
四、数据仓库和Hive环境搭建
上次介绍了HDFS,本来想进入Mapreduce,但感觉Mapreduce基本废弃,于是直接进入了Hive中来。
数据仓库
数据仓库,英文名称为Data Warehouse,可简写为DW或DWH。数据仓库顾名思义,是一个很大的数据存储集合,出于企业的分析性报告和决策支持目的而创建,对多样的业务数据进行筛选与整合。
它为企业提供一定的BI(商业智能)能力,指导业务流程改进、监视时间、成本、质量以及控制。
数据仓库的输入方是各种各样的数据源,最终的输出用于企业的数据分析、数据挖掘、数据报表等方向。
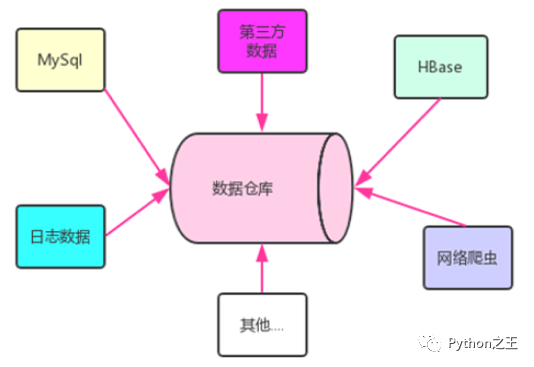
数据库和数据仓库区别
数据库是面向交易的处理系统,它是针对具体业务在数据库联机的日常操作,通常对记录进行查询、修改。用户较为关心操作的响应时间、数据的安全性、完整性和并发支持的用户数等问题。
数据仓库一般针对某些主题的历史数据进行分析,支持管理决策,又被称为联机分析处理 OLAP(On-Line Analytical Processing)。
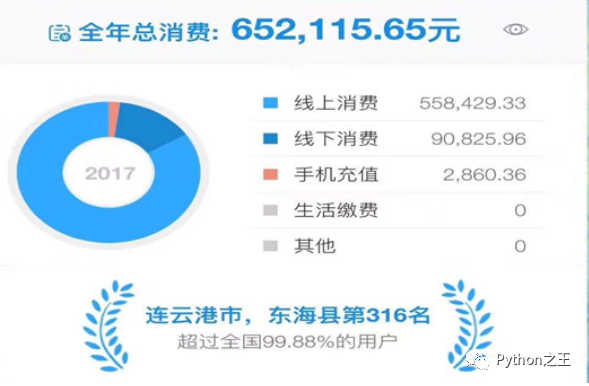
比如,支付宝年度账单其本质是基于数据仓库进行数据可视化而成。
数据仓库,是在数据库已经大量存在的情况下,为了进一步挖掘数据资源、为了决策需要而产生的,它决不是所谓的“大型数据库”。
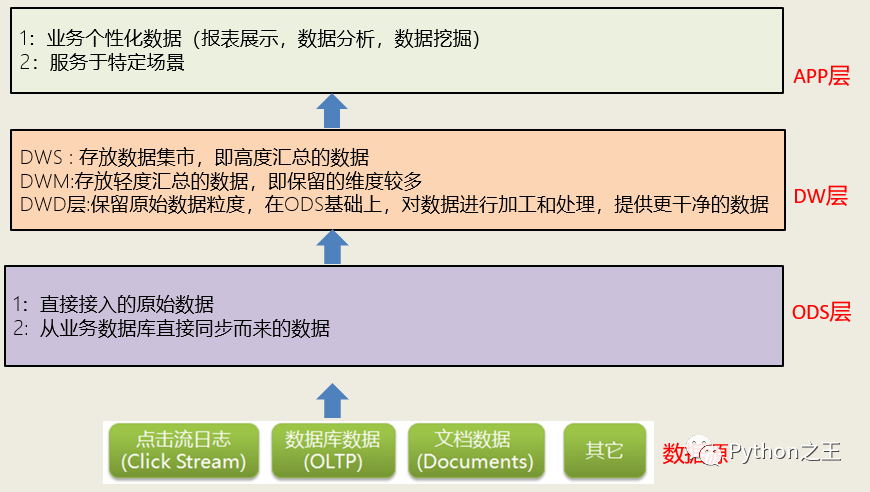
数据仓库分层
按照数据流入流出的过程,数据仓库架构可分为三层——源数据(ODS)、数据仓库(DW)、数据应用(APP)。
Hive
Hive是一个构建在 Hadoop上的数据仓库框架。最初,Hive是由Facebook开发,后来移交由 Apache!软件基金会开发,并作为一个 Apache开源项目。
Hive是建立在 Hadoop上的数据仓库基础构架。它提供了一系列的工具,可以存储、查询和分析存储在分布式存储系统中的大规模数据集。Hive定义了简单的类SQL査询语言,通过底层的计算引擎,将SQL转为具体的计算任务进行执行。
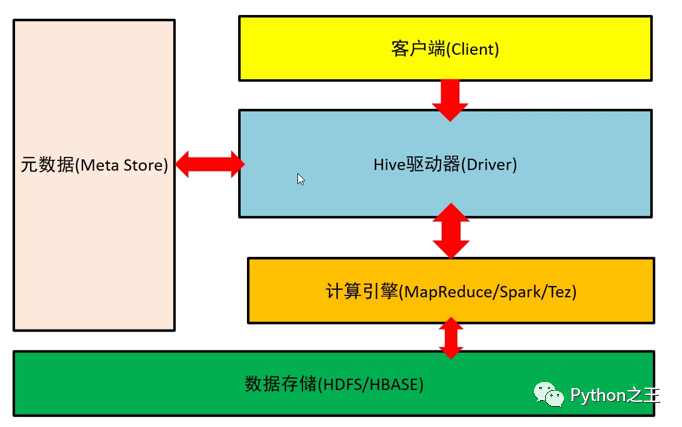
Hive支持Mapreduce、Tez、Spark等分布式计算引擎。
Hive环境搭建
在Hive环境搭建无需配置集群,Hive的安装其实有两部分组成,一个是Server端、一个是客户端,所谓服务端其实就是Hive管理Meta的那个Hive,服务端可以装在任何节点上,可以是Namenode上也可以是Datanode的任意一个节点上。
Hive的客户端界面工具早期选择SQuirrel SQL Client,但最近我喜欢上了Apache Zeppelin,Apache Zeppelin是一款基于Web的NoteBook,其实和Juypyter Notebook没有什么两样。
在 Hive环境搭建,需要搭建Mysql,这里选择节点node02进行Mysql环境搭建。
