
Http实战之缓存、重定向
Http缓存
关于Http缓存这部分内容在网上查阅资料时,发现很多文章将其分为*强制缓存、协商缓存或者对比缓存*,但笔者在RFC文档中并没有找到相关词汇,所以本文并不会采用上述分类,而是以RFC文件及《Http权威指南》中的内容为准。除此之外还需要明确的一点:「本文并不讨论【代理缓存】,只分析客户端本身进行缓存的情况」。
RFC文档:https://datatracker.ietf.org/doc/html/rfc2616#section-13,中主要涉及到的Http缓存相关的内容如下:
缓存处理步骤
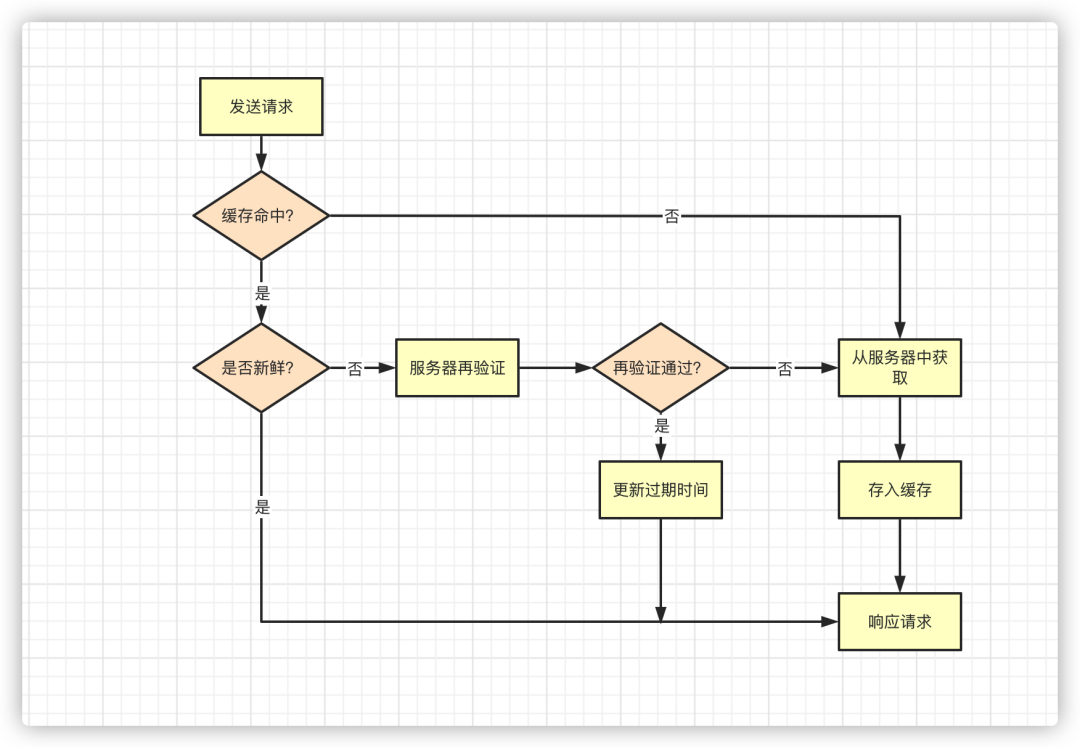
整个流程比较简单,可能需要解释的有两个名词
判断是否新鲜,也就是 新鲜度检测,可以理解为检查缓存是否已经过期服务器再验证,在确认了缓存已经过期的情况我们还需要到服务器去确认过期的缓存是否还有效,如果仍然有效的话此时我们需要将客户端的缓存重新生效,这个过程称之为 再验证(revalidation)。
关于第二点小伙伴们可能会有疑问:
为什么确认缓存已经过期了还需要去服务端验证呢,缓存过期不应该直接请求服务器返回最新数据吗?
再验证的话多了一次验证过程不是增加了网络开销了吗?
