
Kyuubi实践 | 编译 Spark3.1 以适配 CDH5 并集成 Kyuubi
1. Spark ThriftServer 在我们业务场景中的不足
2. 关于 Kyuubi
3. 编译 Spark3.1.2 以适配 CDH5
4. 测试 Spark 是否正常可用
5. 安装配置 kyuubi
5.1 创建用户 kyuubi
5.2 配置 kyuubi 代理用户的权限
5.3 创建用户 kyuubi 的 principal 并导出 keytab
5.4 在 Sentry 中给 kyuubi 用户赋予角色以及权限
5.5 配置 Kyuubi
6. Kyuubi 测试
6.1 Kyuubi 多租户测试
6.2 Kyuubi CONNECTION 级别的引擎共享
7. 总结
1. Spark ThriftServer 在我们业务场景中的不足
STS 是 Spark 中自带的一个组件,它可以在 yarn 上启动一个常驻的 Spark 应用,然后对外提供 JDBC 服务。
STS 在我们内部最典型的应用场景是,每天大量的 Tableau Spark Thrift 数据源刷新任务,需要定时执行,并拉取数据到 Tableau Server 端。在较高的并发负载下或一次性拉取的数据量过多时,就大概率会出现 driver 端进程卡死的情况(具体表现是,driver 端进程老年代内存占用 100%,GC 线程无法工作,分析 dump 文件,发现有内存泄漏的现象发生)。
每当遇到这样的情况,只能选择重启 STS,这期间 Application 中运行的 job 也一并会被杀死,导致数据源刷新任务频繁重试,浪费集群资源的同时,也会造成报表数据刷新的 SLA 无法满足业务方的要求。
基于此,我们开始了对 kyuubi 的调研,并重点测试其高可用,以及 CONNECTION 级别的引擎共享能力。
2. 关于 Kyuubi
Kyuubi 是一个分布式多租户 Thrift JDBC/ODBC 服务,同样构建在 Apache Spark 之上,用于大规模数据管理、处理和分析,类似 STS,但功能比 STS 更加丰富和优良。
其更详细的文档以及与 STS 的深入对比,可以参考其官方文档:
https://blog.csdn.net/NetEaseResearch/article/details/115013920
https://kyuubi.apache.org/docs/stable/integrations/index.html
3. 编译 Spark3.1.2 以适配 CDH5
我们团队内部 Hadoop 集群的版本是:
hive 1.1.0-cdh5.13.1 hadoop 2.6.0-cdh-5.13.1
同时,集群开启了 Sentry 和 Kerberos。
从 Spark3.0.x 开始,官方要求编译 Spark 时所依赖的 Hadoop 的最低版本是 2.7,默认所支持的 hive 的版本也高于 1.1.0。基于此,本小节记录了针对在 CDH5 的环境中,编译以及测试 Spark3.1.2 的完整流程。
当然,如果你没有强迫症,也可以选择 spark3-hadoop-2.7 的安装包来进行测试,kyuubi 社区也有大佬做过这样的测试。
下载 Spark3.1.2 的代码并导入到 IDEA 中,修改 Spark 的父 pom 文件,加入aliyun、cloudera、maven center的仓库地址,防止在国内的网络环境下,有些依赖的 jar 包下载不下来(原来的 repository 地址可以注释掉)。
<repository>
<id>aliyun</id>
<name>Nexus Release Repository</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
<repository>
<id>cloudera</id>
<name>cloudera Repository</name>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
<repository>
<id>central</id>
<name>Maven Repository</name>
<url>https://repo.maven.apache.org/maven2</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
在 pom 中加入 cdh-hadoop 的 profile,然后在 IDEA 中先尝试 build 下代码,看是否有报错发生。
<profile>
<id>hadoop2.6.0-cdh5.13.1</id>
<properties>
<hadoop.version>hadoop2.6.0-cdh5.13.1</hadoop.version>
<curator.version>2.7.1</curator.version>
<commons-io.version>2.4</commons-io.version>
<javax.servlet-api.name>servlet-api</javax.servlet-api.name>
</properties>
</profile>
点击绿色的锤子按钮,尝试 build 下代码。

正常情况下,在 build 的执行过程中,会有编译型异常发生。
Spark3.1.x 适配hadoop2.6.0-cdh5.13.1需要修改代码的地方有两处:
一处是修改resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/Client.scala,
参考:https://github.com/apache/spark/pull/16884/files
修改后的代码示例:
sparkConf.get(ROLLED_LOG_INCLUDE_PATTERN).foreach { includePattern =>
// 原有代码
/* try {
val logAggregationContext = Records.newRecord(classOf[LogAggregationContext])
logAggregationContext.setRolledLogsIncludePattern(includePattern)
sparkConf.get(ROLLED_LOG_EXCLUDE_PATTERN).foreach { excludePattern =>
logAggregationContext.setRolledLogsExcludePattern(excludePattern)
}
appContext.setLogAggregationContext(logAggregationContext)
} catch {
case NonFatal(e) =>
logWarning(s"Ignoring ${ROLLED_LOG_INCLUDE_PATTERN.key} because the version of YARN " +
"does not support it", e)
}*/
try {
val logAggregationContext = Records.newRecord(classOf[LogAggregationContext])
// These two methods were added in Hadoop 2.6.4, so we still need to use reflection to
// avoid compile error when building against Hadoop 2.6.0 ~ 2.6.3.
