
挑战Redis单实例内存最大极限,“遭遇”NUMA陷阱!

我们公司的基础架构部有个云Redis平台,其中Redis实例在申请的时候可以自由选择需要的内存的大小。然后就引发了我的一个思考,Redis单实例内存最大申请到多大比较合适?假设母机是64GB内存的物理机,如果不考虑CPU资源的的浪费,我是否可以开一个50G的Redis实例?
于是我在Google上各种搜索,讨论这个问题的人似乎不多。找到唯一感觉靠谱点的答案,那就是单进程分配的内存最好不要超过一个node里的内存总量,否则linux当该node里的内存分配光了的时候,会在自己node里动用硬盘swap,而不是其它node里申请。这即使所谓的numa陷阱,当Redis进入这种状态后会导致性能急剧下降(不只是redis,所有的内存密集型应用如mysql,mongo等都会有类似问题)。

到来后来CPU的开发者们发现CPU的频率已经接近物理极限了,没法再有更大程度的提高了。在2003年的时候,CPU的频率就已经达到2个多GB,甚至3个G了。现在你再来看今天的CPU,基本也还是这个频率,没进步多少。摩尔定律失效了,或者说是向另外一个方向发展了。那就是多核化、多CPU化。
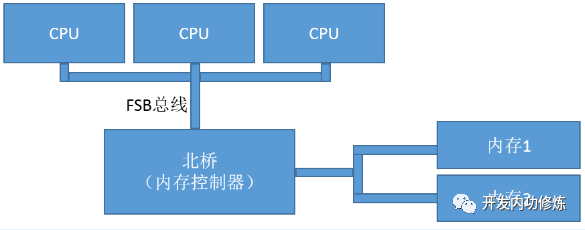
刚开始核不多的时候,FSB总线勉强还可以支撑。但是随着CPU越来越多,所有的数据IO都通过这一条总线和内存交换数据,这条FSB就成为了整个计算机系统的瓶颈。举个北京的例子,这就好比进回龙观的京藏高速,刚开始回龙观人口不多的时候,这条高速承载没问题。但是现在回龙观聚集了几十万人了,“总线”还仅有这一条,未免效率太低。
CPU的设计者们很快改变了自己的设计,引入了QPI总线,相应的CPU的结构就叫NMUA架构。下图直观理解

NUMA陷阱指的是引入QPI总线后,在计算机系统里可能会存在的一个坑。大致的意思就是如果你的机器打开了numa,那么你的内存即使在充足的情况下,也会使用磁盘上的swap,导致性能低下。原因就是NUMA为了高效,会仅仅只从你的当前node里分配内存,只要当前node里用光了(即使其它node还有),也仍然会启用硬盘swap。
# numactl --hardware
available: 2 nodes (0-1)
node 0 cpus: 0 1 2 3 4 5 12 13 14 15 16 17
node 0 size: 32756 MB
node 0 free: 19642 MB
node 1 cpus: 6 7 8 9 10 11 18 19 20 21 22 23
node 1 size: 32768 MB
node 1 free: 18652 MB
node distances:
node 0 1
0: 10 21
1: 21 100 关闭zone_reclaim模式,可以从其他zone或NUMA节点回收内存 1 打开zone_reclaim模式,这样内存回收只会发生在本地节点内
2 在本地回收内存时,可以将cache中的脏数据写回硬盘,以回收内存
4 在本地回收内存时,表示可以用Swap 方式回收内存
# cat /proc/sys/vm/zone_reclaim_mode
1额,好吧。我的这台机器上的zone_reclaim_mode还真是1,只会在本地节点回收内存。
那我的好奇心就来了,既然我的单个node节点只有32G,那我部署一个50G的Redis,给它填满数据试试到底会不会发生swap。
# top
......
Mem: 65961428k total, 26748124k used, 39213304k free, 632832k buffers
Swap: 8388600k total, 0k used, 8388600k free, 1408376k cached
# cat /proc/zoneinfo"
......
Node 0, zone Normal
pages free 4651908
Node 1, zone Normal
pages free 4773314/proc/zoneinfo里包含了node可供应用程序申请的free pages。node1有4651908个页面,4651908*4K=18G的可用内存。# top
Mem: 65961428k total, 53140400k used, 12821028k free, 637112k buffers
Swap: 8388600k total, 0k used, 8388600k free, 1072524k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
8356 root 20 0 62.8g 46g 1292 S 0.0 74.5 3:45.34 redis-server
# cat /proc/zoneinfo | grep "pages free"
pages free 3935
pages free 347180
pages free 1402744
pages free 1501670莫非是大佬们的忠告错了吗?其实不是,如果不绑定亲和性的话,分配内存是当进程在哪个node上的CPU发起内存申请,就优先在哪个node里分配内存。之所以是平均分配在两个node里,是因为redis-server进程实验中经常会进入主动睡眠状态,醒来后可能CPU就换了。所以基本上,最后看起来内存是平均分配的。如下图,CPU进行了500万次的上下文切换,用top命令看到cpu也是在node0和node1跳来跳去。
# grep ctxt /proc/8356/status
voluntary_ctxt_switches: 5259503
nonvoluntary_ctxt_switches: 1449# cat /proc/zoneinfo
Node 0, zone Normal
pages free 7597369
Node 1, zone Normal
pages free 7686732绑定CPU和内存的亲和性,然后再启动。
numactl --cpunodebind=0 --membind=0 /search/odin/daemon/redis/bin/redis-server /search/odin/daemon/redis/conf/redis.conftop命令观察到CPU确实一直在node0的节点里。node里的内存也在快速消耗。
# cat /proc/zoneinfo
Node 0, zone Normal
pages free 10697
Node 1, zone Normal
pages free 7686732看,内存很快就消耗光了。我们再看top命令观察到的swap,很激动地发现,我终于陷入到传说中的numa陷阱了。
Tasks: 603 total, 2 running, 601 sleeping, 0 stopped, 0 zombie
Cpu(s): 0.7%us, 5.4%sy, 0.0%ni, 85.6%id, 8.2%wa, 0.0%hi, 0.1%si, 0.0%st
Mem: 65961428k total, 34530000k used, 31431428k free, 319156k buffers
Swap: 8388600k total, 6000792k used, 2387808k free, 777584k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
258 root 20 0 0 0 0 R 72.3 0.0 0:17.18 kswapd0
25934 root 20 0 37.5g 30g 1224 D 71.6 48.7 1:06.09 redis-server通过今天的实验,我们可以发现确实有NUMA陷阱这种东西存在。不过那是我手工通过numactl指令绑定cpu和mem的亲和性后才遭遇的。相信国内绝大部分的线上Redis没有进行这个绑定,所以理论上来单Redis单实例可以使用到整个机器的物理内存。(实践中最好不要这么干,你的大部分内存都绑定到一个redis进程里的话,那其它CPU核就没啥事干了,浪费了CPU的多核计算能力)
numactl绑定CPU和mem都在一个node里的时候,内存IO不需要经过总线,性能会比较高,你Redis的QPS能力也会上涨。和跨node的内存IO性能对比,可以下面的实例,就是10:21的区别。# numactl --hardware
......
node distances:
node 0 1
0: 10 21
1: 21 10你要是对性能有极致的追求,可以试着绑定numa的亲和性玩玩。不过,no作no die,掉到numa陷阱里可别赖我,嘎嘎!
【好东西值得分享,点亮看点】