
Transformer-Unet | 如何用Transformer一步一步改进 Unet?


本文提出了一种用于医学图像分析的基于Transformer和UNet的神经网络,Transformer直接处理原始图像而不是提取的特征图,性能优于Trans-Unet等网络。
作者单位:北京Zoezen机器人,北航
1简介
医学图像分割在生物医学图像分析中占有重要地位,也引起了人们的广泛关注。良好的分割结果可以帮助医生进行判断,进一步改善患者体验。
在医学图像分析的众多可用方法中,UNet是最受欢迎的神经网络之一,它通过在编码器和解码器之间添加级联来保持原始特征,这使得它在工业领域仍有广泛的应用。同时,Transformer作为一种主导自然语言处理任务的模型,现已被广泛地引入到计算机视觉任务中,并在目标检测、图像分类和语义分割等任务中取得了良好的效果。因此,Transformer和UNet的结合应该比2种方法单独工作更有效。
在本文中,作者提出了Transformer-UNet,通过在原始图像中添加Transformer Block而不是在UNet中添加Feature map,并在CT-82数据集中测试本文的网络来进行胰腺分割。在实验中,形成了一个端到端的网络,并获得了比以往许多基于Unet的算法更好的分割结果。
2本文方法
首先设计一个典型的UNet作为CNN结构,使用双线性插值作为上采样方法,max-pooling作为下采样方法。为了方便实现,作者设计了一个几乎对称的网络,它可以很容易修改注意力模块和Transformer模块。然而,在T-Unet中,编码器和解码器并不直接连接,这将在本节中解释。
Transformer作为一个以序列数据为输入的模型,对于分割任务Transformer则需要1D数据。因此,需要将一幅原始图像平展成维的数组,其中n×n为图像patch的大小,为数组序列的长度。遵循Dosovitskiy等人所提的方法,将整个图像分割成不同的平方块,n是正方形边缘的长度。为了简化实现过程,在大多数情况下假设H=W和H,W可以被n整除。

与NLP Transformer略有不同,如图1所示。ViT将LayerNorm放在Multi-Head Attention和MLP之前,以确保输入值不会太大而无法处理。此外,ViT保留了Vaswani等人(2017)的主要设计,如Multi-Head Self-Attention和MLP层。Dosovitskiy等人(2021)进一步添加了一个可学习的数组tensor,用于在将整个序列输入到存储在T-Unet中的Transformer之前进行位置嵌入。