val setRolledLogsIncludePatternMethod =
logAggregationContext.getClass.getMethod("setRolledLogsIncludePattern", classOf[String])
setRolledLogsIncludePatternMethod.invoke(logAggregationContext, includePattern)
sparkConf.get(ROLLED_LOG_EXCLUDE_PATTERN).foreach { excludePattern =>
val setRolledLogsExcludePatternMethod =
logAggregationContext.getClass.getMethod("setRolledLogsExcludePattern", classOf[String])
setRolledLogsExcludePatternMethod.invoke(logAggregationContext, excludePattern)
}
appContext.setLogAggregationContext(logAggregationContext)
} catch {
case NonFatal(e) =>
logWarning(s"Ignoring ${ROLLED_LOG_INCLUDE_PATTERN.key} because the version of YARN " +
"does not support it", e)
}
}
第二处修改/spark-3.1.2/core/src/main/scala/org/apache/spark/util/Utils.scala:
def unpack(source: File, dest: File): Unit = {
// StringUtils 在hadoop2.6.0中引用不到,所以取消此import,然后修改为相似的功能
// val lowerSrc = StringUtils.toLowerCase(source.getName)
if (source.getName == null) {
throw new NullPointerException
}
val lowerSrc = source.getName.toLowerCase()
if (lowerSrc.endsWith(".jar")) {
RunJar.unJar(source, dest, RunJar.MATCH_ANY)
} else if (lowerSrc.endsWith(".zip")) {
FileUtil.unZip(source, dest)
} else if (
lowerSrc.endsWith(".tar.gz") || lowerSrc.endsWith(".tgz") || lowerSrc.endsWith(".tar")) {
FileUtil.unTar(source, dest)
} else {
logWarning(s"Cannot unpack $source, just copying it to $dest.")
copyRecursive(source, dest)
}
}
然后重新 build,修改完代码之后,build 的过程中应该不会再有报错发生。
hive 的版本就不要在 pom 中替换了,替换之后的编译报错修改起来会很麻烦。所以 hive 就用默认版本(2.3.7),因为从 Spark1.4.0 开始,Spark SQL 的单个二进制版本可用于查询不同版本的 Hive 元存储。具体内容可以参考:
https://spark.apache.org/docs/latest/sql-data-sources-hive-tables.html#interacting-with-different-versions-of-hive-metastore
运行打包命令前,请先修改下dev/make-distribution.sh,具体修改内容如下:
# spark版本
VERSION=3.1.2
# scala版本
SCALA_VERSION=2.12
# hadoop版本
SPARK_HADOOP_VERSION=2.6.0-cdh5.13.1
# 开启hive
SPARK_HIVE=1
