
数仓(四)数据仓库分层
上一节我们了解了数仓中常见的两大建模体系:关系建模和维度建模,并论述了维度建模的4个步骤。
数仓(三)简析阿里、美团、网易、恒丰银行、马蜂窝5家数仓分层架构
其实数仓建模中还有些其他建模体系:
像DataVault、Anchor模型,这两个模型感兴趣的可以自己查些资料。
这一篇我们来学习一下数仓中非常重要的内容:数仓的分层架构体系。
一、数据集市(Data Mart)
数据集市也叫数据市场。为某个特殊的专业人员团体服务的数据源中收集数据的仓库。从范围上来说,数仓是从企业范围的,而数据集市是部门范围的。
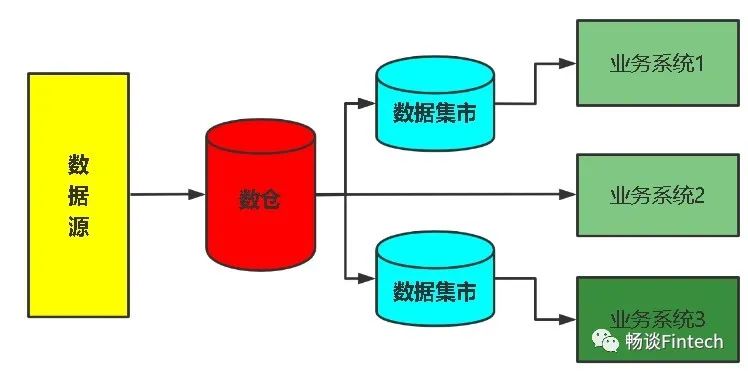
数据仓库
是企业级的,能为整个企业各个部门的运行提供决策支持手段;
数据集市
则是一种微型的数据仓库,它通常有更少的数据,更少的主题区域,以及更少的历史数据,因此是部门级的。
一般只能为某个局部范围内的管理人员服务,因此也称之为部门级数据仓库。
二、数仓分层思想
通过分层管理来实现分步完成工作,
用空间换时间,通过数据预处理提高效率,提升应用系统的用户体验(效率),简化数据清洗的过程,使每一层处理逻辑变得更简单。
每一层的处理逻辑都相对简单和容易理解,这样我们比较容易保证每一个步骤的正确性; 当数据发生错误的时候,往往我们只需要局部调整某个步骤即可。
数据结构化更清晰
数据血缘追踪
增强数据复用能力
简化复杂的问题
减少业务的影响
统一数据口径
分层就能解决业务上所有的数据问题?
数仓分层尽管给数仓带来了很多好处,但它不是银弹,不能解决所有的数据问题;
并且没有绝对标准的数仓。不同的公司针对不同的业务搭建数仓的设计模型和分层一般也不一样。
数仓分层要结合当下企业的的技术以及当前的业务的数据量,业务的复杂度等通盘考量。
数仓的搭建设计是由关系型在线交易系统到面向主题的数据仓库系统,从范式建模到维度建模的必经之路。
三、数仓中常见的层级
数仓中常见的层级如下:
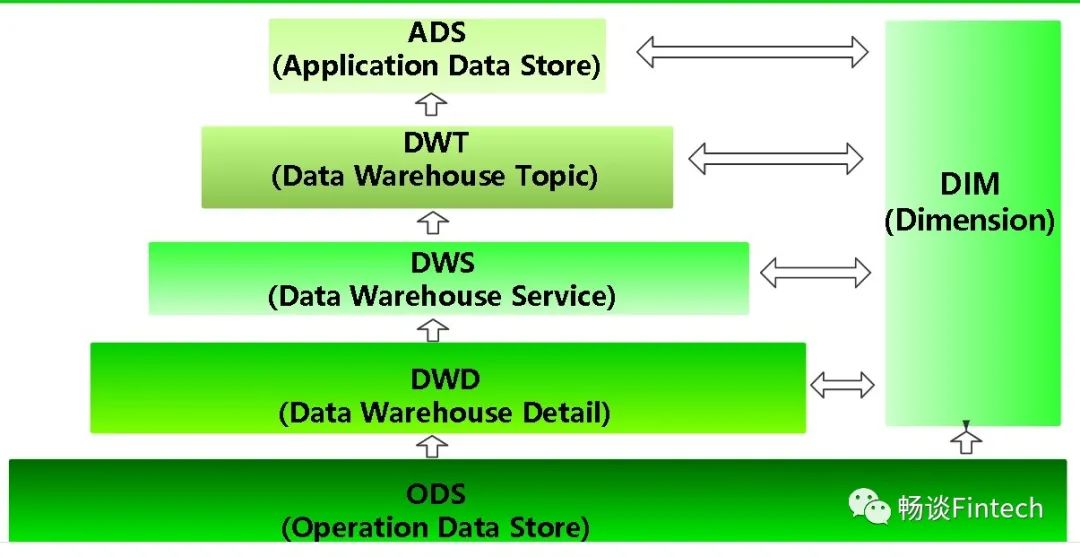
又叫“贴源层”,这层保持数据原貌不做任何修改,保留历史数据,储存起到备份数据的作用。 数据一般采用lzo、Snappy、parquet等压缩格式,减少磁盘存储空间(例如:原始数据 10G,根据算法可以压缩到 1G 左 右)。 创建分区表,防止后续的全表扫描,减少集群资源访问数仓的压力,一般按天存储在数仓中。