第一个问题,答:
「缓存过期并不意味着缓存中的数据跟服务器保存的数据不一致」,例如服务器通过Cache-Control 告诉了客户端缓存有效期为两小时,但在接下来的两小时内服务器上的这份数据并没有任何写入操作,也就是说虽然客户端在检测的时候数据已经过期了,但是客户端此时缓存的数据仍然跟服务器保存的最新数据是一致的,此时也就没必要让服务重新发送一份客户端已经缓存的数据,我们只需要服务器通过某种机制告诉客户端缓存是可用的即可。
第二个问题,答:
「缓存的再校验跟向服务器请求最新数据往往会被合并成一个请求」。我们可以在发送请求时附加一些用于验证的头信息,比如我们可以给缓存的实体打上一个标签,每次向服务器发送请求时携带上这个标签,当进行再验证时服务器校验客户端当前记录的数据标签是否跟自身保存的一致,如果一致告诉服务器缓存是可用的(304响应码),如果不一致则返回最新数据及最新标签。如下:
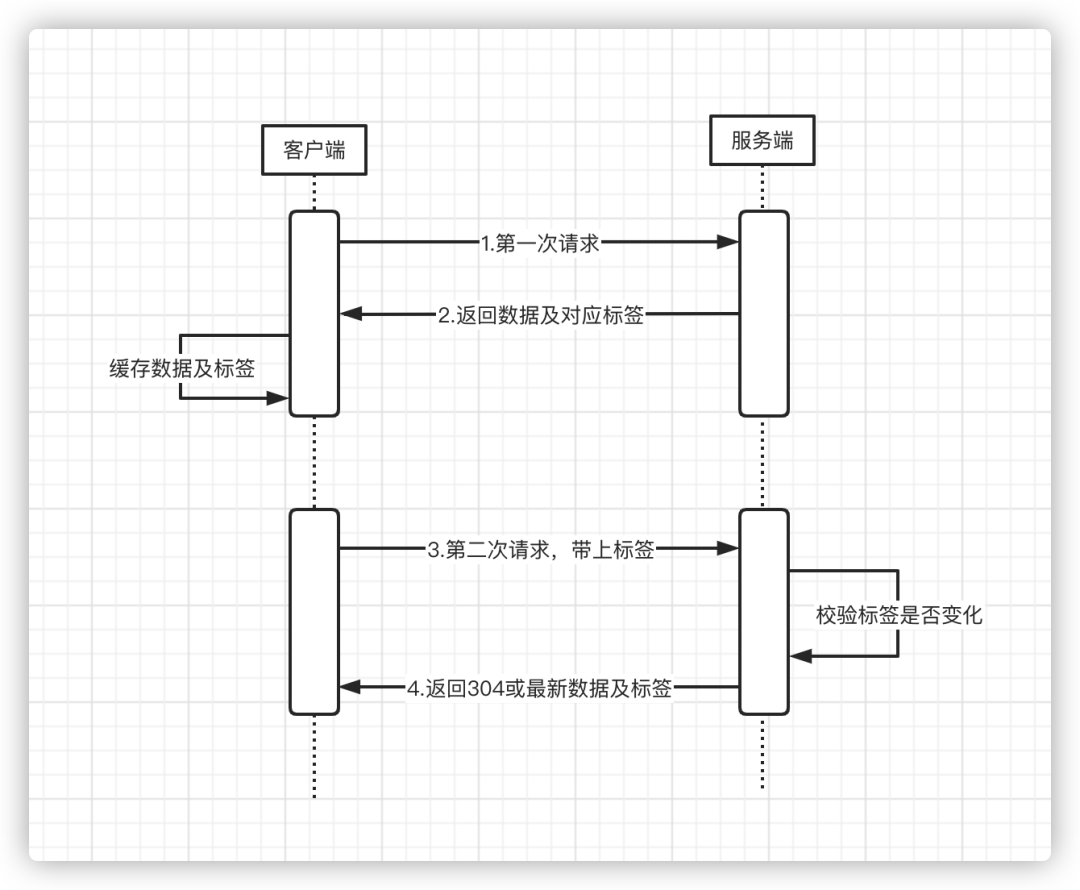
通过前文所述相信大家对Http的缓存机制有了一个大概的了解,那么接下来我们就开始分析其中的细节:「如何完成新鲜度检测及再验证?」
新鲜度检测
所谓新鲜度检测实际就是检测文档是否过期,服务器可以通过Cache-Control首部和 Expires首部指定返回数据的有效期,Expires是HTTP1.0的规范,使用的是决定时间,如下:
❝Expires: Wed, 21 Oct 2022 07:28:00 GMT
❞
Cache-Control是HTTP1.1的规范,搭配max-age并使用相对时间,如下:
❝Cache-Control: max-age=30(单位为秒)
❞
只要在有效期内,客户端即可认为此时的缓存数据是新鲜的,无须向服务器发送请求
再验证
如果客户端检测到此时缓存已经过期,那么需要向服务器发起再验证,一个具有再验证功能的请求跟普通的请求唯一的区别在于请求头中多了一些用于校验的字段,如下:
❝参考:https://datatracker.ietf.org/doc/html/rfc7232
❞
| 字段名 | 描述 | 备注 |
|---|---|---|
| If-Modified-Since | 如果从指定日期之后数据「【被修改】」过了则「验证」失败,需要向服务器发送请求获取最新数据,如果验证成功,服务端返回「「304(Not Modified)」」 | 通过日期校验,通常用于缓存再校验,一般会结合响应头中的Last-Modified使用 |