# 原来的内容注释掉
#VERSION=$("$MVN" help:evaluate -Dexpression=project.version $@ \
# | grep -v "INFO"\
# | grep -v "WARNING"\
# | tail -n 1)
#SCALA_VERSION=$("$MVN" help:evaluate -Dexpression=scala.binary.version $@ \
# | grep -v "INFO"\
# | grep -v "WARNING"\
# | tail -n 1)
#SPARK_HADOOP_VERSION=$("$MVN" help:evaluate -Dexpression=hadoop.version $@ \
# | grep -v "INFO"\
# | grep -v "WARNING"\
# | tail -n 1)
#SPARK_HIVE=$("$MVN" help:evaluate -Dexpression=project.activeProfiles -pl sql/hive $@ \
# | grep -v "INFO"\
# | grep -v "WARNING"\
# | fgrep --count "<id>hive</id>";\
# # Reset exit status to 0, otherwise the script stops here if the last grep finds nothing\
# # because we use "set -o pipefail"
# echo -n)
在 Spark 项目的根路径下运行编译打包的命令
./dev/make-distribution.sh --name 2.6.0-cdh5.13.1 --pip --tgz -Phive -Phive-thriftserver -Pmesos -Pyarn -Pkubernetes -Phadoop2.6.0-cdh5.13.1 -Dhadoop.version=2.6.0-cdh5.13.1 -Dscala.version=2.12.10
首次编译时会拉取大量依赖,遇到网络错误可以多试几次。编译过程中会下载如 maven 安装包、Scala 之类的软件包到项目根路径的 build 目录下,在网络慢的情况下,可以手动下载这些软件包,然后移动到相应的目录之下也行。
Mac 下 R 环境有些问题,所以这里编译时就没带上 sparkR 的支持,所以 sparkR 估计用不了,编译完成之后最终的安装包会输出在 Spark 项目的根路径下。
4. 测试 Spark 是否正常可用
编译的工作还算顺利,网上也有很多类似的文章可供参考,如:
https://www.codeleading.com/article/42014747657/
之后的工作便是测试 Spark 的可用性,这里我主要测试的是,跑通 spark-shell、spark-sql,正常提交作业到 yarn 集群,正常读取到 hive 表中的数据,至于其他更细致的测试,后续会有文章接着介绍。
Spark 无需分布式部署安装,只需要准备好一个 Spark 的客户端环境即可。
涉及到修改 Spark 配置的命令参考如下:
cd /opt/spark-3.1.2/conf
# 把hive hdfs 相关配置文件的软连接构建起来
ln -s /etc/hive/conf/hive-site.xml hive-site.xml
ln -s /etc/hive/conf/hdfs-site.xml hdfs-site.xml
ln -s /etc/hive/conf/core-site.xml core-site.xml
mv log4j.properties.template log4j.properties
mv spark-defaults.conf.template spark-defaults.conf
mv spark-env.sh.template spark-env.sh
vim spark-defaults.conf
# 自定义spark要加载的hive metastore的版本以及jar包的路径,注意在spark3.1.x 与 spark3.0.x中此处配置的差异
spark.sql.hive.metastore.version=1.1.0
spark.sql.hive.metastore.jars=path
