
最新ICCV 2021 | 虚拟试衣(21)图像编辑-文本引导(22)图像编辑-单样本(23)生成对抗GAN
图像编辑系列之(2)基于StyleGAN(3)GAN逆映射(4)人脸 (5)语义生成
图像恢复系列之(6)超分(7)反光去除(8)光斑去除 (9)阴影去除(10)水下图像失真去除
图像检测系列之(12)异常检测(13)拼接伪造(14)deepfake
二十一、虚拟试衣
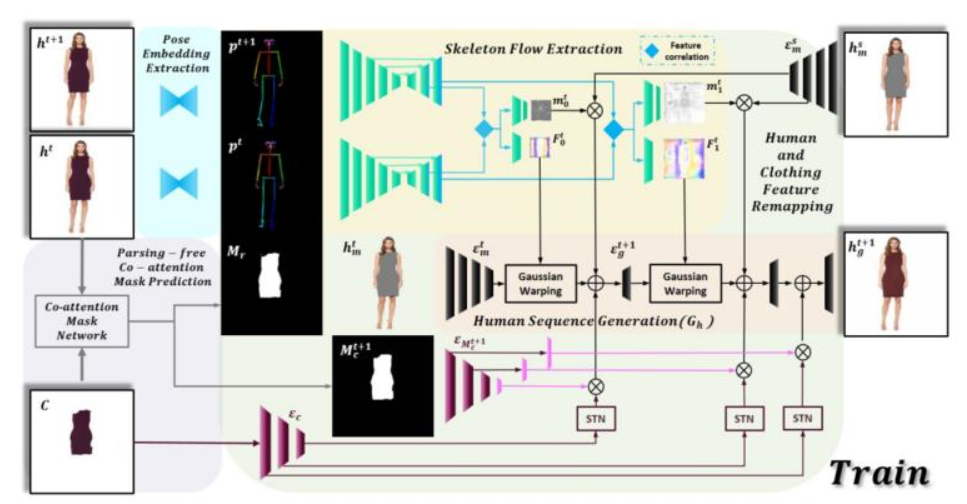
63、FashionMirror: Co-attention Feature-remapping Virtual Try-on with Sequential Template Poses
虚拟试穿任务引起了越来越多的关注。现有技术专注于通过扭曲衣服和在语义分割的帮助下融合像素级别的信息来解决此任务。但语义分割比较耗时,且随着时间的推移容易导致错误累积。此外,在像素级别而不是特征级别扭曲信息会限制性能(例如,无法生成不同的视图)。相比之下,在特征层面融合信息可以通过卷积进一步细化得到最终结果。
基于这些假设,提出了一个协同注意力的特征重映射框架( co-attention feature-remapping framework),即 FashionMirror,它根据驱动姿势序列分两个阶段生成试穿结果。在第一阶段,考虑源人体图像和目标试穿衣服来预测移除掩膜和试穿衣服的掩膜,以取代预处理的语义分割,减少推理时间。在第二阶段,首先通过移除掩膜对源人体上的衣服进行移除,并扭曲试穿衣服掩膜上的衣服特征,且调节以适应下一帧的人。同时预测来自连续 2D 姿势的光流,并将源人类扭曲到特征级别的下一帧。然后,在每一帧中增强服装特征并获取人体特征,以生成具有时空平滑度的真实试穿结果。定性和定量结果都表明了FashionMirror 的优越性。