| If-None-Match | 如果缓存中数据的标签跟服务器数据的标签不匹配则验证失败,需要向服务器发送请求获取最新数据,与Etag 服务器响应首部配合使用,如果验证成功,服务端返回「「304(Not Modified)」」 | 通过唯一标识进行校验,通常用于缓存再校验 |
「If-Modified-Since」再验证工作过程如下
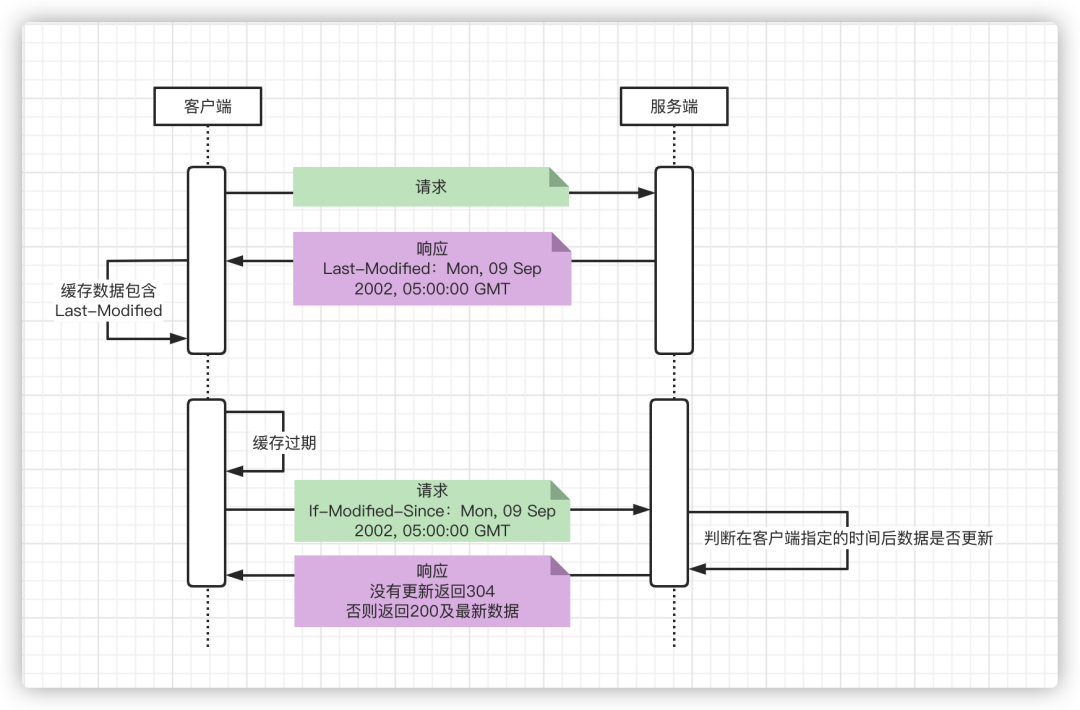
客户端在第一次缓存时同时也记录了服务器返回的Last-Modified,再后续发现缓存过期时会向服务器发送一个再验证请求,在请求头中添加一个If-Modified-Since字段,其值为Last-Modified的值,服务器在收到此请求后,先判断在指定时间后数据是否发生了变化,如果没有变化则返回「「304(Not Modified)」」,否则返回200状态码及最新数据。
「If-None-Match」:实体标签再验证
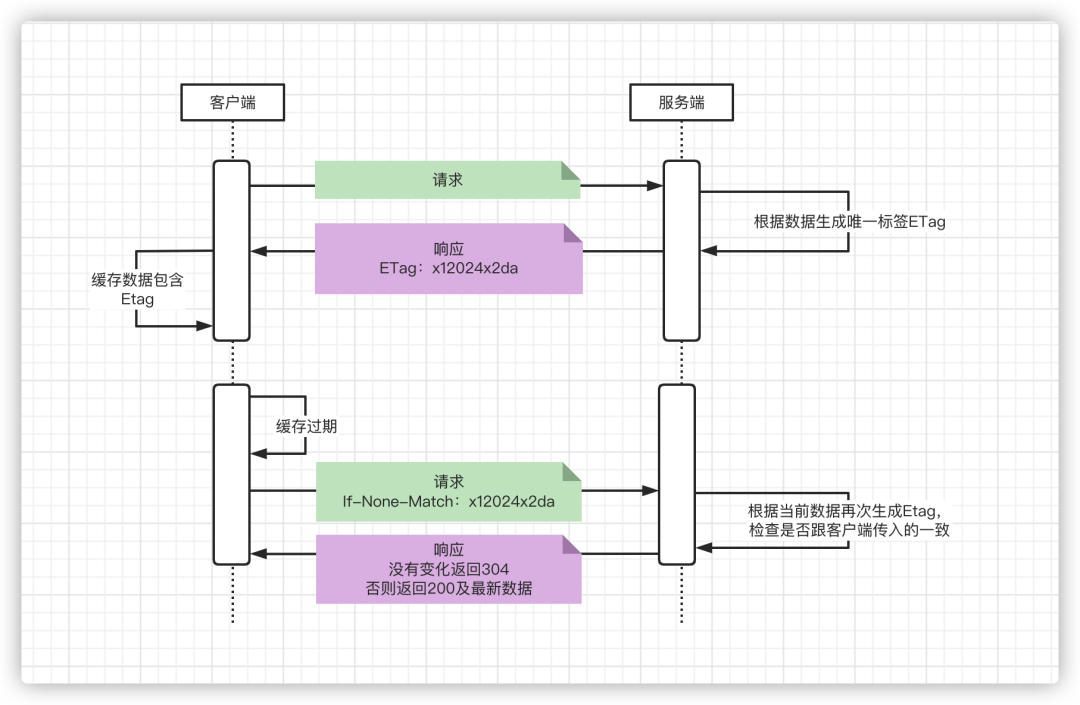
整个校验过程跟「If-Modified-Since」是一致的,唯一的区别在于「If-Modified-Since」校验的是日志,而「If-None-Match」校验的是数据对应的唯一标签。如果 缓存数据中同时有 Etag 和 Last-Modified 字段的时候, Etag 的优先级更高,也就是先会判断 Etag 是否变化了,如果 Etag 没有变化,然后再看 Last-Modified。
这里需要说明一下,除了上面提到的两个头部字段外,Http中还定义了一些其它的带有校验含义的header,如下:
| 字段名 | 描述 | 备注 |
|---|---|---|
| If-Match | 与Etag 服务器响应首部配合使用,校验失败返回「「412(Precondition Failed)」」 | 并不用于缓存相关操作,而是用于避免错误的更新操作(PUT、POST、DELETE),只有在满足条件的情况下才允许更新,通常用于多人协作更新同一份数据时 |
