
MDFR :基于人脸图像复原和人脸转正联合模型的人脸识别方法
点击下方“AI算法与图像处理”,一起进步!
重磅干货,第一时间送达


原文标题:《Joint Face Image Restoration and Frontalization For Recognition》
论文地址:https://ieeexplore.ieee.org/document/9427073/
MDFR 可以从给定的多姿态、多重低质量因素影响的人脸图像中复原其高质量的正面人脸图像。MDFR是一个设计良好的编码器-解码器网络结构。
在模型的构建中,作者引入了姿态残差学习策略,以及一个基于3D的姿势归一化模块(3D-based Pose Normalization Module,PNM),该模块可以感知输入人脸姿态和正面人脸姿态之间的差异,以此差异来指导人脸的转正学习。
实验表示,训练完成之后的MDFR可以通过一个单一化的网络,一次性地从多重低质量因素影响的侧面人脸图像中恢复其高清的正面人脸图像,并有效的提高人脸算法的识别率。
背景及简介
非限制条件下的人脸识别方法是计算机视觉任务中一项重要的工作。在实际应用中,采集到的人脸图像可能包含大姿态,不良光照,低分辨率以及模糊和噪声等,这些影响人脸成像质量的因素可能导致人脸识别应用的失败。为了解决这些问题,已经有很多方法使用分阶段模型来分别处理相应的低质量因子影响的人脸图像,即首先将低质量人脸恢复成高质量的人脸图像,随后进行人脸转正并用于人脸识别。
然而这些方法都只考虑了人脸识别的单一因素,很少有方法能够同时解决影响人脸识别的多重因素。因此,这类基于单一因素的人脸处理方法并不能很好的适用于非限制条件下的人脸识别。在本文中,作者提出了一种解决多退化因子的人脸复原模型(MDFR),从给定任意姿态的低质量人脸图像中恢复出高质量正面人脸。
文章的贡献如下:
提出了一种多退化因子人脸复原模型(Multi-Degradation Face Restoration, MDFR),将给定的任意姿态和受多重低质量因子影响的人脸图像恢复为正面且高质量的图像; 在人脸转正过程中,使用了姿态残差学习策略,并且提出了一种基于3D的姿态归一化模块; 提出了一种有效的整合训练策略将人脸重建和转正任务融合到一个统一的网络中,该方法能够进一步提升输出的人脸质量和后续的人脸识别效果;
方法描述
MDFR结构如图1所示。在训练过程中,MDFR主要包含两个模块,即双代理生成器(Dual-Agent Generator)和双代理判别器(Dual-Agent Discriminator)。姿态归一化模型模块(Pose Normalization Module, PNM)被嵌入到网络中对人脸的姿态进行归一化。
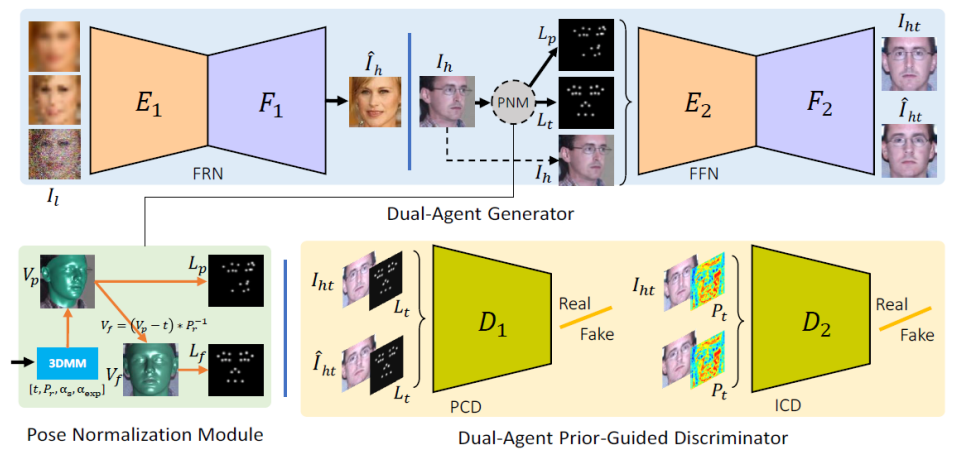
图1. MDFR模型的结构,包括双代理生成器,姿态归一化模型,以及双代理判别器。
(1)双代理生成器
双代理生成器包含一个人脸复原子网络(Face Restoration sub-Net, FRN)和一个人脸转正子网络(Face Frontalization sub-Net, FFN)。FRN网络的作用是将低质量人脸图像重建为高质量人脸图像,而FFN网络将FRN生成的侧脸图像进行转正。其中每个子网络均包含一个编码器和解码器,前者用来将输入映射到特征空间,而后者主要将编码后的特征重建为相应的目标人脸图像。两个子网络具有相同的网络结构,但是输入有所不同。FRN的编码器对输入的人脸图像进行编码,随后解码器对编码器的特征进行解码。FFN的解码器的输入除了人脸的编码特征外,还包含人脸两种姿态的编码残差,如图2所示。
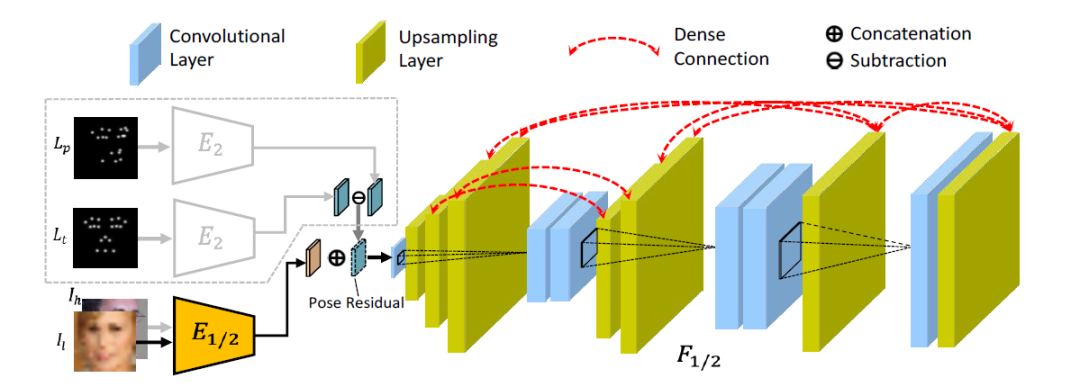 图2生成网络的网络结构