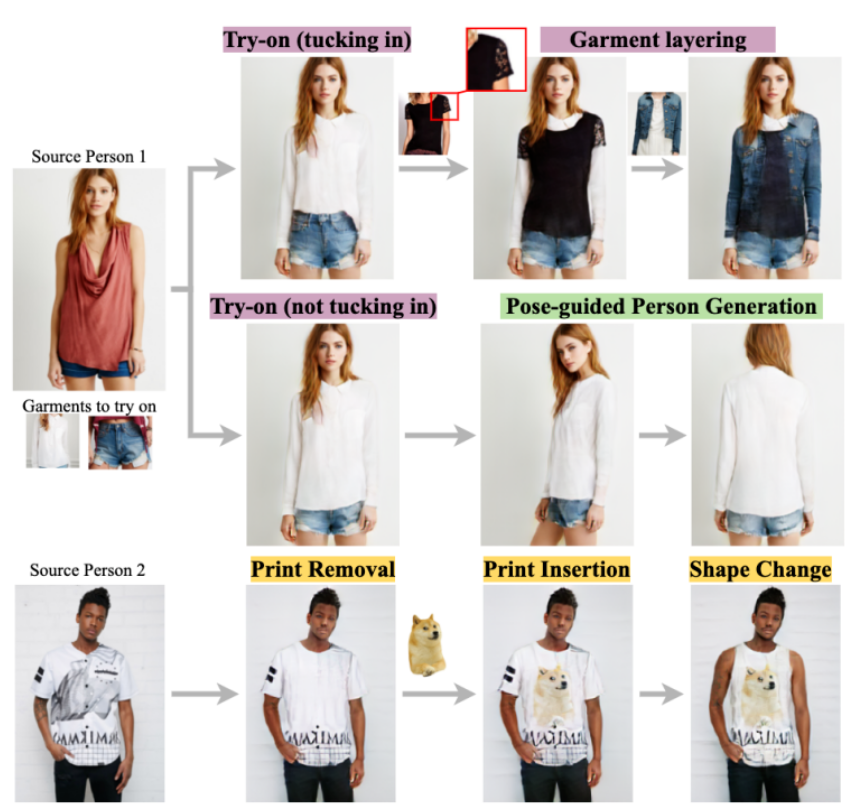
64、Dressing in Order: Recurrent Person Image Generation for Pose Transfer, Virtual Try-on and Outfit Editing
本文提出了一个灵活的人物生成框架,称为 Dressing in Order (DiOr),它支持 2D 姿势转换、虚拟试穿和时尚编辑任务。DiOr 的关键是一种循环生成流水线,可以将衣服按顺序穿在一个人身上,这样以不同的顺序试穿相同的衣服就会产生不同的外观。
系统可以产生现有工作无法实现的着装效果,包括服装的不同相互作用(例如,将上衣塞进下装或叠穿),以及多件相同类型的服装的分层(例如,将夹克套在衬衫套上) T恤)。DiOr 明确编码每件衣服的形状和质地,使这些元素可以单独编辑。姿势转移和修复的联合培训有助于生成服装的细节保存和连贯性。
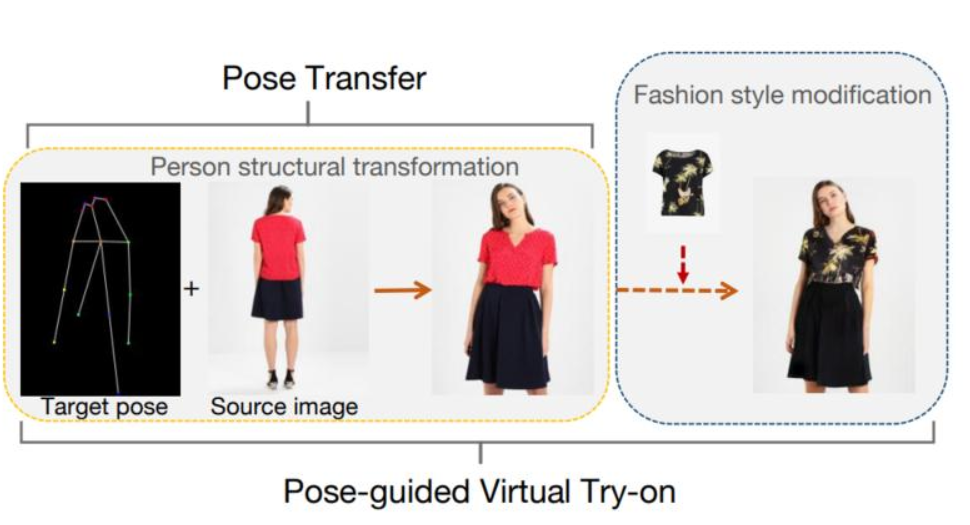
65、Structure-transformed Texture-enhanced Network for Person Image Synthesis
姿势引导的虚拟试穿指的是,基于姿势迁移任务下,去修改服饰。这是两个人物图像合成中的常见任务,具有很强的相关性和相似性。但大多数现有方法将它们视为两个单独的任务,并没有探索它们之间的相关性。此外,由于较大的错位和遮挡,这两项任务具有挑战性,因此这些方法中的大多数容易产生不清晰的人体结构和模糊的细粒度纹理。
本文设计一个结构转换的纹理增强网络来生成高质量的人物图像并构建两个任务之间的关系。由两个模块组成:结构转换渲染器和纹理增强风格器(structure-transformed renderer and texture enhanced stylizer)。大量实验表明,方法在两项任务上的优越性。