| If-Unmodified-Since | 如果从指定日期之后数据「【未被修改】」则「验证」成功。验证失败时服务端需要返回「「412(Precondition Failed)」」 | 跟If-Match一样能避免错误的更新操作,不同的是If-Match比较的是标签而If-Unmodified-Since比较的是日期。另外在进行部分文件的传输时,获取文件的其余部分之前,要确保文件未发生变化,此时这个首部是非常有用的。例如在端点续传的场景下,需要保证服务端已经传送到客户端的资源没有发生变化。 |
| If-Range | 支持对不完整文档的缓存,会搭配服务器响应中的Last-Modified或者ETag使用,验证失败时服务端需要返回「「412(Precondition Failed)」」 | 主要用于范围请求或断点续传 |
读者朋友们需要注意的是,虽然If-Match、If-Unmodified-Since看起来是If-None-Match跟If-Modified-Since的反义词,但在HTPP协议中定义的语义是完全不一样的。具体可以参考:https://datatracker.ietf.org/doc/html/rfc7232#page-17
缓存控制
关于缓存控制我们可以分为两部分讨论
服务端如何进行缓存控制 客户端如何进行缓存控制
服务端控制
服务端进行缓存控制主要依赖Cache-Control、及Expires请求头,其中Expires已经不推荐使用。其优先级如下所示:
附加一个 Cache-Control: no-store首部到响应中去;附加一个 Cache-Control: no-cache首部到响应中去;附加一个 Cache-Control: must-revalidate首部到响应中去;附加一个 Cache-Control: max-age首部到响应中去;附加一个 Expires日期首部到响应中去;
Cache-Control: no-store,客户端禁止使用缓存
Cache-Control: no-cache,客户端可以进行缓存,但每次使用缓存时必须跟服务器进行「再验证」
Cache-Control: must-revalidate ,客户端可以进行缓存,在「缓存过期后」必须进行「再验证」,跟no-cache的区别在于must-revalidate强调的是缓存过期后的行为,因为在某些情况下为了提升效率客户端会使用已经过期的缓存,如果服务端指定了Cache-Control: must-revalidate ,那么缓存过期后不能直接使用,必须进行再验证。no-cache不论缓存是否过期都需要客户端发起再验证。