图2生成网络的网络结构
(2)姿态归一化模块
作者设计了一个姿态归一化模块(PNM)对姿态进行归一化。PNM提供了标准的、并且尺度统一的真实正面姿态来来引导人脸转正。基于3D形变模型(3D Morphable Model, 3DMM),二维人脸图像对应的三维顶点可以通过人脸正交基线性加权相加而得到:
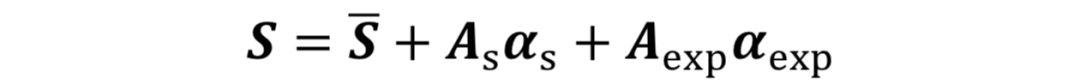
通过尺度正交映射将三维人脸顶点映射到二维图像平面,二维侧脸人脸图像可以表示为:
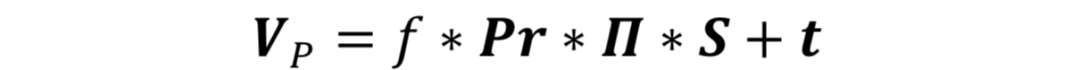
其中,参数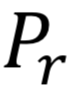 是相应的旋转矩阵,t 为平移向量。当移去旋转矩阵和平移向量后,归一化后真实转正的人脸密集二维坐标可以表述为:
是相应的旋转矩阵,t 为平移向量。当移去旋转矩阵和平移向量后,归一化后真实转正的人脸密集二维坐标可以表述为:
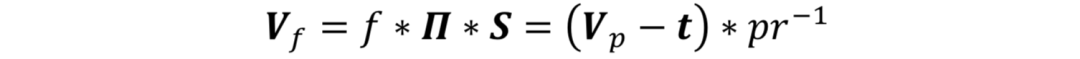
在文章中,作者使用3D人脸转正方法 2DAL 从一张给定的二维人脸图像中获取人脸密集坐标,最后选取18个常用的关键点来生成相应的高斯热力图(Gaussian Heatmaps)。
(3)双代理先验引导判别器
在人脸超分辨率领域使用的判别损失能够很好的提高重建人脸的真实度。因此,在本文中,作者在判别器中加入两种额外的先验信息:目标人脸的landmarks以及正脸的身份特征图,使得生成的人脸不仅能够获得目标姿态,还具有真实的身份信息。对应的判别器分别为PCD(Pose Conditioned Discriminator)以及ICD(Identity Conditioned Discriminator)。