[hadoop@node02 ~]$ cd module/
[hadoop@node02 module]$ mkdir mysql
[hadoop@node02 module]$ cd mysql/
[hadoop@node02 mysql]# wget https://dev.mysql.com/get/mysql57-community-release-el7-9.noarch.rpm
[hadoop@node02 mysql]$ sudo rpm -ivh mysql57-community-release-el7-9.noarch.rpm
[hadoop@node02 yum.repos.d]$ yum install mysql-server
[hadoop@node02 yum.repos.d]# #第一次登录跳过权限认证
[hadoop@node02 yum.repos.d]# sudo vim /etc/my.cnf
############
[mysqld]
# 添加下面一行
skip-grant-tables
[hadoop@node02 yum.repos.d]# sudo systemctl start mysqld
[hadoop@node02 yum.repos.d]# mysql -u root
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)
mysql> ALTER USER 'root'@'localhost' IDENTIFIED BY '123456';
Query OK, 0 rows affected (0.00 sec)
mysql> create database hive;
Query OK, 1 row affected (0.00 sec)
mysql> exit;
[hadoop@node02 yum.repos.d]# mysql -u root -p123456
mysql> use mysql;
# 设置远程连接权限
mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '123456' WITH GRANT OPTION;
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> FLUSH PRIVILEGES;
Query OK, 0 rows affected (0.00 sec)
下面开始在centos系统中安装Hive。为了兼顾Hadoop3.1.4版本,我们选择安装hive3.1.2版本。Hive下载官方:http://www.apache.org/dyn/closer.cgi/hive/
[hadoop@node02 module]$ ls
apache-hive-3.1.2-bin.tar.gz hadoop mysql