Cache-Control: max-age ,指明了缓存的有效期,是一个相对时间,单位为秒
Expires ,指明了缓存的有效,是一个决定时间。HTTP 设计者后来认为,由于很多服务器的时钟都不同步,或者不正确,所以最好还是用剩余秒 数,而不是绝对时间来表示过期时间,已经不推荐使用。
客户端控制
上面我们介绍了,服务器端如何在响应头中添加响应的字段来浏览来是否可以使用缓存,同样,客户端自己也可以控制,以浏览器为例,这里我们主要说三个场景:
浏览器刷新
即我们按F5刷新页面的时候,该页面的http请求中会添加:Cache-Control:max-age:0, 即说明缓存直接失效啦,就不走缓存了,直接从服务器端读取数据。
浏览器强制刷新
即我们按ctrl+f5强制刷新页面的时候,该页面的http请求会添加:Cache-Control:no-cache; 即表示此时要首先去服务器端验证资源是否有更新,如果有更新则直接返回最新资源,如果没有更新,则返回304,然后浏览器端判断是304的话,则从缓存中读取数据。
浏览器前进后退重定向
当我们点击浏览器的前进后退操作时,这个时候请求中不会有Cache-Control的字段,没有该字段,就表示会检查缓存,直接利用之前的资源,不再重新请求服务器。
httpClient缓存代码分析
需要引入HttpClinet缓存模块
测试代码如下:
public class CacheHttpClient {
static CacheConfig cacheConfig =
CacheConfig.custom().setMaxCacheEntries(1000).setMaxObjectSize(8192).build();
static CloseableHttpClient cachingClient =
CachingHttpClients.custom().setCacheConfig(cacheConfig).build();
public static void main(String[] args) throws Exception {
Scanner scanner = new Scanner(System.in);