DWD层是维度建模层 关于维度建模请查阅数仓(三)建模和维度建模,这层维度建模主要做的4个步骤:

ODS到DWD层,需要对数据进行清洗做ETL操作(ETL是英文Extract-Transform-Load的缩写)。
ETL(Extract-Transform-Load)
将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程。是将业务系统的数据经过抽取、清洗转换之后加载到数据仓库的过程。
目的是将企业中的分散、凌乱、标准不统一的数据整合到一起,为企业的决策提供分析依据。
主要的数据处理是:去空值、去极值(比方取款300亿)、去业务极值、部分数据脱敏、维度退化等即对业务数据传过来的表进行维度退化和降维(如:商品一级二级、省市县、年月日等)。
使轻度汇总层,从ODS层中对用户的行为做一个初步的汇总,抽象出来一些通用的维度:时间、ip、id,并根据这些维度做一些统计值。
这里做轻度的汇总会让以后的计算更加的高效,如:统计各个主题对象计算7天、30天、90天的行为, 应对特殊需求(例如,购买行为,统计商品复购率)会快很多不必走ODS层反复拿数据做加工。
这层以分析的主题对象作为建模驱动,基于上层的应用和产品的指标需求,构建公共粒度的汇总指标事实表,以宽表化手段物理化模型。构建命名规范、口径一致的统计指标,为上层提供公共指标,建立汇总宽表、明细事实表。
服务于 DWT 层的主题宽表,以及一些业务明细数据。
高基数维度数据 一般是用户资料表、商品资料表等类似的资料表。数据量可能是千万级或者上亿级别。 低基数维度数据 一般是配置表,比如枚举值对应的中文含义,比如国家、城市、县市、街道等维表。数据量可能是个位数或者几千几万。
这一层是提供为数据产品使用的结果数据。 在这里,主要是提供给数据产品和数据分析使用的数据,一般会存放在 ES、MySQL等系统中供线上系统使用,也可能会存在 Hive 或者 Druid 、kill中供数据分析和数据挖掘使用。如我们经常说的报表数据,或者说那种大宽表,一般就放在这里。
4、DM(Data Mart)
数据仓库第4版 数据仓库工具 DAMA数据管理知识体系指南 华为数据之道
>>>>
Q&A
Q:数仓分几层适合?有没有统一的标准