[hadoop@node02 module]$ tar -zxvf apache-hive-3.1.2-bin.tar.gz
[hadoop@node02 module]$ mv apache-hive-3.1.2-bin hive
[hadoop@node02 module]$ ls
apache-hive-3.1.2-bin.tar.gz hadoop hive mysql
[hadoop@node02 conf]$ mv hive-env.sh.template hive-env.sh
[hadoop@node02 conf]$ vim hive-env.sh
#########
export HADOOP_HOME=/home/hadoop/module/hadoop/hadoop-3.1.4
export HIVE_CONF_DIR=/home/hadoop/module/hive/conf
export HIVE_AUX_JARS_PATH=/home/hadoop/module/hive/lib
[hadoop@node02 conf]$ sudo vim /etc/profile
#########
export HIVE_HOME=/home/hadoop/module/hive
export PATH=$PATH:$HIVE_HOME/bin
export HIVE_CONF_DIR=$HIVE_HOME/conf
[hadoop@node02 conf]$ source /etc/profile
[hadoop@node02 conf]$ mv hive-default.xml.template hive-site.xml
[hadoop@node02 conf]$ vim hive-site.xml
#########
<property>
<!--
对应的文件夹需要创建
-->
<name>hive.exec.local.scratchdir</name>
<value>/home/hadoop/module/data/hive/jobs</value>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/home/hadoop/module/data/hive/resources</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.147.129:3306/hive?createDatabaseIfNotExsit=true</value>
</property>
<!-- MySQL5.7使用com.mysql.jdbc.Driver
Mysql6版本使用com.mysql.cj.jdbc.Driver
-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
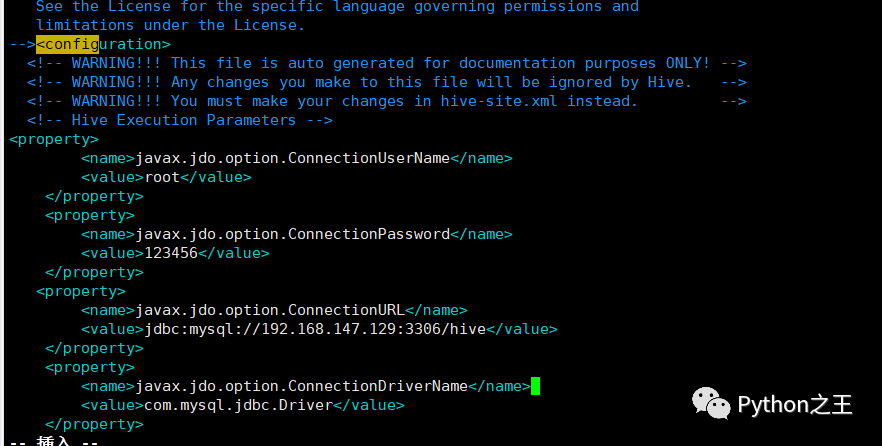