while (true) {
scanner.nextLine();
HttpCacheContext context = HttpCacheContext.create();
HttpGet httpget = new HttpGet("http://www.mydomain.com/content/");
CloseableHttpResponse response = cachingClient.execute(httpget, context);
try {
CacheResponseStatus responseStatus = context.getCacheResponseStatus();
switch (responseStatus) {
case CACHE_HIT:
System.out.println(
"A response was generated from the cache with "
+ "no requests sent upstream");
break;
case CACHE_MODULE_RESPONSE:
System.out.println(
"The response was generated directly by the " + "caching module");
break;
case CACHE_MISS:
System.out.println("The response came from an upstream server");
break;
case VALIDATED:
System.out.println(
"The response was generated from the cache "
+ "after validating the entry with the origin server");
break;
default:
// do nothing
}
} finally {
response.close();
}
}
}
}
缓存的核心处理逻辑位于org.apache.http.impl.client.cache.CachingExec#execute中,如下:
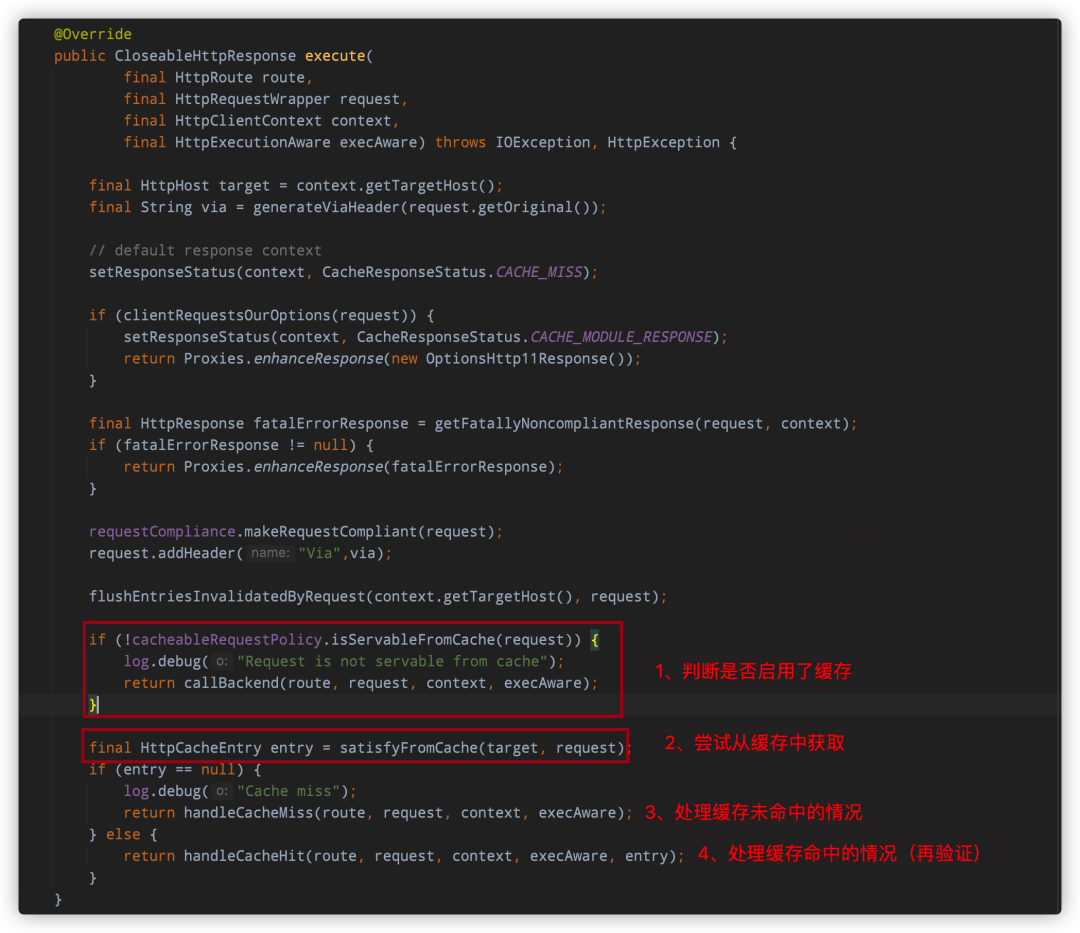