spark.sql.hive.metastore.jars.path=file:///opt/cloudera/parcels/CDH-5.13.1-1.cdh5.13.1.p0.2/lib/hive/lib/*
spark.sql.hive.metastore.version 不要写1.1.0-cdh5.13.1,spark 中 metastore 的自定义配置请参考:
http://spark.apache.org/docs/latest/sql-data-sources-hive-tables.html#specifying-storage-format-for-hive-tables
测试 spark-shell 以及 spark-sql 的命令参考:
export SPARK_HOPME=/opt/spark-3.1.2
# 本地跑spark-shell
sh /opt/spark-3.1.2/bin/spark-shell
# 以yarn-client的方式跑spark-shell
sh /opt/spark-3.1.2/bin/spark-shell --master yarn --deploy-mode client --executor-memory 1G --num-executors 2
# 以yarn-cluster的方式跑spark-sql
sh /opt/spark-3.1.2/bin/spark-sql --master yarn -deploy-mode cluster --executor-memory 1G --num-executors 2
# 跑一些spark代码 操作hive表中的一些数据,测试正常就OK
5. 安装配置 kyuubi
kyuubi 的安装包可以选择官方制作好的,如:
也可以自己拉取代码进行编译,这里我选择自己编译 kyuubi,使用的版本是最新发布的
v1.3.0-incubating
https://github.com/apache/incubator-kyuubi/releases/tag/v1.3.0-incubating
kyuubi 的编译请参考:
https://kyuubi.apache.org/docs/r1.3.0-incubating/develop_tools/distribution.html
下载代码到本地,导入 IDEA 中(或不导入),在项目根路径下输入:
./build/dist --tgz --spark-provided
# --spark-provided 我的spark环境已有,这里选择不把spark一并打包
打包完成之后,上传 tar 包至服务器,解压缩,去掉配置文件的后缀.template

配置和运行 kyuubi 之前,需要先做一些额外的操作。
5.1 创建用户 kyuubi
创建一个独立用户 kyuubi 来起 kyuubi 服务
useradd kyuubi
5.2 配置 kyuubi 代理用户的权限
kyuubi 需要代理其他用户来启动引擎,所以需要为其设置代理用户的权限。

5.3 创建用户 kyuubi 的 principal 并导出 keytab
命令参考:
kadmin.local
addprinc -pw 123456 kyuubi/node2.bigdata.leo.com@LEO.COM
ktadd -k kyuubi.keytab -norandkey kyuubi/node2.bigdata.leo.com@LEO.COM
其中 principal 的组成有 kyuubi node2.bigdata.leo.com @LEO.COM 这三部分组成,如果设置为kyuubi@LEO.COM,运行 kyuubi 时会报错。
5.4 在 Sentry 中给 kyuubi 用户赋予角色以及权限
无 Sentry 可跳过授权,但还是需要注意 kyuubi 用户在 hdfs 以及 hive 中是否存在权限问题。
5.5 配置 Kyuubi
上述准备工作完成之后,可以配置 kyuubi。参考命令以及参考的配置文件。
vim kyuubi-defaults.conf
# 启动的spark引擎以yarn-cluster模式跑
spark.master=yarn
spark.submit.deployMode=cluster
# spark引擎共享级别,user,即同一用户共享一个引擎,
kyuubi.engine.share.level=USER
