经有好多类似标题的文章了。所以打算另辟蹊径,换个角度,如何组装一个注册中心。
组装意味着不必从0开始造轮子,这也比较符合许多公司对待自研基础组件的态度。
知道如何组装一个注册中心有什么用呢?
第一可以更深入理解注册中心。以我个人经历来说,注册中心的第一印象就是Dubbo的Zookeeper(以下简称zk),后来逐渐深入,学会了如何去zk上查看Dubbo注册的数据,并能排查一些问题。后来了解了Nacos,才发现,原来注册中心还可以如此简单,再后来一直从事服务发现相关工作,对一些细枝末节也有了一些新的理解。
第二可以学习技术选型的方法,注册中心中的每个模块,都会在不同的需求下有不同的选择,最终的选择取决于对需求的把握以及技术视野,但这两项是内功,一时半会练不成,学个选型的方法还是可以的。
本文打算从需求分析开始,一步步拆解各个模块,整个注册中心以一种如无必要,勿增实体的原则进行组装,但也不会是个玩具,向生产可用对齐。
当然在实际项目中,不建议重复造轮子,尽量用现成的解决方案,所以本文仅供学习参考。
需求分析
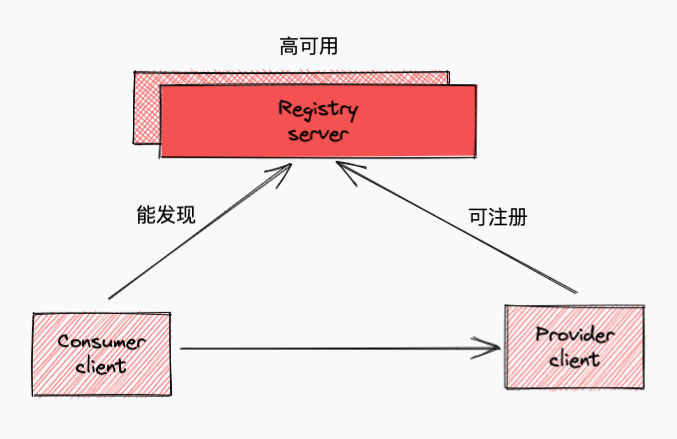
本文的注册中心需求很简单,就三点:可注册、能发现、高可用。
服务的注册和发现是注册中心的基本功能,高可用则是生产环境的基本要求,如果高可用不要求,那本文可讲解的内容就很少,上图中的高可用标注只是个示意,高可用在很多方面都有体现。
至于其他花里胡哨的功能,我们暂且不表。
我们这里介绍三个角色,后文以此为基础:
提供者(Provider):服务的提供方(被调用方) 消费者(Consumer):服务的消费方(调用方) 注册中心(Registry):本文主角,服务提供列表、消费关系等数据的存储方
接口定义
注册中心和客户端(SDK)的交互接口有三个:
注册(register),将服务提供方注册到注册中心 注销(unregister),将注册的服务从注册中心中删除 订阅(subscribe),服务消费方订阅需要的服务,订阅后提供方有变更将通知到对应的消费方
注册、注销可以是服务提供方的进程发起,也可以是其他的旁路程序辅助发起,比如发布系统在发布一台机器完成后,可调用注册接口,将其注册到注册中心,注销也是类似流程,但这种方式并不多见,而且如果只考虑实现一个注册中心,必然是可以单独运行的,所以通常注册、注销由提供方进程负责。
有了这三个接口,我们该如何去定义接口呢?注册服务到底有哪些字段需要注册?订阅需要传什么字段?以什么序列化方式?用什么协议传输?