缓存处理的核心代码我在图中已经做了标注
是否启用缓存,代码很简单
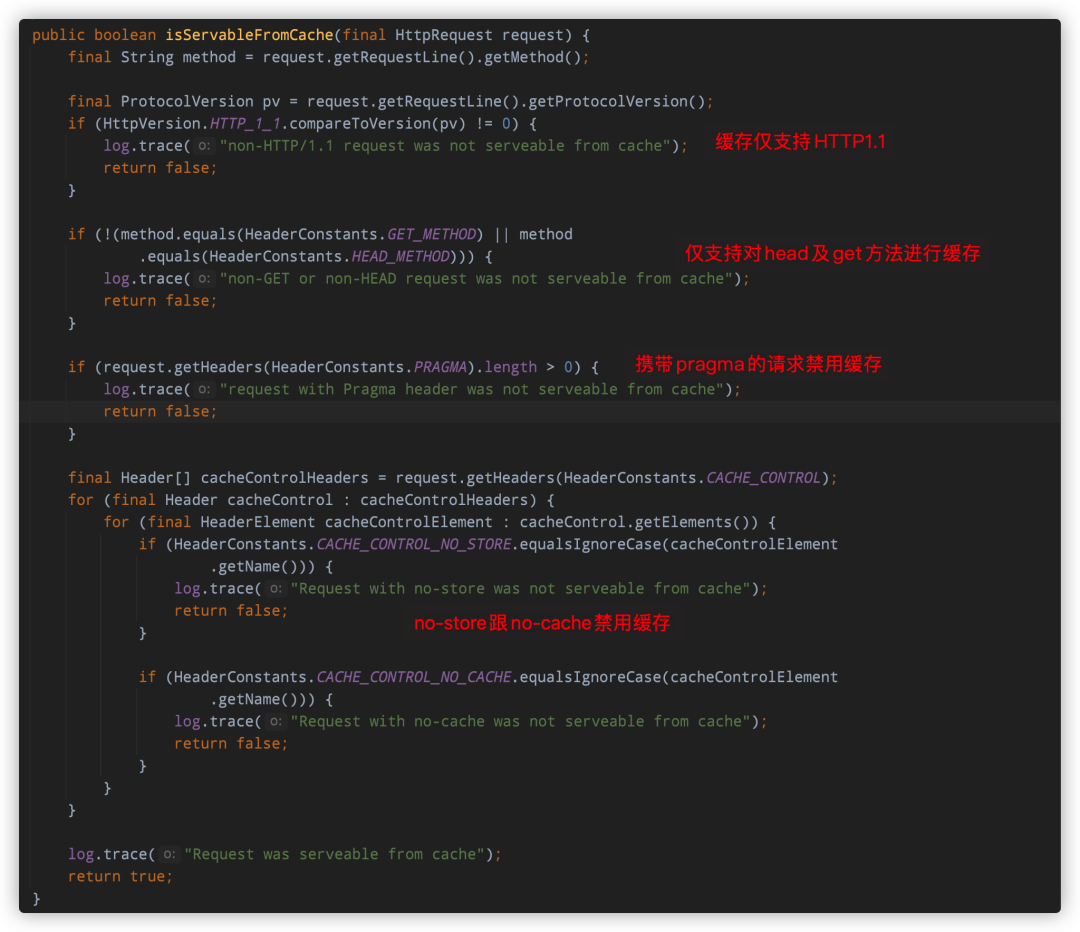
从缓存中获取信息,这里的key实际就是访问时使用的URI,缓存底层默认使用的是一个Map
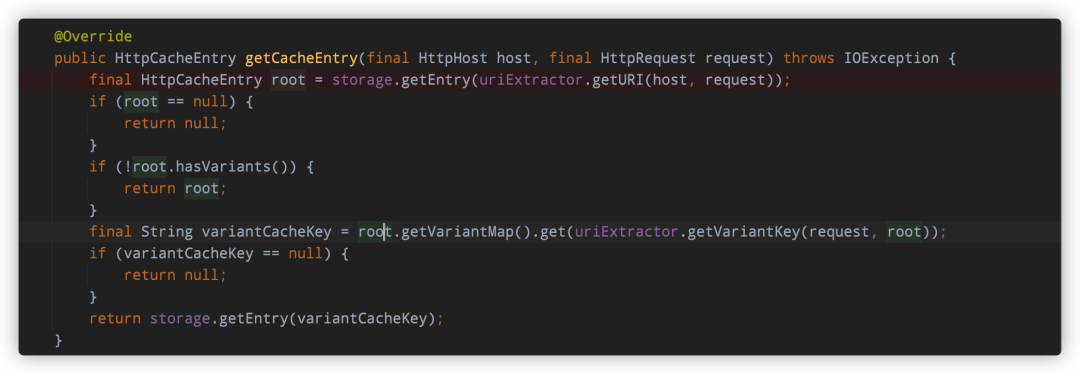
image-20220721214408121 缓存未命中时会向服务器发送真正的请求,代码简单,不做分析
缓存命中,这时要处理两种情况:「「缓存未过期」」、「「缓存过期+再验证」」
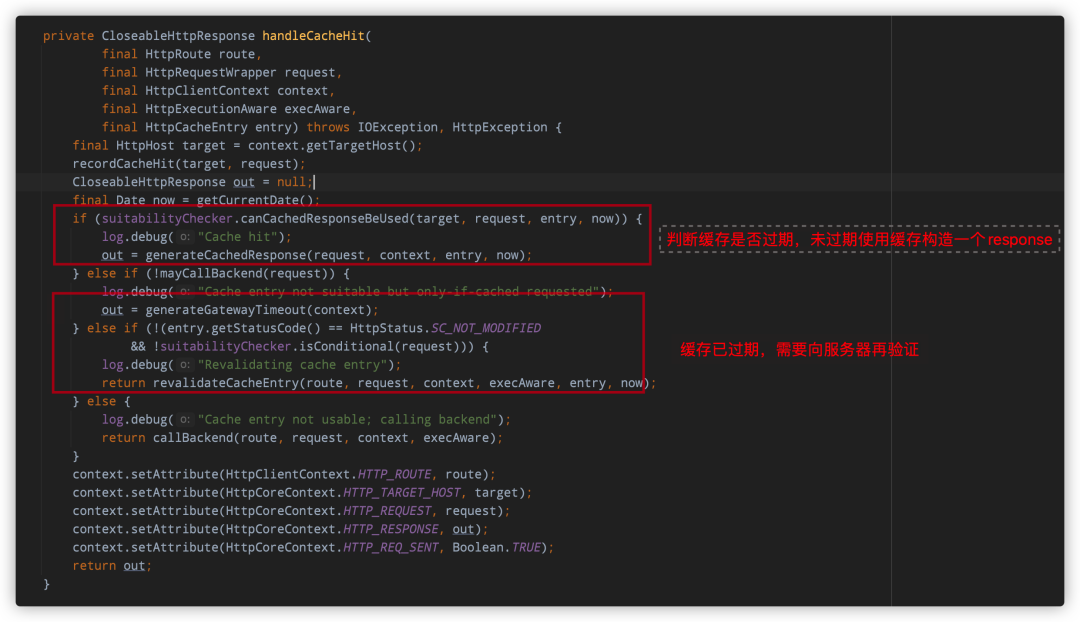
对http协议了解后,这块的代码非常简单,所以笔者在这里也不赘述了
重定向
❝https://datatracker.ietf.org/doc/html/rfc2616#page-61
❞
接下来我们聊聊重定向,跟重定向相关的响应码如下:
| 状态码 | 原因短语 | 含 义 |
|---|---|---|
| 301 | Moved Permanently | 在请求的 URL 已被移除时使用。响应的 Location 首部中应该包含 资源现在所处的URL,「【301代表永久重定向】」,客户端在后续访问时应该将URL替换为本次Location首部标明的URL |
| 302 | Found | 「【302代表临时重定向】」,客户端后续访问时不需要进行替换,仍然应该使用原来的URL |
| 303 | See Other | 其主要目的是允许 POST 请求的响应将客户端定向到某个资源上去 |
| 307 | Temporary Redirect | 也是临时重定向,跟302类似 |
你可能已经注意到 302、303 和 307 状态码之间存在一些交叉。这些状态码的用法有着细微的差别,大部分差别都源于 「【HTTP/1.0 和 HTTP/1.1 应用程序对 这些状态码处理方式的不同】」。
当 HTTP/1.0 客户端发起一个 POST 请求,并在响应中收到 302 重定向状态码时, 它会接受 Location 首部的重定向 URL,并向那个 URL 发起一个 GET 请求(而不 会像原始请求中那样发起 POST 请求)。
