
【NLP】使用AutoX_nlp自动化提取文本特征
背景

你是否曾面对结构化数据中的文本列,不知如何处理?文本数据作为一种常见的数据类型,包含了大量重要特征,如情感、意图等。为了高效地将文本转换为可供模型使用的特征,AutoX_nlp提供了文本列自动特征提取的解决方案。通过该方案,可以很方便地调用文本处理工具,将文本特征变成数值特征,进行后续训练、预测。
效果
目前AutoX_nlp结合AutoX端到端自动机器学习建模方案,已在多个包含文本域的数据集上取得优于其他自动建模工具的结果。
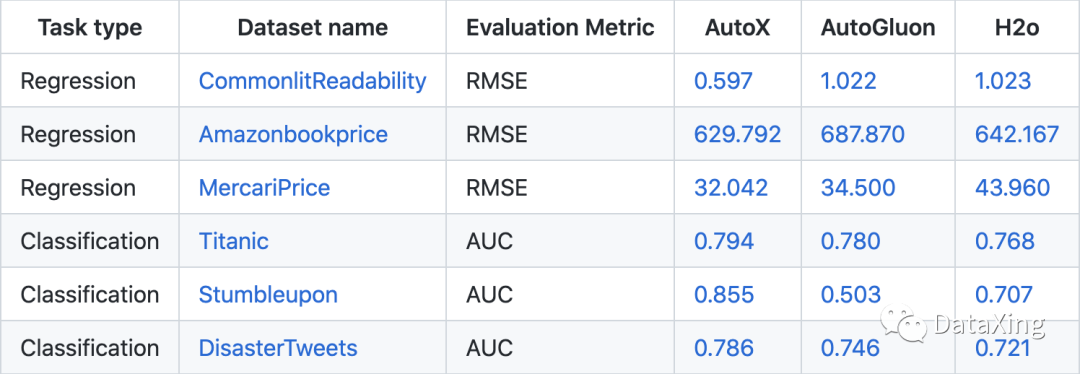
案例说明
你可以很容易地使用AutoX_nlp,几行代码即可完成文本特征提取:
from autox.autox_nlp import NLP_featureNLP_feature = NLP_feature()text_columns = ['text1','text2']train_text_feature = NLP_feature.fit_transform(train,text_columns)test_text_feature = NLP_feature.transform(test)
AutoX_nlp介绍
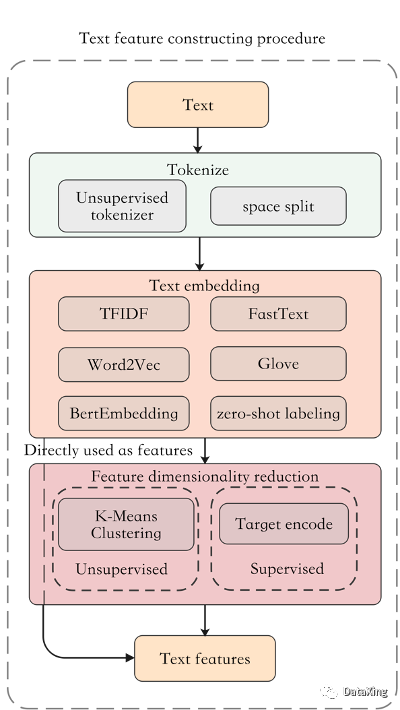
主要流程包括:
1. 分词:将单条文本拆分为多个token,将文本信息拆分细化。默认为空格分词,无监督分词器可以动态选择较合适的分词粒度;
2. 特征提取:将拆分后的文本表示为数值特征向量,默认为TFIDF,此外还支持Word2Vec、FastText、Glove、Bert、Zero-shot labeling。其中zero shot labeling使用在NLI任务下训练的模型对文本潜在的类别进行预测,适用于提前知晓文本列所指代特征的情况;
3. 输出:将特征转化为期望的输出格式,默认为离散型,此外也可以直接以稀疏矩阵输出第二步的特征,以及使用有监督的方式输出连续型特征。
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 中国大学慕课《机器学习》(黄海广主讲) 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑 机器学习交流qq群955171419,加入微信群请扫码:
评论