在实现过程中,作者将两种先验信息分别作用到输入判别器中引导人脸的生成,然后再输入到相应的判别器中进行判别损失的求解。PCD和ICD不仅可以区分真实人脸和生成的人脸,同时可以学习到真实人脸和生成人脸的姿态和身份差异。
(4)网络训练
网络的训练主要分为两个阶段:Separate Training和TI Training。
Separate Training:文章首先分别训练FRN和FFN两个子网络,两个训练过程分别简写为FRN-S和FFN-S。FRN-S训练过程中所用到的损失函数如下:
身份信息损失:
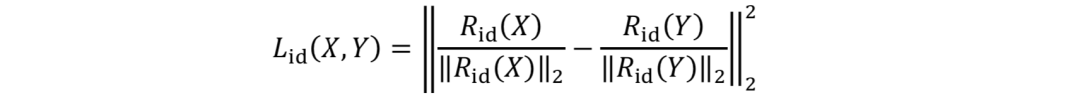
重建像素损失:
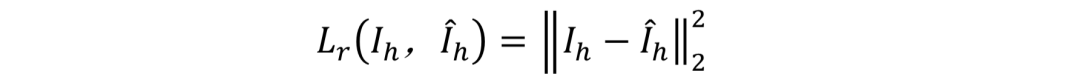
总的损失:
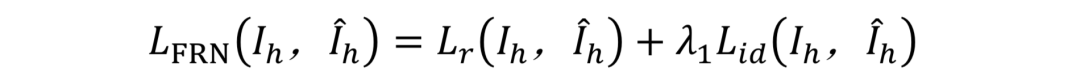
FFN-S训练过程中所用到的损失函数如下:
转正损失:
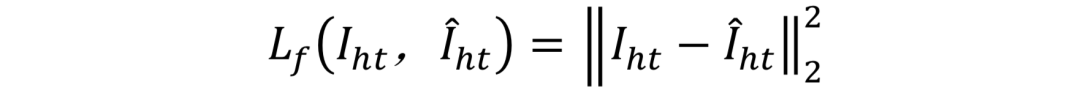
条件对抗损失:
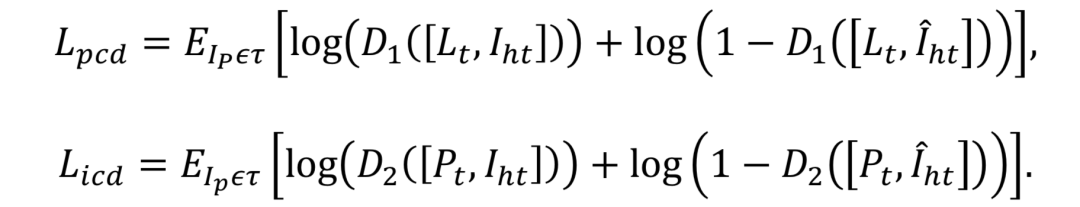
总的损失:
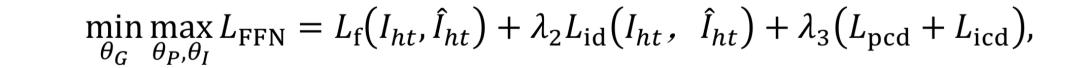
Task-Integrated (TI) training:在FRN和FFN完成了相应的分开训练后,作者在预训练模型的基础上进行整合训练。在这个阶段,作者使用FFN模型的输出作为ground-truth来训练FRN。同时,使用PNM归一化后的真实转正面部landmarks来引导FFN中人脸的转正。为了生成更好的人脸效果,在这一阶段作者还使用了特征对齐损失(Feature Alignment Loss, FA),具体的定义如下:
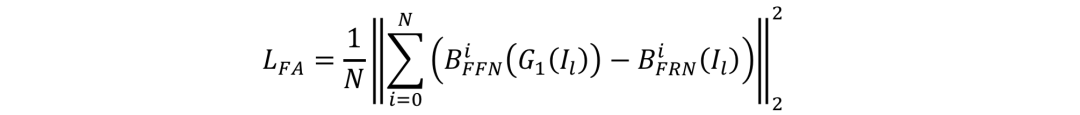
整体的训练损失函数为:
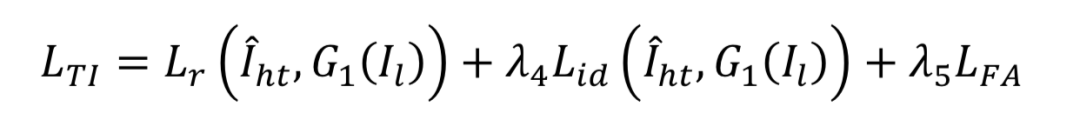