kyuubi.session.engine.idle.timeout=PT10H
# 启用HA,指定ZK地址
kyuubi.ha.enabled true
kyuubi.ha.zookeeper.quorum node1:2181,node2:2181,node3:2181
kyuubi.ha.zookeeper.client.port 2181
# kerbero授权开启
kyuubi.authentication=KERBEROS
kyuubi.kinit.principal=kyuubi/node2.bigdata.leo.com@LEO.COM
kyuubi.kinit.keytab=/home/kyuubi/kyuubi.keytab
# kyuubi环境变量配置,按需配置
vim kyuubi-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_181-cloudera
export SPARK_HOME=/opt/spark-3.1.2
关于 kyuubi 更详细的配置参数,请参考。
https://kyuubi.apache.org/docs/r1.3.0-incubating/deployment/settings.html#kyuubi-configurations
运行 kyuubi
bin/kyuubi start
运行 beeline 测试连接 kyuubi
beeline -u "jdbc:hive2://node2.bigdata.leo.com:10009/;principal=kyuubi/node2.bigdata.leo.com@LEO.COM"
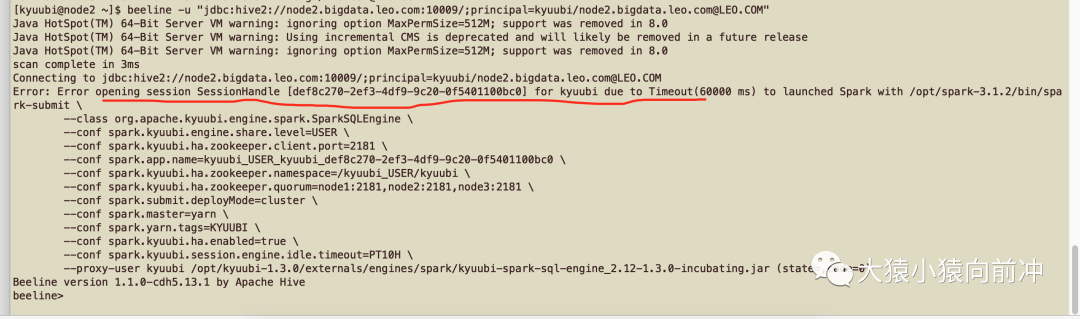
查看日志,先查看 kyuubi 服务运行过程中的输出日志
/opt/kyuubi-1.3.0/logs/kyuubi-kyuubi-org.apache.kyuubi.server.KyuubiServer-node2.bigdata.leo.com.out

此日志中没有上述异常发生的具体原因,继续看日志,此日志为 kyuubi 启动的 Spark 的 engine 日志
/opt/kyuubi-1.3.0/work/kyuubi/kyuubi-spark-sql-engine.log.0
此日志中依旧没有有用的信息,继续看 spark application 的日志,由于没有 Spark History 服务,所以我这里用 yarn 命令来看日志:
yarn logs -applicationId application_1632672215527_0014
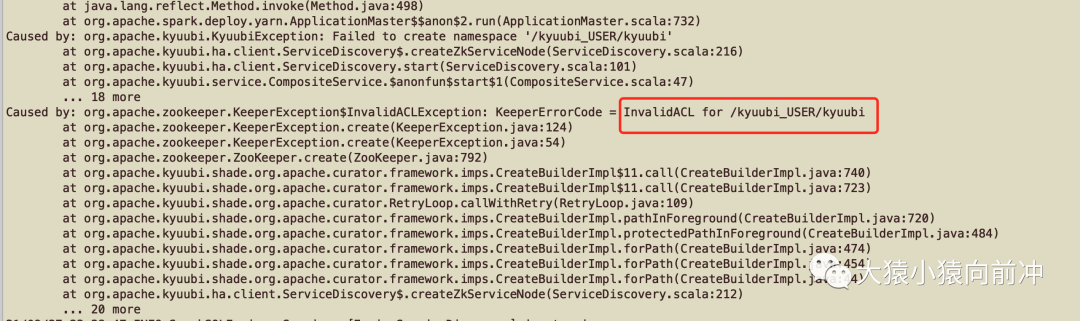
由于开启了 HA,kyuubi 会在指定 ZK 上创建一些 znode path,由于我的 zookeeper 服务在 kerberos 环境中,因此可能会遇到 zk kerberos 认证,或 zk node path 的 ACL 问题,在 zk shell 查看/kyuubi_USER 的 ACL,并尝试是否可以创建 znode path。
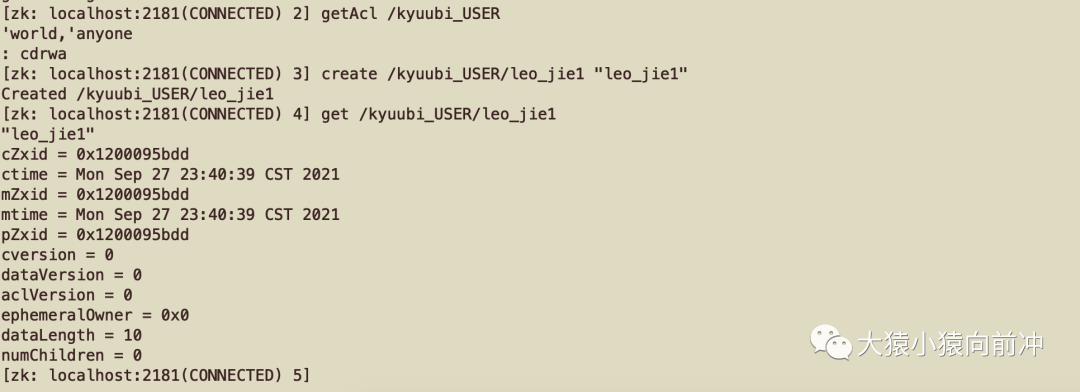
经过上述测试可知,kyuubi 用户 kinit 拿到 kerberos 凭证之后,再去操作/kyuubi_USER 这个 znode path 时,并不会出现 ACL 问题。
根据官方大佬的解释以及大致看了下源码之后得知,这里出现 ZK ACL 的问题是因为,kyuubi server 启动,创建 zkClient 时,会获取 kerberos 认证。但在 spark engine 的 driver 端创建的 zkClient,并没有去获取 Kerberos 认证,所以才产生这个报错(分析不到位的地方还望与我沟通)。
临时的解决办法是取消 HA 配置或使用其他未开启 kerberos 的 Zookeeper(待确认)。禁用 HA 使用 kyuubi 自带的 ZK 服务,需要修改 kyuubi-defaults.conf 为:
spark.master=yarn
spark.submit.deployMode=cluster
kyuubi.engine.share.level=USER
kyuubi.session.engine.idle.timeout=PT10H