这些问题接踵而来,我觉得我们先不急着去做选择,先看看这个领域有没有相关标准,如果有就参考或者直接按照标准实现,如果没有,再来分析每一点的选择。
服务发现还真有一套标准,但又不完全有。它叫OpenSergo,它其实是服务治理的一套标准,包含了服务发现:
OpenSergo 是一套开放、通用的、面向分布式服务架构、覆盖全链路异构化生态的服务治理标准,基于业界服务治理场景与实践形成通用标准规范。OpenSergo 的最大特点就是以统一的一套配置/DSL/协议定义服务治理规则,面向多语言异构化架构,做到全链路生态覆盖。无论微服务的语言是 Java, Go, Node.js 还是其它语言,无论是标准微服务还是 Mesh 接入,从网关到微服务,从数据库到缓存,从服务注册发现到配置,开发者都可以通过同一套 OpenSergo CRD 标准配置针对每一层进行统一的治理管控,而无需关注各框架、语言的差异点,降低异构化、全链路服务治理管控的复杂度。
官网:https://opensergo.io/
我们需要的服务注册与发现也被纳入其中:

说有但也不是完全有是因为这个标准还在建设中,服务发现相关的标准在写这篇文章的时候还没有给出。
既然没有标准,可以结合现有的系统以及经验来定义,这里我用json的序列化方式给出,以下为笔者的总结,不能囊括所有情形,需要时根据业务适当做一些调整:
服务注册入参
{
"application":"provider_test", // 应用名
"protocol":"http", // 协议
"addr":"127.0.0.1:8080", // 提供方的地址
"meta":{ // 携带的元数据,以下三个为示例
"cluster":"small",
"idc":"shanghai",
"tag":"read"
}
}
服务订阅入参
{
"subscribes":[
{
"provider":"test_provider1", // 订阅的应用名
"protocol":"http", // 订阅的协议
"meta":{ // 携带的元数据,以下为示例
"cluster":"small",
"idc":"shanghai",
"tag":"read"
}
},
{
"provider":"test_provider2",
"protocol":"http",
"meta":{
"cluster":"small",
"tag":"read"
}
}
]
}
服务发现出参
{
"version":"23des4f", // 版本
"endpoints":[ // 实例
{
"application":"provider_test",
"protocol":"http",
"addr":"127.0.0.1:8080",
"meta":{
"cluster":"small",
"idc":"shanghai",
"tag":"read"
}
},
{
"application":"provider_test",
"protocol":"http",
"addr":"127.0.0.2:8080",
"meta":{
"cluster":"small",
"idc":"shanghai",
"tag":"read"
}
}
]
}
变更推送 & 服务健康检查
有了定义,我们如何选择序列化方式?选择序列化方式有两个重要参考点:
语言的适配程度,比如 json 几乎所有编程语言都能适配。除非能非常确定5-10年内不会有多语言的需求,否则我还是非常建议你选择一个跨语言的序列化协议 性能,序列化的性能包含了两层意思,序列化的速度(cpu消耗)与序列化后的体积,设想一个场景,一个服务被非常多的应用订阅,如果此时该服务发布,则会触发非常庞大的推送事件,此时注册中心的cpu和网络则有可能被打满,导致服务不可用
至于编程语言的选择,我觉得应该更加偏向团队对语言的掌握,以能hold住为最主要,这点没什么好说的,一般也只会在 Java / Go 中去选,很少见用其他语言实现的注册中心。