实验结果
作者首先探索了不同的网络结构和损失函数的组合来观察FFN-S和FRN-TI相应部分对人脸生成的影响,实验结果如图3所示。
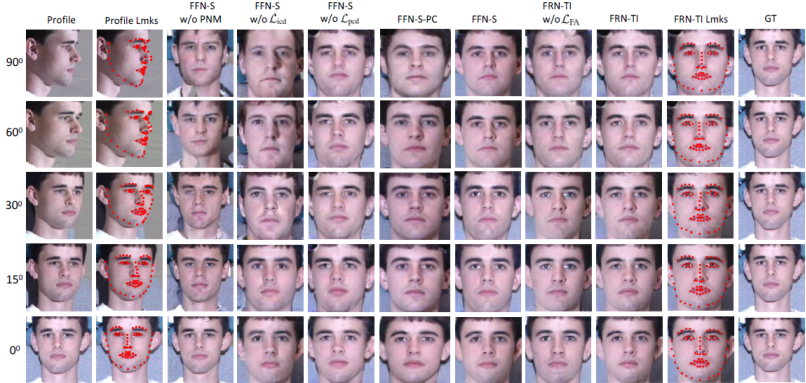
图3. 消融实验在Multi-PIE数据库上的对比结果。
同时,表1展示了 MDFR 的不同变异体对不同姿态人脸的 rank-1 识别率。在所有的实验模型中,FFN-S 和 FRN-TI 均获得了最好的精度。
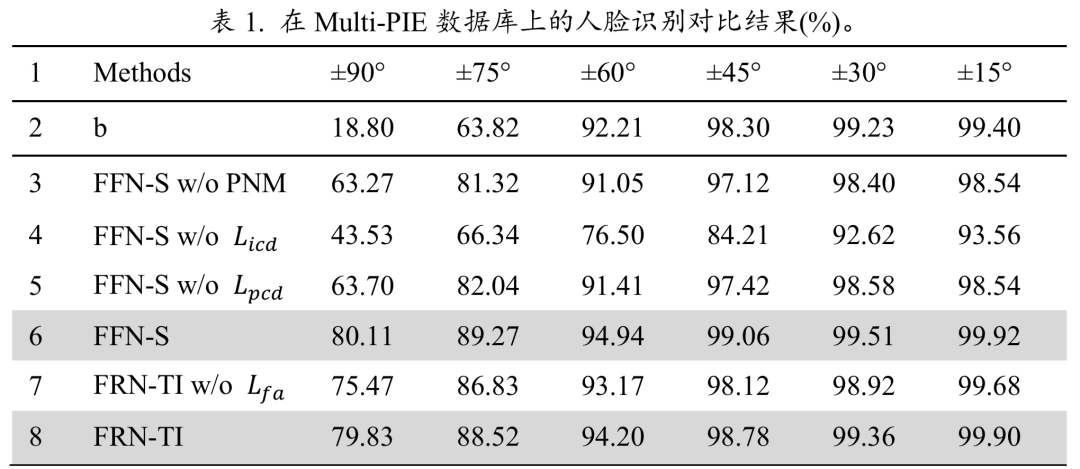
表2列举了 FFN-S 和 FRN-TI 同其他方法在 Multi-PIE 数据集上人脸识别率的比较。FFN-S 在所有的姿态中获得了最好的效果,其次是FFN-TI。当姿态角度在±45°以内时,FFN-S 和FFN-TI获得了同 CAPG-GAN 相似的识别效果。但当姿态角度大于±45°时,FFN-S 和 FFN_TI 的效果要显著的好于 CAPG-GAN。
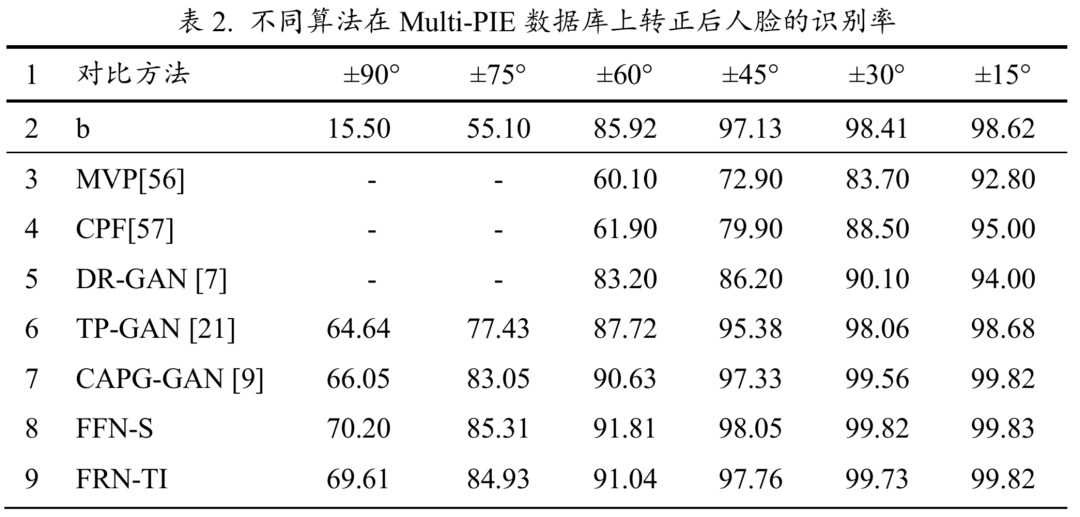
图4. 不同方法在多重低质量因素影响下的人脸复原效果
作者在多重低质量因素影响的人脸图像上进行相应的验证,包括低分辨率、不良光照、噪声以及模糊。实验表明,文章提到的方法不仅可以充分应对多种低质量因子,而且都可以生成相应的高质量人脸图像。图4展示了不同方法在多重低质量因素影响下的人脸复原效果。可以看出不同于之前只能处理单一的任务的方法,文中所提出的方法既可以对人脸进行转正也可以进行高质量复原,且取得了最好的视觉效果。
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021 在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