二十二、图像编辑-文本引导
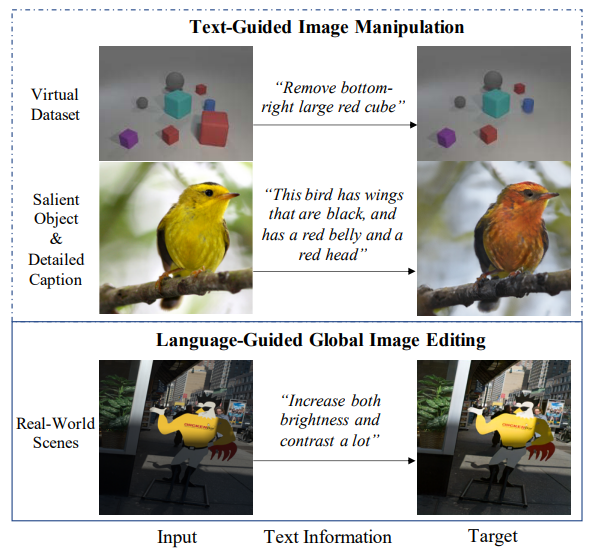
66、Language-Guided Global Image Editing via Cross-Modal Cyclic Mechanism
通过语言请求来自动编辑图像可以大大节省繁重的手工工作,且对摄影新手友好。
本文专注于语言引导的全局图像编辑任务。现有工作存在数据集数据分布不平衡和不足的问题,因此无法很好地理解语言请求。为了解决这个问题,使用图像生成器创建一个循环,方法是创建一个称为编辑描述网络 (EDNet) 的新模型,该模型预测给定一对图像的编辑嵌入。鉴于循环,提出了几种增强策略,以帮助模型在不平衡数据集的情况下理解各种编辑请求。此外,还提出了图像请求注意(IRA)模块,当图像在不同区域需要不同的编辑程度时,该模块可以在空间上自适应地编辑图像,以及对此的新评估指标比传统像素损失(例如 L1)更语义和合理的任务。对两个基准数据集的广泛实验证明了方法的有效性。
二十三、图像编辑-单样本
67、Image Shape Manipulation from a Single Augmented Training Sample
本文提出 DeepSIM,一种基于单张图像的条件生成模型。本文认为数据增强是实现单图像训练的关键,并将薄板样条 (TPS) 的使用作为有效的增强。
网络学习在图像的原始表征与图像本身之间进行映射,而原始表征的选择对操作的易用性和表现力有影响,可以是自动的(例如边缘)、手动的(例如分割)或混合的,例如分割的边缘。操作时,生成器通过修改原始输入表示并将其映射到网络来进行复杂的图像更改。

猜您喜欢:
 戳我,查看GAN的系列专辑~!
戳我,查看GAN的系列专辑~!附下载 |《TensorFlow 2.0 深度学习算法实战》