为了使用Java连接Mysql,需要下载Mysql驱动,下载地址:https://maven.ityuan.com/maven2/mysql/mysql-connector-java/5.1.33。
下载完成后并放在lib文件夹中,并通过hive初始化Mysql数据库。
[hadoop@node02 lib]$ pwd
/home/hadoop/module/hive/lib
[hadoop@node02 lib]$ wget https://repo1.maven.org/maven2/mysql/mysql-connector-java/5.1.33/mysql-connector-java-5.1.33.jar
[hadoop@node02 lib]$ schematool -dbType mysql -initSchema
在Hive初始化Mysql数据库,容易遇到两个比较常见的Bug:
第一个Hive初始化Mysql数据库:java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument
错误原因:系统找不到这个类所在的jar包或者jar包的版本不一样系统不知道使用哪个。hive启动报错的原因是后者
解决办法:
com.google.common.base.Preconditions.checkArgument这个类所在的jar包为:guava.jar
hadoop-3.2.1(路径:hadoop\share\hadoop\common\lib)中该jar包为 guava-27.0-jre.jar;而hive-3.1.2(路径:hive/lib)中该jar包为guava-19.0.1.jar
将jar包变成一致的版本:删除hive中低版本jar包,将hadoop中高版本的复制到hive的lib中。
第二个Hive初始化Mysql数据库:Exception in thread "main" java.lang.RuntimeException: com.ctc.wstx.exc.WstxParsingException: Illegal character entity: expansion character (code 0x8 at
报错原因:在本身的hive-site.xml配置文件中,3215行(见报错记录第二行)有特殊字符
解决办法:进入hive-site.xml文件,跳转到对应行,删除里面的特殊字符即可。
如果报Unknown database 'hive',建议直接在MySQL中创建hive数据库。
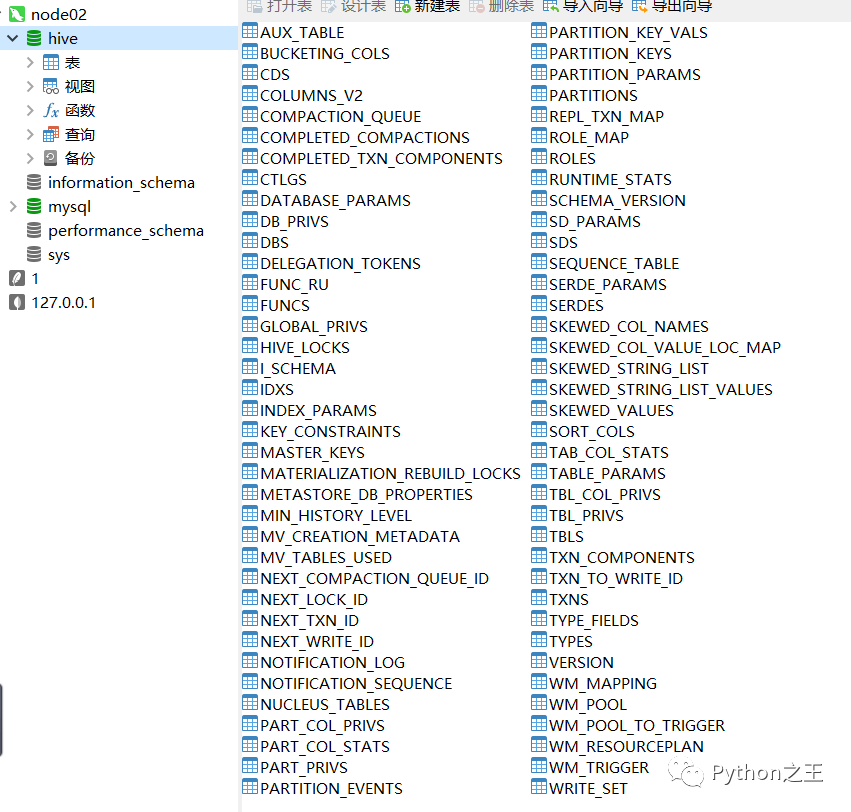
最终Hive成功初始化Mysql数据库如下图所示:

查看hive数据库,就会看见对应初始化的表生成。
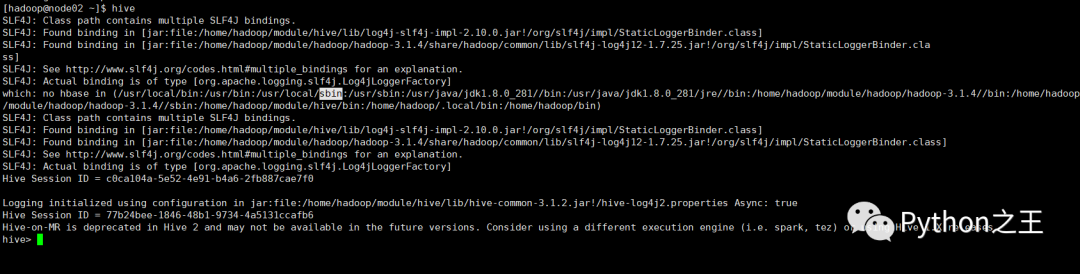
在输入hive,即可进入Hive命令行,说明Hive搭建成功。
更多的文章
点击下面小程序

- END -