对于注册、订阅接口,无论是基于TCP的自定义私有协议,还是用HTTP协议,甚至基于HTTP2的gRPC我觉得都可以。
但变更推送这个技术点的实现,有多种实现方式:
定时轮询,每隔一段时间向注册中心请求查询订阅的服务提供列表 长轮询,向注册中心查询订阅的服务提供列表,如果列表较上次没有变化,则服务端hold住请求,等待有变化或者超时(较长时间)才返回 UDP推送,服务列表有变化时通过UDP将事件通知给客户端,但UDP推送不一定可靠,可能会丢失、乱序,故要配合定时轮询(较长时间间隔)来作为一个兜底 TCP长连接推送,客户端与注册中心建立一个TCP长连接,有变更时推送给客户端
从实现的难易、实时性、资源消耗三个方面来比较这四种实现方式:
| 实现难易 | 实时性 | 资源消耗 | 备注 | |
|---|---|---|---|---|
| 定时轮询 | 简单 | 低 | 高 | 实时性越高,资源消耗越多 |
| 长轮询 | 中等 | 高 | 中等 | 服务端hold住很多请求 |
| UDP推送 | 中等 | 高 | 低 | 推送可能丢失,需要配合定时轮询(间隔较长) |
| TCP长连接推送 | 中等 | 高 | 中等 | 服务端需要保持很多长连接 |
似乎我们不好抉择到底使用哪种方式来做推送,但以我自己的经验来看,定时轮询应该首先被排除,因为即便是一个初具规模的公司,定时轮询的消耗也是巨大的,更何况这种消耗随着实时性以及服务的规模日渐庞大,最后变得不可维护。
剩下三种方案都可以选择,我们可以继续结合服务节点的健康检查来综合判断。
服务启动时注册到注册中心,当服务停止时,从注册中心摘除,通常摘除会借助劫持kill信号实现,如果是Java则有封装好的ShutdownHook,当进程被 kill 时,触发劫持逻辑,从注册中心摘除,实现优雅退出。
但事情不总是如预期,如果有人执行了kill -9强制杀死进程,或者机器出现硬件故障,会导致提供者还在注册中心,但已无法提供服务。
此时需要一种健康检查机制来确保服务宕机时,消费者能正常感知,从而切走流量,保证线上服务的稳定性。
关于健康检查机制,在之前的文章《服务探活的五种方式》中有专门的总结,这里也列举一下,以便做出正确的选择:
| 优点 | 缺点 | |
|---|---|---|
| 消费者被动探活 | 不依赖注册中心 | 需在服务调用处实现逻辑;用真实流量探测,可能会有滞后性 |
| 消费者主动探活 | 不依赖注册中心 | 需在服务调用处实现逻辑 |
| 提供者上报心跳 | 对调用无入侵 | 需消费者服务发现模块实现逻辑,服务端处理心跳消耗资源大 |
| 注册中心主动探测 | 对客户端无要求 | 资源消耗大,实时性不高 |
| 提供者与注册中心会话保持 | 实时性好,资源消耗少 | 与注册中心需保持TCP长连接 |
我们暂时无法控制调用动作,故而前2项依赖消费者的方案排除,提供者上报心跳如果规模较小还好,上点规模也会不堪重任,这点在Nacos中就体现了,Nacos 1.x版本使用提供者上报心跳的方式保持服务健康状态,由于每次上报健康状态都需要写入数据(最后健康检查时间),故对资源的消耗是非常大的,所以Nacos 2.0版本后就改为了长连接会话保持健康状态。
所以健康检查我个人比较倾向最后两种方案:注册中心主动探测与提供者与注册中心会话保持的方式。
结合上述变更推送,我们发现如果实现了长连接,好处将很多,很多情况下,一个服务既是消费者,又是提供者,此时一条TCP长连接可以解决推送和健康检查,甚至在注册注销接口的实现,我们也可以复用这条连接,可谓是一石三鸟。
长连接技术选型
长连接的技术选型,在《Nacos架构与原理》这本电子书中有有详细的介绍,我觉得这部分堪称技术选型的典范,我们参考下,本节内容大量参考《Nacos架构与原理》,如有雷同,那便是真是雷同。
首先是长连接的核心诉求:

图来自《Nacos架构与原理》