HTTP/1.0 服务器希望 HTTP/1.0 客户端这么做——如果 HTTP/1.0 服务器收到来自 HTTP/1.0 客户端的 POST 请求之后发送了 302 状态码,服务器就期望客户端能够接 受重定向 URL,并向重定向的 URL 发送一个 GET 请求。
问题出在 HTTP/1.1。HTTP/1.1 规范使用 303 状态码来实现同样的行为(服务器发 送 303 状态码来重定向客户端的 POST 请求,在它后面跟上一个 GET 请求)。
为了避开这个问题,HTTP/1.1 规范指出,对于 HTTP/1.1 客户端,用 307 状态码取 代 302 状态码来进行临时重定向。这样服务器就可以将 302 状态码保留起来,为 HTTP/1.0 客户端使用了。
HttpClient重定向代码分析
核心代码位于:org.apache.http.impl.execchain.RedirectExec#execute
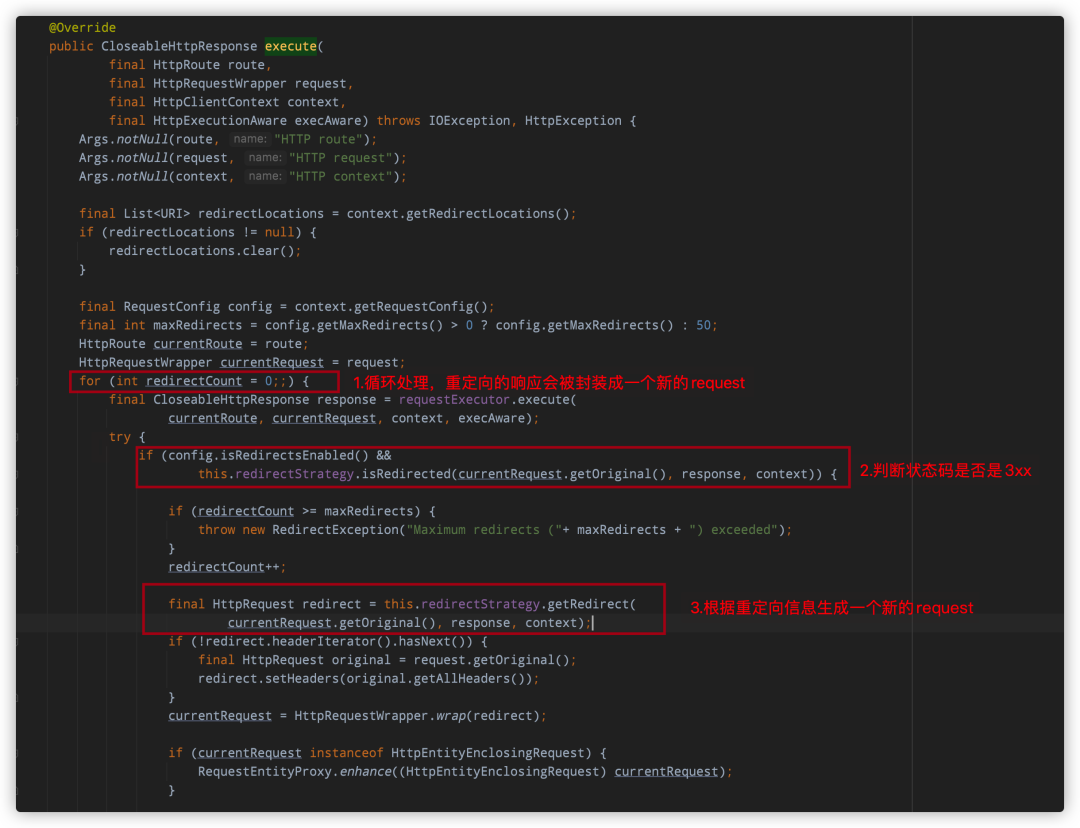
重定向的处理策略都定义在redirectStrategy中,我们看下它的代码:
isRedirected方法,是否需要重定向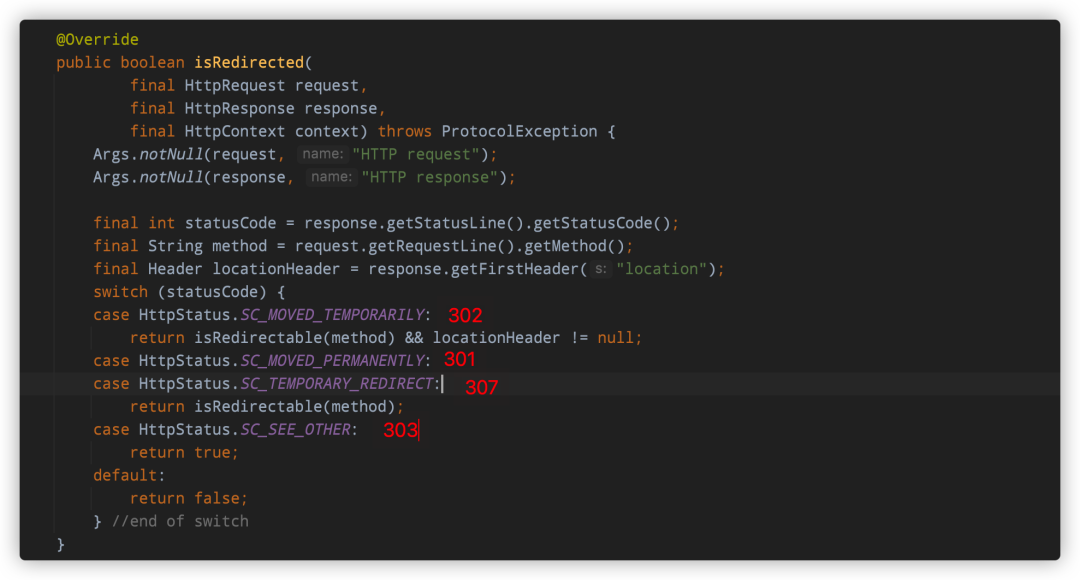
实际就是判断状态码是不是我们前文提到过的301、302、303、307。
getRedirect方法,重定向时需要封装的请求信息:请求方法+URL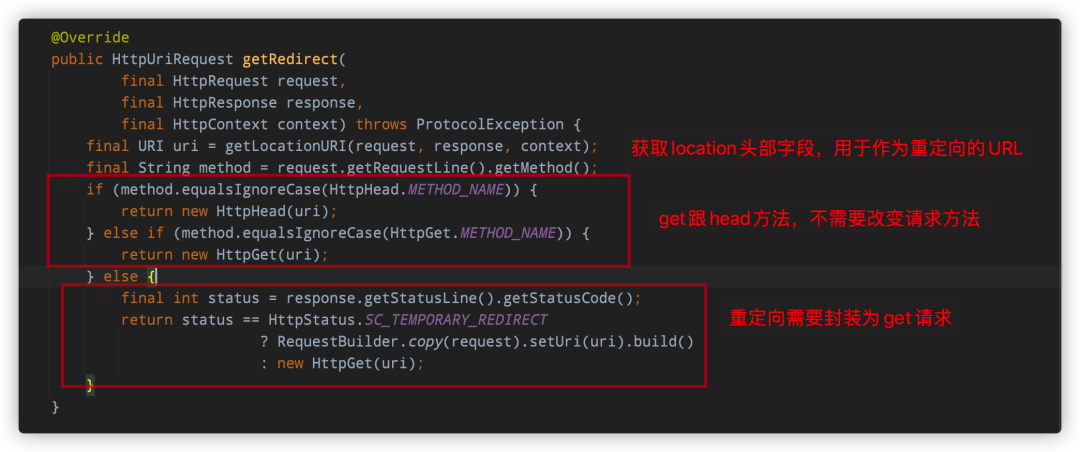
写在最后
本来打算这篇文章作为《HTTP实战》的最后一篇的,实在太忙再加上篇幅原因,关于数据压缩、分块传输、范围请求就放到下篇文章吧~
「参考:」
《Http权威指南》
https://hc.apache.org/httpcomponents-client-4.5.x/current/tutorial/html/caching.html
https://datatracker.ietf.org/doc/html/rfc2616#page-74
https://datatracker.ietf.org/doc/html/rfc7232#page-13
https://www.digitalocean.com/community/tutorials/web-caching-basics-terminology-http-headers-and-caching-strategies