作者进一步修改ViT,用ELU代替GELU作为在 Transformer MLP层的激活函数,因为作者观察到ELU在实验中表现更好。与RELU和GELU相比,ELU在Transformer中使用较少,其定义为:
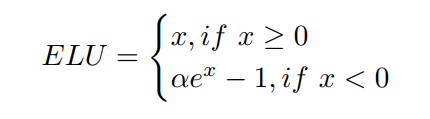
作者认为ELU是有用的,因为CT图像中的负值与正值同样重要。在实验中将超参数α设为1。
用上面解释的方法,用下列方程形成Transformer模型:
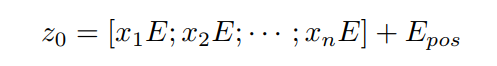
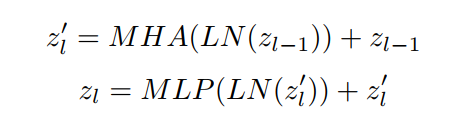
式中,MHA为Multi-Head Attention layers, LN为layer normalization, 为image patches, 为Transformer layer number。对于原始图像的处理,在ViT中通过在整个图像上应用一个核大小为的卷积操作进行Position Embedding过程。
Transformer在提取局部特征方面不如CNN高效,所以作者遵循UNet的设计在T-Unet中添加了一个附加的编码器。此编码器不直接与解码器连接。
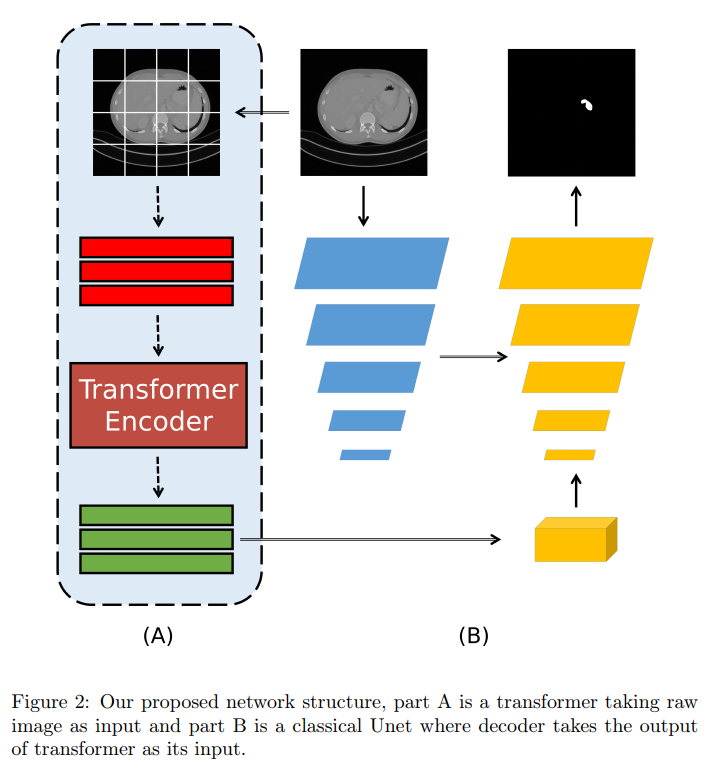
相反,它输出具有不同接受域的特征映射,并将它们与解码器中的特征映射连接起来,如图2所示。解码器以Transformer的输出作为输入,具体来说,对于采用大小为的序列的Transformer,将其输出Reshape为大小为并将其直接送入解码器。通过这样做保证了解码器的输入包含了不同图像patch的信息,因此对最终预测更好。
3复现
由于在TUnet中处理原始图像,原始图像和图像patch的大小非常重要,因为它们决定了Transformer模型的大小和运行速度。由于选择CT82作为实验数据集,其中包含大小为的高分辨率CT切片,因此选择作为图像patch大小,因此构建的序列长度为1024。因此,在实验中解码器的输入尺寸为,进一步通过双线性插值将其Reshape为尺寸为。作者按照Ronneberger等人的方法在解码器中添加了连接部分,并相应地构建了编码器。为了最小化模型,同时保持其效率,作者设计的Transformer模块中的注意力头和总层数分别为8和6。