低成本快速感知:客户端需要在服务端不可用时尽快地切换到新的服务节点,降低不可用时间 客户端正常重启:客户端主动关闭连接,服务端实时感知 服务端正常重启 : 服务端主动关闭连接,客户端实时感知 防抖:网络短暂不可用,客户端需要能接受短暂网络抖动,需要一定重试机制,防止集群抖动,超过阈值后需要自动切换 server,但要防止请求风暴 断网:断网场景下,以合理的频率进行重试,断网结束时可以快速重连恢复 低成本多语言实现:在客户端层面要尽可能多的支持多语言,降低多 语言实现成本 开源社区:文档,开源社区活跃度,使用用户数等,面向未来是否有足够的支持度
据此,我们可选的轮子有:
| gRPC | Rsocket | Netty | Mina | |
|---|---|---|---|---|
| 客户端感知断连 | 基于 stream 流 error complete 事件可实现 | 支持 | 支持 | 支持 |
| 服务端感知断连 | 支持 | 支持 | 支持 | 支持 |
| 心跳保活 | 应用层自定义,ping-pong 消息 | 自定义 kee palive frame | TCP+ 自定义 | 自定义 kee palive filter |
| 多语言支持 | 强 | 一般 | 只Java | 只Java |
我比较倾向gRPC,而且gRPC的社区活跃度要强于Rsocket。
数据存储
注册中心数据存储方案,大致可分为2类:
利用第三方组件完成,如Mysql、Redis等,好处是有现成的水平扩容方案,稳定性强;坏处是架构变得复杂 利用注册中心本身来存储数据,好处是无需引入额外组件;坏处是需要解决稳定性问题
第一种方案我们不必多说,第二种方案中最关键的就是解决数据在注册中心各节点之间的同步,因为在数据存储在注册中心本身节点上,如果是单机,机器故障或者挂掉,数据存在丢失风险,所以必须得有副本。
数据不能丢失,这点必须要保证,否则稳定性就无从谈起了。保证数据不丢失怎么理解?在客户端向注册中心发起注册请求后,收到正常的响应,这就意味着数据存储了起来,除非所有注册中心节点故障,否则数据就一定要存在。
如下图,比如提供者往一个节点注册数据后,正常响应,但是数据同步是异步的,在同步完成前,nodeA节点就挂掉,则这条注册数据就丢失了。

所以,我们要极力避免这种情况。
而一致性算法(如raft)就解决了这个问题,一致性算法能保证大部分节点是正常的情况下,能对外提供一致的数据服务,但牺牲了性能和可用性,raft算法在选主时便不能对外提供服务。
有没有退而求其次的算法呢?还真有,像Nacos、Eureka提供的AP模型,他们的核心点在于客户端可以recover数据,也就是注册中心追求最终一致性,如果某些数据丢失,服务提供方是可以重新将数据注册上来。
比如我们将提供方与注册中心之间设计为长连接,提供方注册服务后,连接的节点还没来得及将数据同步到其他节点就挂了,此时提供方的连接也会断开,当连接重新建立时,服务提供方可以重新注册,恢复注册中心的数据。
对于注册中心选用AP、还是CP模型,业界早有争论,但也基本达成了共识,AP要优于CP,因为数据不一致总比不可用要好吧?你说是不是。
高可用
其实高可用的设计散落在各个细节点,如上文提到的数据存储,其基本要求就是高可用。除此之外,我们的设计也都必须是面向失败的设计。
假设我们的服务器会全部挂掉,怎样才能保持服务间的调用不受影响?
通常注册中心不侵入服务调用,而是在内存(或磁盘)中缓存一份服务列表,当注册中心完全挂了,大不了这份缓存不再更新,但也不影响现有的服务调用,但新应用启动就会受到影响。
总结
本文内容略多,用一幅图来总结:
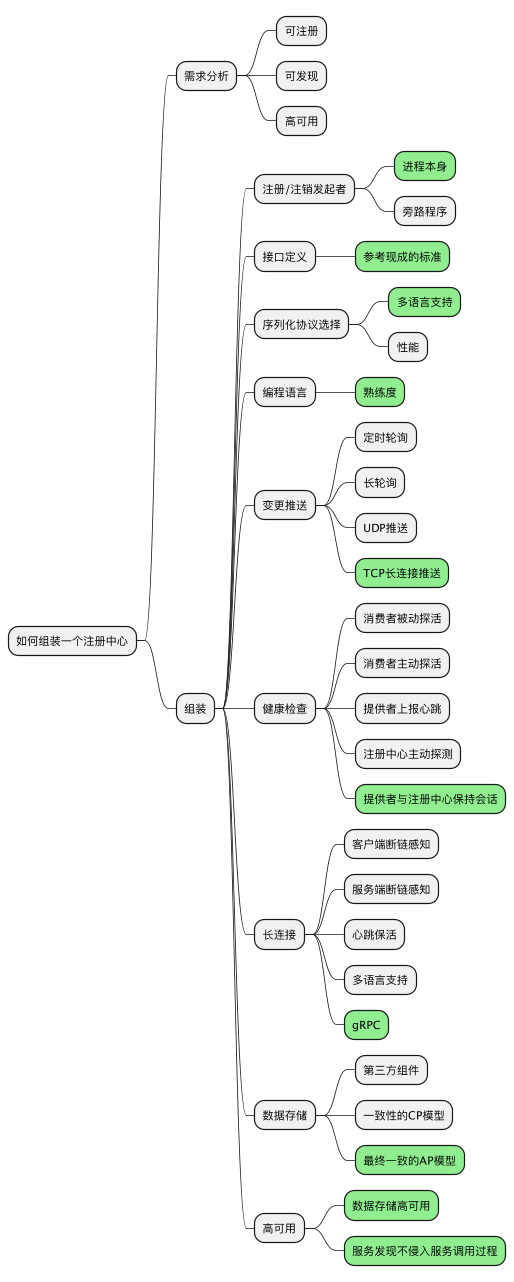
组装一个线上可用的注册中心最小集,从需求分析出发,每一步都有许多选择,本文通过一些核心的技术选型来描绘出一个大致蓝图,剩下的工作就是用代码将这些组装起来。
其中有些细节,我在之前的文章中有提及,这里也一并推荐,感谢大家的阅读,如果稍有收获,麻烦点个赞和在看,你的支持是我创作的最大动力~
搜索关注微信公众号"捉虫大师",后端技术分享,架构设计、性能优化、源码阅读、问题排查、踩坑实践。