kyuubi.ha.enabled false
kyuubi.zookeeper.embedded.client.port 2182
kyuubi.authentication=KERBEROS
kyuubi.kinit.principal=kyuubi/node2.bigdata.leo.com@LEO.COM
kyuubi.kinit.keytab=/home/kyuubi/kyuubi.keytab
重启 kyuubi 之后,再用 beeline 连接,测试正常。
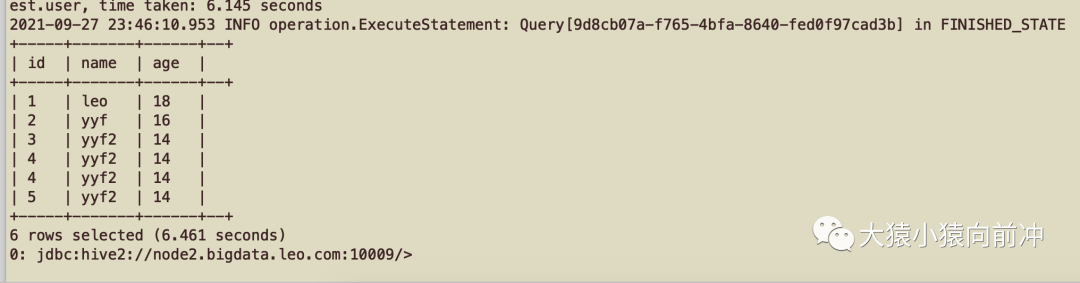
6. Kyuubi 测试
6.1 Kyuubi 多租户测试
保证 kyuubi server 正常启动,创建一个测试用户 leo_jie,并为其创建 principal 以及导出对应用户的 keytab,分别在两个客户端上用 kyuubi 以及 leo_jie 来测试连接 kyuubi server。示例命令如下:
# 用户leo_jie的操作
kinit -kt leo_jie.keytab leo_jie@LEO.COM
beeline -u "jdbc:hive2://node2.bigdata.leo.com:10009/;principal=kyuubi/node2.bigdata.leo.com@LEO.COM"
# 用户kyuubi的操作
kinit -kt kyuubi.keytab kyuubi/node2.bigdata.leo.com@LEO.COM
beeline -u "jdbc:hive2://node2.bigdata.leo.com:10009/;principal=kyuubi/node2.bigdata.leo.com@LEO.COM"
在 yarn ui 上可以看到起了两个 application,一个所属用户是 leo_jie,一个是 kyuubi。如果是 STS,则需要连续手动启动两个 STS 进程。

Spark Engine 空闲一段时间之后就会被释放,这个空闲时间可由参数kyuubi.session.engine.idle.timeout来控制。
6.2 Kyuubi CONNECTION 级别的引擎共享
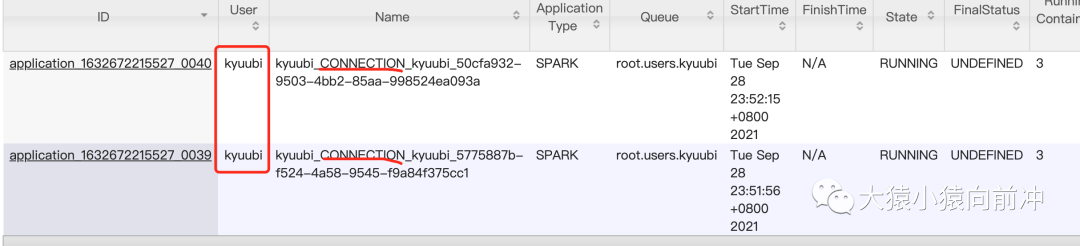
从资源共享的角度,Engine 支持用户端配置不同的共享级别,如果设置为 CONNECTION 级别共享,用户的一次 JDBC 连接就会初始化一个 Engine(例如:起多个 beeline 客户端,就会起多个 Spark Engine,对应多个 Spark Application),在这个连接内,用户可以执行多个 Statement 直至连接关闭。
如果设置为 USER 级别共享,用户的多次 JDBC 都会复用这个 Engine(例如:起多个 beeline 客户端,只会起一个 Spark Engine,对应一个 Spark Application),在高可用的模式中,无论用户的连接打到哪个 Kyuubi Server 实例上,这个 Engine 都能实现共享。
配置 conf/kyuubi-defaults.conf 以支持 CONNECTION 级别的引擎共享
kyuubi.engine.share.level=CONNECTION
# kyuubi.engine.share.level=USER
# kyuubi.session.engine.idle.timeout=PT10H
在多个客户端中起多个 beeline 客户端,yarn-ui 上可以看到每一个客户端对应着一个 Application,客户端连接断开之后,对应的 Spark Application 也会被释放掉。
7. 总结
上述文章梳理并记录了 Spark3.1.2 适配 CDH5 Hadoop 的编译和功能测试过程,并初步体验了 kyuubi,简单测试了 kyuubi 的多租户隔离特性,以及不同级别的 Engine 共享能力。
尤其是 Kyuubi 的 CONNECTION 级别的引擎共享机制,可以有效地解决 STS 被某些 SQL 执行时卡死的情况,每一个 tableau 数据源刷新任务触发时所建立的对 Kyuubi Server 的 ODBC 连接,都能对应一个独立的 Driver,就算此 Driver 被打死,也不会影响其他 SQL 的正常执行。
之后会继续为大家介绍我们在生产环境中对 Kyuubi 的使用经验。