4损失函数
为了评价模型,通过与其他算法的比较,本文选择了在Binary分割任务中最常用的损失函数binary Cross Entropy(BCE) Loss作为主要损失函数。这个损失函数比较简单,在最终的预测概率图中并不能反映像素之间的关系,所以它更能说明模型是如何连接图片的不同部分的。一般来说,BCE Loss定义为:
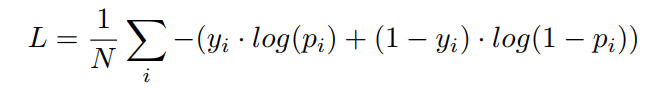
其中N是像素个数,是像素的标签,是像素的标签在最终的预测映射中为真的概率。根据定义,很明显,这个函数只计算最终预测ixel-bypixel的损失,而不是区域的损失。
5实现细节
数据集的大小对Transformer很重要。通过对CT切片而不是整个CT序列进行处理,可以扩大数据集的大小。
基于MLP的Transformer占用了大量的图形存储空间。因此,Transformer不会大量增加权重文件的大小,因此更适合于2D图像。
因此,在实验中处理CT切片,并将TUnet与现有模型Unet、Attention Unet和TransUnet进行比较。为了使模型更好地处理数据,作者将整个图像用1024进行分割,1024是数据集中所有CT切片的近似最大绝对值。
6实验
6.1 结果分析
作者的主要评价方法是多个验证指标,包括mIOU值和最终预测的Dice score。CT82数据集被分离为60/22进行训练和测试。在模型中,最低分辨率为16×16,这也适用于Unet, Attention Unet和TransUnet。
为了证明结果,作者将阈值设置为0.8(即,最终预测图中值大于0.8的像素将被视为胰腺点),在计算mIOU和像素精度值时,不仅要考虑胰腺分割的准确性,还要考虑背景的识别。
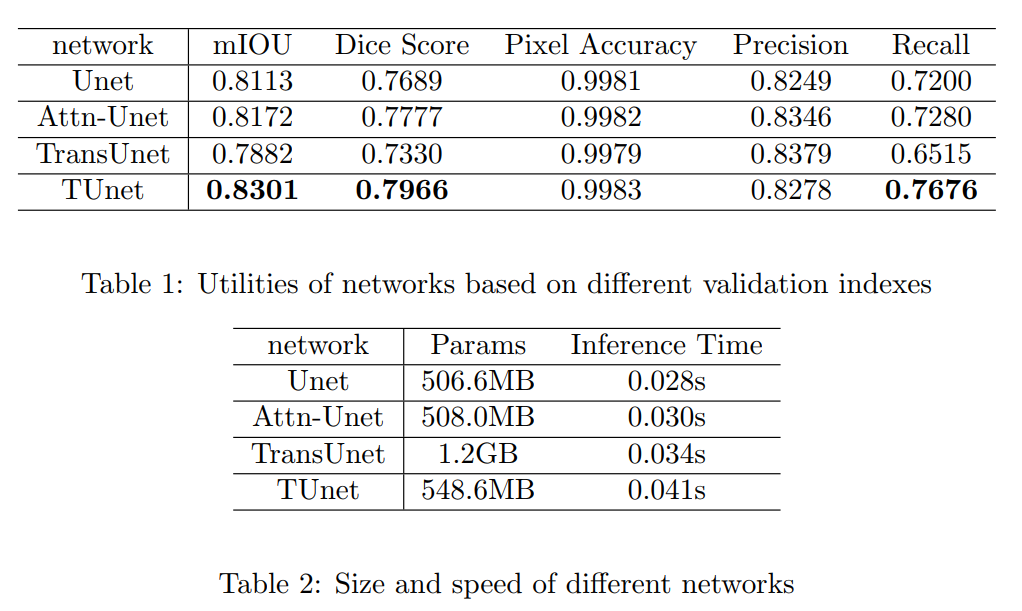

图3显示了Transformer的一个主要优点,这使得模型可以使用几个Transformer层在全局和局部进行特性提取工作。
表1显示了Unet的性能和它的方差,包括TUNet。以深层Unet模型为Backbone,本文的模型能够超越UNet及其相关网络,包括目前流行的Attention Unet。
表2显示了不同模型的大小和推理时间,本文模型并没有带来特别大的参数量和推理速度。
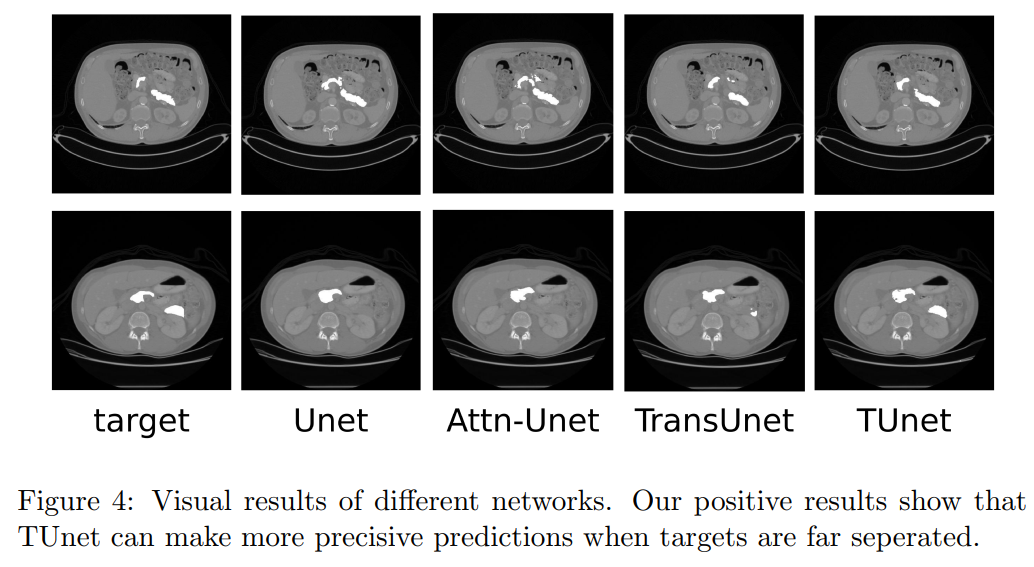
图4显示了不同网络的可视化结果,TUnet由于使用了Transformer,能够对长距离像素对进行很好的分割,因此优于以往其他基于Unet的网络。
6.2 方差分析
在实验中,选择n=16作为图像patch的大小。然而,还有许多其他选项,这表明16可能不是TUnet的理想值,进一步对n=32,32进行实验。
TUnet的另一个重要特征是deep and large Unet backbone。然而,Unet和Attention Unet在浅层模型中仍然有用。由于深度模型不像浅模型那样方便,因为它们自然需要更好的硬件,如gpu,所以进一步尝试浅模型Unet Backbone。在较浅的模型中Unet中减少了1/3层CNN,并将kernel数量减少到1/4。整个模型仍然是端到端的从头到尾地训练原始模型。
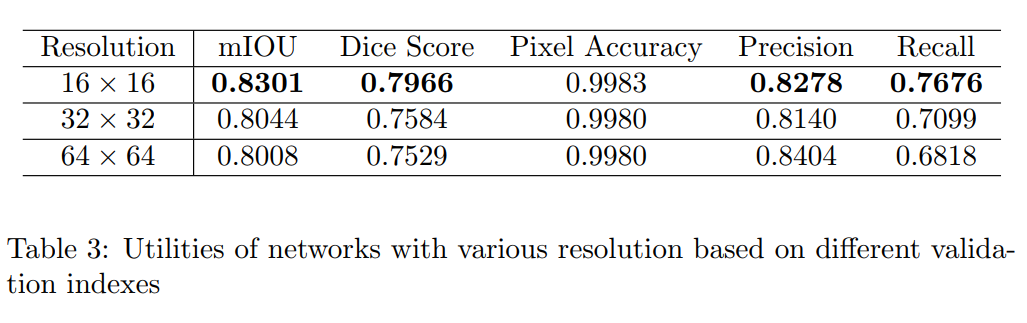
从表3可以看出,对于T-Unet来说,是Transformer的最佳分辨率,而高分辨率会降低Transformer的效率,因为同时阵列序列的长度也在减少,而这对于Transformer的自注意力层是必不可少的。
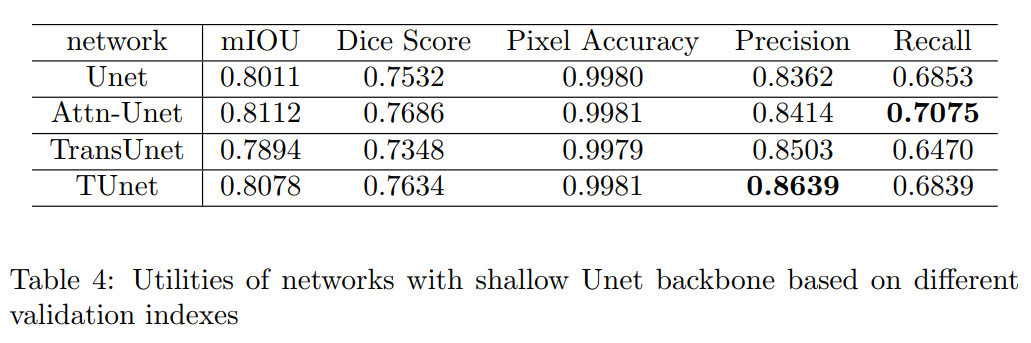
从表4中可以看出,当使用浅层网络作为Backbone时,T-Unet没有明显的优势。因此,Transformer提取的抽象特征可能需要更深层次的模型进行解码。
7参考
[1].Transformer-Unet: Raw Image Processing with Unet
8推荐阅读

高效Transformer | 85FPS!CNN + Transformer语义分割的又一境界,真的很快!

【书童的学习笔记】集智小书童建议你这么学习Transformer,全干货!!!

改进UNet | 透过UCTransNet分析ResNet+UNet是不是真的有效?
长按扫描下方二维码添加小助手。
可以一起讨论遇到的问题
声明:转载请说明出处
扫描下方二维码关注【集智书童】公众号,获取更多实践项目源码和论文解读,非常期待你我的相遇,让我们以梦为马,砥砺前行!
